Web modern hampir tidak terpikirkan tanpa konten media: hampir setiap nenek kita memiliki telepon pintar, semua orang duduk di jejaring sosial, dan waktu henti layanan mahal untuk perusahaan. Yang menarik perhatian Anda adalah transkrip cerita Badoo tentang bagaimana mengatur pengiriman foto menggunakan solusi perangkat keras, masalah kinerja apa yang ditemui dalam proses, apa yang menyebabkannya, dan bagaimana masalah ini diselesaikan menggunakan solusi perangkat lunak berbasis Nginx, sambil memastikan toleransi kesalahan di semua tingkatan ( video ). Kami berterima kasih kepada penulis cerita Oleg Sannis Efimov dan Alexander Dymov, yang berbagi pengalaman mereka di konferensi Uptime day 4 .
Web modern hampir tidak terpikirkan tanpa konten media: hampir setiap nenek kita memiliki telepon pintar, semua orang duduk di jejaring sosial, dan waktu henti layanan mahal untuk perusahaan. Yang menarik perhatian Anda adalah transkrip cerita Badoo tentang bagaimana mengatur pengiriman foto menggunakan solusi perangkat keras, masalah kinerja apa yang ditemui dalam proses, apa yang menyebabkannya, dan bagaimana masalah ini diselesaikan menggunakan solusi perangkat lunak berbasis Nginx, sambil memastikan toleransi kesalahan di semua tingkatan ( video ). Kami berterima kasih kepada penulis cerita Oleg Sannis Efimov dan Alexander Dymov, yang berbagi pengalaman mereka di konferensi Uptime day 4 .- Mari kita mulai dengan pengantar singkat tentang bagaimana kita menyimpan dan menyimpan foto. Kami memiliki lapisan tempat kami menyimpannya, dan lapisan tempat kami menyimpan foto. Pada saat yang sama, jika kita ingin mencapai hit besar dan mengurangi beban pada seratus, penting bagi kita bahwa setiap foto pengguna individu terletak pada satu server caching. Kalau tidak, kita harus meletakkan disk sebanyak mungkin, berapa banyak server yang kita miliki. Kami memiliki hit rate sekitar 99%, yaitu, kami mengurangi beban pada penyimpanan kami hingga 100 kali, dan untuk melakukan ini, bahkan 10 tahun yang lalu, ketika semua ini dibangun, kami memiliki 50 server. Oleh karena itu, untuk memberikan foto-foto ini, pada dasarnya kami membutuhkan 50 domain eksternal yang dilayani oleh server ini.
Tentu, pertanyaan segera muncul: jika satu server jatuh, itu tidak akan tersedia, lalu lintas apa yang hilang? Kami melihat apa yang ada di pasar dan memutuskan untuk membeli sepotong besi sehingga akan menyelesaikan semua masalah kami. Pilihan jatuh pada keputusan perusahaan jaringan F5 (yang, kebetulan, baru-baru ini membeli NGINX, Inc): BIG-IP Local Traffic Manager.

Apa yang dilakukan perangkat keras (LTM) ini: router besi yang melakukan redundansi besi pada port eksternal dan memungkinkan Anda untuk merutekan lalu lintas berdasarkan topologi jaringan, pada beberapa pengaturan, dan melakukan pemeriksaan kesehatan. Penting bagi kami bahwa potongan besi ini dapat diprogram. Dengan demikian, kita dapat menggambarkan logika bagaimana foto-foto pengguna tertentu diberikan dari cache tertentu. Seperti apa bentuknya? Ada sepotong besi yang terlihat di Internet melalui satu domain, satu ip, tidak ssl offload, mem-parsing permintaan http, dari IRule memilih nomor cache ke mana harus pergi, dan memungkinkan lalu lintas pergi ke sana. Pada saat yang sama, itu membuat pemeriksaan kesehatan, dan jika beberapa mesin tidak tersedia, kami membuat pada saat itu sehingga lalu lintas pergi ke satu server cadangan. Dari sudut pandang konfigurasi, tentu saja ada beberapa nuansa, tetapi secara umum semuanya cukup sederhana: kami meresepkan kartu, mencocokkan beberapa nomor dengan IP kami di jaringan, kami mengatakan bahwa kami akan mendengarkan pada port ke-80 dan ke-443, kami katakan, bahwa jika server tidak tersedia, maka Anda harus memulai lalu lintas pada cadangan, dalam hal ini yang ke-35, dan kami menggambarkan banyak logika bagaimana arsitektur ini harus dibongkar. Satu-satunya masalah adalah bahwa bahasa yang memprogram perangkat keras adalah Tcl. Jika ada yang ingat ini ... bahasa ini lebih baik dari pada bahasa yang nyaman untuk pemrograman:

Apa yang kita dapatkan? Kami memiliki perangkat keras yang menyediakan ketersediaan tinggi infrastruktur kami, merutekan semua lalu lintas kami, menyediakan layanan kesehatan dan hanya bekerja. Selain itu, telah bekerja cukup lama: selama 10 tahun terakhir tidak ada keluhan tentang hal itu. Pada awal 2018, kami sudah membagikan sekitar 80 ribu foto per detik. Ini adalah sekitar 80 gigabit lalu lintas dari kedua pusat data kami.
