Data deret waktu atau deret waktu adalah data yang berubah seiring waktu. Kutipan mata uang, telemetri pergerakan transportasi, statistik akses server atau beban CPU adalah data deret waktu. Untuk menyimpannya membutuhkan alat khusus - basis data temporal. Ada puluhan alat, misalnya, InfluxDB atau ClickHouse. Tetapi bahkan solusi penyimpanan seri waktu terbaik pun memiliki kekurangan. Semua penyimpanan deret waktu adalah tingkat rendah, hanya cocok untuk data deret waktu, dan menjalankan dan menyuntikkan ke tumpukan saat ini adalah mahal dan menyakitkan.

Tetapi, jika Anda memiliki tumpukan PostgreSQL, Anda bisa melupakan InfluxDB dan semua basis data temporal lainnya. Instal dua ekstensi, TimescaleDB dan PipelineDB, dan simpan, proses, dan analisis data deret waktu secara langsung di ekosistem PostgreSQL. Tanpa pengenalan solusi pihak ketiga, tanpa kerugian penyimpanan sementara dan tanpa masalah menjalankannya. Apa ekstensi ini, apa kelebihan dan kemampuannya, akan memberi tahu
Ivan Muratov ( binakot ) - kepala departemen pengembangan di "Perusahaan Pemantau Pertama".
Apa itu data deret waktu atau deret waktu?
Ini adalah data tentang proses yang dikumpulkan di berbagai titik dalam hidupnya.
Misalnya, lokasi mobil: kecepatan, koordinat, arah, atau penggunaan sumber daya di server dengan data pada beban pada CPU, menggunakan RAM dan ruang disk kosong.
Rangkaian waktu memiliki beberapa fitur.
- Di tali pengikat . Setiap catatan seri waktu memiliki bidang dengan cap waktu di mana nilai tersebut dicatat.
- Karakteristik proses, yang disebut level seri : kecepatan, koordinat, memuat data.
- Hampir selalu dengan data seperti itu mereka bekerja dalam mode append-only . Ini berarti bahwa data baru tidak menggantikan yang lama. Hanya data yang usang yang dihapus.
- Entri tidak dianggap terpisah satu sama lain . Data hanya digunakan secara kolektif untuk jendela waktu, interval atau periode.
Solusi penyimpanan populer
Grafik yang saya ambil dari
db-engines.com menunjukkan popularitas berbagai model penyimpanan selama dua tahun terakhir.
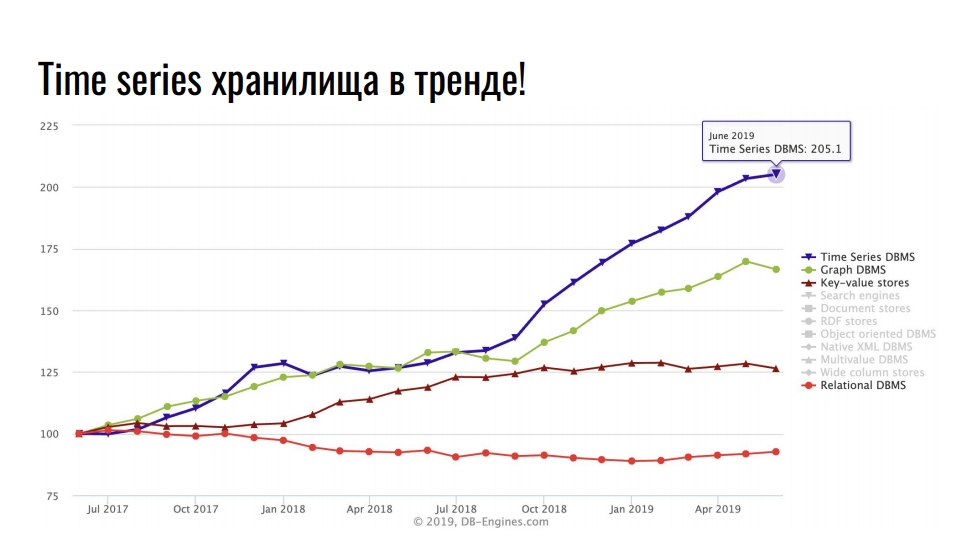
Posisi terdepan ditempati oleh penyimpanan deret waktu, di tempat kedua - basis data grafik, lalu - nilai kunci dan basis data relasional. Popularitas repositori khusus dikaitkan dengan pertumbuhan intensif dalam integrasi teknologi informasi: Big Data, jejaring sosial, IoT, pemantauan infrastruktur beban tinggi. Selain data bisnis yang bermanfaat, bahkan log dan metrik juga menghabiskan banyak sumber daya.
Solusi penyimpanan populer untuk data deret waktu
Grafik menunjukkan solusi khusus untuk menyimpan data deret waktu. Skala tersebut adalah logaritmik.
