Memartisi ("mempartisi") di SQL Server, dengan kesederhanaan yang tampak ("apa yang ada - Anda menyebarkan tabel dan indeks berdasarkan filegroup, Anda mendapat untung dalam administrasi dan kinerja") adalah topik yang agak luas. Di bawah ini saya akan mencoba menjelaskan cara membuat dan menerapkan skema fungsi dan partisi dan masalah apa yang mungkin Anda temui. Saya tidak akan berbicara tentang manfaat, kecuali untuk satu hal - beralih bagian, ketika Anda langsung menghapus kumpulan data besar dari sebuah tabel, atau sebaliknya - langsung memuat set yang tidak kalah besar ke dalam tabel.
Seperti yang dinyatakan
msdn : “Data tabel dan indeks yang dipartisi dibagi menjadi beberapa blok yang dapat didistribusikan di beberapa grup file dalam database. Data dipartisi secara horizontal, sehingga grup baris dipetakan ke bagian individual. Semua bagian dari indeks atau tabel yang sama harus dalam database yang sama. Tabel atau indeks dianggap sebagai entitas logis tunggal ketika menjalankan kueri atau pembaruan data. "
Keuntungan utama juga tercantum di sana:
- Transfer dan akses subset data dengan cepat dan efisien dengan tetap menjaga integritas set data
- Operasi pemeliharaan dapat dilakukan lebih cepat dengan satu atau lebih bagian;
- Anda dapat meningkatkan kecepatan eksekusi permintaan, tergantung pada permintaan yang sering dieksekusi dalam konfigurasi perangkat keras Anda.
Dengan kata lain, partisi digunakan untuk penskalaan horizontal. Tabel / indeks "tersebar" oleh grup-grup file yang berbeda, yang dapat ditempatkan pada disk fisik yang berbeda, yang secara signifikan meningkatkan kenyamanan administrasi dan, secara teoritis, memungkinkan Anda untuk meningkatkan kinerja kueri untuk data ini - Anda dapat membaca hanya bagian yang diinginkan (lebih sedikit data), atau membaca semuanya secara paralel (perangkat berbeda, baca cepat). Dalam praktiknya, semuanya agak lebih rumit dan meningkatkan kinerja kueri ke tabel dipartisi hanya bisa berfungsi jika kueri Anda menggunakan pemilihan berdasarkan bidang yang Anda pisahkan. Jika Anda belum memiliki pengalaman dengan tabel dipartisi, perlu diingat bahwa kinerja kueri Anda mungkin tidak berubah, tetapi dapat menurun setelah Anda mempartisi tabel Anda.
Mari kita bicara tentang keuntungan absolut yang pasti Anda dapatkan dengan mempartisi (tetapi yang juga harus Anda bisa gunakan) - ini adalah peningkatan yang dijamin dalam kenyamanan mengelola basis data Anda. Misalnya, Anda memiliki tabel dengan satu miliar catatan, di mana 900 juta berasal dari periode lama ("tertutup") dan hanya baca. Dengan bantuan pengelompokan, Anda dapat mentransfer data lama ini ke grup file hanya baca terpisah, mencadangkannya, dan tidak lagi menyeretnya ke semua cadangan harian Anda - kecepatan membuat salinan cadangan akan meningkat dan ukurannya akan berkurang. Anda dapat membangun kembali indeks tidak di atas seluruh tabel, tetapi lebih dari bagian yang dipilih. Selain itu, ketersediaan basis data Anda bertambah - jika salah satu perangkat yang berisi grup file dengan bagian tersebut gagal, yang lain masih akan tersedia.
Untuk mencapai manfaat yang tersisa (langsung beralih bagian; meningkatkan produktivitas) - Anda perlu secara khusus merancang struktur data dan menulis kueri.
Saya kira saya sudah cukup mempermalukan pembaca dan sekarang saya bisa melanjutkan berlatih.
Pertama, buat database dengan 4 grup file tempat kami akan melakukan percobaan:
create database [PartitionTest] on primary (name ='PTestPrimary', filename = 'E:\data\partitionTestPrimary.mdf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg1] (name ='PTestFG1', filename = 'E:\data\partitionTestFG1.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg2] (name ='PTestFG2', filename = 'E:\data\partitionTestFG2.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg3] (name ='PTestFG3', filename = 'E:\data\partitionTestFG3.ndf', size = 8092KB, filegrowth = 1024KB) log on (name = 'PTest_Log', filename = 'E:\data\partitionTest_log.ldf', size = 2048KB, filegrowth = 1024KB); go alter database [PartitionTest] set recovery simple; go use partitionTest;
Buat tabel yang akan kita siksa.
create table ptest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000));
Dan isi dengan data selama satu tahun:
;with nums as ( select 0 n union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9 ) insert into ptest(dt, dummy_int, dummy_char) select dateadd(hh, rn-1, '20180101') dt, rn dummy_int, 'dummy char column #' + cast(rn as varchar) from ( select row_number() over(order by (select (null))) rn from nums n1, nums n2, nums n3, nums n4 )t where rn < 8761
Sekarang tabel pTest berisi satu catatan untuk setiap jam 2018.
Sekarang Anda perlu membuat fungsi partisi yang menggambarkan kondisi batas untuk membagi data menjadi beberapa bagian. SQL Server hanya mendukung berbagai partisi.
Kami akan mempartisi tabel kami sesuai dengan kolom dt (datetime) sehingga setiap bagian berisi data selama 4 bulan (di sini saya mengacaukannya - pada kenyataannya, bagian pertama akan berisi data untuk 3, yang kedua untuk 4, yang ketiga untuk 5 bulan, tetapi untuk tujuan demonstrasi - ini bukan masalah)
create partition function pfTest (datetime) as range for values ('20180401', '20180801')
Segalanya tampak normal, tetapi di sini saya sengaja membuat satu "kesalahan". Jika Anda melihat sintaks dalam
msdn , Anda akan melihat bahwa selama pembuatan Anda dapat menentukan bagian mana yang akan menjadi perbatasan - ke kiri, atau ke kanan. Secara default, untuk beberapa alasan yang tidak diketahui, batas yang ditentukan merujuk ke bagian "kiri", jadi untuk kasus saya, akan benar untuk membuat fungsi partisi sebagai berikut:
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
Sementara saya benar-benar dieksekusi:
create partition function pfTest (datetime) as range left for values ('20180401', '20180801')
Tetapi kita akan kembali ke sini nanti dan menciptakan kembali fungsi partisi kita. Sementara itu, kami melanjutkan dengan apa yang terjadi untuk memahami apa yang terjadi dan mengapa itu tidak baik bagi kami.
Setelah membuat fungsi partisi, Anda perlu membuat skema partisi. Itu jelas mengikat bagian ke filegroup:
create partition scheme psTest as partition pfTest to ([FG1], [FG2], [FG3])
Seperti yang Anda lihat, ketiga bagian kami akan berada di grup file yang berbeda. Sekarang saatnya mempartisi tabel kita. Untuk melakukan ini, kita perlu membuat indeks berkerumun dan, alih-alih menentukan grup file di mana ia seharusnya berada, tentukan skema partisi:
create clustered index cix_pTest_id on pTest(id) on psTest(dt)
Dan di sini juga, saya membuat "kesalahan" dalam skema saat ini - saya bisa saja membuat indeks cluster unik pada kolom ini, namun, ketika membuat indeks unik, kolom yang digunakan untuk partisi harus dimasukkan dalam indeks. Dan saya ingin menunjukkan apa yang dapat Anda temui dengan konfigurasi ini.
Sekarang mari kita lihat apa yang kita dapatkan di konfigurasi saat ini (
permintaan diambil dari sini ):
SELECT sc.name + N'.' + so.name as [Schema.Table], si.index_id as [Index ID], si.type_desc as [Structure], si.name as [Index], stat.row_count AS [Rows], stat.in_row_reserved_page_count * 8./1024./1024. as [In-Row GB], stat.lob_reserved_page_count * 8./1024./1024. as [LOB GB], p.partition_number AS [Partition

