AntipovSN dan MihhaCF
Bagian dua, di mana Athos memiliki semua aturan, tetapi Count de la Fer kehilangan sesuatu
UPD Bagian Satu ada di sini
UPD bagian tiga di sini
Pengantar dari penulis:
Selamat siang Hari ini kami melanjutkan serangkaian artikel yang ditujukan untuk penilaian dan penggunaan teori grafik di dalamnya. Anda dapat membiasakan diri dengan artikel pertama di sini .
Semua alegori komik, sisipan, dll. Dirancang untuk sedikit mengurangi narasi dan tidak membiarkannya jatuh ke dalam kuliah yang membosankan. Kami meminta maaf kepada semua orang yang tidak masuk ke humor kami
Tujuan artikel ini: dalam waktu tidak lebih dari 30 menit, untuk menggambarkan cara utama menyimpan data grafik dan menjelaskan aturan dan prinsip-prinsip membangun model kami untuk penilaian peminjam.
Ketentuan dan definisi:
- Tabel hash adalah struktur data yang mengimplementasikan antarmuka array asosiatif, yang memungkinkan Anda untuk menyimpan pasangan (kunci, nilai) dan melakukan tiga operasi: operasi menambahkan pasangan baru, operasi pencarian, dan operasi menghapus pasangan dengan kunci. Pencarian berdasarkan tabel hash, rata-rata, dilakukan selama O (1) waktu.
Auditor yang disewa oleh Korol PJSC untuk menilai kelayakan kredit One for All NPO mengalami beberapa masalah. Di satu sisi, sangat mudah untuk menggambarkan skema interaksi 10-15 perusahaan dan melakukan penilaian awal interaksi antara perusahaan, cukup untuk memiliki selembar kertas dan pena di tangan. Tetapi bagaimana jika Anda memiliki informasi tentang interaksi puluhan atau ratusan ribu perusahaan? Misalnya, jika Anda perlu menggambarkan interaksi Aramis dengan semua gairah hidupnya atau D'artagnan dengan semua orang yang ia lawan?
Bagaimana cara menyimpan data tentang interaksi ini?
Struktur dan pendekatan data apa yang digunakan?
Auditor harus menanamkan seluruh korps penulis monastik untuk pekerjaan ini.
Kami tidak akan melakukan ini dan akan memberi auditor kami pengetahuan dan teknologi masa depan ( kami akan mengirimkan Prometheus dalam bentuk T-800 kepada mereka, yang akan memberi mereka cahaya pengetahuan ).
Baiklah, mari kita mulai menjawab pertanyaan yang diajukan. Jadilah terang!
Saat kami menulis dan menggambar di sini , grafik adalah rasio 2 set - satu set node dan satu set tepi. Apa cara terbaik untuk menyimpan grafik?
Sebelum menjawab pertanyaan tentang cara menyimpan grafik, Anda perlu memutuskan apa yang ingin kami simpan dan dalam bentuk apa.
Menurut teori grafik, simpul grafik dapat berupa objek apa pun dengan set parameter apa pun (fakta ini akan berguna bagi kita nanti, untuk model lanjutan / adaptif untuk menghitung bola penilaian).
Jadi apa yang perlu kita simpan?
Minimal, pengidentifikasi simpul dan pengidentifikasi tetangganya (dengan siapa ia terkait). Kehadiran data ini sudah memungkinkan Anda untuk mencari lebar dan dalam.
Apakah saya perlu menyimpan data tepi grafik? Ya, jika kita berurusan dengan grafik berbobot. Dalam kasus kami, kami berurusan dengan grafik berbobot dan pada artikel pertama kami menggambar grafik seperti itu.
Apakah informasi ini cukup? Tidak.
Dari mana tulang rusuk itu berasal? Dalam buku teks, informasi ini ada di sana, seseorang telah mengumpulkan dan memprosesnya sebelum kita. Di akhir Abad Pertengahan kita (saat itu Musketeers hidup) tidak ada yang mau repot menghitung bobot tepi Count kita. Kita harus melakukannya sendiri. Dalam artikel ini dan artikel berikutnya, kami tidak akan menjelaskan metodologi spesifik untuk menghitung bobot satu sisi, ini akan dilakukan dalam artikel 4. Sekarang penting bagi kita untuk memutuskan informasi apa tentang grafik kita yang akan kita simpan.
Jadi, dalam kasus kami, ada tiga parameter utama yang perlu kita ketahui untuk menghitung skor penilaian dengan benar:
- Penilaian internal suatu simpul - terdiri dari indikator yang mengkarakterisasi simpul tersebut (omset, utang, denda, dll.) Dalam contoh kita, ini akan menjadi:
- Evaluasi - simpul baik atau buruk terkait dengan NPO "Satu untuk semua";
- Peringkat simpul - Raja memiliki peringkat tertinggi, Bonacieux - terendah;
- Volume dana, dengan kata lain, solvabilitas.