Namun ...
Pada awal 2018, kami melihat gambar jelek di tangga lagu: waktu respons foto jelas meningkat. Dan itu tidak lagi cocok untuk kita. Masalahnya adalah bahwa perilaku ini hanya terlihat di puncak lalu lintas - untuk perusahaan kami ini adalah malam dari hari Minggu hingga Senin. Tetapi sisa waktu, sistem berperilaku seperti biasa, tidak ada tanda-tanda kerusakan.

Namun demikian, masalahnya harus dipecahkan. Kami mengidentifikasi kemungkinan kemacetan dan mulai menghilangkannya. Pertama-tama, tentu saja, kami memperluas uplink eksternal, melakukan audit lengkap terhadap uplink internal, menemukan semua kemungkinan kemacetan. Tetapi semua ini tidak memberikan hasil yang jelas, masalahnya tidak hilang.
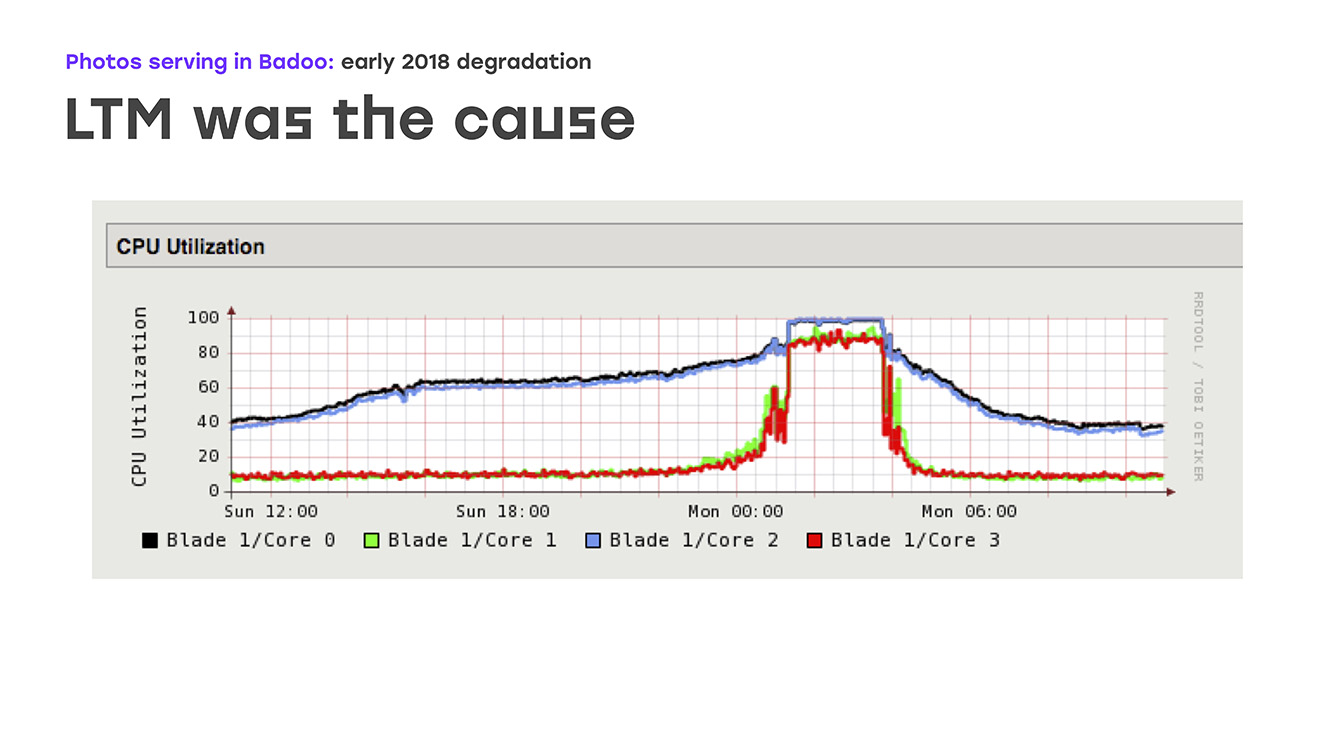
Hambatan lain yang mungkin terjadi adalah kinerja cache foto itu sendiri. Dan kami memutuskan bahwa mungkin masalahnya ada pada mereka. Yah, kami memperluas kinerjanya - terutama port jaringan pada cache foto. Tetapi sekali lagi, tidak ada perbaikan nyata yang terlihat. Pada akhirnya, kami sangat memperhatikan kinerja LTM itu sendiri, dan di sini kami melihat gambar yang menyedihkan pada grafik: memuat semua CPU mulai berjalan dengan lancar, tetapi kemudian tiba-tiba bersandar di rak. Pada saat yang sama, LTM berhenti merespons secara memadai terhadap pemeriksaan kesehatan dan tautan naik dan mulai mematikannya secara acak, yang mengarah pada penurunan kinerja yang serius.