Dengan demikian, kami mendapat tiga bagian yang tidak terlalu sukses - yang pertama menyimpan data dari awal waktu hingga 04/01/2018 00:00:00 inklusif, yang kedua - dari 01/01/2018 00:00:01 hingga 08/01/2018 00:00:00 inklusif, yang ketiga dari 08/01/2018 00:00:01 sampai akhir dunia (saya sengaja melewatkan sepersekian detik, karena saya tidak ingat gradasi SQL Server mana yang menulis pecahan ini, tetapi artinya disampaikan dengan benar).
Sekarang buat indeks non-clustered di bidang dummy_int, "selaras" sesuai dengan skema partisi yang sama.
Mengapa kita membutuhkan indeks yang selaras?kita memerlukan indeks yang disejajarkan sehingga kita dapat melakukan operasi pengalihan bagian (switch) - dan ini adalah salah satu operasi yang, sering kali, mereka repot-repot dengan partisi. Jika ada setidaknya satu indeks yang tidak selaras dalam tabel, Anda tidak bisa mengganti bagian
create nonclustered index nix_pTest_dummyINT on pTest(dummy_int) on psTest(dt);
Dan mari kita lihat mengapa saya mengatakan bahwa pertanyaan Anda mungkin menjadi lebih lambat setelah penerapan sectioning. Jalankan permintaan:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 SET STATISTICS TIME, IO OFF;
Dan mari kita lihat statistik eksekusi:
Table 'ptest'. Scan count 3, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Dan rencana implementasi:

Karena indeks kami “disejajarkan” dengan bagian-bagian, secara kondisional, setiap bagian memiliki indeksnya sendiri, yang “tidak terhubung” dengan indeks pada bagian lain. Kami tidak memaksakan kondisi di lapangan di mana indeks dipartisi, jadi SQL Server dipaksa untuk mengeksekusi indeks pencarian di setiap bagian, pada kenyataannya, 3 indeks mencari bukannya satu.
Mari kita coba untuk mengecualikan satu bagian:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 and dt < '20180801' SET STATISTICS TIME, IO OFF;
Dan mari kita lihat statistik eksekusi:
Table 'ptest'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Ya, satu bagian dikecualikan dan pencarian untuk nilai yang diinginkan hanya dilakukan dalam dua bagian.
Ini adalah sesuatu yang harus diingat ketika memutuskan partisi. Jika Anda memiliki kueri yang tidak menggunakan batasan pada bidang di mana tabel dipartisi, Anda mungkin memiliki masalah.
Kami tidak lagi memerlukan indeks yang tidak berkerumun, jadi saya menghapusnya
drop index nix_pTest_dummyINT on pTest;
Dan mengapa diperlukan indeks non-cluster?secara umum, saya tidak membutuhkannya, saya bisa menunjukkan hal yang sama dengan indeks cluster, saya tidak tahu mengapa saya membuatnya, tetapi karena saya sudah membuatnya dan membuat screenshot - jangan menghilang
Sekarang pertimbangkan skenario berikut: kami mengarsipkan data dari tabel ini setiap 4 bulan - kami menghapus data lama dan menambahkan bagian untuk empat bulan ke depan (organisasi "jendela geser" dijelaskan dalam msdn dan tumpukan blog).
Kami membagi tugas menjadi subtugas kecil dan dapat dimengerti:
- Tambahkan bagian untuk data dari 01/01/2019 hingga 04/01/2019
- Buat tabel panggung kosong
- Ganti bagian data hingga 04/01/2018 di tabel panggung
- Singkirkan bagian yang kosong
Ayo pergi:
1. Kami mengumumkan bahwa bagian baru akan dibuat di filegroup FG1, karena akan segera dibebaskan dari kami:
alter partition scheme psTest next used [FG1];
Dan ubah fungsi partisi dengan menambahkan batas baru:
SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
Kami melihat statistik:
Table 'ptest'. Scan count 1, logical reads 76171, physical reads 0, read-ahead reads 753, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 7440, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Ada 8809 halaman di tabel (indeks cluster), jadi jumlah bacaan, tentu saja, di luar yang baik dan yang jahat. Mari kita lihat apa yang sekarang kita miliki di beberapa bagian.