- Peringkat iga Dalam kasus kami, penilaian koneksi akan untuk setiap node - ini berarti bahwa hubungan Bonacieux - Constance mungkin tidak sama dengan koneksi Constance - Bonacieux, karena mereka memiliki kemungkinan berbeda untuk saling mempengaruhi.
- Level simpul - tidak akan disimpan, tetapi merupakan indikator penting.
Jangan tanya dari mana semua angka-angka ini berasal dari model, D'artanyan melihatnya. Dalam kehidupan nyata, indikator-indikator ini juga tidak akan dihitung oleh kami (perdagangan, utang, denda, dll., Kami ambil dari sumber yang ada, kami tidak berada di Abad Pertengahan, semacam).
Dari semua hal di atas, ternyata di samping pengidentifikasi node, kita harus menyimpan parameter setiap node dan bobot tepi yang kita dapatkan berdasarkan pada agregasi parameter dari node tersebut.
Total, informasi berikut dapat disimpan:
- Nama simpul;
- Parameter simpul
- Simpul tetangga;
- Berat iga untuk setiap tetangga.
Hebat! Kami menemukan apa yang perlu kami simpan. Sekarang - cara menyimpan.
Dan sekali lagi penyimpangan kecil.
Seperti apa proses penilaian kami dalam bentuk yang disederhanakan:
- Pengumpulan data objek;
- Pembentukan objek yang akan menggambarkan model grafik. Di fasilitas inilah kami akan melakukan semua operasi penilaian kami.
Berdasarkan dua langkah ini, kami memiliki tiga opsi:
- Kami menyimpan data tentang objek penilaian pada server SQL / NoSQL. Semua operasi yang terkait dengan perhitungan, algoritma, dll. Dilakukan langsung di server;
- Kami menyimpan data tentang objek penilaian pada server SQL / NoSQL. Berdasarkan data ini, kami membuat objek terpisah (misalnya, tabel hash) yang dengannya kami melakukan semua perhitungan dasar;
- Data tentang objek penilaian disimpan dalam RAM. Berdasarkan data ini, kami membuat objek terpisah (misalnya, tabel hash) yang dengannya kami melakukan semua perhitungan dasar.
Persyaratan dasar untuk proses ini:
- Kecepatan kerja;
- Keandalan
- Verifikasi.
Sekarang mari kita bicara. Kami akan duduk, seperti musketeer kami sambil minum apa yang mereka minum di sana, teh, misalnya. Yang utama adalah kita tidak mengganggu semua jenis ayam dengan para penjaga.
Jika penyimpanan jangka panjang diperlukan, maka Anda dapat memilih tabel dengan bidang signifikan yang sesuai. Dalam NoSQL atau RAM, lebih baik menyimpan data dalam bentuk daftar atau direktori (tabel hash) objek.
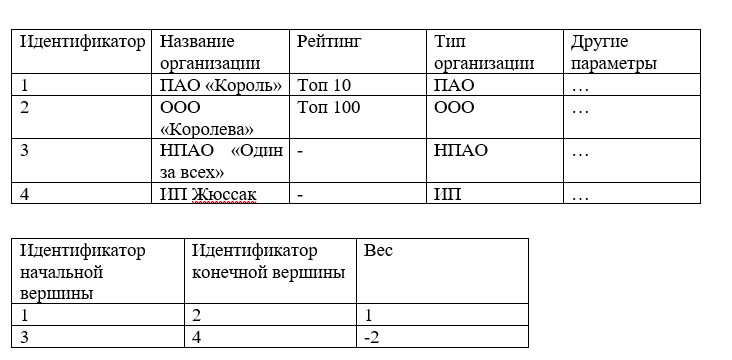
{ 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000 }
Dengan puncak lebih atau kurang jelas. Apa cara terbaik untuk mewakili lengkok / tepi grafik? Untuk melakukan ini, Anda perlu memahami prinsip dasar dari setiap operasi analitik pada grafik - akses ke busur / tepi harus terjadi dengan sangat cepat, diharapkan bahwa waktu akses sama dengan O (1). Array atau matriks langsung terlintas dalam pikiran - struktur di mana setiap elemen dapat diakses dengan cepat berdasarkan indeks.
[i, j] - elemen matriks menunjukkan busur dari grafik, di mana i adalah pengidentifikasi titik awal, j adalah pengidentifikasi titik akhir, akses dan pemilihan titik awal terjadi secara langsung oleh pengidentifikasi titik awal. Persimpangan i dan j menyimpan bobot tepi.
Ada beberapa kelemahan pada tampilan ini:
- Seringkali, strukturnya redundan, terutama jika grafiknya jarang (sejumlah kecil tepian), ada banyak nilai kosong yang menunjukkan bahwa tidak ada koneksi.