Artinya, kami mengidentifikasi sumber masalah, mengidentifikasi kemacetan. Masih untuk memutuskan apa yang akan kita lakukan.
Hal pertama yang menunjukkan bahwa kita dapat mengambil adalah entah bagaimana memutakhirkan LTM itu sendiri. Tetapi ada beberapa nuansa, karena setrika ini cukup unik, Anda tidak akan pergi ke supermarket terdekat dan Anda tidak akan membelinya. Ini adalah kontrak terpisah, kontrak lisensi terpisah, dan itu akan memakan banyak waktu. Opsi kedua adalah mulai berpikir sendiri, menghasilkan solusi Anda sendiri pada komponen Anda, lebih disukai menggunakan program akses terbuka. Tetap hanya memutuskan apa yang akan kita pilih untuk ini dan berapa banyak waktu yang kita habiskan untuk menyelesaikan masalah ini, karena pengguna belum menerima foto. Karena itu, semua ini harus dilakukan dengan sangat, sangat cepat, bisa dikatakan - kemarin.
Karena tugasnya terdengar seperti "melakukan sesuatu secepat mungkin dan menggunakan perangkat keras yang kami miliki," hal pertama yang kami pikir adalah untuk menghapus beberapa bukan mesin yang paling kuat dari depan, letakkan Nginx dengan yang kami kami tahu cara bekerja, dan mencoba menerapkan semua logika yang biasa dilakukan oleh besi. Faktanya, kami meninggalkan perangkat keras kami, menyiapkan 4 server lagi yang harus kami konfigurasi, membuat domain eksternal untuk mereka, mirip dengan bagaimana 10 tahun yang lalu ... Kami kehilangan sedikit ketersediaan jika mesin-mesin ini mogok, tetapi kurang menyelesaikan masalah pengguna kami secara lokal.
Oleh karena itu, logikanya tetap sama: kita menempatkan Nginx, ia dapat melakukan SSL-offload, kita entah bagaimana dapat memprogram logika routing, pemeriksaan kesehatan pada konfigurasi dan hanya menduplikasi logika yang kita miliki sebelumnya.
Kami duduk untuk menulis konfigurasi. Pada awalnya tampaknya semuanya sangat sederhana, tetapi, sayangnya, sangat sulit untuk menemukan manual untuk setiap tugas. Karena itu, kami tidak menyarankan hanya google "cara mengkonfigurasi Nginx untuk foto": lebih baik merujuk ke dokumentasi resmi, yang akan menunjukkan pengaturan mana yang layak disentuh. Tetapi lebih baik memilih sendiri parameter tertentu. Nah, maka semuanya sederhana: kita menggambarkan server yang kita miliki, kita menggambarkan sertifikat ... Tapi yang paling menarik adalah, pada kenyataannya, logika perutean itu sendiri.
Pada awalnya, tampak bagi kami bahwa kami hanya menggambarkan lokasi kami, mencocokkan jumlah cache foto kami di dalamnya, menggambarkan dengan tangan kami atau generator berapa banyak hulu yang kami butuhkan, di setiap hulu kami menunjukkan server ke mana lalu lintas harus pergi, dan server cadangan jika server utama tidak tersedia:

Tapi, mungkin, jika semuanya akan begitu sederhana, kami hanya akan pulang dan tidak mengatakan apa-apa. Sayangnya, dengan pengaturan default Nginx, yang, secara umum, dibuat selama bertahun-tahun pengembangan dan tidak cukup untuk kasus ini ... konfigurasi terlihat seperti ini: jika beberapa server hulu memiliki kesalahan atau batas waktu permintaan, Nginx selalu mengalihkan lalu lintas ke yang berikutnya. Pada saat yang sama, setelah file pertama, server juga akan dimatikan selama 10 detik, baik karena kesalahan maupun oleh batas waktu - ini bahkan tidak dapat dikonfigurasi. Artinya, jika kita menghapus atau mengatur ulang opsi batas waktu dalam arahan hulu, maka meskipun Nginx tidak akan memproses permintaan ini dan akan menanggapi dengan beberapa kesalahan yang tidak terlalu baik, server akan dimatikan.

Untuk menghindari ini, kami melakukan dua hal:
a) mereka melarang Nginx untuk melakukan ini dengan tangan - dan sayangnya, satu-satunya cara untuk melakukan ini adalah dengan hanya mengatur pengaturan max gagal.
b) ingat bahwa dalam proyek lain kami menggunakan modul yang memungkinkan Anda melakukan pemeriksaan kesehatan latar belakang - oleh karena itu, kami melakukan pemeriksaan kesehatan yang cukup sering sehingga kami akan memiliki jumlah minimum jika terjadi kecelakaan.
