
Pertemuan Tahunan Asosiasi untuk Linguistik Komputasi (ACL) adalah konferensi pemrosesan bahasa alami utama. Ini telah diselenggarakan sejak 1962. Setelah Kanada dan Australia, dia kembali ke Eropa dan berbaris di Florence. Dengan demikian, tahun ini lebih populer di kalangan peneliti Eropa daripada EMNLP serupa dengan itu.
Tahun ini 660 artikel dari 2900 yang dikirimkan diterbitkan. Jumlah yang sangat besar. Hampir tidak mungkin membuat semacam tinjauan objektif tentang apa yang ada di konferensi. Karena itu, saya akan menceritakan perasaan subjektif saya dari acara ini.
Saya datang ke konferensi untuk menunjukkan dalam sesi poster
keputusan kami dari kompetisi Kaggle tentang
Resolusi Pronoun Jender Google. Solusi kami sangat bergantung pada penggunaan
model BERT yang telah
dilatih sebelumnya . Dan, ternyata, kami tidak sendirian dalam hal ini.
Bertologi

Ada begitu banyak karya berdasarkan BERT, menggambarkan sifat-sifatnya dan menggunakannya sebagai ruang bawah tanah, bahkan istilah Bertology muncul. Memang, model BERT ternyata sangat sukses sehingga bahkan kelompok penelitian besar membandingkan model mereka dengan BERT.
Jadi pada awal Juni, pekerjaan muncul tentang
XLNet . Dan tepat sebelum konferensi -
ERNIE 2.0 dan
RoBERTaFacebook RoBERTa
Ketika model XLNet pertama kali diperkenalkan, beberapa peneliti menyarankan agar mencapai hasil yang lebih baik bukan hanya karena arsitektur dan prinsip pelatihannya. Dia juga belajar pada tubuh yang lebih besar (hampir 10 kali) dari BERT dan lebih lama (iterasi 4 kali lebih banyak).
Para peneliti di Facebook telah menunjukkan bahwa BERT belum mencapai maksimum. Mereka mempresentasikan pendekatan yang dioptimalkan untuk mengajar model BERT - RoBERTa (Pendekatan BERT yang dioptimalkan dengan kuat).
Tidak mengubah apa pun dalam arsitektur model, mereka mengubah prosedur pelatihan:
- Kami meningkatkan tubuh untuk pelatihan, ukuran bets, panjang urutan dan durasi pelatihan.
- Tugas memprediksi kalimat selanjutnya dihapus dari pelatihan.
- Mereka mulai secara dinamis menghasilkan token MASK (token bahwa model mencoba untuk memprediksi selama pra-pelatihan).
ERNIE 2.0 dari Baidu
Seperti semua model terbaru yang populer (BERT, GPT, XLM, RoBERTa, XLNet), ERNIE didasarkan pada konsep transformator dengan mekanisme self-attention. Apa yang membedakannya dari model lain adalah konsep pembelajaran multi-tugas dan pembelajaran berkelanjutan.
ERNIE belajar tentang tugas yang berbeda, terus-menerus memperbarui representasi internal model bahasanya. Tugas-tugas ini memiliki, seperti model lain, tujuan belajar mandiri (diawasi sendiri dan diawasi lemah). Contoh tugas tersebut:
- Pulihkan urutan kata yang benar dalam sebuah kalimat.
- Kapitalisasi kata.
- Definisi kata bertopeng.
Pada tugas-tugas ini, model belajar secara berurutan, kembali ke tugas-tugas di mana ia dilatih sebelumnya.
RoBERTa vs ERNIE
Dalam publikasi, RoBERTa dan ERNIE tidak dibandingkan satu sama lain, karena mereka muncul hampir bersamaan. Mereka dibandingkan dengan BERT dan XLNet. Tapi di sini tidak mudah untuk membuat perbandingan. Misalnya, dalam
tolok ukur populer,
GLUE XLNet diwakili oleh ansambel model. Dan peneliti dari Baidu lebih tertarik membandingkan model tunggal. Selain itu, karena Baidu adalah perusahaan Cina, mereka juga tertarik untuk membandingkan hasil bekerja dengan bahasa Cina. Baru-baru ini, sebuah tolok ukur baru telah muncul:
SuperGLUE . Belum ada banyak solusi, tetapi RoBERTa ada di tempat pertama di sini.
