Petunjuk pencarian sangat bagus. Seberapa sering kita mengetik alamat situs lengkap di bilah alamat? Dan nama produk di toko online? Untuk pertanyaan singkat seperti itu, mengetik beberapa karakter biasanya cukup jika petunjuk pencariannya bagus. Dan jika Anda tidak memiliki dua puluh jari atau kecepatan mengetik yang luar biasa, maka Anda pasti akan menggunakannya.
Pada artikel ini, kita akan berbicara tentang layanan petunjuk pencarian hh.ru baru kami, yang kami lakukan dalam edisi
School of Programmer sebelumnya .
Layanan lama memiliki sejumlah masalah:
- ia mengerjakan kueri pengguna populer yang dipilih sendiri;
- tidak dapat beradaptasi dengan mengubah preferensi pengguna;
- tidak dapat membuat peringkat kueri yang tidak termasuk di bagian atas;
- tidak memperbaiki kesalahan ketik.
Dalam layanan baru, kami memperbaiki kekurangan ini (sambil menambahkan yang baru).
Kamus pertanyaan populer
Ketika tidak ada petunjuk sama sekali, Anda dapat secara manual memilih permintaan teratas-N pengguna dan menghasilkan petunjuk dari permintaan ini menggunakan kemunculan kata yang tepat (dengan atau tanpa urutan). Ini adalah pilihan yang bagus - mudah diimplementasikan, memberikan akurasi prompt yang baik dan tidak mengalami masalah kinerja. Untuk waktu yang lama, sugest kami bekerja seperti itu, tetapi kelemahan signifikan dari pendekatan ini adalah tidak lengkapnya masalah ini.
Misalnya, permintaan "pengembang javascript" tidak termasuk dalam daftar seperti itu, jadi ketika kita memasukkan "waktu javascript", kita tidak dapat menampilkan apa pun. Jika kami menambah permintaan, dengan hanya mempertimbangkan kata terakhir, kami akan melihat "tukang javascript" di tempat pertama. Untuk alasan yang sama, tidak mungkin untuk menerapkan koreksi kesalahan lebih sulit daripada pendekatan standar dengan menemukan kata-kata terdekat dengan jarak Damerau-Levenshtein.
Model bahasa
Pendekatan lain adalah belajar mengevaluasi probabilitas kueri dan menghasilkan kelanjutan yang paling mungkin untuk kueri pengguna. Untuk melakukan ini, gunakan model bahasa - distribusi probabilitas pada serangkaian urutan kata.
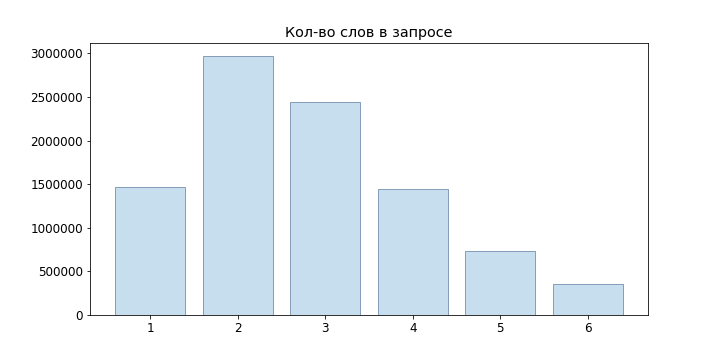
Karena sebagian besar permintaan pengguna pendek, kami bahkan tidak mencoba model bahasa jaringan saraf, tetapi membatasi diri pada n-gram:
P(w1 dotswm)= prodmi=1P(wi|w1 dotswi−1) approx prodmi=1P(wi|wi−(n−1) dotswi−1)
Sebagai model paling sederhana, kita dapat mengambil definisi statistik dari probabilitas
P(wi|w1 dotswi−1)= fraccount(w1 dotswi)count(w1 dotswi−1)
Namun, model seperti itu tidak cocok untuk mengevaluasi pertanyaan yang tidak ada dalam sampel kami: jika kami tidak mengamati 'junior developer java', maka ternyata
P( textjuniordeveloperjava)= fraccount( textjuniordeveloperjava)count( textjuniordeveloper)=0
Untuk mengatasi masalah ini, Anda dapat menggunakan berbagai model perataan dan interpolasi. Kami menggunakan Backoff:
Pbo(wn|w1 dotswn−1)= begincasesP(wn|w1 dotswn−1),hitung(w1 dotswn−1)>0 alphaPbo(wn|w2 titikwn−1),hitung(w1 titikwn−1)=0 endkas
alpha= fracP(w1 dotswn−1)1− sumwPbo(w|w2 dotswn−1)
Di mana P adalah probabilitas yang dihaluskan
w1...wn−1 (kami menggunakan Laplace smoothing):
P(wn|w1 dotswn−1)= fraccount(wn)+ deltacount(w1 dotswn−1)+ delta|V|
dimana V adalah kamus kami.