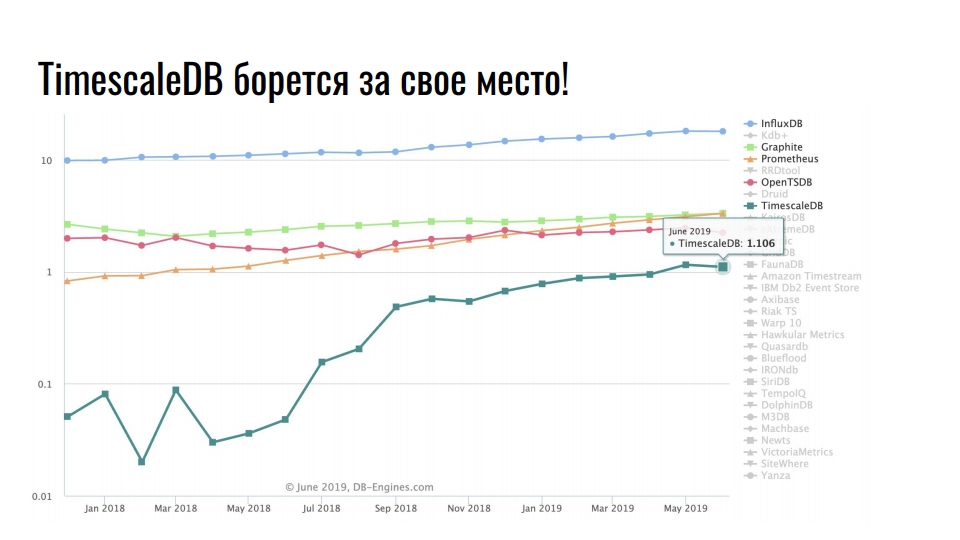
Pemimpin stabil InfluxDB. Setiap orang yang telah menemukan data deret waktu telah mendengar tentang produk ini. Tetapi grafik menunjukkan peningkatan sepuluh kali lipat dalam TimescaleDB - perpanjangan untuk DBMS relasional berjuang untuk tempat di bawah matahari di antara produk yang awalnya dikembangkan di bawah seri waktu.
PostgreSQL tidak hanya database yang baik, tetapi juga platform yang dapat dikembangkan untuk mengembangkan solusi khusus.
Postgres, Postgis, dan TimescaleDB
Perusahaan Pemantau Pertama memonitor pergerakan kendaraan menggunakan satelit. Kami melacak 20.000 kendaraan dan menyimpan data pergerakan selama dua tahun. Secara total, kami memiliki 10 TB data telemetri saat ini. Rata-rata, setiap kendaraan mengirim 5 catatan telemetri per menit saat mengemudi. Data dikirim melalui peralatan navigasi ke server telematik kami. Mereka menerima 500 paket navigasi per detik.
Beberapa waktu lalu, kami memutuskan untuk meningkatkan infrastruktur secara global dan beralih dari monolit ke layanan mikro. Kami menyebut sistem baru Waliot, dan sudah dalam produksi - 90% dari semua kendaraan dipindahkan ke sana.
Banyak yang telah berubah dalam infrastruktur, tetapi tautan sentral tetap tidak berubah - ini adalah database PostgreSQL. Sekarang kami sedang mengerjakan versi 10 dan sedang bersiap untuk pindah ke 11. Selain PostgreSQL, sebagai penyimpanan utama, dalam tumpukan kami menggunakan PostGIS untuk komputasi geospasial, dan TimescaleDB untuk menyimpan sejumlah besar data deret waktu.
Mengapa PostgreSQL?
Mengapa kami mencoba menggunakan database relasional untuk menyimpan seri waktu, daripada
ClickHouse solusi khusus untuk tipe data ini? Karena dengan latar belakang akumulasi keahlian dan kesan bekerja dengan PostgreSQL, kami tidak ingin menggunakan solusi yang tidak dikenal sebagai penyimpanan utama.
Beralih ke solusi baru adalah risiko.
Ada banyak solusi khusus untuk menyimpan dan memproses data deret waktu. Dokumentasi tidak selalu cukup, dan banyak pilihan solusi tidak selalu baik. Tampaknya para pengembang dari setiap produk baru ingin menulis semuanya dari awal, karena ada sesuatu yang tidak menyenangkan dalam solusi sebelumnya. Untuk memahami apa yang sebenarnya tidak disukai, Anda harus mencari informasi, menganalisis, dan membandingkan. Berbagai variasi
peringkat ,
peringkat , dan
perbandingan lebih menakutkan daripada memotivasi untuk mencoba sesuatu. Anda harus menghabiskan banyak waktu untuk mencoba semua solusi pada diri Anda sendiri. Kami tidak mampu mengadaptasi hanya satu solusi selama beberapa bulan. Ini adalah tugas yang sulit, dan waktu yang dihabiskan tidak akan pernah berhasil. Karena itu, kami telah memilih ekstensi untuk PostgreSQL.
Selama fase pengembangan infrastruktur Waliot, kami menganggap InfluxDB sebagai repositori telemetri utama. Tetapi ketika saya menemukan TimescaleDB dan menjalankan tes di sana, tidak ada pertanyaan tentang pilihan. PostgreSQL dengan ekstensi TimescaleDB memungkinkan Anda untuk menggunakan ekstensi lain dalam penyimpanan PostGIS atau PipelineDB yang sama. Kami tidak perlu mengeluarkan data, mentransformasikan, melakukan analisis, dan mentransfernya melalui jaringan. Semuanya terletak pada satu server atau dalam sistem cluster - data tidak perlu diseret. Semua perhitungan dilakukan pada level yang sama.
Baru-baru ini,
Nikolay Samokhvalov , penulis akun postgresmen,
menerbitkan tautan ke artikel menarik tentang penggunaan SQL untuk streaming pemrosesan data. Lima dari enam penulis artikel berpartisipasi dalam pengembangan berbagai produk Apache dan bekerja dengan pemrosesan aliran. Oleh karena itu, artikel tersebut menyebutkan Apache Spark, Apache Flink, Apache Beam, Apache Calcite dan KSQL dari Confluent.
Tapi bukan artikel itu sendiri yang menarik, tetapi
topik tentang Hacker News , di mana itu dibahas. Penulis topik menulis bahwa, berdasarkan artikel tersebut, ia menerapkan hampir semua ide berdasarkan PostgreSQL 11. Dia menggunakan ekstensi CitusDB untuk penskalaan dan sharding horizontal, PipelineDB untuk komputasi aliran dan tampilan terwujud, TimescaleDB untuk menyimpan data deret waktu dan pembagian. Dia juga menggunakan beberapa Pembungkus Data Asing.
