
Dalam
artikel sebelumnya
, saya menceritakan sejarah singkat tentang pengembangan produk internal dan eksternal DublGIS. Hari ini kita menyelami rincian pengembangan salah satu produk, yaitu, ekspor data. Saya akan berbicara tentang arsitektur proyek dan solusi teknis individual yang memungkinkan kami untuk secara bertahap mengembangkan proyek dan menyesuaikannya dengan perubahan persyaratan seiring waktu.
Ringkasan singkat dari artikel terakhir
Ada beberapa produk internal yang mengumpulkan sejumlah besar data peta, direktori organisasi, iklan, umpan balik pengguna, ulasan, foto, berbagai analitik. Produk-produk ini saling berkomunikasi melalui bus data atau melalui Rest Api. Dan ada proses ekspor terpisah yang mengumpulkan semua data ini dalam tumpukan, memproses dan menguraikannya dalam format yang diinginkan, mengemas dan membentuk "bundel" siap pakai untuk pengiriman ke produk akhirnya. Pengiriman dilakukan melalui server pembaruan untuk versi PC dan seluler, atau di backend online untuk, pada kenyataannya, versi online 2GIS.
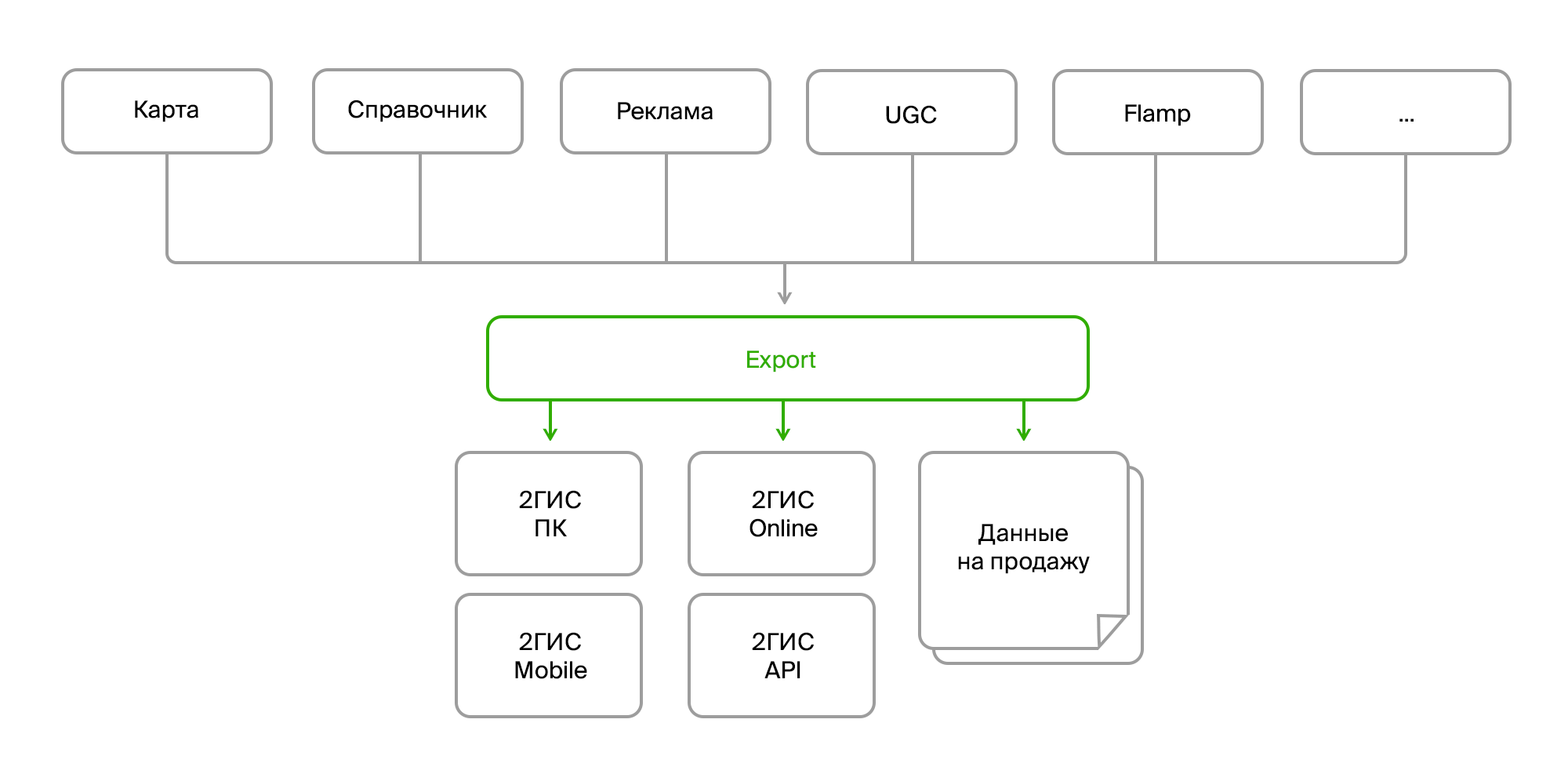
Sumber data
Jadi, di pintu masuk kami memiliki:
- beberapa sumber data yang sama;
- berbagai metode pengiriman (Firebird, bus, FTP, RestAPI);
- struktur berbeda dari objek yang sama;
- perubahan konstan dalam struktur data;
- format berbeda (data mentah dalam database, XML, JSON).
Dari sudut pandang konsumen:
- sekali lagi, format yang berbeda (format datanya untuk versi produk yang berbeda, format terpisah untuk dijual);
- perubahan format konstan;
- data agregat (Anda perlu menggabungkan objek yang berbeda menjadi satu, mengumpulkan data tentang perusahaan dari semua cabang, melengkapi mereka dengan tautan ke foto, ulasan, pemberhentian terdekat, dll.);
