Artikel ini menjelaskan proses penguraian kalimat bahasa Rusia menggunakan tata bahasa bebas konteks dan algoritma LR-analysis.
Pemrosesan bahasa alami adalah arah umum kecerdasan buatan dan linguistik matematika. Ini mempelajari masalah analisis komputer dan sintesis bahasa alami.
Secara umum, proses menganalisis kalimat bahasa alami adalah sebagai berikut: (1) memisahkan kalimat menjadi unit sintaksis - kata dan frasa; (2) penentuan parameter tata bahasa setiap unit; (3) definisi hubungan sintaksis antar unit. Outputnya adalah pohon parsing abstrak.
1. Memisahkan kalimat menjadi unit sintaksis
Kalimat bahasa alami terdiri dari bentuk kata dan frasa yang kuat. Sejumlah bentuk kata dari kata yang diberikan disebut paradigma.
Sebagai contoh
"": [, , , , , ]
Frasa - kata penghubung majemuk, predikat, atau ekspresi stabil - tidak berubah dan tidak dapat didekomposisi menjadi unit yang lebih kecil tanpa kehilangan makna. Lebih jauh, dengan kata yang kami maksud adalah unit sintaksis - bentuk kata atau frasa.
Setiap kata dalam kalimat ditentukan oleh tiga:
- bentuk kata / kata string ("wrote")
- bentuk kata normal ("tulis")
- satu set parameter gramatikal (['KATA KERJA', 'bernyanyi', 'musc', 'tran', 'masa lalu'])
Dengan demikian, rincian kalimat "
Jelas, dia tidak akan datang ke pertemuan " akan memiliki bentuk sebagai berikut:
[' ', '', '', '', '', ''] ' ' - ,
2. Definisi parameter gramatikal (tata bahasa)
Gramme adalah elemen dari kategori gramatikal; tata bahasa yang berbeda dari kategori yang sama bersifat eksklusif dan tidak dapat diungkapkan bersama. Untuk setiap bentuk kata, kami mendefinisikan satu set tujuh tata bahasa:
[ , , , , , , ]
Sebagai sumber, kita akan menggunakan kamus
OpenCorpora dan antarmuka-nya,
pymorphy2 . Untuk mencari aturan dalam tata bahasa untuk set gram yang diberikan, kami akan menyajikannya dalam bentuk umum:
'' [NOUN,plur,neut,accs] -> [NOUN,?numb,?per,?gend,accs,None,None] '?' ,
3. Definisi hubungan sintaksis antara kata-kata
Untuk menentukan hubungan sintaksis antara kata-kata, kita akan menggunakan tata bahasa bebas konteks dan analisis LR.
Analisis Tata Bahasa dan LR
Tata bahasa formal adalah cara menggambarkan bahasa dalam bentuk yang disebut produksi. Sebagai contoh:
a -> ab | ac
berarti aturan 'a' menumbuhkan 'ab' ATAU 'ac'.
Nonterminals adalah objek yang menunjukkan esensi dari bahasa (kalimat, formula, dll.).
Terminal - objek yang secara langsung hadir dalam bahasa yang sesuai dengan tata bahasa, dan memiliki makna yang spesifik dan tidak berubah (huruf, kata, rumus, dll.). Tata bahasa bebas konteks adalah tata bahasa di mana sisi kiri semua produk adalah non-terminal tunggal.
Untuk menggambarkan bahasa Rusia, kita akan menggunakan teori tata bahasa komponen (
frase structure grammar ), yang mengklaim bahwa setiap unit tata bahasa kompleks terdiri dari dua unit yang lebih sederhana dan tidak berpotongan, yang disebut komponen langsungnya. Komponen-komponen berikut dibedakan:
(1) Kelompok Nominal (NP) NP[case='nomn'] -> N[case='nomn'] | ADJ[case='nomn'] NP[case='nomn'] | …
Artinya, nomina nominaative nomina adalah nomina dalam nominative case ATAU kata sifat dalam nominative case + nominative nomina phrase ATAU other.
(2) Grup verbal (VP) VP[tran] -> V[tran] NP[case='ablt'] | ADJ VP[tran] | …
Dengan kata lain, grup kata kerja transitif adalah kata kerja transitif + grup kata benda ablatif ATAU kata sifat pendek + grup kata kerja transitif ATAU yang lain.
(3) Grup Preposisi (PP) PP -> PREP NP[case='datv'] | ...
Grup preposisi adalah preposisi + grup datif nominal ATAU yang lain.