Sayangnya, ini tidak semuanya, karena secara harfiah dua minggu pertama dari skema ini menunjukkan bahwa pemeriksaan kesehatan TCP juga merupakan hal yang tidak dapat diandalkan: bukan Nginx, atau Nginx dalam keadaan D dapat dinaikkan di server upstream, dalam hal ini kernel akan menerima koneksi, pemeriksaan kesehatan akan berlalu, tetapi tidak akan berfungsi. Oleh karena itu, kami segera menggantinya dengan pemeriksaan kesehatan http'shny, membuat yang spesifik, yang jika mengembalikan 200, maka semuanya berfungsi dalam skrip ini. Anda dapat melakukan logika tambahan - misalnya, dalam kasus caching server, verifikasi bahwa sistem file sudah terpasang dengan benar:

Dan itu cocok untuk kita, kecuali bahwa pada saat itu sirkuit benar-benar mengulangi apa yang dilakukan oleh potongan besi itu. Tapi kami ingin melakukan yang lebih baik. Sebelumnya, kami memiliki satu server cadangan, dan mungkin ini tidak terlalu baik, karena jika Anda memiliki seratus server, maka ketika beberapa crash sekaligus, satu server cadangan tidak mungkin mengatasi beban. Oleh karena itu, kami memutuskan untuk mendistribusikan reservasi di semua server: kami baru saja membuat hulu terpisah, mencatat semua server dengan parameter tertentu di sana sesuai dengan jenis beban yang dapat mereka tangani, menambahkan pemeriksaan kesehatan yang sama seperti yang kami miliki sebelumnya :