Pembuatan Opsi
Jadi, kami dapat menilai probabilitas permintaan tertentu, tetapi bagaimana cara menghasilkan permintaan yang sama? Adalah bijaksana untuk melakukan hal berikut: biarkan pengguna memasukkan kueri
w1...wn , maka pertanyaan yang cocok untuk kita dapat ditemukan dari kondisi tersebut
w1 dotswm= undersetwn+1 dotswm dalamVargmaxP(w1 dotswnwn+1 dotswm)
Tentu saja, memilah-milah
|V|m−n,m=1 dotsM Tidak mungkin untuk memilih opsi terbaik untuk setiap permintaan yang masuk, jadi kami
akan menggunakan
Penelusuran Balok . Untuk model bahasa n-gram kami, diturunkan ke algoritme berikut:
def beam(initial, vocabulary): variants = [initial] for i in range(P): candidates = [] for variant in variants: candidates.extends(generate_candidates(variant, vocabulary)) variants = sorted(candidates)[:N] return candidates def generate_candidates(variant, vocabulary): top_terms = []

Di sini simpul yang disorot dengan warna hijau adalah opsi yang dipilih terakhir, angka di depan simpul
wn - probabilitas
P(wn|wn−1) , setelah simpul -
P(w1...wn) .
Ini telah menjadi jauh lebih baik, tetapi di generate_candidates Anda perlu dengan cepat mendapatkan N istilah terbaik untuk konteks yang diberikan. Dalam hal hanya menyimpan probabilitas n-gram, kita perlu membaca seluruh kamus, menghitung probabilitas semua frasa yang mungkin, dan kemudian mengurutkannya. Jelas, ini tidak akan berlaku untuk permintaan online.
Boron untuk probabilitas
Untuk mendapatkan varian probabilitas kondisional terbaik N dari kelanjutan frasa, kami menggunakan istilah boron. Dalam simpul
w1 hinggaw2 koefisien yang disimpan
alpha , nilai
P(w2|w1) dan diurutkan berdasarkan probabilitas bersyarat
P( bullet|w1w2) daftar istilah
w3 bersama dengan
P(w3|w1w2) . Istilah khusus
eos menandai akhir dari frasa.
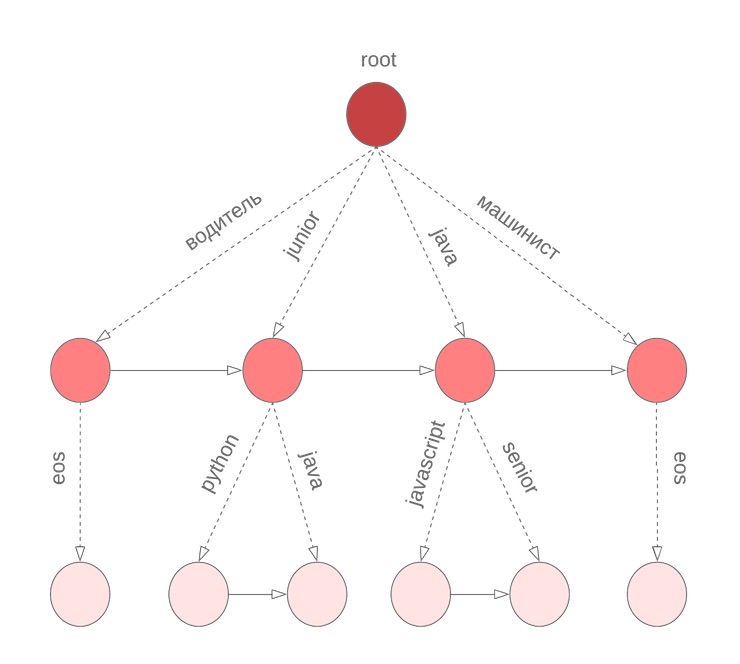
Namun ada nuansa
Dalam algoritme yang dijelaskan di atas, kami menganggap bahwa semua kata dalam kueri selesai. Namun, ini tidak benar untuk kata terakhir yang dimasuki pengguna saat ini. Kita lagi perlu menelusuri seluruh kamus untuk melanjutkan kata yang sedang dimasukkan. Untuk mengatasi masalah ini, kami menggunakan boron simbolis, di simpul yang kami simpan istilah M diurutkan berdasarkan probabilitas unigram. Misalnya, ini akan terlihat seperti bor kami untuk java, junior, jupyter, javascript dengan M = 3:

Kemudian, sebelum memulai Pencarian Beam, kami menemukan kandidat terbaik untuk melanjutkan kata saat ini
wn dan pilih N kandidat terbaik untuk
P(w1 dotswn) .