(4) Penawaran penuh (S) S -> NP[case='nomn'] VP[tran]
Sebuah kalimat lengkap ada jika dan hanya jika kelompok kata benda dan kata kerja dicocokkan dalam jumlah, orang dan jenis kelamin.
def agreement(self, node_left, node_right): ... if (numb1 and numb2): if (numb1 != numb2): return False; if (per1 and per2): if (per1 != per2): return False; if (gend1 and gend2): if (gend1 != gend2): return False; return True;
Kalimat yang tidak lengkap adalah kalimat di mana bagian nominal dihilangkan. Sebagai aturan, dalam kalimat seperti itu, kata kerja grup diekspresikan oleh kata kerja impersonal. Misalnya, "
Saya ingin berjalan ," "Sudah
mulai terang ." Kalimat berbentuk bulat panjang adalah kalimat di mana bagian kata kerjanya dihilangkan, digantikan oleh tanda hubung. Misalnya, "
Di belakang belakang adalah hutan. Ke kanan dan kiri adalah rawa-rawa ."
Untuk menentukan apakah kalimat ini milik bahasa tata bahasa, kami akan menggunakan algoritma analisis LR. Algoritma ini melibatkan konstruksi pohon parsing dari bawah ke atas (dari daun ke akar). Elemen kunci dari algoritma ini adalah metode "transfer-convolution" (
pengurangan shift Inggris):
(1) kita membaca karakter dari jalur input sampai ada rantai yang cocok dengan sisi kanan aturan mana pun, letakkan rantai yang ditemukan di tumpukan (transfer);
(2) mengganti rantai yang ditemukan oleh aturan dari tata bahasa (konvolusi).
Jika semua rantai tali telah dibungkus, maka kalimat ini milik bahasa tata bahasa, dan setidaknya ada satu pohon parse.
PohonUntuk mewakili koneksi sintaksis, kalimat menggunakan pohon biner, di mana daun adalah kata-kata (terminal) dengan seperangkat gram, dan simpulnya adalah aturan (preterminal). Akar adalah kalimat (non-terminal).
Node pohon didefinisikan sebagai berikut:
class Node: def __init__(self, word=None, tag=None, grammemes=None, leaf=False): self.word = word;
Konstruksi pohon dimulai dengan dedaunan, yang diberi serangkaian kata atau frasa, serta seperangkat tata bahasanya.
def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)
Selanjutnya, analisis LR dilakukan. Setiap konvolusi sesuai dengan penyatuan dua simpul atau daun di bawah leluhur yang sama. Node leluhur diberikan tag preterminal yang sesuai dengan aturan tata bahasa, di samping itu, leluhur menerima tata bahasa dari anggota utama grup, misalnya, dalam grup kata kerja V [tran] PRCL (misalnya
"ingin" ) tanda-tanda akan diambil dari kata kerja transitif V [tran], dan bukan dari partikel PRCL; dan dalam grup kata benda NP [case = 'nomn'] NP [case = 'gent'] (misalnya
“bapak anak-anak” ) tanda-tanda akan diambil dari kata benda dalam nominatif.
Penting untuk dicatat bahwa konvolusi terjadi dalam urutan yang ditetapkan:
def reduce(self): self.reduce_ADJ() # self.reduce_NP() # self.reduce_PP() # self.reduce_VP() # self.reduce_S() #
Urutan ini penting karena tidak termasuk kemungkinan "kehilangan" beberapa anggota proposal. Pertama, kata sifat dibentuk bersama-sama dengan pengubah (misalnya
sangat indah ), kemudian kelompok nominal, preposisi dan akhirnya verbal. Setelah itu, ada pencarian untuk kalimat lengkap / tidak lengkap, jika tidak ada, maka pohon itu tidak memiliki akar, dan oleh karena itu kalimat itu bukan milik bahasa tata bahasa.