Namun secara keseluruhan, RoBERTa dan ERNIE memiliki kinerja yang lebih baik daripada XLNet dan secara signifikan lebih baik daripada BERT. RoBERTa, pada gilirannya, bekerja sedikit lebih baik daripada ERNIE.
Grafik pengetahuan
Banyak pekerjaan telah dikhususkan untuk menggabungkan dua pendekatan: jaringan pra-terlatih dan penggunaan aturan dalam bentuk grafik pengetahuan (Grafik Pengetahuan, KG).
Misalnya:
ERNIE: Representasi Bahasa yang Disempurnakan dengan Entitas Informatif . Makalah ini menyoroti penggunaan grafik pengetahuan di atas model bahasa BERT. Ini memungkinkan Anda untuk mendapatkan hasil yang lebih baik pada tugas-tugas seperti menentukan jenis entitas (
Pengetikan Entitas) dan Klasifikasi Relasi .
Secara umum, mode untuk memilih nama untuk model dengan nama-nama karakter dari Sesame Street menyebabkan konsekuensi lucu. Misalnya, ERNIE ini tidak ada hubungannya dengan ERNIE 2.0 Baidu, tentang yang saya tulis di atas.

Karya lain yang menarik tentang menghasilkan pengetahuan baru:
COMET: Commonsense Transformers untuk Konstruksi Grafik Pengetahuan Otomatis . Makalah ini mempertimbangkan kemungkinan menggunakan arsitektur baru berdasarkan transformator untuk pelatihan jaringan berbasis pengetahuan. Basis pengetahuan dalam bentuk yang disederhanakan adalah tiga kali lipat: subjek, sikap, objek. Mereka mengambil dua dataset basis pengetahuan: ATOMIC dan ConceptNet. Dan mereka melatih jaringan berdasarkan model GPT (Generative Pre-terlatih Transformer). Subjek dan sikap adalah input dan mencoba untuk memprediksi objek. Dengan demikian, mereka mendapat model yang menghasilkan objek dengan memasukkan subjek dan hubungan.
Metrik
Topik menarik lainnya di konferensi adalah masalah memilih metrik. Seringkali sulit untuk mengevaluasi kualitas model dalam tugas pemrosesan bahasa alami, yang memperlambat kemajuan dalam bidang pembelajaran mesin ini.
Dalam
Mempelajari Metodologi Evaluasi Summarization dalam artikel
Rentang Penilaian yang Tepat , Maxim Peyar membahas penggunaan berbagai metrik dalam masalah peringkasan teks. Metrik ini tidak selalu berkorelasi baik satu sama lain, yang mengganggu perbandingan objektif berbagai algoritma.
Atau inilah pekerjaan yang menarik:
Evaluasi Otomatis untuk Teks Multi-Kalimat . Di dalamnya, penulis menyajikan metrik yang dapat menggantikan BLEU dan ROUGE pada tugas di mana Anda perlu mengevaluasi teks dari beberapa kalimat.
Metrik BLEU dapat direpresentasikan sebagai Presisi - berapa banyak kata (atau n-gram) dari respons model yang terkandung dalam target. ROUGE adalah Panggilan - berapa banyak kata (atau n-gram) dari target yang terkandung dalam respons model.
Metrik yang diusulkan dalam artikel ini didasarkan pada metrik WMD (Word Mover's Distance) - jarak antara dua dokumen. Itu sama dengan jarak minimum antara kata-kata dalam dua kalimat dalam ruang representasi vektor kata-kata ini. Informasi lebih lanjut tentang WMD dapat ditemukan di tutorial, yang menggunakan
WMD dari Word2Vec dan
dari GloVe .
