Beberapa bulan yang lalu, saya mengalami masalah, model saya yang dibangun pada algoritma pembelajaran mesin tidak berfungsi. Saya sudah lama berpikir tentang bagaimana menyelesaikan masalah ini dan pada titik tertentu saya menyadari bahwa pengetahuan saya sangat terbatas dan ide-ide saya langka. Saya tahu beberapa lusin model, dan ini adalah bagian yang sangat kecil dari karya-karya yang bisa sangat berguna.
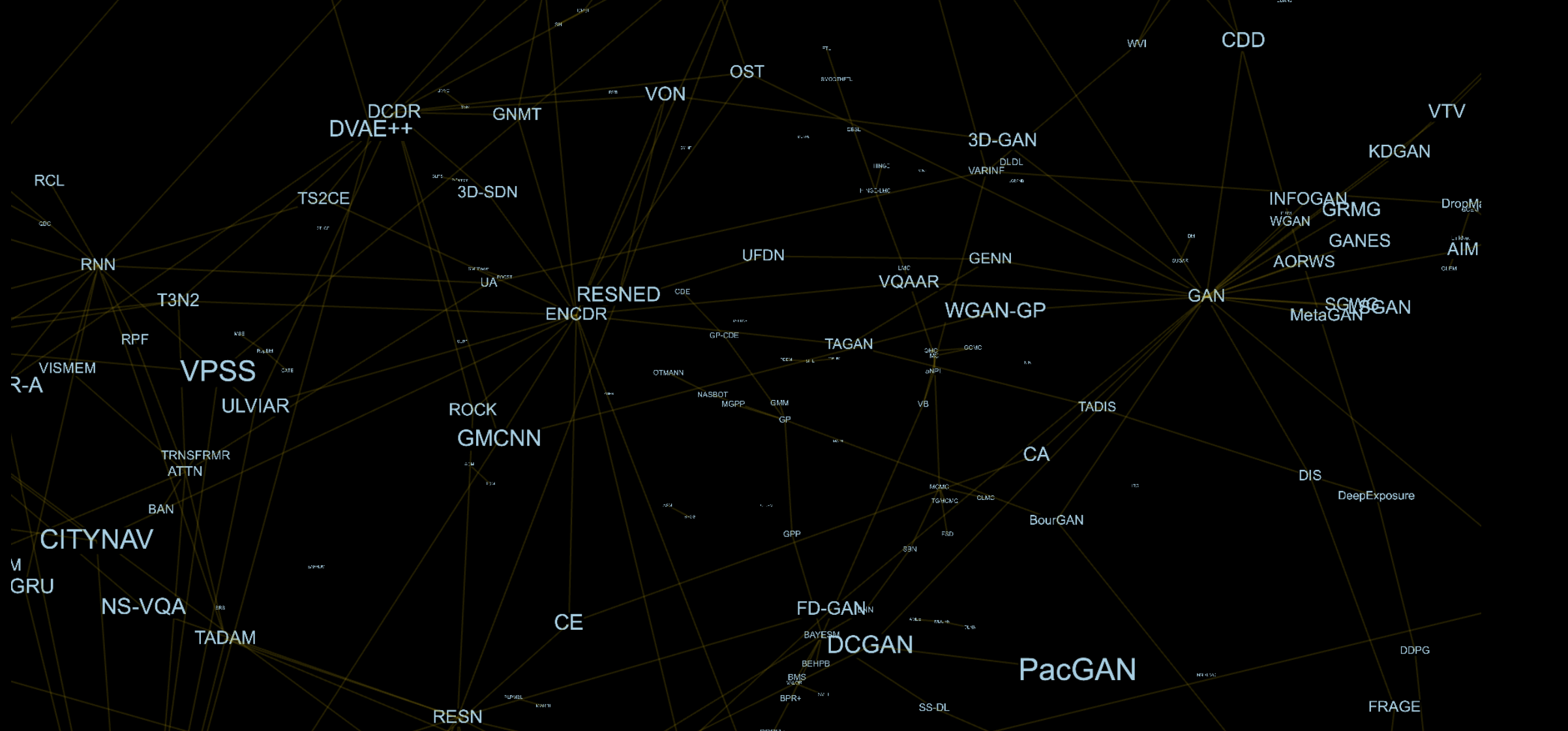
Pikiran pertama yang muncul di benak saya adalah jika saya tahu dan memahami lebih banyak model, kualitas saya sebagai peneliti dan insinyur secara keseluruhan akan meningkat. Gagasan ini mendorong saya untuk mempelajari artikel dari konferensi pembelajaran mesin baru-baru ini. Penyusunan informasi semacam itu cukup sulit, dan perlu untuk mencatat ketergantungan dan hubungan antar metode. Saya tidak ingin menyajikan dependensi dalam bentuk tabel atau daftar, tetapi saya menginginkan sesuatu yang lebih alami. Akibatnya, saya menyadari bahwa memiliki grafik tiga dimensi dengan tepi antara model dan komponennya untuk diri saya, terlihat cukup menarik.