Gabungan gila PostgreSQL dan ekstensi sekali lagi menegaskan bahwa PostgreSQL bukan hanya DBMS - itu adalah platform.
Dan kapan penyimpanan pluggable akan dikirimkan ... Ugh!
Ironisnya, ketika meneliti solusi, kami menemukan
Outflux , pengembangan tim TimescaleDB, yang mereka terbitkan pada 1 April. Menurutmu apa yang dia lakukan? Ini adalah utilitas untuk bermigrasi dari InfluxDB ke TimescaleDB dalam satu perintah ...
Sensasi postgres!
Jangan meremehkan kekuatan hype! Kami sering bercanda bahwa "pembangunan didorong oleh hype," karena hal itu memengaruhi persepsi kami tentang komponen penyempurnaan dan infrastruktur. Di
HighLoad ++, kami banyak membahas PostgreSQL, ClickHouse, Tarantool - ini adalah perkembangan hype. Hanya saja jangan katakan bahwa itu tidak mempengaruhi preferensi Anda dan pilihan solusi untuk infrastruktur ... Tentu saja, ini bukan faktor utama, tetapi apakah ada pengaruhnya?
Saya telah bekerja dengan PostgreSQL selama 5 tahun. Saya suka solusi ini. Dia menyelesaikan hampir semua tugas saya dengan keras. Setiap kali ada yang salah dengan pangkalan ini, tangan saya yang bengkok harus disalahkan. Karena itu, pilihannya sudah ditentukan sebelumnya.
TimescaleDB VS PipelineDB
Mari kita beralih ke ekstensi TimescaleDB dan PipelineDB. Apa yang dikatakan pembuatnya tentang ekstensi?
TimescaleDB adalah database seri waktu sumber terbuka yang dioptimalkan untuk penyisipan cepat dan kueri kompleks.
PipelineDB adalah ekstensi berkinerja tinggi yang dirancang untuk menjalankan kueri SQL berkelanjutan
untuk data deret waktu .
Selain bekerja dengan data deret waktu, mereka memiliki cerita serupa. Timescale didirikan pada 2015, dan Pipeline pada 2013. Versi kerja pertama muncul masing-masing pada 2017 dan 2015. Butuh waktu dua tahun bagi tim untuk merilis fungsionalitas minimum. Rilis produksi kedua ekstensi berlangsung Oktober lalu dengan perbedaan satu minggu. Rupanya, terburu-buru satu sama lain.
GitHub memiliki banyak bintang dan garpu, yang, seperti biasa, tidak memiliki komitmen tunggal. Begitulah cara kerja Open Source, tidak ada yang bisa dilakukan. Tetapi ada banyak bintang,
TimescaleDB memiliki lebih dari
PipelineDB , dan bahkan lebih dari PostgreSQL itu sendiri.
Ekstensi tampaknya serupa, tetapi posisinya berbeda.
TimescaleDB mengklaim telah menyisipkan jutaan catatan per detik dan menyimpan ratusan miliar baris dan puluhan terabyte data. Ekstensi lebih cepat dari InfluxDB, Cassandra, MongoDB atau vanilla PostgreSQL. Mendukung replikasi streaming dan alat cadangan. TimescaleDB adalah ekstensi, bukan fork dari PostgreSQL.
PipelineDB hanya menyimpan hasil perhitungan streaming, tanpa perlu menyimpan data mentah untuk perhitungan mereka. Ekstensi ini mampu melakukan agregasi terus-menerus melalui aliran data waktu-nyata, digabungkan dengan tabel konvensional untuk perhitungan dalam konteks domain domain. PipelineDB adalah ekstensi, bukan garpu, tetapi pada awalnya itu adalah garpu.
Timescaledb
Sekarang secara rinci tentang ekstensi. Mari kita mulai dengan TimescaleDB. Saya telah bekerja dengannya selama hampir 2 tahun. Menyeretnya ke produksi sebelum versi rilis. Mari kita lihat contoh bagaimana menerapkannya.
Penyimpanan untuk metrik infrastruktur . Kami memiliki metrik konsumsi sumber daya wadah Docker, waktu komitmen metrik, pengidentifikasi wadah, dan bidang konsumsi sumber daya, misalnya, memori bebas. Kita perlu menampilkan statistik untuk semua wadah dengan jumlah rata-rata jendela memori gratis selama 10 detik. Kueri yang Anda lihat memecahkan masalah ini dan TimescaleDB dapat digunakan sebagai repositori untuk metrik infrastruktur.
SELECT time_bucket('10 seconds', time) AS period, container_id, avg(free_mem) FROM metrics WHERE time < now() - interval '10 minutes' GROUP BY period, container_id ORDER BY period DESC, container_id;
period | container_id | avg -----------------------+--------------+--- 2019-06-24 12:01:00+00 | 16 | 72202 2019-06-24 12:01:00+00 | 73 | 837725 2019-06-24 12:01:00+00 | 96 | 412237 2019-06-24 12:00:50+00 | 16 | 1173393 2019-06-24 12:00:50+00 | 73 | 90104 2019-06-24 12:00:50+00 | 96 | 784596
Untuk perhitungan . Kita perlu menghitung jumlah truk yang meninggalkan Krasnodar dan total tonasinya per hari.