Salah ketik
Kami telah membangun layanan yang memungkinkan Anda memberikan petunjuk yang baik untuk permintaan pengguna. Kami bahkan siap untuk kata-kata baru. Dan semuanya akan baik-baik saja ...
Tetapi pengguna berhati-hati dan tidak mengganti keyboard hfcrkflre.Bagaimana cara mengatasinya? Hal pertama yang terlintas dalam pikiran adalah mencari koreksi dengan menemukan opsi terdekat untuk jarak Damerau-Levenshtein, yang didefinisikan sebagai jumlah minimum penyisipan / penghapusan / penggantian karakter atau transposisi dari dua karakter tetangga yang diperlukan untuk mendapatkan yang lain dari satu baris. Sayangnya, jarak ini tidak memperhitungkan kemungkinan penggantian tertentu. Jadi, untuk kata yang dimasukkan "pencari ranjau", kita mendapatkan bahwa opsi "kolektor" dan "tukang las" adalah setara, meskipun secara intuitif tampaknya mereka berarti kata kedua.
Masalah kedua adalah bahwa kita tidak memperhitungkan konteks di mana kesalahan terjadi. Misalnya, dalam kueri "memesan sapper" kita harus tetap memilih opsi "kolektor" daripada "tukang las".
Jika Anda mendekati tugas mengoreksi kesalahan ketik dari sudut pandang probabilistik, wajar saja untuk sampai pada
model saluran bising :
- set alfabet Sigma ;
- set semua garis trailing Sigma∗ atas dirinya;
- banyak baris kata yang benar D subseteq Sigma∗ ;
- distribusi yang diberikan P(s|w) dimana s in Sigma∗,w dalamD .
Kemudian tugas koreksi ditetapkan sebagai menemukan kata yang benar untuk input s. Bergantung pada sumber kesalahan, ukur
P itu dapat dibangun dengan cara yang berbeda, dalam kasus kami adalah bijaksana untuk mencoba memperkirakan kemungkinan kesalahan ketik (sebut saja mereka penggantian elementer)
Pe(t|r) , di mana t, r adalah simbolik n-gram, dan kemudian mengevaluasi
P(s|w) sebagai probabilitas mendapatkan s dari w oleh penggantian elementer yang paling mungkin.
Biarkan
Partn(x) - Memisahkan string x menjadi n substring (mungkin nol). Model Brill-Moore melibatkan perhitungan probabilitas
P(s|w) sebagai berikut:
P(s|w) approx maxR diPartn(w),T diPartn(s) prodni=1Pe(Ti|Ri)
Tetapi kita perlu menemukannya
P(w|s) :
P(w|s)= fracP(s|w)P(w)P(s)=const cdotP(s|w) cdotP(w)
Dengan belajar mengevaluasi P (w | s), kami juga akan menyelesaikan masalah pilihan peringkat dengan jarak Damerau-Levenshtein yang sama dan akan dapat mempertimbangkan konteks ketika mengoreksi kesalahan ketik.
Perhitungan Pe(Ti|Ri)
Untuk menghitung probabilitas substitusi dasar, kueri pengguna akan membantu kami lagi: kami akan membuat pasangan kata (s, w) yang
- tutup di Damerau-Levenshtein;
- salah satu kata lebih umum daripada N kali lainnya.
Untuk pasangan seperti itu, kami mempertimbangkan perataan optimal menurut Levenshtein:
Kami menyusun semua kemungkinan partisi s dan w (kami membatasi diri untuk panjang n = 2, 3): n → n, pr → rn, pro → rn, ro → po, m → ``, mm → m, dll. Untuk setiap n-gram, kami temukan
Pe(t|r)= fraccount(r tot)count(r)
Perhitungan P(s|w)
Perhitungan
P(s|w) langsung mengambil
O(2|w|+|s|) : kita perlu memilah-milah semua kemungkinan partisi w dengan semua kemungkinan partisi s. Namun, dinamika pada awalan dapat memberikan jawaban
O(|w|∗|s|∗n2) dengan n adalah panjang maksimum pergantian unsur:
d [i, j] = \ begin {case} d [0, j] = 0 & j> = k \\ d [i, 0] = 0 & i> = k \\ d [0, j] = P (s [0: j] \ spasi | \ spasi w [0]) & j <k \\ d [i, 0] = P (s [0] \ spasi | \ spasi w [0: i]) & i <k \\ d [i, j] = \ underset {k, l \ le n, k \ lt i, l \ lt j} {max} (P (s [jl: j] \ space | \ space w [ik: i]) \ cdot d [ik-1, jl-1]) \ end {cases}
Di sini P adalah probabilitas dari baris yang sesuai dalam model k-gram. Jika Anda melihat lebih dekat, ini sangat mirip dengan algoritma Wagner-Fisher dengan kliping Ukkonen. Di setiap langkah kita dapatkan
P(w[0:i]|s[0:j]) dengan menyebutkan semua perbaikan
w[i−k:i] masuk
s[j−l:j] tunduk pada
k,l len dan pilihan yang paling memungkinkan.
