Halo semuanya! Kami menerbitkan terjemahan dari artikel yang disiapkan untuk siswa dari kelompok baru kursus Insinyur Data . Jika Anda tertarik mempelajari cara membangun sistem pemrosesan data yang efisien dan scalable dengan biaya minimal, lihat rekaman kelas master oleh Yegor Mateshuk!

Beberapa minggu yang lalu saya menulis artikel tentang Hadoop, yang membahas berbagai hal
bagian dan mencari tahu apa perannya dalam bidang rekayasa data. Dalam artikel ini, saya
Saya akan memberikan deskripsi singkat tentang berbagai format file di Hadoop. Cepat dan mudah
topik. Jika Anda mencoba memahami cara kerja Hadoop dan tempat apa yang diperlukan dalam pekerjaan
Insinyur Data, lihat artikel saya di Hadoop di sini .
Format file Hadoop dibagi menjadi dua kategori: berorientasi baris dan kolom-
berorientasi.
Berorientasi baris:
Baris data dari satu jenis disimpan bersama, membentuk sebuah kontinu
penyimpanan: SequenceFile, MapFile, Avro Datafile. Jadi, jika perlu
akses hanya sejumlah kecil data dari satu baris, toh seluruh baris
akan dibaca ke dalam memori. Penundaan serialisasi dapat sampai batas tertentu
meringankan masalah, tetapi sepenuhnya dari overhead membaca seluruh baris data dengan
drive tidak akan bisa dihilangkan. Penyimpanan berorientasi baris
cocok dalam kasus di mana perlu untuk memproses seluruh baris pada saat yang sama
data.
Berorientasi pada kolom:
Seluruh file dibagi menjadi beberapa kolom data dan semua kolom data
disimpan bersama: Parket, RCFile, ORCFile. Format berorientasi kolom (kolom-
berorientasi), memungkinkan Anda untuk melewati kolom yang tidak perlu saat membaca data, yang cocok untuk
situasi ketika sejumlah kecil garis diperlukan. Tapi ini format membaca dan menulis
membutuhkan lebih banyak ruang memori karena seluruh baris cache harus ada dalam memori
(untuk mendapatkan kolom beberapa baris). Pada saat yang sama, itu tidak cocok untuk
streaming rekaman, karena setelah kegagalan perekaman file saat ini tidak dapat
dipulihkan, dan data yang berorientasi linear dapat digunakan kembali
disinkronkan dari titik sinkronisasi terakhir dalam hal terjadi kesalahan tulis, oleh karena itu,
misalnya, Flume menggunakan format penyimpanan berorientasi garis.

Gambar 1 (kiri). Tabel logis ditampilkan
Gambar 2 (kanan). Lokasi berorientasi baris (file urutan)

Gambar 3. Tata letak berorientasi kolom
Jika Anda belum sepenuhnya memahami apa itu orientasi kolom atau baris,
jangan khawatir. Anda dapat mengikuti tautan ini untuk memahami perbedaan di antara keduanya.
Berikut adalah beberapa format file yang banyak digunakan dalam sistem Hadoop:
File Urutan
Format penyimpanan berubah tergantung pada apakah penyimpanan dikompresi,
Apakah itu menggunakan kompresi tulis atau blok kompresi:

Gambar 4. Struktur internal file urutan tanpa kompresi dan dengan kompresi catatan.
Tanpa kompresi:
Menyimpan dalam urutan yang sesuai dengan panjang rekaman, Panjang kunci, Nilai derajat,
Nilai kunci dan Nilai nilai. Rentang adalah jumlah byte. Serialisasi
dilakukan dengan menggunakan yang ditentukan.
Rekam Kompresi:
Hanya nilai yang dikompresi, dan codec yang dikompresi disimpan di header.
Kompresi Blok:
Beberapa catatan dikompresi sehingga Anda dapat menggunakan
Manfaatkan kesamaan antara dua entri dan menghemat ruang. Bendera
sinkronisasi ditambahkan ke awal dan akhir blok. Nilai blok minimum
ditetapkan oleh atribut o.seqfile.compress.blocksizeset.