Dalam artikel mereka, mereka menawarkan metrik baru: WMS (Word Mover's Similarity).
WMS(A, B) = exp(−WMD(A, B))
Mereka kemudian mendefinisikan SMS (Kesamaan Kalimat Penggerak). Ini menggunakan pendekatan yang mirip dengan pendekatan dengan WMS. Sebagai representasi vektor dari kalimat, mereka mengambil vektor rata-rata dari kata-kata kalimat.
Saat menghitung WMS, kata-kata dinormalisasi dengan frekuensinya dalam dokumen. Saat menghitung kalimat SMS dinormalisasi dengan jumlah kata dalam kalimat.
Akhirnya, metrik S + WMS adalah kombinasi dari WMS dan SMS. Dalam artikel mereka, mereka menunjukkan bahwa metrik mereka berkorelasi lebih baik dengan penilaian manual seseorang.
Chatbots
Bagian yang paling berguna dari konferensi, menurut pendapat saya, adalah sesi poster. Tidak semua laporan menarik, tetapi jika Anda mulai mendengarkan beberapa, Anda tidak akan meninggalkan yang lain di tengah laporan. Poster adalah masalah lain. Ada beberapa lusin dari mereka di sesi poster. Anda memilih yang Anda sukai dan sebagai aturan, Anda dapat berbicara langsung dengan pengembang tentang perincian teknis. Ngomong-ngomong, ada situs yang menarik dengan
poster dari konferensi . Benar, ada poster dari dua konferensi di sana, dan tidak diketahui apakah situs akan diperbarui.
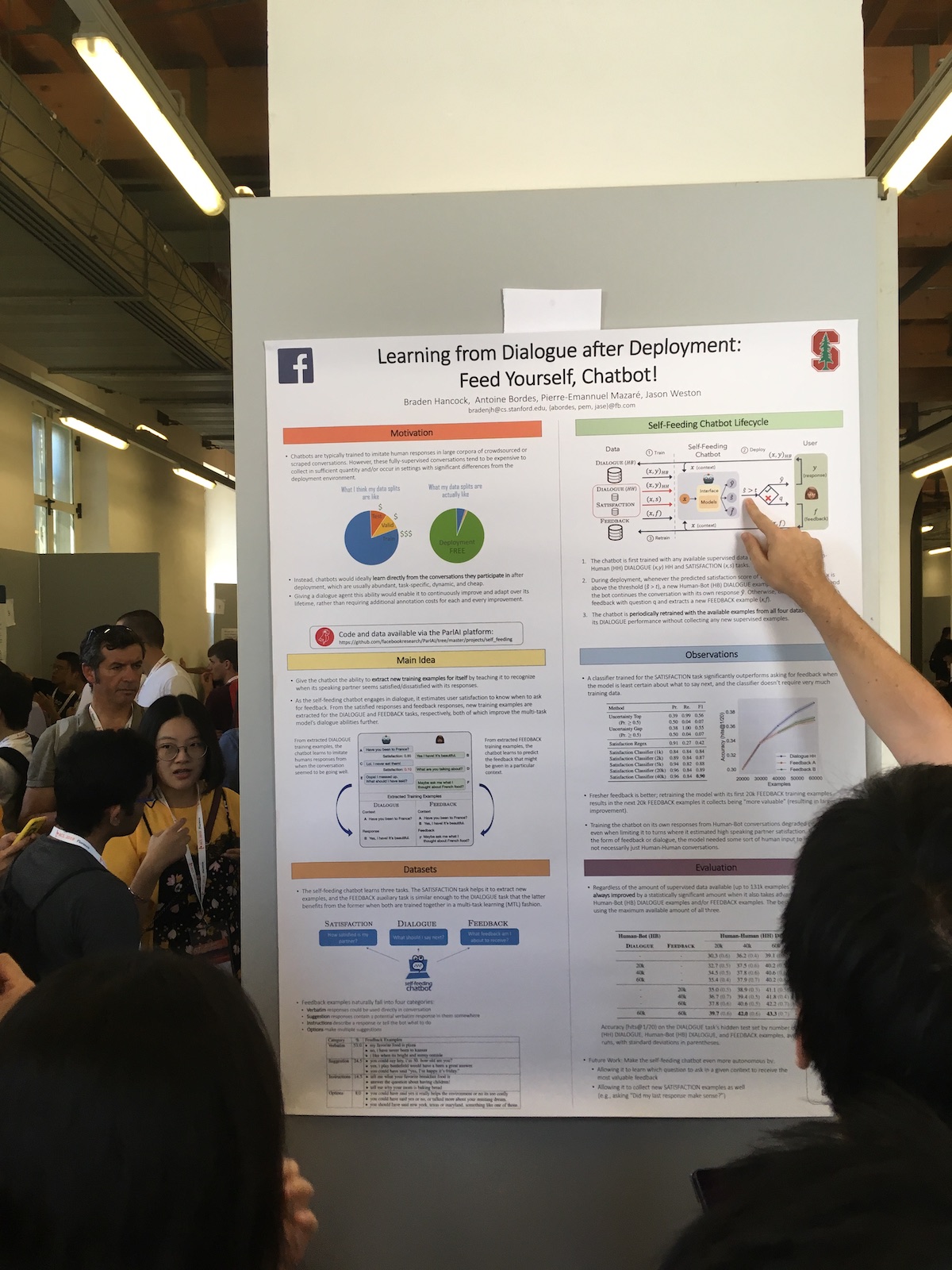
Dalam sesi poster, perusahaan besar sering menyajikan karya yang menarik. Sebagai contoh, inilah artikel Facebook
Belajar dari Dialog setelah Penempatan: Beri Makan Sendiri, Chatbot! .
Keunikan sistem mereka adalah perluasan penggunaan respons pengguna. Mereka memiliki classifier yang mengevaluasi seberapa puas pengguna dengan dialog. Mereka menggunakan informasi ini untuk tugas yang berbeda:
- Gunakan ukuran kepuasan sebagai metrik kualitas.
- Mereka melatih model, sehingga menerapkan pendekatan pembelajaran berkelanjutan (Continual Learning).
- Gunakan langsung dalam dialog. Ekspresikan beberapa reaksi manusia jika pengguna puas. Atau mereka bertanya apa yang salah jika pengguna tidak puas.
Dari laporan tersebut, ada cerita menarik tentang chatbot berbahasa Mandarin dari Microsoft.
Desain dan implementasi XiaoIce, chatbot sosial empatiChina sudah menjadi salah satu pemimpin dalam memperkenalkan teknologi kecerdasan buatan. Tetapi seringkali apa yang terjadi di Tiongkok tidak dikenal di Eropa. Dan XiaoIce adalah proyek yang luar biasa. Sudah ada selama lima tahun. Saat ini tidak banyak chatbot yang berfungsi. Pada 2018, sudah ada 660 juta pengguna.
Sistem ini memiliki bot chit-chat dan sistem keterampilan. Bot sudah memiliki 230 keterampilan, yaitu mereka menambahkan sekitar satu keterampilan per minggu.
Untuk menilai kualitas bot obrolan, mereka menggunakan durasi dialog. Dan tidak dalam hitungan menit, seperti yang sering dilakukan, tetapi dalam jumlah replika dalam percakapan. Mereka menyebut metrik ini Conversation-turns Per Session (CPS) dan menulis bahwa saat ini nilai rata-ratanya adalah 23, yang merupakan indikator terbaik di antara sistem yang sama.
Secara umum, proyek ini sangat populer di Cina. Selain bot itu sendiri, sistem menulis puisi, menggambar,
melepaskan koleksi pakaian , menyanyikan lagu.
Terjemahan mesin
Dari semua pidato yang saya hadiri, yang terindah adalah laporan
interpretasi simultan oleh Liang Huang, mewakili Baidu Research.