- pra-dan pasca-pemrosesan yang rumit (memperbarui beberapa data berdasarkan yang lain, mengonversi data, menghasilkan data yang hilang, misalnya, mengatur iklan mini-logo pada bangunan, menghapus atau memperbaiki data yang salah);
- persyaratan konsistensi dan validitas data;
- SEMUA data dibutuhkan.
Di sini perlu fokus pada paragraf terakhir. Seperti yang Anda ketahui, fitur utama 2GIS adalah pekerjaan offline. Artinya, sebagian besar data yang Anda lihat di versi PC dan seluler kami ada di perangkat Anda. Tapi ini adalah susunan besar: ratusan ribu objek geo (laut, hutan, sungai, jalan, bangunan, pintu masuk, beranda, tanda tangan, denah lantai, model 3D), puluhan dan ratusan ribu perusahaan dan cabangnya dengan kontak, jam kerja, atribut tambahan seperti tagihan rata-rata dan ketersediaan Wi-Fi. Dan, tentu saja, mengiklankan teks dan gambar.
Dan semuanya terus berubah, ditambahkan, dihapus.
Dan agar tidak tenggelam dalam arus perubahan tanpa akhir ini, ketika mengembangkan arsitektur ekspor, kami harus fokus pada beberapa bidang utama:
- sumber data;
- metode pengiriman;
- algoritma pemrosesan;
- format data konsumen.
Kami abstrak dari berbagai sumber dan format data
Berbagai sumber memperkenalkan kesulitan-kesulitan berikut:
- mereka memberikan data yang sama dalam berbagai format;
- memiliki sekumpulan entitas atau atribut yang berbeda yang perlu direduksi menjadi satu objek domain.
Ini adalah masalah yang cukup standar, dan diselesaikan sebagai standar. Kita hanya perlu membuat antarmuka untuk menerima data, dan implementasi spesifik sudah berjalan di tempat yang diperlukan dan akan mendapatkan data dalam bentuk yang kita butuhkan.