SELECT time_bucket('1 day', time) AS day, count(*) AS trucks_exiting, sum(weight) / 1000 AS tonnage FROM vehicles INNER JOIN cities ON cities.name = 'Krasnodar' WHERE ST_Within(last_location, ST_Polygon(cities.geom, 4326)) AND NOT ST_Within(current_location, ST_Polygon(cities.geom, 4326)) GROUP BY day ORDER BY day DESC LIMIT 3;
Itu juga menggunakan fungsi dari ekstensi PostGIS untuk menghitung transportasi yang meninggalkan kota, bukan hanya bergerak di dalamnya.
Pemantauan nilai tukar mata uang . Contoh ketiga adalah tentang cryptocurrency. Permintaan memungkinkan Anda untuk menampilkan bagaimana harga Ethereum telah berubah relatif terhadap Bitcoin dan dolar Amerika selama 2 minggu terakhir per hari.
SELECT time_bucket('14 days', c.time) AS period, last(c.closing_price, c.time) AS closing_price_btc, last(c.closing_price, c.time) * last(b.closing_price, c.time) filter (WHERE b.currency_code = 'USD') AS closing_price_usd FROM crypto_prices c JOIN btc_prices b ON time_bucket('1 day', c.time) = time_bucket('1 day', b.time) WHERE c.currency_code = 'ETH' GROUP BY period ORDER BY period DESC;
Ini semua sama jelas dan nyaman bagi kita SQL.
Apa yang keren tentang TimescaleDB?
Mengapa tidak menggunakan alat partisi tabel bawaan? Dan mengapa repot-repot memecahkan meja? Jawaban yang jelas adalah
kecepatan penyisipan dalam database seperti itu . Grafik menunjukkan pengukuran aktual tingkat penyisipan jumlah baris per detik antara tabel vanilla reguler PostgreSQL 10 tanpa sectioning, dan TimescaleDB hipertensi.
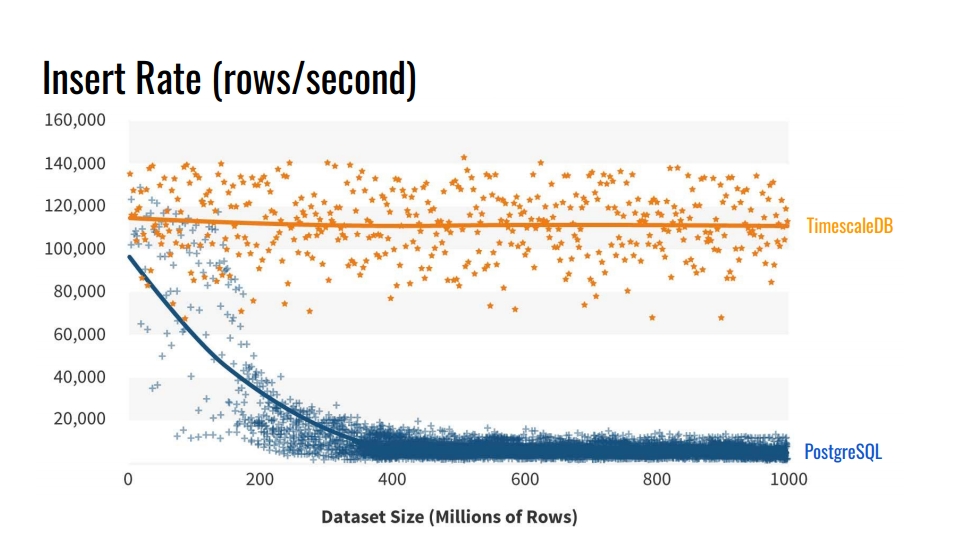
Patokan ini menulis 1 miliar baris pada satu mesin, mensimulasikan skenario untuk mengumpulkan metrik dari infrastruktur. Catatan berisi waktu, pengidentifikasi komponen infrastruktur, dan 10 metrik. Benchmark dijalankan pada Azure VM dengan 8 core dan 28 gigabytes RAM, serta drive SSD jaringan. Penyisipan dilakukan dalam batch 10 ribu catatan.
Dari manakah penurunan kinerja PostgreSQL tersebut? Karena ketika Anda memasukkan, Anda juga perlu memperbarui indeks tabel. Ketika mereka tidak masuk ke dalam cache, kami mulai memuat disk. Partisi menyelesaikan masalah ini jika indeks bagian tempat kami memasukkan data ditempatkan dalam RAM.
Mari kita lihat tabel berikut. Ini membandingkan sistem partisi deklaratif yang dibangun ke dalam PostgreSQL 10 dan tabel hyperc TimescaleDB. Pada sumbu horizontal, jumlah bagian.
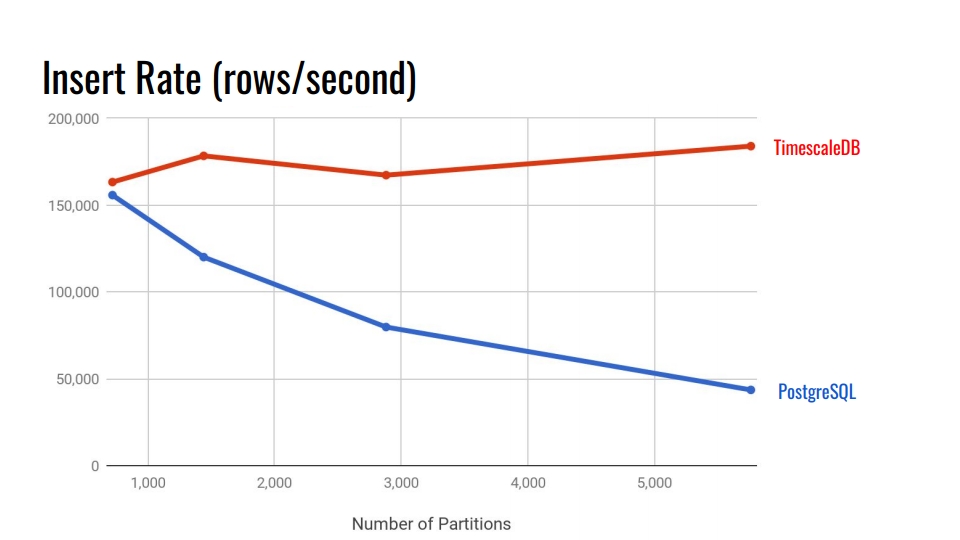
Dalam TimescaleDB, degradasi dapat diabaikan dengan meningkatnya bagian. Pengembang ekstensi mengklaim bahwa mereka baik-baik saja dengan 10.000 bagian dalam satu contoh PostgreSQL.