- Untuk menemukan semua tetangga vertex, perlu untuk memilah-milah semua elemen dari baris ke-i dari matriks hubungan.
- Matriks dengan banyak kolom tidak dapat disimpan dalam database.
Opsi selanjutnya untuk menyimpan busur / tepi adalah tabel, yaitu, kumpulan kolom dan baris.
Sebagai contoh:

Struktur seperti itu dapat dengan mudah disimpan dalam basis data relasional dan pilih nilai yang diperlukan ketika mengeksekusi query SQL, tetapi ketika menyangkut RAM, kompleksitas menemukan semua tepi verteks meningkat dan dalam kasus umum mengambil O (n) di mana n adalah jumlah semua tepi grafik.
Ada metode penyimpanan grafik lain yang sangat bagus untuk digunakan di hampir semua sistem, tanpa kekurangan yang dijelaskan di atas - ini adalah referensi nilai kunci atau tabel hash. Mendapatkan semua tepi dari simpul yang diinginkan terjadi dengan kecepatan O (1).
Sebuah kekurangan yang signifikan adalah bahwa tidak semua bahasa pemrograman mendukung desain ini.
Bagaimana seseorang dapat membayangkan struktur yang serupa dalam sistem yang berbeda?
Di database relasional, Anda bisa menerapkan hubungan tabel objek dan tepi (paragraf sebelumnya)
NoSQL
{ 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000, 'Relations': [{3,2}, {4,5}, … {n, -5}] }
Saat mengakses objek dengan kuncinya, kami segera mendapatkan satu set koneksinya. Jika kami memiliki grafik yang tidak berbobot, alih-alih larik objek, Anda dapat melewati larik pengidentifikasi tetangga Hubungan: [3,4, ... n]. Dalam bentuk referensi, kuncinya adalah nilainya, opsi ini mirip dengan yang sebelumnya. Dalam direktori, nilai kunci, Anda dapat menyimpan objek yang sama seperti pada contoh sebelumnya, kunci, tentu saja, akan menjadi pengidentifikasi titik (mungkin ada angka, mungkin ada string, dll., Yang memungkinkan sistem pengembangan tertentu). Juga di direktori Anda hanya dapat menyimpan array tautan, dan informasi tentang simpul di direktori lain.
Graf[1] = { 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000, 'Relations': [{3,2}, {4,5}, … {n, -5}] }
atau
graf['one_for_all'] = 'Relations': [{3,2}, {4,5}, … {n, -5}]
Sebagai contoh kami, kami memilih opsi untuk menyimpan data dalam RAM dengan membuat tabel hash untuk mencetak data. Hasil antara akan ditulis ke file di server.
Kami memiliki struktur penyimpanan yang buruk dan tidak terdefinisi dengan baik, sekarang saatnya untuk mencari tahu di mana harus mulai membangun model analitik kami. Mari kita mulai dengan yang sederhana - kita mendefinisikan interaksi dengan tetangga terdekat dan dengan tetangga tetangga (teman teman).
Dengan demikian, dimungkinkan untuk menentukan interaksi dengan semua simpul yang saling berhubungan. Menurut pengamatan kami, interaksi dengan tetangga yang lebih dalam dari level 2 hanya menarik dalam kasus-kasus khusus dan dihitung dengan metode lain. Kompleksitas perhitungan ini cukup besar 0 (2 ^ n).
Untuk menghitung bola, kami akan menggunakan algoritma pencarian kedalaman yang sedikit dimodifikasi.
Penyempurnaan akan sebagai berikut:
- Kita perlu menemukan bukan simpul tertentu, tetapi mengurutkan semua simpul ke kedalaman n, untuk tugas kita n = 2.
- Kita tidak boleh menyimpan informasi yang tidak perlu dan harus mengasumsikan bahwa perhitungan dapat dibuat untuk setiap simpul dalam grafik, sehingga tingkat simpul tidak akan disimpan dalam grafik.
- Jika 2 atau lebih jalur mengarah ke atas, maka semua jalur dievaluasi, karena kita berhadapan dengan komunikasi dua arah dan perlu untuk sepenuhnya mengevaluasi interaksi node.
- Anda harus dapat menentukan tingkat bersarang dari setiap titik untuk perhitungan tertentu.
Yah, baik, perhitungan teoretis dasar telah dibuat, bahkan jika mereka menganggap seseorang sesuatu yang sederhana dan dangkal. Tetapi bagi kami Gascons, ini semua penting dan menarik, hampir sama dengan memasuki Royal Musketeers.
Kami memberikan implementasi praktis. Satu untuk semua dan semua untuk satu!
Aku akan menemuimu! Kami pasti akan bertemu! Mungkin dalam 10 tahun atau 20! Tapi ketemu!
Artikel selanjutnya sudah dekat!