Gambar 4. Struktur internal file urutan dengan kompresi blok.
File peta
File peta adalah jenis file urutan. Setelah menambahkan indeks ke
file urutan dan pengurutannya menghasilkan file peta. Indeks disimpan sebagai terpisah
file, yang biasanya berisi indeks masing-masing dari 128 entri. Indeks mungkin
dimuat ke dalam memori untuk pengambilan cepat, karena file di mana data disimpan,
diatur dalam urutan yang ditentukan oleh kunci.
Entri file peta harus berurutan. Kalau tidak, kita
dapatkan IOException.
Jenis file peta yang diturunkan:
- SetFile: file peta khusus untuk menyimpan urutan kunci jenis ini
Tertulis Kunci ditulis dalam urutan tertentu. - ArrayFile: kuncinya adalah integer yang menunjukkan posisi dalam array, nilai
ketik dapat ditulis. - BloomMapFile: dioptimalkan untuk metode get () menggunakan file peta
filter Bloom dinamis. Filter disimpan dalam memori, dan metode yang biasa
get () dipanggil untuk membaca hanya jika nilai kuncinya
ada
File yang tercantum di bawah pada sistem Hadoop termasuk RCFile, ORCFile, dan Parket.
Versi berorientasi-kolom Avro adalah Trevni.
File RC
File Kolom Rekam Hive - jenis file ini pertama-tama membagi data menjadi kelompok-kelompok baris,
dan dalam grup baris, data disimpan dalam kolom. Strukturnya adalah sebagai berikut
cara:

Gambar 5. Lokasi data file RC dalam blok HDFS.
Bandingkan dengan baris murni dan berorientasi kolom:
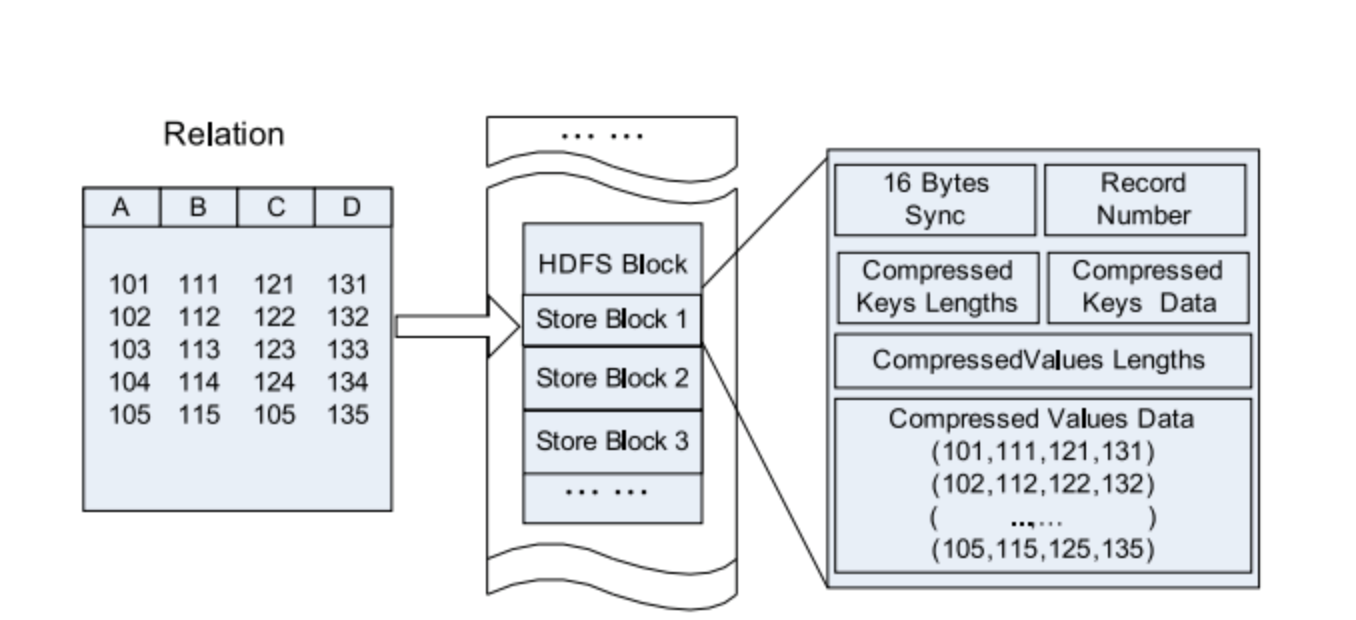
Gambar 6. Penyimpanan baris demi baris di blok HDFS.

Gambar 7. Pengelompokan berdasarkan kolom dalam blok HDFS.
File ORC
ORCFile (File Kolom Rekam yang Dioptimalkan) - adalah format yang lebih efisien
file dari rcfile. Secara internal membagi data menjadi strip masing-masing 250 juta.
Setiap jalur memiliki indeks, data, dan catatan kaki. Indeks menyimpan minimum dan
nilai maksimum setiap kolom, serta posisi setiap baris dalam kolom.