Dalam PostgreSQL, implementasi asli menurun secara signifikan setelah 3.000. Secara umum, partisi deklaratif dalam PostgreSQL adalah langkah besar ke depan, tetapi hanya berfungsi dengan baik untuk tabel dengan beban lebih sedikit. Misalnya, untuk barang, pembeli, dan entitas domain lain yang memasuki sistem tidak seintensif metrik.
Dalam 11 dan 12 versi PostgreSQL, dukungan partisi asli akan muncul dan Anda dapat mencoba menjalankan tes komparatif untuk data deret waktu dengan versi baru. Tapi, menurut saya TimescaleDB masih lebih baik. Semua tolok ukur dari TimescaleDB dapat ditemukan di
github mereka dan coba.
Fitur utama
Saya harap Anda sudah memiliki minat pada ekstensi. Mari kita membahas fitur utama TimescaleDB untuk mengkonsolidasikan perasaan ini.
Partisi melalui hipertensi . TimescaleDB menggunakan istilah "hypertable" untuk tabel di mana fungsi create_hypertable () telah diterapkan. Setelah itu, tabel akan menjadi induk untuk semua bagian yang diwarisi - potongan. Tabel induk itu sendiri tidak akan berisi data apa pun, tetapi akan menjadi titik masuk untuk semua kueri dan templat ketika secara otomatis membuat bagian baru. Semua bagian disimpan bukan dalam skema utama data Anda, tetapi dalam skema khusus. Ini nyaman karena kami tidak melihat ribuan bagian ini dalam skema data.
Ekstensi diintegrasikan ke penjadwal dan pelaksana kueri . Melalui kait khusus di PostgreSQL, TimescaleDB memahami ketika mengakses sebuah hipertensi. TimescaleDB menganalisis kueri dan mengarahkan kueri hanya ke bagian yang diperlukan berdasarkan kondisi yang ditentukan dalam panggilan SQL itu sendiri. Ini memungkinkan Anda untuk memparalelkan pekerjaan dengan bagian selama ekstraksi sejumlah besar data.
Ekstensi tidak memberlakukan batasan pada SQL . Anda dapat dengan bebas menggunakan serikat pekerja, agregat, fungsi jendela, CTE dan indeks tambahan. Jika Anda melihat daftar pembatasan untuk sistem partisi bawaan, ini seharusnya menyenangkan Anda.
Fitur berguna tambahan khusus untuk data deret waktu:
- "Time_bucket" - "date_trun" dari orang sehat;
- histogram - mengisi interval yang terlewat menggunakan interpolasi atau nilai terakhir yang diketahui;
- pekerja latar belakang - layanan yang memungkinkan Anda untuk melakukan operasi latar belakang: membersihkan bagian-bagian lama, mengatur ulang.
TimescaleDB memungkinkan Anda untuk tetap berada di ekosistem PostgreSQL yang kuat . Ekstensi ini tidak merusak PostgreSQL, oleh karena itu semua solusi Ketersediaan Tinggi, sistem cadangan, alat pemantauan akan terus bekerja. TimescaleDB berteman dengan Grafana, Periscope, Prometheus, Telegraf, Zabbix, Kubernetes, Kafka, Seeq, JackDB.
Grafana sudah memiliki dukungan asli untuk TimescaleDB sebagai sumber data. Grafana memahami bahwa PostscreSQL memiliki TimescaleDB. Pembuat kueri di Grafana di dasbor memahami fungsi TimescaleDB tambahan, seperti "time_bucket", "pertama", "terakhir". Anda dapat membuat grafik langsung dari database relasional dengan fungsi deret waktu ini tanpa permintaan raksasa.
Prometheus memiliki adaptor yang memungkinkan Anda untuk menggabungkan data darinya dan menggunakan TimescaleDB sebagai gudang data yang dapat diandalkan. Gunakan adaptor untuk tidak menyimpan data di Prometheus selama bertahun-tahun.
Ada juga
plugin Telegraf . Solusinya memungkinkan Anda untuk menghapus Prometheus sepenuhnya. Data infrastruktur segera ditransfer ke TimescaleDB dan dibaca melalui Telegraf.
Lisensi dan Berita
Belum lama ini, perusahaan beralih ke model lisensi baru. Sebagian besar kode dilisensikan di bawah Apache 2.0. Sebagian kecil gratis untuk digunakan, tetapi dilisensikan di bawah TSL.
Ada versi Perusahaan dengan lisensi komersial. Jangan khawatir, tidak semua barang dalam versi Enterprise. Pada dasarnya ada otomatisasi seperti penghapusan otomatis potongan usang, yang dapat dilakukan melalui "cron" sederhana dan hal-hal serupa.
Sekarang perusahaan secara aktif mengerjakan solusi cluster. Mungkin itu akan jatuh ke versi Enterprise. Ada juga versi cloud untuk pemula yang ingin mengelola untuk memasuki pasar sebelum investor kehabisan uang.
