
Salah satu tugas terpenting dalam pembelajaran mesin adalah Deteksi Objek. Baru-baru ini, serangkaian algoritma pembelajaran mesin berdasarkan Deep Learning untuk deteksi objek telah diterbitkan. Algoritma ini menempati salah satu tempat sentral dalam aplikasi visi komputer praktis, khususnya, Mobil Self-Driving yang saat ini sangat populer. Tetapi semua metode ini adalah metode pengajaran dengan seorang guru, yaitu mereka membutuhkan dataset besar (dataset besar). Secara alami, ada keinginan untuk memiliki model yang mampu belajar dari data “mentah” (tidak terisi). Saya mencoba menganalisis metode yang ada dan juga menunjukkan kemungkinan cara pengembangannya. Saya bertanya kepada semua orang yang menginginkan belas kasihan di bawah kat, itu akan menarik.
Status pertanyaan saat ini
Secara alami, rumusan masalah ini telah ada sejak lama (hampir sejak hari-hari pertama keberadaan pembelajaran mesin) dan ada cukup banyak pekerjaan tentang topik ini. Misalnya, salah satu
Deteksi Objek Spasial Invariant Unsupervised favorit saya
dengan Convolutional Neural Networks . Singkatnya, penulis melatih Variable Auto Encoder (VAE), tetapi pendekatan ini menimbulkan sejumlah pertanyaan bagi saya.
Sedikit filosofi
Jadi apa objek dalam gambar? Untuk menjawab pertanyaan ini, kita harus menjawab pertanyaan - mengapa kita bahkan membagi dunia menjadi objek? Setelah sedikit merenungkan pertanyaan ini, saya hanya punya satu jawaban untuk pertanyaan ini (saya tidak mengatakan bahwa tidak ada yang lain, saya hanya tidak menemukan mereka) - kami berusaha menemukan representasi dunia yang mudah bagi kami untuk memahami dan mengendalikan jumlah informasi yang diperlukan untuk menggambarkan dunia. dalam konteks tugas saat ini. Misalnya, untuk tugas mengklasifikasikan gambar (yang umumnya diformulasikan secara tidak benar - jarang ada gambar dengan satu objek. Yaitu, kami memecahkan masalah bukan apa yang ditampilkan dalam gambar, tetapi objek mana yang "utama"), kita hanya perlu mengatakan bahwa gambar itu adalah "mobil" , pada gilirannya, untuk tugas mendeteksi objek, kita ingin tahu objek "menarik" apa (kita tidak tertarik dengan semua daun dari pohon di gambar) di sana, dan di mana mereka, untuk tugas menggambarkan adegan, kita ingin mendapatkan nama proses "menarik" itu terjadi di sana, misalnya, "matahari terbenam", dll.
Ternyata objek adalah representasi data yang nyaman. Properti apa yang harus dimiliki representasi ini? Tampilan harus memuat sebanyak mungkin informasi lengkap tentang gambar. Yaitu memiliki deskripsi objek, kami ingin dapat mengembalikan gambar asli dengan tingkat akurasi yang diperlukan.
Bagaimana ini bisa diekspresikan secara matematis? Bayangkan bahwa gambar tersebut adalah realisasi dari variabel acak X, dan representasi akan menjadi realisasi dari variabel acak Y. Dalam pandangan di atas, kami ingin Y memuat sebanyak mungkin informasi tentang X. Secara alami, untuk melakukan ini, gunakan konsep informasi timbal balik.
Model pembelajaran mesin untuk informasi maksimum
Deteksi objek dapat dianggap sebagai model generatif, yang menerima gambar pada input
, dan output adalah representasi objek dari gambar
.

Sekarang mari kita ingat rumus untuk menghitung informasi bersama:
dimana
distribusi kepadatan bersama juga
terpinggirkan.
Di sini saya tidak akan menjelaskan mengapa rumus ini terlihat seperti ini, tetapi kami akan percaya bahwa secara internal itu sangat logis. Ngomong-ngomong, berdasarkan pertimbangan yang diuraikan, tidak perlu memilih informasi timbal balik yang tepat, itu bisa berupa "informasi" lainnya, tetapi kami akan kembali ke tahap ini lebih dekat hingga akhir.