Sebagai contoh, arsitektur GAN [1] terdiri dari generator (GEN) dan diskriminator (DIS), Adversarial Auto-Encoder (AAE) [2] terdiri dari Auto-Encoder (AE) [3] dan DIS,. Setiap komponen adalah simpul terpisah dalam grafik ini, jadi untuk AAE kita akan memiliki keunggulan dengan AE dan DIS.
Selangkah demi selangkah, saya menganalisis artikel-artikel itu, menulis metode apa yang mereka gunakan, dalam bidang studi apa yang mereka terapkan, pada data apa mereka diuji, dan sebagainya. Dalam prosesnya, saya menyadari berapa banyak solusi yang sangat menarik yang belum diketahui, dan tidak menemukan aplikasi mereka.
Pembelajaran mesin dibagi menjadi beberapa bidang studi, di mana setiap bidang mencoba memecahkan masalah tertentu menggunakan metode tertentu. Dalam beberapa tahun terakhir, perbatasan hampir dihapus, dan praktis sulit untuk mengidentifikasi komponen yang hanya digunakan di area tertentu. Tren ini umumnya mengarah pada hasil yang lebih baik, tetapi masalahnya adalah bahwa dengan peningkatan jumlah artikel, banyak metode menarik tidak diperhatikan. Ada banyak alasan untuk ini, dan mempopulerkannya oleh perusahaan besar hanya di daerah tertentu memainkan peran penting dalam hal ini. Menyadari hal ini, grafik, yang sebelumnya dikembangkan sebagai sesuatu yang sangat pribadi, menjadi publik dan terbuka.
Secara alami, saya melakukan penelitian dan mencoba mencari analog dengan apa yang saya lakukan. Ada cukup layanan yang memungkinkan Anda untuk memantau munculnya artikel baru di area ini. Tetapi semua metode ini ditujukan terutama untuk menyederhanakan perolehan pengetahuan, dan bukan untuk membantu menciptakan ide-ide baru. Kreativitas lebih penting daripada pengalaman, dan alat yang dapat membantu Anda berpikir ke arah yang berbeda dan melihat gambaran yang lebih lengkap, menurut saya yang seharusnya menjadi bagian integral dari proses penelitian.
Kami memiliki alat yang mempermudah percobaan, peluncuran, dan evaluasi model, tetapi kami tidak memiliki metode yang memungkinkan kami menghasilkan dan mengevaluasi ide dengan cepat.
Hanya dalam beberapa bulan, saya menyortir sekitar 250 artikel dari konferensi NeurIPS terakhir dan sekitar 250 artikel lainnya yang menjadi dasarnya. Sebagian besar daerah benar-benar asing bagi saya, butuh beberapa hari untuk memahaminya. Kadang-kadang saya tidak dapat menemukan deskripsi yang tepat untuk model, dan komponen apa yang mereka miliki. Melanjutkan dari ini, langkah logis kedua adalah untuk menciptakan kemungkinan bagi penulis untuk menambah dan mengubah metode dalam grafik itu sendiri, karena tidak ada seorang pun kecuali penulis artikel yang tahu cara mem-parsing dan menggambarkan metode mereka dengan cara terbaik.
Contoh dari apa yang terjadi sebagai hasilnya disajikan di sini.
Saya berharap proyek ini akan bermanfaat bagi seseorang, jika hanya karena itu, mungkin, akan memungkinkan seseorang untuk mendapatkan asosiasi yang dapat mengarah pada ide baru yang menarik. Saya terkejut ketika saya mendengar bagaimana ide jaringan persaingan generatif didasarkan. Pada podcast Intelijen mesin MIT [4], Yan Goodfellow mengatakan bahwa gagasan jaringan permusuhan dikaitkan dengan fase “positif” dan “negatif” dari pembelajaran Mesin Boltzman [5].
Proyek ini digerakkan oleh masyarakat. Saya ingin mengembangkannya dan memotivasi lebih banyak orang untuk menambahkan informasi tentang metode mereka di sana, atau mengedit apa yang sudah dibuat. Saya percaya bahwa informasi metode yang lebih akurat dan teknologi visualisasi yang lebih baik akan sangat membantu menjadikan ini alat yang bermanfaat.
Ada banyak ruang untuk pengembangan proyek, mulai dari meningkatkan visualisasi itu sendiri, berakhir dengan kemampuan untuk membangun grafik individu dengan kemungkinan mendapatkan rekomendasi untuk metode perbaikan.
Beberapa
detail teknis
dapat ditemukan di sini .
[1] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio. Generasi Adversarial Nets.[2] Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, Ian Goodfellow, Brendan Frey. Autoencoder Adversarial.[3] Dana H. Ballard. Autoencoder.[4] Ian J. Goodfellow: podcast Kecerdasan Buatan di MIT.[5] Ruslan Salakhutdinov, Geoffrey Hinton. Mesin boltzmann yang dalam