Dari berita:
- satu juta unduhan selama setengah tahun terakhir;
- Investasi $ 31 juta;
- Kolaborasi aktif dengan MS Azure mengenai solusi IoT.
Untuk meringkas
TimescaleDB dirancang untuk menyimpan data deret waktu. Ini adalah sistem partisi yang kuat dengan batasan minimal dibandingkan dengan yang asli di PostgreSQL.
Sayangnya, ekstensi belum memiliki versi multinode. Jika Anda ingin multimaster atau beling, Anda harus bermain-main, misalnya dengan CitusDB. Jika Anda ingin replikasi logis, itu akan menyakitkan. Tapi itu selalu menyakitkan baginya.
Pipelinedb
Sekarang mari kita bicara tentang ekstensi kedua. Sayangnya, kami tidak dapat mengujinya dengan benar dalam pertempuran. Sekarang sedang melalui tahap adaptasi dalam sistem kami. Benar, ada satu masalah yang akan saya bicarakan lebih dekat sampai akhir.
Seperti pada kasus sebelumnya, kita mulai dengan contoh nyata. Lebih mudah untuk memahami manfaat ekstensi dan motivasi untuk menggunakannya.
Koleksi statistik . Bayangkan kami mengumpulkan statistik tentang kunjungan ke situs web kami. Kami membutuhkan analitik dari halaman yang paling populer, jumlah pengguna unik dan beberapa gagasan tentang keterlambatan sumber daya. Semua ini harus diperbarui secara waktu nyata. Tetapi kami tidak ingin menyentuh tabel data setiap kali dan membuat kueri, atau memperbarui tampilan di atas tabel.
CREATE CONTINUOUS VIEW v AS SELECT url::text, count(*) AS total_count, count(DISTINCT cookie::text) AS uniques, percentile_cont(0.99) WITHIN GROUP (ORDER BY latency::integer) AS p99_latency FROM page_views GROUP BY url;
url | total_count | uniques | p99_latency -----------+-------------+---------+------------ some/url/0 | 633 | 51 | 178 some/url/1 | 688 | 37 | 139 some/url/2 | 508 | 88 | 121 some/url/3 | 848 | 36 | 59 some/url/4 | 126 | 64 | 159
Pemrosesan streaming dan ekstensi PipelineDB datang untuk menyelamatkan. Ekstensi menambahkan abstraksi LIHAT LANJUTAN. Dalam versi Rusia, ini mungkin terdengar seperti "presentasi berkelanjutan". Tampilan ini diperbarui secara otomatis ketika dimasukkan ke dalam tabel dengan catatan kunjungan, sementara hanya berdasarkan data baru, tanpa pembacaan yang sudah direkam sebelumnya.
Aliran data . PipelineDB tidak terbatas hanya pada tipe tampilan baru. Misalkan kita melakukan pengujian A / B dan mengumpulkan analitik real-time tentang efektivitas solusi bisnis baru. Tetapi kami tidak ingin menyimpan data pada tindakan pengguna itu sendiri. Kami hanya tertarik pada hasilnya - grup mana yang memiliki konversi terbanyak.
Untuk menghindari penyimpanan langsung dari data mentah untuk streaming komputasi, kita perlu abstraksi seperti
stream - stream data . PipelineDB memperkenalkan fitur ini. Anda dapat membuat stream seperti tabel biasa. Di bawah tenda, itu akan menjadi "TABEL LUAR NEGERI" berdasarkan pada antrian ZeroMQ, yang ekstensi secara tak terlihat menggunakan dari kami. Data memasuki antrian internal ZeroMQ dan memicu pembaruan ke tampilan berkelanjutan.
CREATE STREAM ab_event_stream ( name text, ab_group text, event_type varchar(1), cookie varchar(32) ); CREATE CONTINUOUS VIEW ab_test_monitor AS SELECT name, ab_group, sum(CASE WHENevent_type = 'v' THEN 1 ELSE 0 END) AS view_count, sum(CASE WHENevent_type = 'c' THEN 1 ELSE 0 END) AS conversion_count, count(DISTINCT cookie) AS uniques FROM ab_event_stream GROUP BY name, ab_group;
Kemudian kami membuat "LIHAT LANJUTAN" berdasarkan data dari aliran yang dibuat sebelumnya. Ketika data tiba di aliran, tampilan akan diperbarui berdasarkan data ini. Setelah itu, data hanya akan dibuang, tidak disimpan di mana pun dan tidak mengambil ruang disk. Ini memungkinkan Anda untuk membangun analitik pada jumlah data yang hampir tidak terbatas, memuatnya ke dalam aliran data PipelineDB dan membaca hasil perhitungan dari tampilan berkelanjutan.
Komputasi aliran Setelah kami membuat aliran data dan tampilan berkelanjutan, kami dapat bekerja dengan komputasi aliran. Ini terlihat seperti ini.
INSERT INTO ab_event_stream (name, ab_group, event_type, cookie) SELECT round(random() * 2) AS name, round(random() * 4) AS ab_group, (CASE WHENrandom() > 0.4 THEN 'v' ELSE 'c' END) AS event_type, md5(random()::text) AS cookie FROM generate_series(0, 100000); SELECT ab_group, uniques FROM ab_test_monitor; SELECT ab_group, view_count * 100 / (conversion_count + view_count) AS conversion_rate FROM ab_test_monitor;
"SELECT" pertama memberi grup "ab" dan jumlah pengunjung unik. Yang kedua - memberikan rasio antara kelompok - konversi. Itu semua pengujian A / B pada lima panggilan SQL dalam database relasional.