Contoh antarmuka:
public interface ISource : IDisposable { ISourceReader GetDeletedRows(); ISourceReader GetInsertedOrUpdatedRows(); byte[] GetDataVersion(); } public interface ISourceReader : IDisposable { bool Read(); object this[string columnName] { get; } }
Contoh penerapan perusahaan yang mendapatkan:
internal class FirmSetSource : ISource { public ISourceReader GetDeletedRows() { if(_lastDataVersion == null) return null; var query = DataContext.ExecuteObject<EsbFirmDeleted>(_lastDataVersion); return new DeletedIdsSourceReader<long>( query.Select(x => x.Id).GetEnumerator()); } public ISourceReader GetInsertedOrUpdatedRows() { return new EnumeratorSourceReader(typeof(FirmSet), GetNewOrChangedRows().GetEnumerator()); } public virtual byte[] GetDataVersion() { return DataContext.ExecuteObject<EsbFirm>().Max(x => x.RowVersion); } }
Abstraksi ini sebagian memungkinkan kita untuk menyelesaikan masalah dengan perbedaan dalam model domain, tetapi tidak sepenuhnya. Keterbatasan yang signifikan adalah kebutuhan untuk menerima data secara bertahap, yaitu, hanya menerima pembaruan mereka, dan tidak menghisap semuanya setiap saat. Dalam hal ini, agak tidak nyaman untuk melacak hubungan antara data untuk mengumpulkan beberapa agregat. Dan relatif sulit untuk melakukan semuanya tanpa kesalahan. Oleh karena itu, kami memutuskan bahwa pada tahap ini kami akan mengekstraksi data dari sumber satu ke satu, dan kami akan menyelesaikan masalah dengan model domain pada tingkat yang berbeda.
Model domain
Agar tidak bergantung pada perubahan dalam kumpulan data dan strukturnya dalam sumber data, basis data ekspor dibuat dengan daftar tabel yang relatif stabil, yang pada akhirnya jatuh pada domain kami. Jika sumber 1 tidak memiliki atribut untuk entitas A (Objek Data pada gambar berikutnya), maka mereka menerima nilai default atau opsional. Dan jika entitas B adalah semacam agregat dari data sumber atau bahkan sumber yang berbeda, maka setiap bagian dapat diperoleh secara terpisah dan kemudian dikumpulkan secara keseluruhan di tahap berikutnya.

Kami abstrak dari metode pengiriman data
Bahkan, memiliki database Anda sendiri dalam ekspor dan tampilan antarmuka
ISourceReader sudah menyelesaikan masalah ini. Tetapi ada satu titik yang tidak terselesaikan: model akuisisi data yang sedikit berbeda. Dalam satu kasus, kami menarik dan mendapatkan snapshot pada saat saat ini, di yang lain - delta perubahan pada bus, di ketiga - juga status saat ini pada saat permintaan, tetapi dengan informasi tentang objek yang dihapus dari saat permintaan sebelumnya.
Untuk membawa keseragaman ke kebun binatang ini, kami akan menambahkan satu lagi basis data yang akan kami gabungkan semua data dari semua sumber.
Anda mendapatkan gambar seperti itu.