Terutama perhatian (atau mereka yang membaca buku tentang teori informasi) telah memperhatikan bahwa informasi timbal balik tidak lebih dari perbedaan Kullback-Lebler antara distribusi bersama dan karya yang marjinal. Di sini muncul sedikit komplikasi - siapa pun yang telah membaca setidaknya beberapa buku tentang pembelajaran mesin tahu bahwa jika kita hanya memiliki sampel dari dua distribusi (mis. Kita tidak tahu fungsi distribusi), maka itu bahkan tidak optimal, tetapi bahkan mengevaluasi perbedaan Kullback, Tugas Leibler sangat tidak sepele. Selain itu, GAN tercinta kami lahir justru karena alasan ini.
Untungnya, ide bagus untuk menggunakan batas variasional yang lebih rendah yang dijelaskan dalam
On Variational Bounds of Mutual Information datang ke bantuan kami. Informasi timbal balik dapat direpresentasikan sebagai:
Atau
dimana
- distribusi representasi untuk gambar yang diberikan, parametrized oleh jaringan saraf kami dan dari distribusi ini kami dapat sampel, tetapi kami tidak perlu dapat memperkirakan kepadatan atau probabilitas sampel tertentu (yang umumnya khas dari banyak model generatif).
Adalah fungsi kepadatan tertentu yang ditentukan oleh jaringan saraf kedua (dalam kasus paling umum, kita membutuhkan 2 jaringan saraf, meskipun dalam beberapa kasus mereka dapat diwakili oleh yang pertama), di sini kita harus dapat menghitung probabilitas sampel yang dihasilkan.
Nilai
disebut Batas Variatif Bawah.
Sekarang kita dapat memecahkan pendekatan untuk masalah kita, yaitu, untuk meningkatkan bukan informasi timbal balik itu sendiri, tetapi batas variasional yang lebih rendah. Jika distribusinya
dipilih dengan benar, maka pada titik maksimum batas variasional dan informasi timbal balik akan bertepatan, tetapi dalam kasus praktis (ketika distribusi
tidak bisa membayangkan dengan tepat
, tetapi terdiri dari keluarga fungsi yang cukup besar) akan sangat dekat, yang juga cocok untuk kita.
Jika seseorang tidak tahu bagaimana ini bekerja, saya menyarankan Anda untuk hati-hati mempertimbangkan algoritma EM. Ini kasus yang sangat mirip.
Apa yang sedang terjadi di sini? Bahkan, kami mendapat fungsionalitas untuk melatih pembuat kode otomatis. Jika Y adalah hasil pada output dari jaringan saraf dengan beberapa gambar di input, maka ini berarti
dimana
fungsi transformasi jaringan saraf. Dan perkirakan distribusi terbalik oleh Gaussian, mis.
kami mendapatkan:
Dan ini adalah fitur klasik untuk pembuat enkode otomatis.
Pengkode Otomatis tidak cukup
Saya pikir banyak yang sudah ingin melatih auto-encoder dan berharap bahwa di lapisan tersembunyi akan ada neuron yang merespons objek tertentu. Secara umum, ada konfirmasi tentang sesuatu yang serupa dan ternyata
Membangun Fitur Tingkat Tinggi Menggunakan Pembelajaran Tanpa pengawasan Skala Besar . Tapi tetap saja ini sama sekali tidak praktis. Dan orang-orang yang paling penuh perhatian telah memperhatikan bahwa penulis artikel ini menggunakan regularisasi - mereka menambahkan sebuah istilah yang memberikan tingkat kepedihan pada lapisan tersembunyi, dan mereka menulis dalam warna hitam dan putih bahwa tidak ada yang terjadi tanpa istilah ini.