Tampilan diperbarui secara dinamis. Anda tidak bisa menunggu pemrosesan seluruh data array, tetapi membaca hasil antara yang sudah diproses. Tampilan dibaca dengan cara yang sama seperti PostgreSQL biasa. Anda juga dapat menggabungkan tampilan dengan tabel atau bahkan tampilan lainnya. Tidak ada batasan.
Topologi
Kafka menerima telemetri, topik dalam Kafka mengirimkan data ini ke PostgreSQL, dan kami menggabungkannya lebih lanjut. Misalnya, kami menggabungkan dengan beberapa tabel biasa dan mengarahkan data ke aliran. Selanjutnya, ia memprovokasi pembaruan dari presentasi berkelanjutan yang sesuai, dari mana klien database sudah dapat membaca data yang sudah selesai.
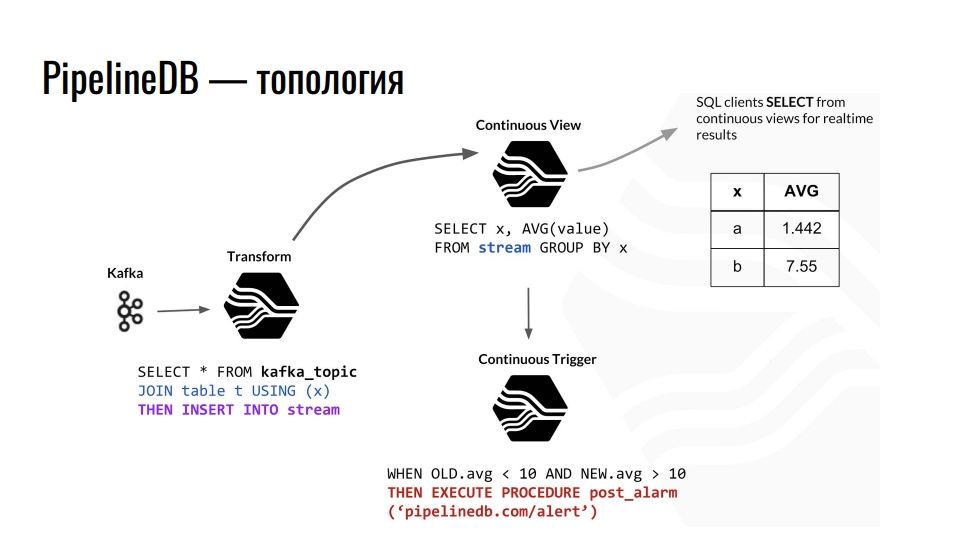 Contoh topologi komponen PipelineDB di dalam PostgreSQL. Sirkuit ini dipinjam dari presentasi oleh Derek Nelson.
Contoh topologi komponen PipelineDB di dalam PostgreSQL. Sirkuit ini dipinjam dari presentasi oleh Derek Nelson.Selain aliran dan tampilan, ekstensi juga menyediakan abstraksi "transform" - konverter atau mutator. Pandangan ini, tetapi bertujuan untuk mengubah aliran data yang masuk menjadi output yang dimodifikasi. Dengan menggunakan mutator ini, Anda dapat mengubah penyajian data atau memfilternya. Dari mutator, semuanya jatuh ke tampilan LIHAT TERUS. Kami sudah mengajukan pertanyaan untuk bisnis di dalamnya. Siapa pun yang akrab dengan pemrograman fungsional harus memahami gagasan itu.
Di PipelineDB kita bisa menggantung pemicu pada pandangan kita dan melakukan tindakan, misalnya, "waspada". Dengan semua perhitungan ini, kami tidak pernah menyimpan sendiri data mentah, atas dasar yang mana kami semua menghitungnya. Ini dapat berupa terabyte, yang kami unggah secara berurutan ke server dengan disk seratus gigabyte. Bagaimanapun, kami hanya tertarik pada hasil perhitungan.
Fitur utama
Ekstensi PipelineDB lebih sulit dipelajari daripada TimescaleDB. Di TimescaleDB, kami membuat tabel, memberi tahu dia bahwa dia hipertensi, dan menikmati hidup menggunakan beberapa fungsi tambahan yang ditawarkan ekstensi.
PipelineDB memecahkan masalah streaming komputasi dalam database relasional . Tugas pemrosesan data streaming lebih rumit daripada mempartisi dalam hal integrasi dan penggunaan. Namun, tidak semua orang memiliki data besar dan miliaran baris. Mengapa menyulitkan infrastruktur jika ada PipelineDB? Ekstensi menyediakan implementasi representasi, aliran, konverter, dan agregat sendiri untuk pemrosesan aliran. Ia juga
diintegrasikan ke dalam perencana kueri dan pelaksana kueri memungkinkan penerapan konsep komputasi aliran dalam basis data relasional.
Seperti TimescaleDB, ekstensi PipelineDB
tidak memaksakan pembatasan SQL di PostgreSQL . Ada beberapa fitur, misalnya, Anda tidak dapat menggabungkan dua aliran, tetapi ini tidak perlu.
Dukungan untuk struktur data dan algoritma probabilistik . Ekstensi menggunakan "Bloom Filter" untuk "SELECT DISTINCT", HyperLogLog untuk "COUNT (DISTINCT)", dan T-Intisari untuk "presentile_count ()" secara langsung dalam SQL. Ini meningkatkan produktivitas.
Ekosistem Ekstensi ini memungkinkan Anda untuk bekerja dengan solusi Ketersediaan Tinggi, alat pemantauan, dan semua hal lain yang sudah biasa di PostgreSQL.
Mengingat kekhasan komputasi streaming, PipelineDB memiliki
integrasi dengan Apache Kafka , dan dengan Amazon Kinesis, layanan analitik waktu-nyata. Karena PipelineDB bukan lagi garpu, tetapi ekstensi, integrasi dengan seluruh kebun binatang juga harus di luar kotak. Suatu keharusan, tetapi kita tidak hidup di dunia yang ideal, dan semuanya patut diperiksa.