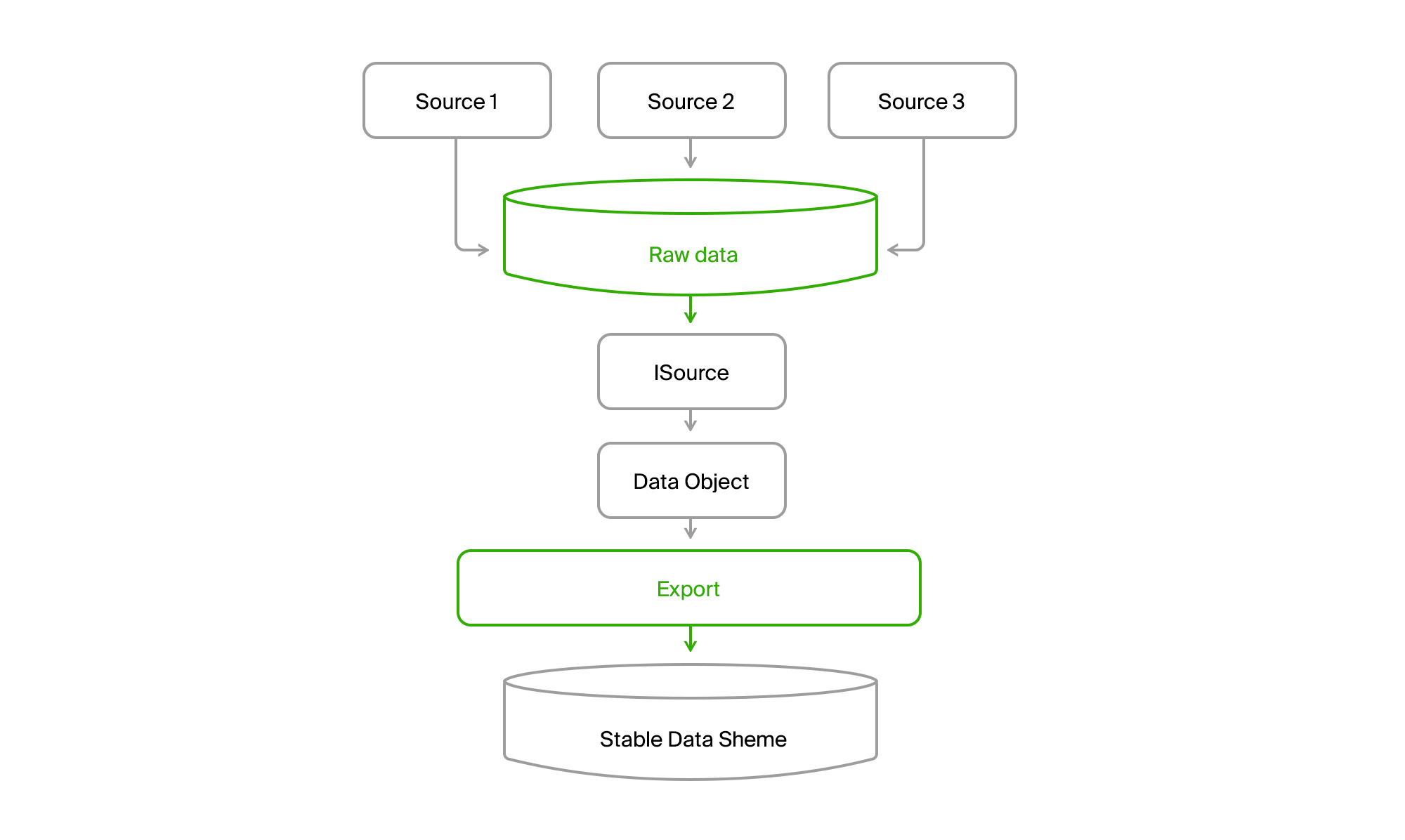
Akibatnya, kami membaca semua data dari saluran mana saja di semua kota ke basis data pusat. Hampir selalu pengiriman bersifat inkremental, yaitu hanya perubahan yang datang. DGPP lama, saat masih hidup, tetap menjadi sumber alternatif. Mampu memompa data dari satu DBMS ke yang lain tidak ada.
Selanjutnya, ekspor melalui ISource menarik data kota dari DGPP atau EMDB ke dalam basis data sinkronisasi yang stabil dan mengubahnya menjadi model domainnya.
Kemudian tinggal memprosesnya dan mengunggahnya dalam format konsumen.