Apakah prinsip memaksimalkan informasi timbal balik cukup untuk mempelajari ide "nyaman"? Jelas tidak, karena kita dapat memilih Y sama dengan X (yaitu, menggunakan gambar itu sendiri sebagai representasi) atau transformasi bijektif apa pun, informasi timbal balik menjadi tak terhingga dalam kasus ini. Tidak ada lagi nilai ini, tetapi seperti yang kita tahu ini adalah ide yang sangat buruk.
Kami membutuhkan kriteria tambahan untuk "kenyamanan" presentasi. Para penulis artikel di atas menganggap sparseness sebagai "kenyamanan." Ini adalah semacam realisasi dari hipotesis bahwa harus ada beberapa "objek penting" dalam gambar. Tapi kita akan melangkah lebih jauh - kita ingin tidak hanya mempelajari fakta bahwa objek seperti itu ada dalam gambar, tetapi juga ingin tahu di mana benda itu, berapa banyak itu tumpang tindih, dll. Muncul pertanyaan, bagaimana membuat jaringan saraf menginterpretasikan output dari neuron seperti, misalnya, koordinat suatu objek? Jawabannya jelas - output dari neuron ini harus digunakan dengan tepat untuk ini. Artinya, mengetahui idenya, kita harus dapat menghasilkan gambar "mirip" dengan yang asli.
Gagasan umum dipinjam dari orang-orang dari Facebook.
Encoder akan terlihat seperti ini:

dimana
- beberapa vektor yang menggambarkan objek,
- koordinat objek,
- skala objek,
- posisi objek secara mendalam,
- probabilitas bahwa objek tersebut ada.
Yaitu, jaringan saraf input menerima gambar dengan ukuran yang telah ditentukan di mana kami ingin menemukan objek dan mengeluarkan array deskripsi. Jika kita menginginkan jaringan single-pass, maka sayangnya array ini harus berukuran tetap. Jika kita ingin menemukan semua objek, maka kita harus menggunakan jaringan rekrutmen.
Dekoder akan seperti ini:
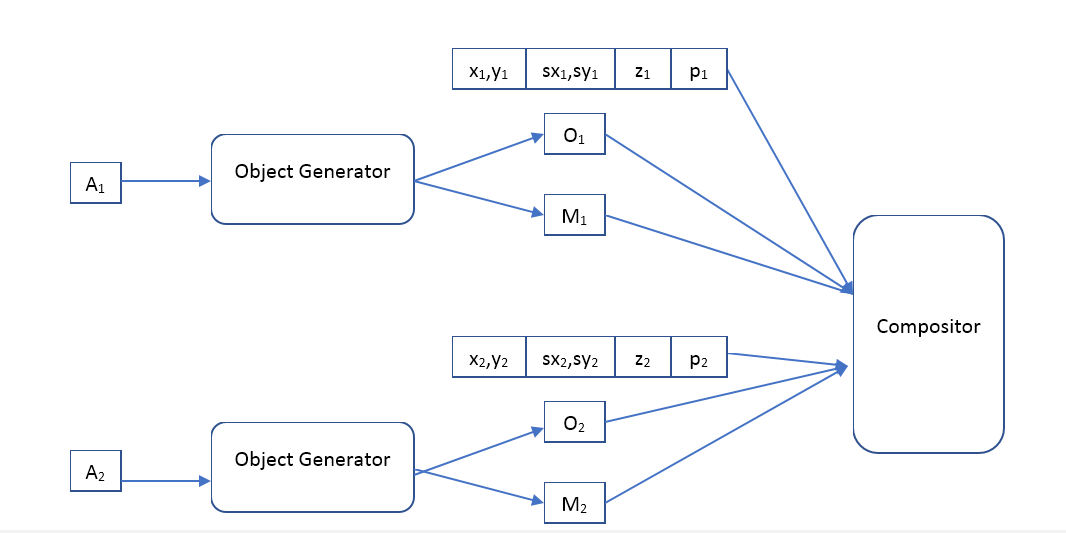
Di mana Object Generator adalah jaringan yang menerima vektor deskripsi objek pada input dan memberi
- gambar (ukuran standar tertentu) dari objek dan topeng piksel buram (topeng opacity).