Karena tidak mungkin untuk pergi ke hulu lain di dalam satu hulu, perlu untuk memastikan bahwa jika hulu utama tidak tersedia, di mana cache foto yang benar ditulis, kami hanya mundur melalui error_page, dari mana kami pergi ke cadangan April:

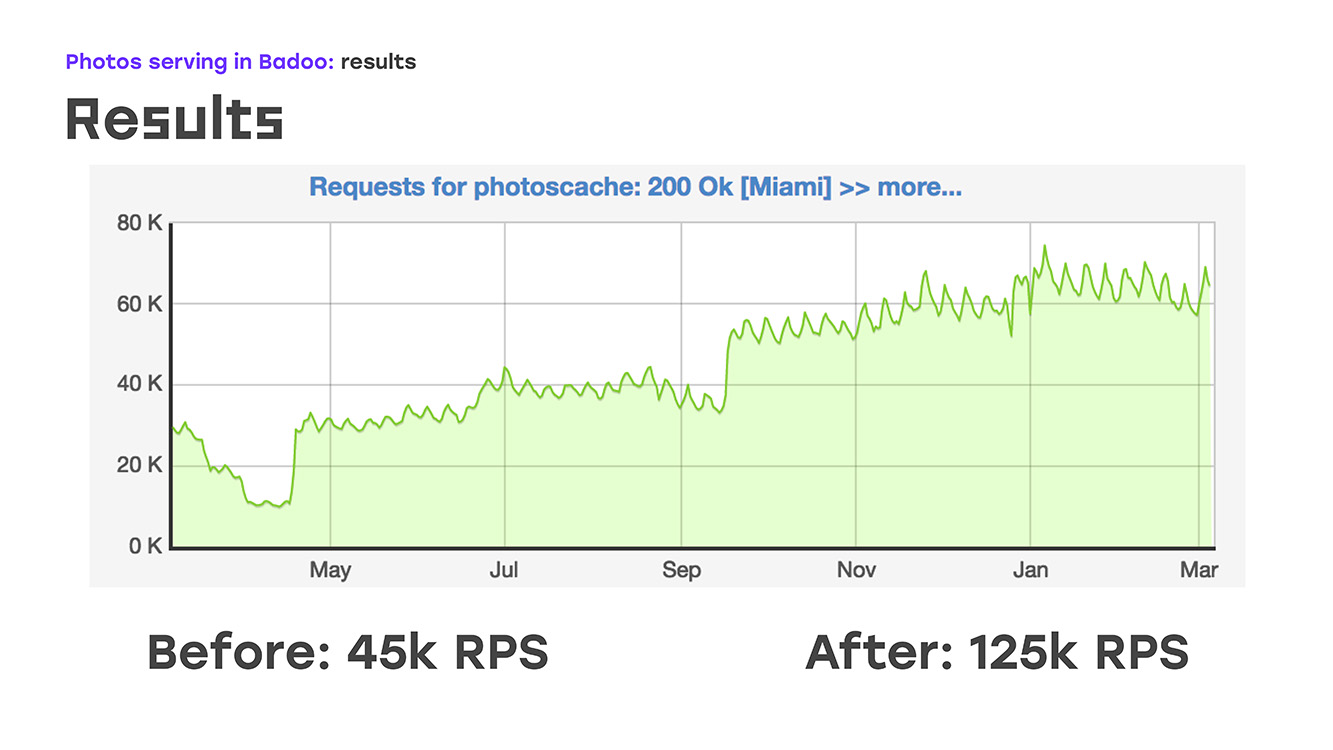
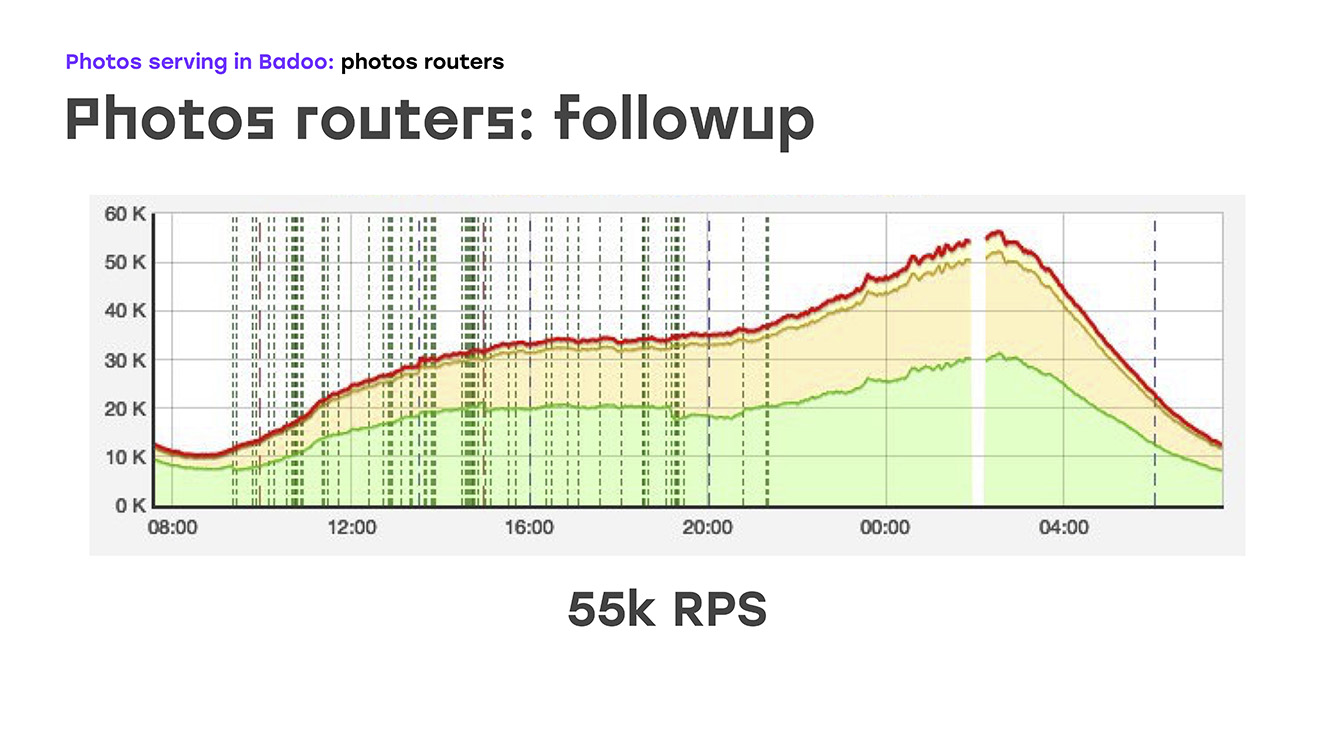
Dan secara harfiah menambahkan empat server, kami mendapatkan ini: kami mengganti bagian dari beban - dihapus dari LTM ke server ini, menerapkan logika yang sama di sana menggunakan perangkat keras dan perangkat lunak standar, dan segera mendapatkan bonus bahwa server ini dapat diskalakan karena mereka dapat dengan mudah letakkan sebanyak yang Anda butuhkan. Yah, satu-satunya negatif adalah bahwa kami telah kehilangan ketersediaan tinggi untuk pengguna eksternal. Tetapi pada saat itu saya harus mengorbankan ini, karena saya harus segera menyelesaikan masalah. Jadi, kami menghapus sebagian dari beban, ini sekitar 40% pada waktu itu, LTM merasa baik, dan secara harfiah dua minggu setelah dimulainya masalah, kami mulai mengirim bukan 45rb permintaan per detik, tetapi 55rb. Faktanya, kami tumbuh sebesar 20% - ini jelas lalu lintas yang tidak kami berikan kepada pengguna. Dan setelah itu mereka mulai berpikir bagaimana menyelesaikan masalah yang tersisa - untuk menyediakan aksesibilitas eksternal yang tinggi.