Mengabstraksi dari algoritma persiapan data
Dan di sini muncul satu kesulitan lagi. Pertama, konsumen yang berbeda menginginkan data dalam format mereka. Selain itu, mereka menginginkan set data yang berbeda. Dan dalam lampiran, data offline harus sekompak dan terstruktur mungkin sehingga dapat dibaca dengan cepat. Sebagai hasilnya, kami mendapatkan format biner yang dikembangkan oleh tim produk akhir. Dan ini adalah orang-orang yang bekerja pada tumpukan teknologi yang sama sekali berbeda. Kami memiliki familiar dan tercinta untuk mengembangkan .NET backend dan terkadang Java, mereka terutama memiliki C ++ dan python.
Secara umum, kebun binatang teknologi.
Pada awal perkembangan pesat, ketika kami hanya memiliki DGPP (lihat
artikel sebelumnya) dan versi PC 2GIS, format data akhir adalah binar, yang disiapkan oleh perpustakaan khusus yang ditulis dalam C ++ dan dibungkus dengan objek COM. Tampaknya bukan integrasi kode heterogen. Kami menghubungkan referensi, antarmuka .NET dihasilkan - dan mengendarainya. Dan pertama kali kami melakukannya.
Tapi, seperti biasa, beberapa masalah muncul.
- Data kami mulai tumbuh dengan cepat. Jenis data baru muncul, kota-kota besar baru seperti Moskow.
- OS X64-bit mulai menyebar secara aktif.
- Masalah dalam COM perlu di-debug entah bagaimana.
Mari kita bahas poinnya.
Pertumbuhan data yang sangat dibutuhkan oleh produk kami telah menyebabkan fakta bahwa pemrosesan mereka mulai mengkonsumsi sejumlah besar RAM. Dan setelah menghubungkan pustaka COM ke proses .NET x86 kami, kami secara otomatis menerima proses x86, yaitu, maksimum operator 3Gb dengan ruang alamat yang ditingkatkan. Tim tidak memiliki dukungan pustaka untuk sumber daya x64, tetapi pustaka itu sendiri memiliki kemampuan untuk menggunakan disk, bukan memori, yang agak mengurangi masalah.