Kembali ke P(w|s)
Jadi, kita bisa menghitung
P(s|w) . Sekarang kita perlu memilih beberapa opsi dengan memaksimalkan
P(w|s) . Lebih tepatnya, untuk permintaan awal
s1s2 dotssn kamu harus memilih
w1 dotswn dimana
P(w1 dotswn|s1 dotssn) maksimum. Sayangnya, pilihan opsi yang jujur tidak sesuai dengan persyaratan waktu respons kami (dan batas waktu proyek hampir berakhir), jadi kami memutuskan untuk fokus pada pendekatan berikut:
- dari kueri asli kami mendapatkan beberapa opsi dengan mengubah k kata-kata terakhir:
- kami memperbaiki tata letak keyboard jika istilah yang dihasilkan memiliki probabilitas beberapa kali lebih tinggi daripada yang asli;
- kami menemukan kata-kata yang jarak Damerau-Levenshtein tidak melebihi d;
- pilih dari mereka opsi top-N untuk P(s|w) ;
- kirim BeamSearch ke input bersama dengan permintaan asli;
- saat memberi peringkat hasil, kami mendiskon opsi yang diperoleh prodk−1i=0P(sn−i|wn−i) .
Untuk item 1.2, kami menggunakan algoritma FB-Trie (maju dan mundur trie), berdasarkan pada pencarian fuzzy di pohon awalan maju dan mundur. Ini ternyata lebih cepat daripada mengevaluasi P (s | w) di seluruh kamus.
Statistik Kueri
Dengan konstruksi model bahasa, semuanya sederhana: kami mengumpulkan statistik tentang kueri pengguna (berapa kali kami membuat kueri untuk frasa tertentu, berapa banyak pengguna, berapa banyak pengguna terdaftar), kami memecah permintaan menjadi n-gram dan membangun bur. Lebih rumit dengan model kesalahan: setidaknya, kamus kata-kata yang tepat diperlukan untuk membangunnya. Seperti disebutkan di atas, untuk memilih pasangan pelatihan, kami menggunakan asumsi bahwa pasangan semacam itu harus dekat dalam jarak Damerau-Levenshtein, dan yang satu harus terjadi lebih sering daripada yang lainnya beberapa kali.
Tetapi datanya masih terlalu berisik: upaya injeksi xss, tata letak yang salah, teks acak dari clipboard, pengguna berpengalaman dengan permintaan "programmer c not 1c",
permintaan dari kucing yang melewati keyboard .
Misalnya, apa yang Anda coba temukan dengan permintaan seperti itu? Oleh karena itu, untuk menghapus sumber data, kami mengecualikan:
- istilah frekuensi rendah;
- Berisi operator bahasa query
- kosakata cabul.
Mereka juga memperbaiki tata letak keyboard, memeriksa kata-kata dari teks lowongan dan kamus terbuka. Tentu saja, itu tidak mungkin untuk memperbaiki semuanya, tetapi opsi seperti itu biasanya benar-benar terputus atau berada di bagian bawah daftar.
Dalam prod
Tepat sebelum perlindungan proyek, mereka meluncurkan layanan produksi untuk pengujian internal, dan setelah beberapa hari - untuk 20% pengguna. Di hh.ru, semua perubahan yang signifikan bagi pengguna harus melalui
sistem tes AB , yang memungkinkan kami tidak hanya untuk memastikan signifikansi dan kualitas perubahan, tetapi juga untuk
menemukan kesalahan .
