Dalam dunia kriptografi, ada banyak cara mudah untuk mengenkripsi pesan. Masing-masing dari mereka baik dengan caranya sendiri. Salah satunya akan dibahas.
Ylchu Schzzkgow
Atau diterjemahkan dari "Cipher Caesar" ke dalam bahasa Rusia - Cipher Caesar .

- Apa esensinya?
- Dia menyandikan pesan, menggeser setiap huruf dengan N poin. Cipher klasik Caesar memindahkan huruf tiga langkah ke depan. Dengan kata sederhana - itu adalah "abv", itu menjadi "di mana".
"Tapi bagaimana dengan huruf-huruf di akhir alfabet?" Bagaimana dengan ruang?
Mereka baik-baik saja. Jika menggeser hurufnya, cipher melampaui lingkup alfabet - mulai menghitung lagi. Artinya, huruf "Eyuya" berubah menjadi "abv." Dan spasi tetap spasi.
- Apakah N harus sama dengan tiga?
Tidak semuanya. N mungkin berbeda dari tiga. Setiap N antara [1: M-1] diperbolehkan, di mana M adalah jumlah huruf dalam alfabet.
Sandi semacam itu mudah diuraikan jika Anda tahu tentang keberadaannya. Tetapi bukan “keandalannya” yang menarik saya, tetapi sesuatu yang lain.
Dasi
Suatu hari di musim panas aku ingin tahu:
- Tetapi bagaimana jika saya mengenkripsi kata menggunakan Caesar, dan saya mendapatkan kata yang ada di output?
- Berapa banyak kata-kata seperti itu "pemindah"?
- Dan akankah ada pola jika N diubah?
Saya mulai mencari jawaban untuk pertanyaan-pertanyaan ini di menit yang sama.
Tugas: Temukan semua kata
Mundur. Dari konser Mikhail Zadornov dan pengalaman pribadi, saya memahami dua hal:
- Orang Amerika tidak tersinggung oleh ucapan komedian Rusia.
- Bahasa Rusia kuat dan kuat. Dan ada banyak kata di dalamnya.
Karena itu, saya memutuskan untuk menggunakan bahasa Inggris sebagai basis saya. Selain itu, pada suatu waktu ada INFA bahwa orang-orang berbahasa Inggris mampu menyusun kamus lengkap kata-kata bahasa Inggris. Apa yang mendorong saya untuk menemukan dataset semacam itu.
Baris pertama dari googling yang lamban membawa saya ke repositori ini . Penulis menjanjikan 479 ribu kata dalam bahasa Inggris dalam format yang mudah. Saya menyukai file json, di mana semua kata-kata diletakkan dalam bentuk yang mudah untuk memuat ke dalam kamus Python.
Setelah otopsi pertama, ternyata ada lebih sedikit kata - 370 101 buah. "Tapi ini tidak masalah, karena untuk contoh yang bagus itu sudah cukup," pikirku.
words = json.load(open('words_dictionary.json', 'r')) len(words.keys()) >> 370101
Pertama, Anda perlu membuat alfabet. Saya memutuskan untuk membuat daftar dengan cara yang paling nyaman bagi saya. Penting juga untuk mengingat jumlah huruf dalam alfabet:
abc = list('abcdefghijklmnopqrstuvwxyz') abc_len = len(abc)
Pada awalnya itu menarik untuk membuat fungsi menerjemahkan kata menjadi terenkripsi. Inilah yang terjadi:
Saya memutuskan untuk membuat siklus besar dari semua kata dan mulai menerjemahkannya satu per satu. Tetapi menemukan masalah. Ternyata beberapa kata mengandung tanda "-", yang mengejutkan dan alami pada saat bersamaan.
Tanpa berpikir dua kali, saya menghitung jumlah kata-kata itu dan ternyata hanya ada dua. Setelah itu dia menghapus keduanya, karena itu akan sangat mempengaruhi hasilnya. Untuk membantu saya, fungsi ini lahir:
Kamusnya terlihat seperti:
{'a': 1, 'aa': 1, 'aaa': 1, 'aah': 1, ... }
Karena itu, saya memutuskan untuk tidak menjadi pintar dan mengganti yang dengan kata-kata yang disandikan. Untuk melakukan ini, tulis fungsi:
Dan, tentu saja, kami membutuhkan siklus besar yang akan melewati semua kata, menemukan pengalih kata dan menyimpan hasilnya. Ini dia:
Anda mungkin telah memperhatikan bahwa dalam parameter fungsi adalah "min_len = 0". Dia akan dibutuhkan di masa depan. Untuk kekhasan dataset ini adalah serangkaian kata "aneh". Seperti: "aa", "aah" dan kombinasi serupa. Merekalah yang memberikan hasil pertama - 660 pemindah kata.