Kami memiliki jeda selama kami membahas solusi mana yang akan kami gunakan untuk ini. Ada saran untuk memastikan keandalan menggunakan DNS, menggunakan beberapa skrip yang ditulis sendiri, protokol perutean dinamis ... ada banyak pilihan, tetapi menjadi jelas bahwa untuk hasil foto yang benar-benar andal Anda perlu memperkenalkan lapisan lain yang akan memantau ini. Kami menyebut direksi foto mesin ini. Karena perangkat lunak yang kami andalkan, saya memilih Keepalived:

Untuk mulai dengan - terdiri dari apa Keepalived. Yang pertama adalah protokol VRRP, yang dikenal luas oleh penggiat jejaring, yang terletak pada peralatan jaringan yang memberikan toleransi kesalahan untuk alamat IP eksternal tempat klien terhubung. Bagian kedua adalah IPVS, server virtual IP, untuk menyeimbangkan antara router foto dan memastikan toleransi kesalahan pada tingkat ini. Dan yang ketiga adalah pemeriksaan kesehatan.
Mari kita mulai dengan bagian pertama: VRRP - seperti apa tampilannya? Ada IP virtual tertentu di mana ada entri di dns badoocdn.com di mana klien terhubung. Pada titik waktu tertentu, kami memiliki alamat IP pada satu server. Paket yang disimpan berjalan antara server menggunakan protokol VRRP, dan jika wizard menghilang dari radar - server reboot atau sesuatu yang lain, server cadangan secara otomatis meningkatkan alamat IP ini dari dirinya sendiri - tidak diperlukan langkah manual. Master dan cadangan berbeda, terutama prioritas: semakin tinggi, semakin besar kemungkinan bahwa mesin akan menjadi master. Keuntungan yang sangat besar adalah bahwa tidak perlu mengkonfigurasi alamat IP pada server itu sendiri, cukup untuk menggambarkannya dalam konfigurasi, dan jika pada saat yang sama alamat IP memerlukan beberapa aturan perutean kustom, ini dijelaskan secara langsung dalam konfigurasi, sintaksis yang sama seperti yang dijelaskan dalam paket VRRP. Anda tidak akan menemukan hal-hal yang tidak dikenal.
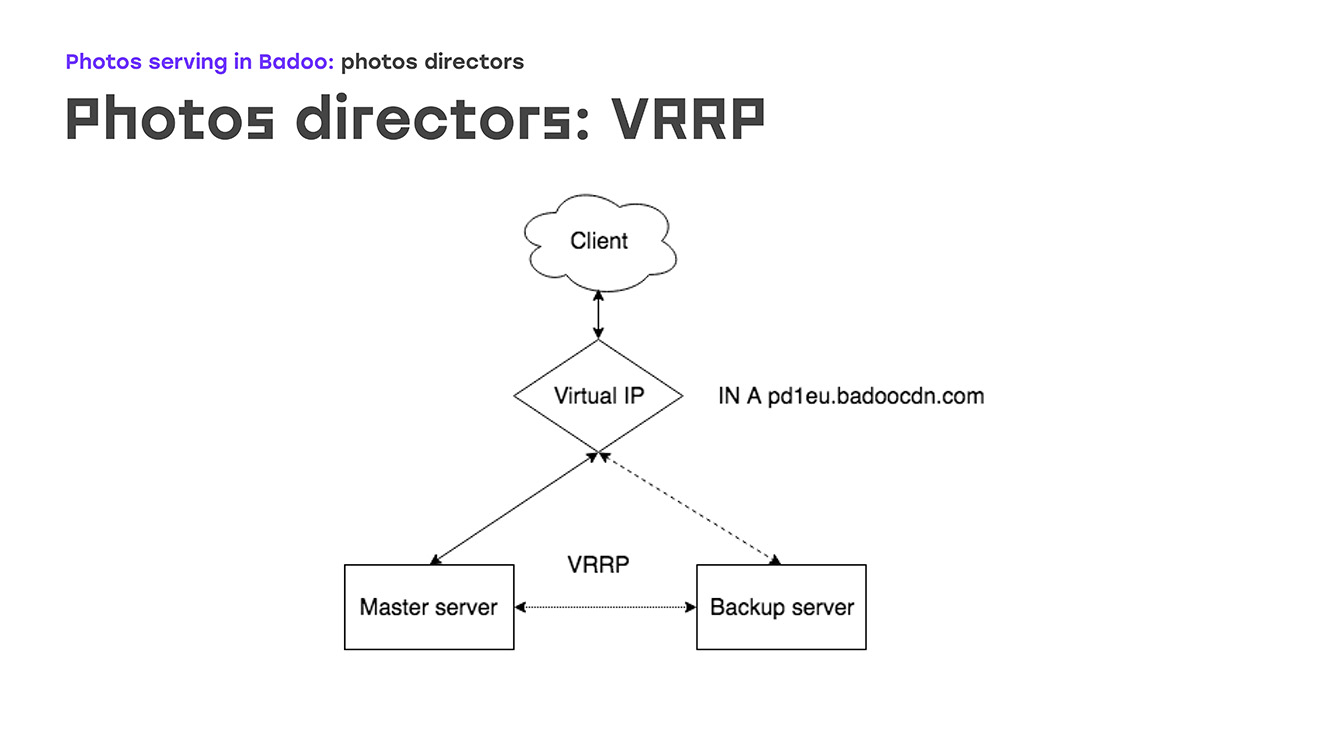
Seperti apa praktiknya? Apa yang terjadi jika salah satu server mati? Segera setelah master menghilang, cadangan kami berhenti menerima iklan dan secara otomatis menjadi master. Setelah beberapa waktu, kami memperbaiki master, reboot, mengangkat Keepalived - iklan datang dengan prioritas yang lebih tinggi daripada cadangan, dan cadangan otomatis kembali, menghapus alamat IP, tidak ada tindakan manual yang diperlukan.