Lisensi dan Berita
Semua kode dilisensikan di bawah Apache 2.0. Ada langganan berbayar untuk dukungan berbagai galeri pemotretan, serta versi klaster dengan lisensi komersial. Berdasarkan PipelineDB, perusahaan menyediakan layanan analitik Stride.
Sebelum saya mulai berbicara tentang ekstensi, saya mengatakan bahwa ada satu "tetapi". Sudah waktunya untuk berbicara tentang dia. Pada 1 Mei 2019, tim PipelineDB mengumumkan bahwa itu sekarang bagian dari Confluent. Ini adalah perusahaan yang mengembangkan KSQL - mesin untuk streaming data di Kafka dengan sintaks SQL. Sekarang Victor Gamov, salah satu pendiri podcast Debriefing, bekerja di sana.
Apa yang mengikuti dari ini? PipelineDB membeku di versi 1.0.0. Selain memperbaiki bug penting, tidak ada yang direncanakan di dalamnya. Karena pengambilalihan, kami mengharapkan integrasi Uber Kafka dengan PostgreSQL. Mungkin itu Confluent berdasarkan penyimpanan pluggable yang akan melakukan sesuatu yang keren.
Apa yang harus dilakukan Pergi ke TimescaleDB. Dalam versi terbaru mereka membuat "LIHAT KONTINU" dengan blackjack. Tentu saja, sekarang fungsinya tidak sekeren di PipelineDB, tetapi itu adalah masalah waktu.
Untuk meringkas
PipelineDB dirancang untuk pemrosesan data streaming kinerja tinggi. Ini memungkinkan Anda untuk melakukan perhitungan pada set data besar tanpa harus menyimpan data itu sendiri.
Dengan PipelineDB, ketika kami mengirim aliran data ke PostgreSQL dalam aliran, kami menganggapnya virtual. Kami tidak menyimpan data, tetapi menggabungkan, menghitung dan membuang. Anda dapat membuat server 200 gigabyte dan mengusir terabyte data melalui stream. Kami akan mendapatkan hasilnya, tetapi data itu sendiri akan dibuang.
Jika karena alasan tertentu "TAMPILAN LANJUT" dari TimescaleDB tidak cukup untuk Anda, coba PipelineDB. Ini adalah proyek open source di bawah lisensi Apache. Itu tidak akan pergi ke mana pun, meskipun tidak lagi dikembangkan secara aktif. Tetapi hal-hal dapat berubah, Confluent belum menulis tentang rencana ekspansi.
Menggunakan TimescaleDB dan PipelineDB
Dengan PostgreSQL dan dua ekstensi,
kita dapat menyimpan dan memproses array besar dari data deret waktu . Anda dapat memikirkan banyak aplikasi. Mari kita lihat contoh dari bidang studi saya - pemantauan kendaraan.

Peralatan navigasi terus mengirimkan rekaman telemetri ke server kami. Mereka mengurai berbagai teks dan protokol biner ke dalam format umum dan mengirim data ke Kafka dalam topik khusus. Dari sana, mereka mendapatkan integrasi dengan PipelineDB ke aliran data telemetri di dalam PostgreSQL. Aliran ini memperbarui pandangan untuk keadaan saat ini kendaraan dan analisis armada umum, dan atas dasar pemicu memprovokasi rekaman catatan telemetri di hipertensi TimescaleDB.
Dengan ekstensi, kami memiliki tiga keunggulan.
- Analitik waktu-nyata.
- Penyimpanan data seri waktu.
- Mengurangi volume telemetri yang disimpan. Menggunakan mutator PipelineDB, kami mengumpulkan data, misalnya, dengan satu menit, menghitung nilai rata-rata.
Grafana memiliki dukungan bawaan untuk fitur TimescaleDB. Oleh karena itu, grafik dapat dibuat sesuai dengan metrik bisnis langsung dari kotak, hingga trek di peta dengan koordinat. Departemen analitik akan senang.
Untuk "menyentuh" semuanya sendiri, lihat
demo di GitHub dan jalankan
gambar Docker - di dalam perakitan dari PostgreSQL, TimescaleDB, dan PipelineDB terbaru.
Total
PostgreSQL memungkinkan Anda untuk menggabungkan berbagai ekstensi, serta menambahkan tipe dan fungsi data Anda sendiri untuk menyelesaikan masalah tertentu. Dalam kasus kami, penggunaan ekstensi TimescaleDB dan PostGIS hampir sepenuhnya mencakup kebutuhan untuk menyimpan data deret waktu dan perhitungan geospasial. Dengan ekstensi PipelineDB, kami dapat melakukan perhitungan terus-menerus untuk berbagai analitik dan statistik, dan penggunaan kolom JSONB memungkinkan kami untuk menyimpan data yang terstruktur dengan lemah dalam database relasional. Solusi Open Source sudah cukup dengan kepala - kami tidak menggunakan solusi komersial.
Ekstensi ini secara praktis tidak memaksakan pembatasan pada ekosistem di sekitar PostgreSQL, seperti solusi Ketersediaan Tinggi, sistem cadangan, pemantauan dan alat analisis log. Kami tidak memerlukan MongoDB jika ada kolom JSONB, dan kami tidak perlu InfluxDB jika ada TimescaleDB.
Apakah Anda suka cerita dari Ivan dan ingin berbagi sesuatu yang serupa? Terapkan sebelum 7 September di HighLoad ++ di Moskow. Program ini secara bertahap terisi. , , , , . , !