Oleh karena itu, saya harus memberi batas lima setidaknya lima karakter sehingga kata-kata itu enak dipandang dan mirip dengan yang ada.
words_result = check_all(words_cesar, min_len=5) words_result >> {'abime': 'delph', 'biabo': 'elder', 'bifer': 'elihu', 'cobra': 'freud', 'colob': 'frore', 'oxime': 'ralph', 'pelta': 'showd', 'primero': 'sulphur', 'teloi': 'whorl', 'xerox': 'ahura'}
Ya, sepuluh kata terbalik ditemukan berkat algoritme. Kombinasi favorit saya:
primero [Pertama] → belerang [Sulfur]. Kebanyakan pasangan penerjemah Google tidak mengenalinya.
Pada tahap ini, saya sebagian memuaskan dahaga akan pengetahuan. Tapi di depan ada pertanyaan seperti: "Bagaimana dengan N lainnya?"
Dan menggunakan fungsi ini, saya menemukan jawabannya:
Siklus selesai dalam 10-15 detik. Tetap hanya untuk melihat hasilnya. Tapi, karena saya pikir itu lebih menarik ketika ada jadwal. Dan inilah fungsi terakhir, yang akan menunjukkan kepada kita hasilnya:
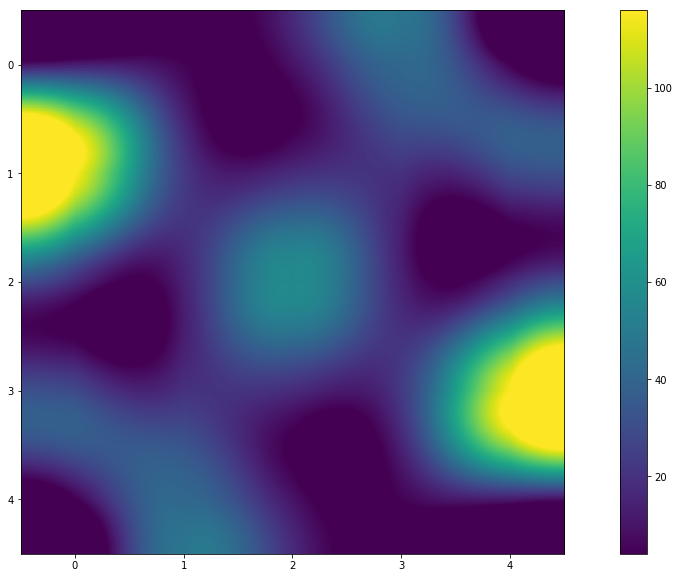
Ringkasan
Jawaban untuk pertanyaan di awal
"Bagaimana jika saya mengenkripsi kata menggunakan Caesar, dan saya mendapatkan kata yang ada di output?"
- Ini mungkin, bahkan sangat. Beberapa N memberikan lebih banyak kata daripada yang lain.
- Ada berapa kata "shifters" di sana?
- Tergantung pada N, panjang minimum dan, tentu saja, pada dataset. Dalam kasus saya, dengan N = 3, panjang kata minimum 0 dan 5 adalah jumlah kata: masing-masing 660 dan 10.
- Dan apakah akan ada pola jika Anda mengubah N?
- Rupanya ya! Dari grafik (atau peta panas) Anda dapat melihat bahwa warnanya simetris. Dan nilai-nilai dalam matriks hasil menunjukkan ini. Dan jawaban untuk pertanyaan "Mengapa begitu?" Saya akan menyerahkannya kepada pembaca.
Kontra dari pekerjaan ini
- Dataset tidak benar. Banyak kata yang tidak jelas. Meskipun mungkin begitu. Ini adalah " semua " kata-kata dari bahasa Inggris.
- Kode
selalu dapat ditingkatkan. - "Kode Caesar" adalah kasus khusus dari "Kode Athena", di mana rumusnya:
Untuk "Cipher Caesar" A = 1. Ngomong-ngomong, ia memiliki lebih banyak nuansa, yang berarti lebih menarik.
File pekerjaan saya dengan hasil dan daftar kata-kata terbalik terletak di repositori ini
Efzp zzhgl!