Kompositor - menerima gambar input dari semua objek, mask, posisi, skala, kedalaman, dan membentuk gambar output, yang harus serupa dengan aslinya.
Apa perbedaan antara pendekatan kami dan VAE?
Tampaknya kita ingin menggunakan auto-encoder dengan arsitektur yang sama dengan penulis artikel
Deteksi Objek Tidak Terduga Spasial Invarian dengan Neural Networks Konvolusional , jadi pertanyaannya adalah apa bedanya. Baik di sana dan di sana autoencoder, hanya di versi kedua itu variasional.
Dari sudut pandang teoretis, perbedaannya sangat besar. VAE adalah model generatif dan tugasnya adalah membuat 2 distribusi (gambar awal dan yang dihasilkan) semirip mungkin. Secara umum, VAE tidak membuat jaminan bahwa gambar yang dihasilkan dari "deskripsi" objek yang dihasilkan dari gambar asli akan setidaknya sedikit mirip dengan aslinya. Omong-omong, penulis VAE
Auto-Encoding Variational Bayes sendiri berbicara tentang ini. Jadi mengapa masih bekerja? Saya berpikir bahwa arsitektur yang dipilih dari jaringan saraf dan "deskripsi" membantu untuk meningkatkan informasi timbal balik dari gambar dan "deskripsi", tetapi saya tidak dapat menemukan bukti matematika untuk hipotesis ini. Sebuah pertanyaan untuk pembaca, dapatkah seseorang menjelaskan hasil penulisnya - gambar yang dipulihkan sangat mirip dengan aslinya, mengapa?
Selain itu, penggunaan VAE memaksa penulis untuk menentukan distribusi "deskripsi," dan metode memaksimalkan informasi timbal balik tidak membuat asumsi tentang hal ini. Yang memberi kita kebebasan tambahan, misalnya, kita dapat mencoba mengelompokkan vektor pada model yang sudah terlatih
deskripsi, dan lihat - mungkin sistem seperti itu akan mempelajari kelas objek? Perlu dicatat bahwa pengelompokan seperti itu menggunakan VAE tidak masuk akal, misalnya, penulis artikel menggunakan distribusi Gaussian untuk vektor-vektor ini.
Eksperimennya
Sayangnya, sekarang pekerjaan membutuhkan banyak waktu dan tidak mungkin untuk menyelesaikannya dalam jumlah waktu yang dapat diterima. Jika seseorang ingin menulis beberapa ribu baris kode, latih ratusan model pembelajaran mesin dan lakukan banyak eksperimen menarik, hanya karena itu memberinya kesenangan - saya akan senang bergabung. Menulis secara pribadi.
Bidang percobaan di sini sangat luas. Saya memiliki rencana untuk memulai dengan melatih autkodeer klasik (pemetaan deterministik gambar ke deskripsi dan distribusi terbalik Gaussian) dan melihat apa yang dipelajarinya. Dalam percobaan pertama, akan cukup menggunakan komposer yang dijelaskan oleh orang-orang dari Facebook, tetapi di masa depan saya pikir akan sangat menarik untuk bermain dengan berbagai komposer, dan dimungkinkan untuk membuatnya juga bisa dipelajari. Bandingkan berbagai regulator: tanpa itu, Jarang, dll. Bandingkan penggunaan model feedforward dan rekursif. Kemudian gunakan model distribusi yang lebih maju untuk distribusi terbalik, misalnya,
estimasi Density menggunakan Real NVP . Lihat bagaimana lebih baik atau lebih buruk dengan model yang lebih fleksibel. Lihat apa yang akan terjadi jika tampilan gambar pada deskripsi dibuat non-deterministik (dihasilkan dari beberapa distribusi bersyarat). Dan akhirnya, coba terapkan berbagai metode pengelompokan untuk menggambarkan vektor
dan memahami apakah sistem seperti itu dapat mempelajari kelas objek.
Tetapi yang paling penting, saya benar-benar ingin membandingkan kualitas model berdasarkan memaksimalkan saling informasi dan model dengan VAE.