Dengan demikian, kami memastikan toleransi kesalahan dari alamat IP eksternal. Bagian selanjutnya adalah entah bagaimana menyeimbangkan lalu lintas ke router foto yang sudah menghentikannya dari alamat IP eksternal. Dengan protokol balancing, semuanya cukup jelas. Ini bisa berupa round-robin sederhana, atau hal-hal yang sedikit lebih rumit, wrr, koneksi daftar, dan sebagainya. Ini dijelaskan pada prinsipnya dalam dokumentasi, tidak ada yang istimewa. Tetapi metode pengiriman ... Di sini kami tinggal lebih detail - mengapa mereka memilih salah satu dari mereka. Ini adalah NAT, Direct Routing dan TUN. Faktanya adalah bahwa kami segera meletakkan pada pengembalian 100 gigabit lalu lintas dari situs. Jika ini diperkirakan, Anda memerlukan 10 kartu gigabit, bukan? 10 kartu gigabit dalam satu server - ini sudah di luar ruang lingkup setidaknya konsep “peralatan standar” kami. Dan kemudian kami ingat bahwa kami tidak hanya membagikan lalu lintas, kami juga memberikan foto.
Apa fiturnya? - Perbedaan besar antara lalu lintas masuk dan keluar. Lalu lintas masuk sangat kecil, keluar sangat besar:
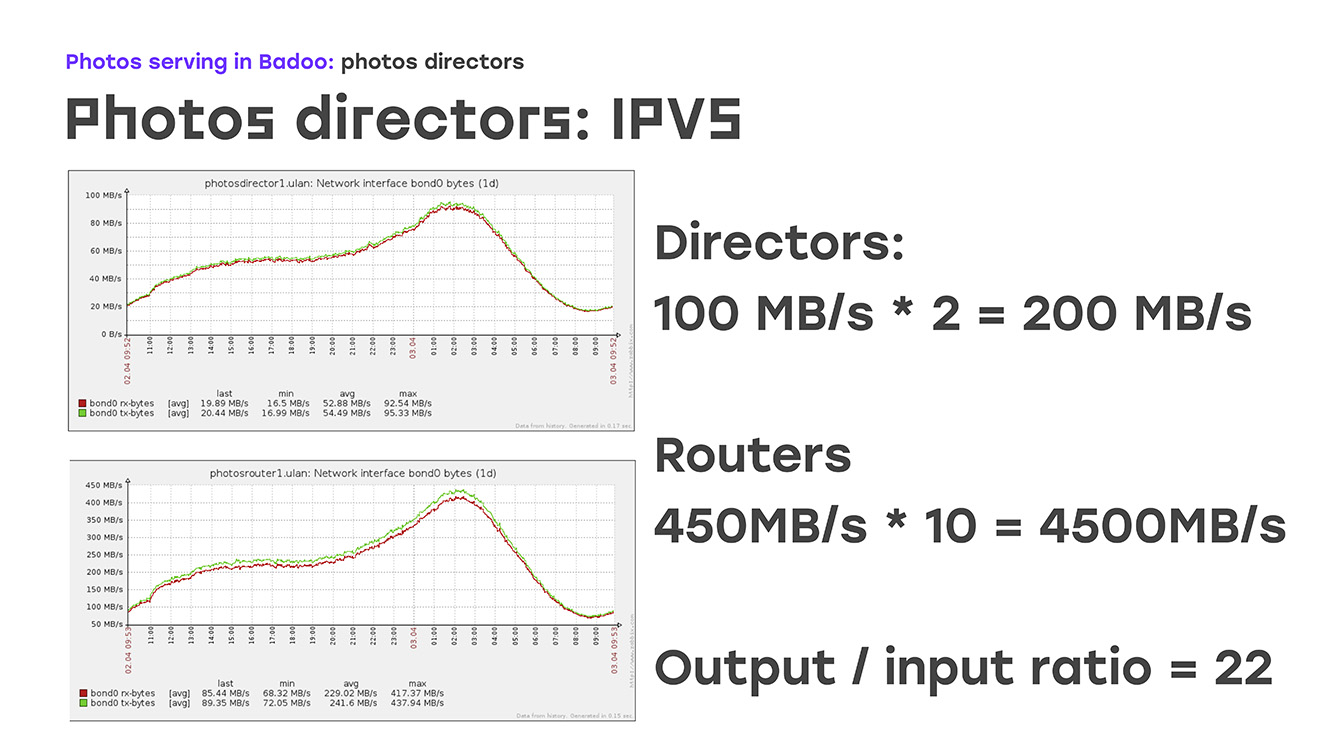
Jika Anda melihat grafik ini, Anda dapat melihat bahwa saat ini sekitar 200 MB per detik akan datang ke sutradara, ini adalah hari yang paling biasa. Kami memberikan kembali 4.500 MB per detik, rasionya sekitar 1/22. Sudah jelas bahwa bagi kami untuk sepenuhnya memastikan lalu lintas keluar ke 22 server yang berfungsi, satu yang menerima koneksi ini sudah cukup. Di sini algoritma perutean langsung, algoritma perutean, membantu kami.