Pertimbangkan contoh kondisional untuk membangun pohon:
sent = " " def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)

NP[case='nomn'] -> NPRO[case='nomn'] NP[case='accs'] -> N[case='accs'] NP[case='datv'] -> ADJ[case='datv'] NP[case='datv']

VP[tran] -> V[tran] NP[case='accs']

VP[tran] -> VP[tran] NP[case='datv']

S -> NP[case='nomn'] VP[tran]
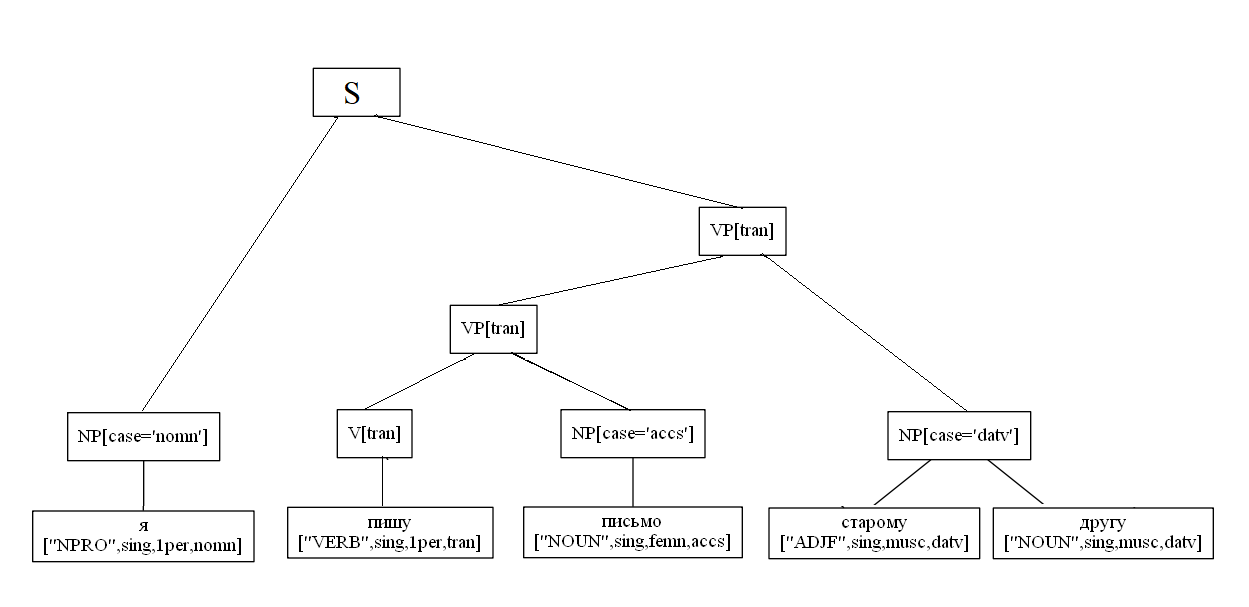
Contoh spesifik dari penguraian kalimat dua bagian:
import analyzer parser = analyzer.Parser() sent = " , ." t = parser.parse(sent) t[0].display() S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres'] NP[case='datv'] ['NOUN', 'sing', 'datv'] S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] PP PREP ['PREP'] NP[case='ablt'] ['NOUN', 'sing', 'femn', 'ablt'] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres']
Masalahnya
Bahasa alami bersifat ambigu, pemahamannya tergantung pada sejumlah faktor - pada fitur struktur tata bahasa, pada budaya nasional, pada pembicara, dll. Kami mencantumkan masalah utama pemrosesan bahasa mesin.
- Pengungkapan anafora. Seseorang yang hidup memahami anafora berdasarkan akal sehat dan konteks, tetapi bagi komputer ini jelas tidak selalu mudah.
- Homonim adalah kebetulan dalam bunyi dan ejaan unit linguistik yang maknanya tidak terkait satu sama lain. Salah satu solusinya adalah metode probabilistik. Dalam kalimat " Saya tahu ini dengan baik, " kemungkinan bahwa " ini " adalah kata ganti dan bukan partikel akan lebih besar. Metode semacam itu membutuhkan penutup yang cukup besar.
- Urutan kata-kata bebas mengarah pada fakta bahwa penafsiran kalimat mungkin ambigu. Misalnya, “ Menjadi menentukan kesadaran ” - apa yang menentukan apa? Di Rusia, urutan kata gratis dikompensasi oleh morfologi, kata layanan dan tanda baca yang dikembangkan, tetapi dalam kebanyakan kasus untuk komputer ini menimbulkan masalah tambahan.
- Tidak semua orang menulis dengan benar. Di internet, orang cenderung menggunakan singkatan, neologisme, elips, dan hal-hal lain yang mungkin bertentangan dengan norma sastra. Karena itu, penggunaan tata bahasa dan kamus bebas konteks tidak selalu memungkinkan.
Kesimpulan
Proyek
ini tersedia untuk digunakan dan diedit. Ini berisi alat analisis itu sendiri, pohon parse, serta tata bahasa Rusia dan tata bahasa Rusia dan kamus kecil gabungan serikat pekerja dan predikat yang tidak ada dalam kamus OpenCorpora. Saat ini, untuk kalimat yang panjang dan rumit, parser dapat menemukan 3 atau lebih pohon, untuk menyelesaikan masalah ini, perubahan dilakukan pada tata bahasa, dan juga direncanakan untuk menggunakan metode probabilistik.