Secara umum, semuanya seperti yang diharapkan - bagian baru dengan batas atas muncul (ingat bahwa kondisi batas untuk kita milik bagian kiri) 01/01/2019 dan bagian kosong di mana akan ada data lain dengan tanggal yang lebih panjang.
Segalanya tampak baik-baik saja, tetapi mengapa ada begitu banyak bacaan? Kami melihat dengan seksama pada gambar di atas, dan melihat bahwa data dari bagian ketiga yang ada di FG3 berakhir di FG1, tetapi bagian berikutnya, kosong, di FG3.
2. Buat tabel panggung.
Untuk mengalihkan (mengganti) bagian ke tabel dan sebaliknya, kita membutuhkan tabel kosong di mana semua batasan dan indeks yang sama dibuat seperti pada tabel partisi kita. Tabelnya harus dalam filegroup yang sama dengan bagian yang ingin kita “ganti” di sana. Bagian pertama (diarsipkan) terletak di FG1, jadi kami membuat tabel dan indeks klaster di tempat yang sama:
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id) on [FG1];
Anda tidak perlu mempartisi tabel ini.
3. Sekarang kami siap untuk berganti:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Dan inilah yang kami dapatkan:
4947, 16, 1, 59 ALTER TABLE SWITCH statement failed. There is no identical index in source table 'PartitionTest.dbo.pTest' for the index 'cix_stageTest_id' in target table 'PartitionTest.dbo.stageTest' .
Lucu, mari kita lihat apa yang ada di indeks:
select o.name tblName, i.name indexName, c.name columnName, ic.is_included_column from sys.indexes i join sys.objects o on i.object_id = o.object_id join sys.index_columns ic on ic.object_id = i.object_id and ic.index_id = i.index_id join sys.columns c on ic.column_id = c.column_id and o.object_id = c.object_id where o.name in ('pTest', 'stageTest')
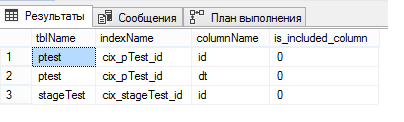
Ingat, saya menulis bahwa perlu membuat indeks berkerumun unik di tabel dipartisi? Itulah mengapa itu perlu. Saat membuat indeks berkerumun unik, SQL Server akan membutuhkan secara eksplisit termasuk kolom di mana kita mempartisi tabel dalam indeks, dan jadi dia menambahkannya sendiri dan lupa mengatakannya. Dan saya benar-benar tidak mengerti mengapa.
Tapi, secara umum, masalahnya bisa dimengerti, kami membuat ulang indeks cluster di atas meja panggung.
create clustered index cix_stageTest_id on stageTest(id, dt) with (drop_existing = on) on [FG1];
Dan sekarang, sekali lagi, kami mencoba untuk mengganti bagian:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Dam Ta! Bagian ini diaktifkan, lihat berapa biayanya:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Tapi tidak ada apa-apa. Mengalihkan bagian ke tabel kosong dan sebaliknya (tabel lengkap ke bagian kosong) adalah operasi semata-mata pada metadata dan inilah mengapa partisi adalah hal yang sangat, sangat keren.
Mari kita lihat ada apa dengan bagian kami:

Dan semuanya baik-baik saja dengan mereka. Di bagian pertama, ada nol catatan yang tersisa, mereka aman pergi ke tabel stageTest. Kita bisa melanjutkan
4. Yang tersisa bagi kami adalah menghapus bagian pertama kami yang kosong. Mari kita lakukan dan lihat apa yang terjadi:
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
Dan ini juga merupakan operasi hanya pada metadata, dalam kasus kami. Kami melihat bagian:

Kami hanya memiliki 3 bagian, masing-masing dalam grup file sendiri. Misi tercapai. Apa yang bisa diperbaiki di sini? Yah, pertama, saya ingin nilai batas merujuk ke bagian "benar", sehingga bagian tersebut berisi semua data selama 4 bulan. Dan saya ingin melihat pembuatan bagian baru lebih murah. Baca data sepuluh kali lebih banyak dari tabel itu sendiri - gagal.
Kami tidak dapat melakukan apa pun dengan yang pertama sekarang, tetapi dengan yang kedua kami akan mencoba. Mari kita membuat bagian baru yang akan berisi data dari 01/01/2019 hingga 04/01/2019, dan tidak sampai akhir waktu:
alter partition scheme psTest next used [FG2]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190401'); SET STATISTICS TIME, IO OFF;
Dan kita melihat:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
Ha! Jadi sekarang operasi ini hanya menggunakan metadata? Ya, jika Anda "membagi" bagian kosong - ini hanya operasi pada metadata, oleh karena itu akan menjadi keputusan yang tepat untuk menjaga bagian kiri dan kanan yang dijamin kosong dan, jika perlu, pilih yang baru - "potong" dari sana.
Sekarang mari kita lihat apa yang terjadi jika saya ingin mengembalikan data dari tabel stage kembali ke tabel dipartisi. Untuk melakukan ini, saya perlu:
- Buat bagian baru di sebelah kiri untuk data
- Pindahkan tabel ke bagian ini
Kami mencoba (dan ingat stageTest di FG1):
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20180401'); SET STATISTICS TIME, IO OFF;
Kita melihat:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 2939, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Yah, tidak buruk, mis. baca hanya bagian kiri (yang kita bagi) dan hanya itu. Baiklah Untuk mengganti tabel non-kosong yang tidak dipartisi menjadi bagian tabel yang dipartisi, tabel sumber harus memiliki batasan sehingga SQL Server tahu bahwa semuanya akan baik-baik saja dan beralih dapat dilakukan sebagai operasi pada metadata (daripada membaca semuanya dalam satu baris dan memeriksa apakah bagian tersebut sesuai dengan kondisi atau tidak) ):
alter table stageTest add constraint check_dt check (dt <= '20180401')
Mencoba beralih:
SET STATISTICS TIME, IO ON; alter table stageTest switch to pTest partition 1 SET STATISTICS TIME, IO OFF;
Statistik:
SQL Server Execution Times: CPU time = 15 ms, elapsed time = 39 ms.
Sekali lagi, operasi hanya pada metadata. Kami melihat ada apa dengan bagian kami:

Baiklah Tampaknya beres. Dan sekarang kita akan mencoba membuat ulang skema fungsi dan partisi (saya menghapus skema partisi dan fungsi, menciptakan kembali dan mengisi ulang tabel dan membuat kembali indeks klaster menggunakan skema partisi baru):
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
Mari kita lihat bagian apa yang kita miliki sekarang:

Nah, sekarang kita memiliki tiga bagian "logis" - dari awal waktu hingga 04/01/2018 00:00:00 (tidak termasuk), dari 04/01/2018 00:00:00 (inklusif) hingga 08/01/2018 00:00:00 ( tidak termasuk) dan yang ketiga, semua yang lebih besar dari atau sama dengan 01/01/2018 00:00:00.
Sekarang mari kita coba melakukan tugas yang sama dalam pengarsipan data yang kita lakukan dengan fungsi partisi sebelumnya.
1. Tambahkan bagian baru:
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
Kami melihat statistik:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 3685, physical reads 0, read-ahead reads 4, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Tidak buruk, setidaknya cukup - baca hanya bagian terakhir. Kami melihat apa yang kami miliki di bagian:

Perhatikan bahwa sekarang, bagian ketiga yang telah selesai tetap di FG3, dan bagian kosong baru telah dibuat di FG1.
2. Kami membuat tabel panggung dan indeks cluster CORRECT di atasnya
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id, dt) on [FG1];
3. Ganti bagian
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
Statistik mengatakan operasi metadata adalah:
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 5 ms.
Sekarang, semua tanpa kejutan.
4. Hapus bagian yang tidak perlu
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
Dan di sini kita punya kejutan:
Table 'ptest'. Scan count 1, logical reads 27057, physical reads 0, read-ahead reads 251, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Kami melihat apa yang kami miliki dengan bagian:

Dan ini menjadi jelas: bagian kami # 2 pindah dari filegroup fg2 ke filegroup fg1. Kelas Bisakah kita melakukan sesuatu tentang ini?
Mungkin kita hanya perlu selalu memiliki bagian kosong dan "menghancurkan" perbatasan antara bagian kiri "pernah kosong" dan bagian yang kita "beralih" ke tabel lain.
Kesimpulannya:- Gunakan sintaks lengkap untuk membuat fungsi partisi, jangan bergantung pada nilai default - Anda mungkin tidak mendapatkan apa yang Anda inginkan.
- Tetap di kiri dan kanan pada bagian yang kosong - mereka akan sangat berguna bagi Anda ketika mengatur "jendela geser".
- Pisahkan dan gabungkan bagian yang tidak kosong - itu selalu menyakitkan, hindari ini jika memungkinkan.
- Periksa kueri Anda - jika mereka tidak menggunakan filter oleh kolom di mana Anda berencana untuk mempartisi tabel dan Anda perlu kemampuan untuk beralih bagian - kinerjanya dapat menurun secara signifikan.
- Jika Anda ingin melakukan sesuatu, tes pertama tidak dalam produksi.
Semoga materi itu bermanfaat. Mungkin ternyata menjadi kusut, jika Anda berpikir bahwa sesuatu yang dinyatakan tidak diungkapkan, tulis, saya akan mencoba menyelesaikannya. Terima kasih atas perhatian anda