Seperti apa bentuknya? Menurut tabel kami, direktur foto mentransfer koneksi ke router foto. Tetapi router foto mengirim lalu lintas balik langsung ke Internet, mengirimkannya ke klien, tidak kembali melalui foto direktur, sehingga, dengan jumlah minimum mesin, kami memberikan toleransi kesalahan yang lengkap dan memompa semua lalu lintas. Dalam konfigurasi itu terlihat seperti ini: kami menentukan algoritma, dalam kasus kami ini adalah rr sederhana, kami menyediakan metode routing langsung dan kemudian kami mulai mendaftar semua server nyata, berapa banyak yang kami miliki. Yang akan menentukan traffic ini. Jika kami mendapatkan satu atau dua server lagi di sana, kebutuhan seperti itu muncul - kami hanya menambahkan bagian ini di konfigurasi dan kami tidak terlalu khawatir. Pada bagian dari server nyata, pada bagian dari router foto, metode ini memerlukan konfigurasi yang sangat minimal, itu dijelaskan dengan sempurna dalam dokumentasi, dan tidak ada jebakan di sana.
Apa yang sangat baik - solusi seperti itu tidak menyiratkan perubahan radikal dari jaringan lokal, itu penting bagi kami, kami harus menyelesaikannya dengan biaya minimal. Jika Anda melihat
output dari perintah admin IPVS , kita akan melihat tampilannya. Di sini kita memiliki server virtual, pada port 443, ia mendengarkan, menerima koneksi, semua server yang bekerja terdaftar, dan jelas bahwa koneksinya sama, plus atau minus. Jika kita melihat statistik pada server virtual yang sama, kita memiliki paket masuk, koneksi masuk, tetapi sama sekali tidak ada yang keluar. Koneksi keluar langsung ke klien. Ya, kami bisa tidak seimbang. Sekarang, apa yang terjadi jika salah satu router foto mengalami kegagalan? Bagaimanapun, besi adalah besi. Ini mungkin menjadi panik kernel, mungkin rusak, catu daya mungkin terbakar. Apa saja. Untuk ini, pemeriksaan kesehatan diperlukan. Mereka dapat berupa yang paling sederhana - memeriksa bagaimana port terbuka dengan kami - atau beberapa yang lebih kompleks, hingga beberapa skrip yang ditulis sendiri yang bahkan akan memeriksa logika bisnis.
Kami berhenti di suatu tempat di tengah: kami memiliki permintaan https untuk lokasi tertentu, sebuah skrip dipanggil jika ia merespons dengan jawaban ke-200, kami percaya bahwa semuanya normal dengan server ini, bahwa ia hidup dan Anda dapat menyalakannya dengan cukup tenang.
Bagaimana itu, sekali lagi, terlihat dalam praktek. Matikan server, misalkan untuk layanan - flashing BIOS, misalnya. Dalam log, kami segera memiliki batas waktu, kami melihat baris pertama, kemudian setelah tiga kali percobaan itu ditandai sebagai "terbalik", dan itu hanya dihapus dari daftar.

Ada perilaku yang mungkin kedua saat VS saja diatur ke nol, tetapi jika foto dikembalikan, itu tidak berfungsi dengan baik. Server naik, Nginx mulai di sana, di sana pemeriksaan kesehatan memahami bahwa koneksi berlalu, bahwa semuanya baik-baik saja, dan server muncul dalam daftar kami, dan beban secara otomatis mulai diterapkan segera. Pada saat yang sama, tidak ada tindakan manual yang diperlukan dari administrator yang bertugas. Di malam hari, server reboot - departemen pemantauan tidak menghubungi kami tentang hal ini di malam hari. Mereka menginformasikan bahwa itu adalah, semuanya normal.
, , .
, , , . , Keepalivede, , , DBus, SMTP, SNMP, Zabbix'. , , , - , , , IP- . , , . nginx -, . , , : -, health-check' , , , , - - . - , amazon -, , , anomaly detection, , machine learning, , , , , , . .
: , , , - , , , HTTPS health-check'. , , , , , .
? 2018-. , , LTM, - 40 60 , 2018- .