Gambar 8. Lokasi data dalam file ORC
Hive menggunakan perintah berikut untuk menggunakan file .orc:
Parket
Format penyimpanan berorientasi kolom generik berdasarkan Google Dremel.
Sangat bagus untuk memproses data dengan tingkat sarang yang tinggi.
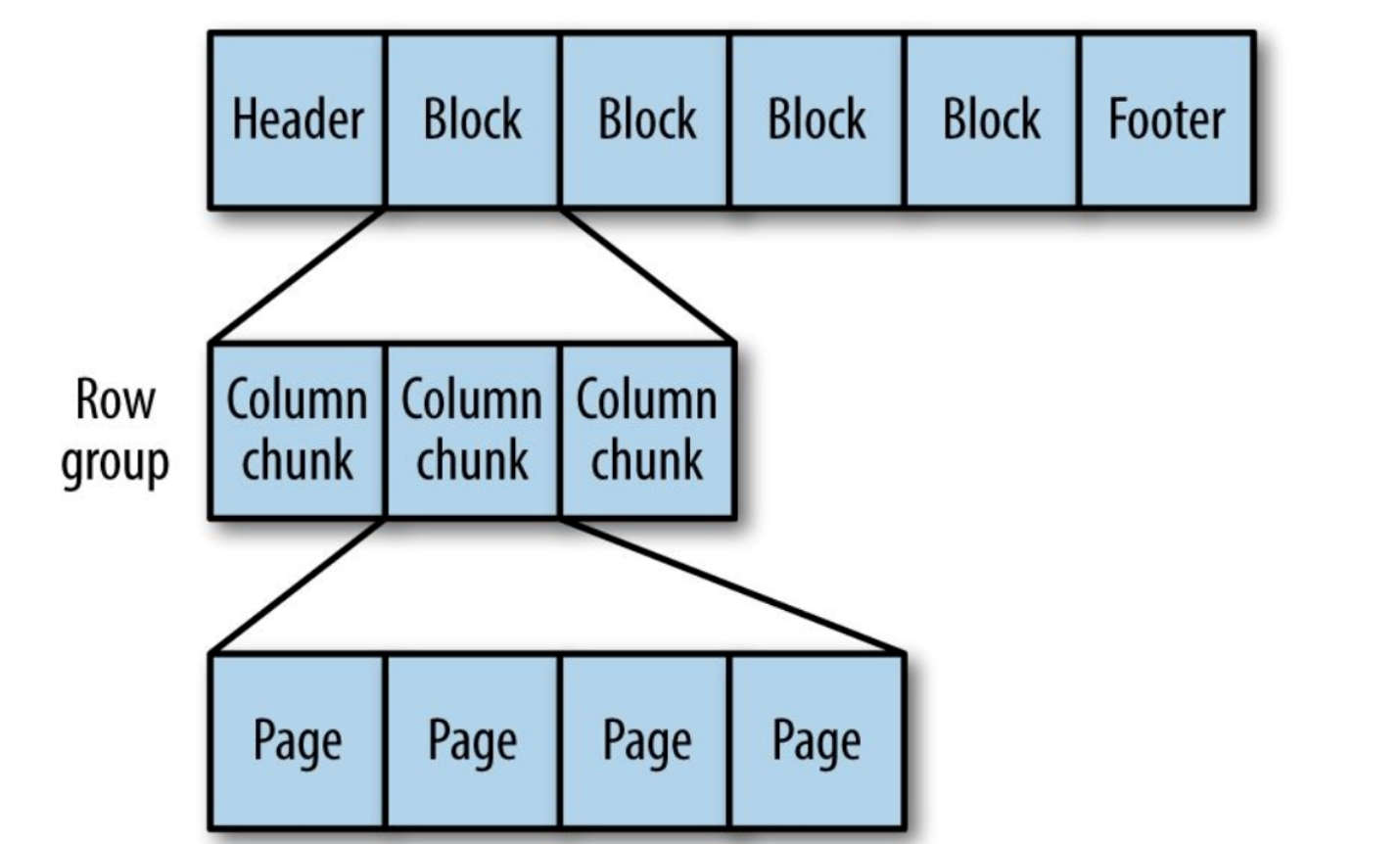
Gambar 9. Struktur internal file Parket.
Parket mengubah struktur bersarang menjadi penyimpanan kolom datar,
yang diwakili oleh tingkat Ulangi dan tingkat Definisi (R dan D) dan menggunakan
metadata untuk memulihkan catatan saat membaca data untuk memulihkan semua
file. Selanjutnya Anda akan melihat contoh R dan D:
AddressBook { contacts: { phoneNumber: “555 987 6543” } contacts: { } } AddressBook { }

Itu saja. Sekarang Anda tahu perbedaan dalam format file di Hadoop. Jika
menemukan kesalahan atau ketidakakuratan, jangan ragu untuk menghubungi
kepada saya. Anda dapat menghubungi saya di LinkedIn .