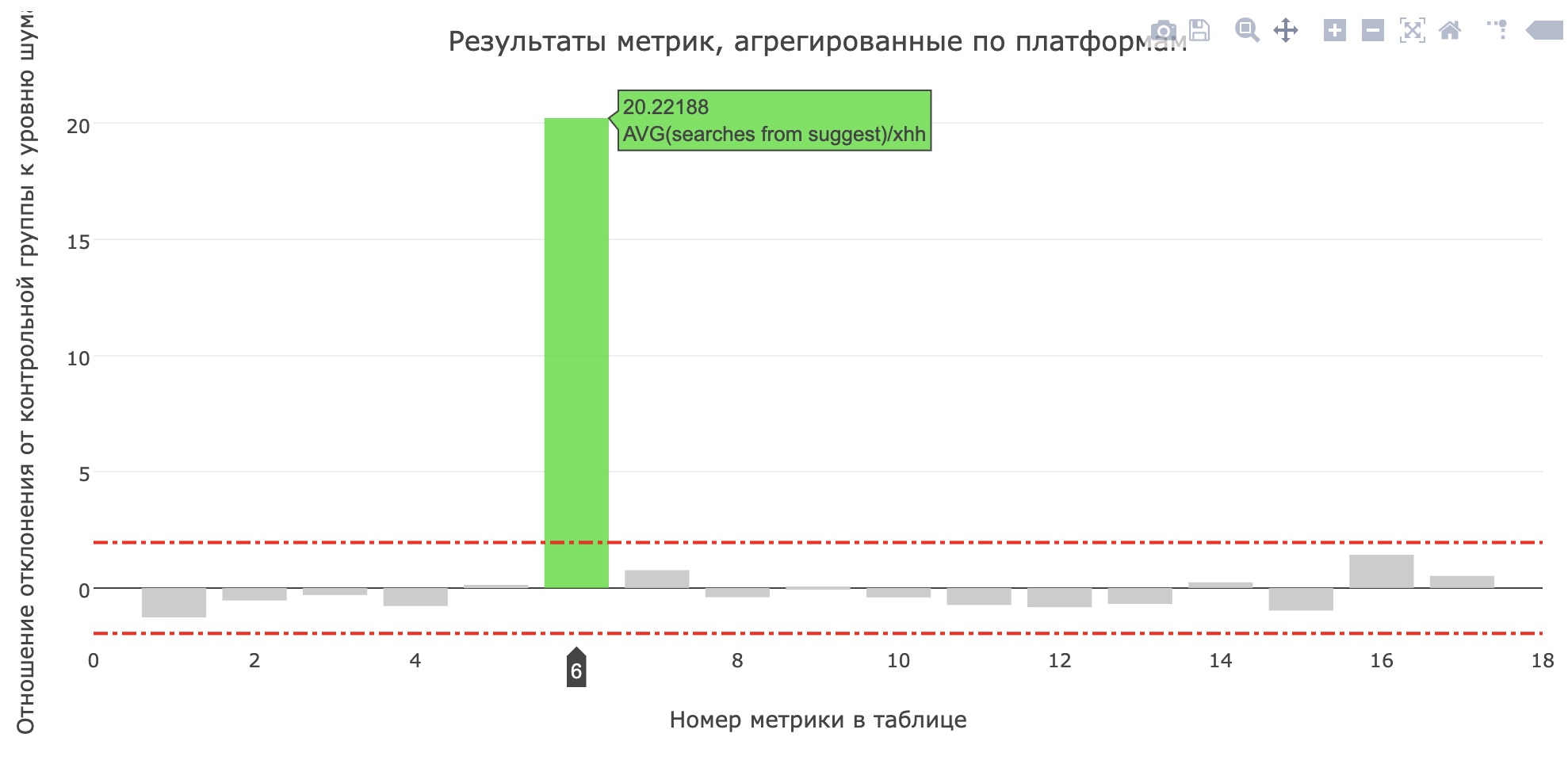
Metrik jumlah rata-rata pencarian dari sujest untuk pelamar telah meningkat (meningkat dari 0,959 menjadi 1,1355), dan bagian pencarian dari sujest dari semua permintaan pencarian telah meningkat dari 12,78% menjadi 15,04%. Sayangnya, metrik produk utama tidak bertambah, tetapi pengguna mulai menggunakan lebih banyak kiat.
Pada akhirnya
Tidak ada ruang untuk cerita tentang proses Sekolah, model yang diuji lainnya, alat yang kami tulis untuk perbandingan model, dan pertemuan di mana kami memutuskan fitur mana yang akan dikembangkan untuk mendapatkan demo perantara. Lihatlah
catatan sekolah masa lalu , tinggalkan permintaan di
https://school.hh.ru , selesaikan tugas yang menarik dan datang untuk belajar. Ngomong-ngomong, layanan untuk pengecekan tugas juga dilakukan oleh lulusan set sebelumnya.
Apa yang harus dibaca?
- Pengantar Model Bahasa
- Model Brill-Moore
- Fb-trie
- Apa yang terjadi pada permintaan pencarian Anda