Tetapi debugging masih sangat sulit. Itu perlu untuk memulai ekspor, menunggu untuk menyiapkan data, mulai menambahkan data ini ke perpustakaan. Dan setelah kesalahan muncul, Anda perlu memahami dari log apa yang salah dan ulangi proses itu lagi. Tidak bagus, sangat buruk.
Solusinya seperti biasa di permukaan. Sudah cukup untuk mengambil semua kode asing ke dalam proses terpisah, dan menjalin komunikasi melalui file perantara dalam format biner atau teks sederhana.
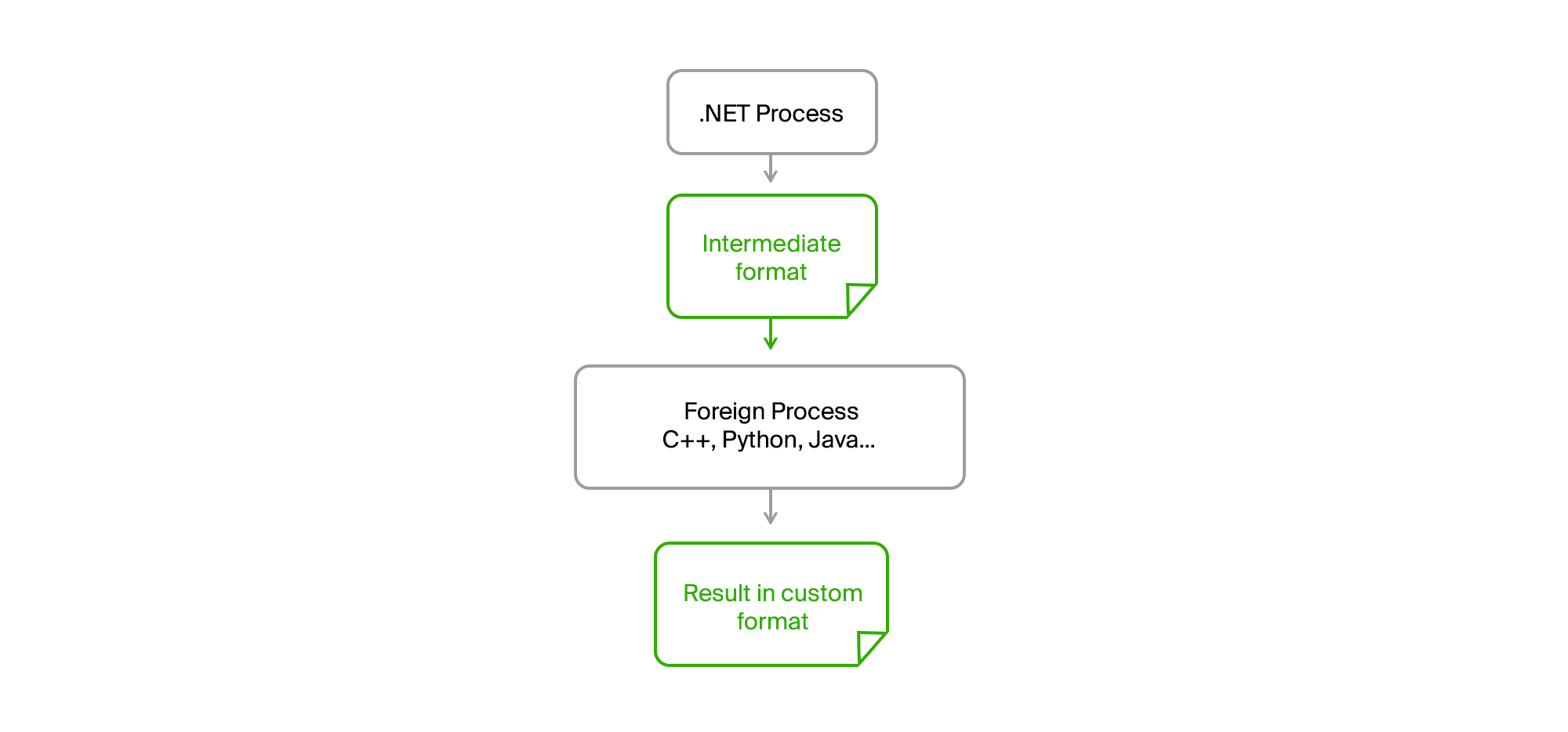
Akibatnya, proses .NET asli kami menjadi sepenuhnya cpu. Tidak ada kebocoran memori atau kesalahan kritis dalam kode pihak ketiga tidak lagi mempengaruhinya. Ekspor menyiapkan data, mengunggahnya ke file perantara, memasukkannya ke utilitas dan menerima hasilnya dari itu juga dalam bentuk file. Orang-orang dari tim pihak ketiga menulis algoritma mereka dalam bahasa mereka (C ++ atau Python) dan dapat men-debug mereka pada data nyata jika terjadi kesalahan pada mesin mereka tanpa perlu mulai mengekspor.
Kami hanya perlu membuat perjanjian pada antarmuka utilitas, yang disediakan dengan runtime, memiliki daftar parameter yang disepakati, dan menampilkan pesan informasi dan kesalahan dalam stdout dalam format yang diperlukan.
 Contoh format teks menengah
Contoh format teks menengahRingkasan
Dalam artikel itu, saya berbicara tentang beberapa pendekatan yang kami gunakan di berbagai tingkat aplikasi untuk mengisolasi proses persiapan data:
- menyembunyikan detail akses ke sumber data di balik antarmuka;
- diabstraksi dari saluran pengiriman data menggunakan penyimpanan perantara;
- buat domain stabil Anda dan konversikan data asli ke dalamnya;
- melakukan setiap tahapan pemrosesan data menjadi proses dan kode yang digunakan dalam bahasa lain.
Terima kasih sudah sampai di akhir. Saya akan menjawab semua pertanyaan di komentar, pastikan untuk bertanya.