Dia berbicara tentang kesulitan-kesulitan seperti itu dalam terjemahan simultan modern:
- Hanya ada 3.000 penerjemah simultan bersertifikat di dunia.
- Penerjemah dapat bekerja hanya 15-20 menit terus menerus.
- Hanya sekitar 60% dari teks sumber diterjemahkan.
Terjemahan pada seluruh kalimat sudah mencapai tingkat yang baik, tetapi untuk terjemahan simultan masih ada ruang untuk perbaikan. Sebagai contoh, ia mengutip sistem penafsiran simultan mereka, yang bekerja di Baidu World Conference. Penundaan terjemahan pada tahun 2018 dibandingkan dengan 2017 berkurang dari 10 menjadi 3 detik.
Tidak banyak tim melakukan ini, dan ada beberapa sistem kerja yang ada. Misalnya, ketika Google menerjemahkan frasa yang Anda tulis secara online, frasa terakhir akan selalu dibuat ulang. Dan ini bukan terjemahan simultan, karena dengan terjemahan simultan kami tidak dapat mengubah kata-kata yang sudah dikatakan.

Dalam sistem mereka, mereka menggunakan terjemahan awalan - bagian dari frasa. Artinya, mereka menunggu beberapa kata dan mulai menerjemahkan, mencoba menebak apa yang akan muncul di sumber. Ukuran pergeseran ini diukur dalam kata-kata dan adaptif. Setelah setiap langkah, sistem memutuskan apakah perlu menunggu, atau apakah sudah bisa diterjemahkan. Untuk mengevaluasi keterlambatan ini, mereka memperkenalkan metrik berikut:
metrik Rata-Rata Tertinggal (AL) .
Kesulitan utama dengan terjemahan simultan adalah urutan kata yang berbeda dalam bahasa. Dan konteksnya membantu memerangi hal ini. Misalnya, Anda sering perlu menerjemahkan pidato-pidato politisi, dan mereka cukup stereotip. Namun ada juga masalah. Kemudian pembicara bercanda tentang Trump. Jadi, katanya, jika Bush terbang ke Moskow, maka sangat mungkin untuk bertemu dengan Putin. Dan jika Trump terbang, maka dia bisa bertemu dan bermain golf. Secara umum, ketika menerjemahkan, orang sering membuat, menambahkan sesuatu dari diri mereka sendiri. Dan katakanlah, jika Anda perlu menerjemahkan semacam lelucon, dan mereka tidak dapat langsung melakukannya, mereka dapat mengatakan: "Lelucon diucapkan di sini, tertawa saja."
Ada juga artikel tentang terjemahan mesin yang menerima penghargaan "The Best Long Paper":
Menjembatani Kesenjangan antara Pelatihan dan Inferensi untuk Terjemahan Mesin Saraf .
Ini menjelaskan masalah terjemahan mesin. Dalam proses pembelajaran, kami menghasilkan terjemahan kata demi kata berdasarkan konteks kata-kata yang dikenal. Dalam proses menggunakan model, kami mengandalkan konteks kata-kata yang baru dihasilkan. Ada perbedaan antara melatih model dan menggunakannya.
Untuk mengurangi perbedaan ini, penulis mengusulkan pada tahap pelatihan dalam konteks untuk mencampurkan kata-kata yang diprediksi oleh model dalam proses pelatihan. Artikel ini membahas pilihan optimal dari kata-kata yang dihasilkan tersebut.
Kesimpulan
Tentu saja, konferensi bukan hanya artikel dan laporan. Ini juga komunikasi, kencan dan jejaring lainnya. Selain itu, panitia konferensi berusaha menghibur para peserta. Di ACL, di pesta utama ada kinerja tenor, Italia. Dan untuk meringkas, ada pengumuman dari penyelenggara konferensi lainnya. Dan reaksi paling keras di antara para peserta disebabkan oleh pesan dari penyelenggara EMNLP bahwa tahun ini partai utama akan berada di Hong Kong Disneyland, dan pada tahun 2020 konferensi akan diadakan di Republik Dominika.