Catatan perev. : Materi ini melanjutkan serangkaian artikel indah dari penginjil teknologi AWS Adrian Hornsby, yang secara sederhana dan jelas menjelaskan pentingnya eksperimen yang dirancang untuk mengurangi konsekuensi kegagalan dalam sistem TI.
"Jika Anda gagal mempersiapkan rencana, maka Anda berencana untuk gagal." - Benjamin Franklin
Pada bagian
pertama dari seri artikel ini, saya memperkenalkan konsep chaos engineering dan menjelaskan bagaimana hal itu membantu untuk menemukan dan memperbaiki kekurangan dalam sistem sebelum menyebabkan crash produksi. Itu juga berbicara tentang bagaimana chaos engineering berkontribusi terhadap perubahan budaya positif dalam organisasi.
Pada akhir bagian pertama, saya berjanji untuk berbicara tentang "alat dan metode untuk memasukkan kegagalan ke dalam sistem." Sayangnya, kepala saya punya rencana sendiri dalam hal ini, dan dalam artikel ini saya akan mencoba menjawab pertanyaan paling populer yang muncul dari orang-orang yang ingin melakukan chaos engineering:
Apa yang harus dipecahkan lebih dulu? Pertanyaan bagus! Namun, dia sepertinya tidak peduli dengan panda ini ...
 Jangan main-main dengan kekacauan panda!Jawaban singkat
Jangan main-main dengan kekacauan panda!Jawaban singkat : Bertujuan untuk layanan kritis di jalur permintaan.
Jawaban yang panjang namun lebih jelas : Untuk memahami di mana memulai eksperimen dengan kekacauan, perhatikan tiga area:
- Lihatlah sejarah kegagalan dan identifikasi pola;
- Tentukan ketergantungan kritis ;
- Gunakan yang disebut. efek terlalu percaya diri .
Itu lucu, tetapi bagian dengan kesuksesan yang sama ini bisa disebut
"Perjalanan menuju pengetahuan diri dan pencerahan .
" Di dalamnya, kita akan mulai "bermain" dengan beberapa alat keren.
1. Jawabannya ada di masa lalu
Jika Anda ingat, pada bagian pertama saya memperkenalkan konsep Koreksi-Kesalahan (COE) - metode yang digunakan untuk menganalisis kesalahan kami: meleset dalam teknologi, proses, atau organisasi - untuk memahami tujuan mereka dan mencegah pengulangan di masa mendatang. . Secara umum, ini harus dimulai.
"Untuk memahami masa kini, kau harus tahu masa lalu." - Karl Sagan
Lihatlah sejarah kegagalan, letakkan tag di SOE atau postmortem'ah dan klasifikasikan. Identifikasi pola umum yang sering menimbulkan masalah, dan untuk setiap BUMN, tanyakan pada diri sendiri pertanyaan berikut:
"Mungkinkah ini telah diramalkan, dan karena itu dicegah dengan diperkenalkannya kerusakan?"Saya ingat satu kegagalan di awal karir saya. Itu bisa dengan mudah dicegah jika kami memiliki beberapa percobaan kekacauan sederhana:
Dalam kondisi normal, instance backend merespons pemeriksaan kesehatan dari load balancer (ELB ). ELB menggunakan cek ini untuk mengarahkan permintaan ke instance yang sehat. Ketika ternyata contoh tertentu “tidak sehat,” ELB berhenti mengirim permintaan kepadanya. Suatu kali, setelah kampanye pemasaran yang sukses, volume lalu lintas tumbuh, dan backend mulai merespons pemeriksaan kesehatan lebih lambat dari biasanya. Harus dikatakan bahwa pemeriksaan kesehatan ini dalam , yaitu, keadaan ketergantungan diperiksa.
Namun, untuk sementara semuanya beres.
Kemudian, sudah dalam kondisi yang agak menegangkan, salah satu contoh mulai melakukan tugas cron reguler yang tidak kritis dari kategori ETL. Kombinasi traffic tinggi dan cronjob mendorong pemanfaatan CPU hampir 100%. Kelebihan prosesor memperlambat respons terhadap pemeriksaan kesehatan bahkan lebih - sehingga ELB memutuskan bahwa instance tersebut mengalami masalah. Seperti yang diharapkan, penyeimbang berhenti mendistribusikan lalu lintas ke sana, yang, pada gilirannya, menyebabkan peningkatan beban pada instance yang tersisa dalam grup.
Tiba-tiba, semua contoh lainnya juga mulai gagal dalam pemeriksaan kesehatan.
Meluncurkan instance baru diperlukan pengunduhan dan penginstalan paket dan butuh waktu lebih lama dari yang dibutuhkan ELB untuk memutusnya - satu per satu - dalam grup skala otomatis. Jelas bahwa segera seluruh proses mencapai titik kritis dan aplikasi jatuh.
Kemudian kita selamanya memahami hal-hal berikut:
- Untuk menginstal perangkat lunak saat membuat instance baru untuk waktu yang lama, lebih baik memberikan preferensi pada pendekatan abadi dan Golden AMI .
- Dalam situasi sulit, respons terhadap pemeriksaan kesehatan dan ELB harus diutamakan - hal terakhir yang ingin Anda lakukan adalah membuat hidup lebih sulit untuk contoh yang tersisa.
- Caching lokal pemeriksaan kesehatan (bahkan untuk beberapa detik) banyak membantu.
- Dalam situasi yang sulit, jangan jalankan tugas cron dan proses tidak kritis lainnya - hemat sumber daya untuk tugas yang paling penting.
- Saat melakukan autoscaling, gunakan instance yang lebih kecil. Sekelompok 10 salinan kecil lebih baik dari 4 salinan besar; jika satu contoh jatuh, dalam kasus pertama 10% dari lalu lintas akan didistribusikan di 9 titik, di kedua - 25% dari lalu lintas di tiga titik.
Jadi,
dapatkah ini diramalkan, dan karena itu dicegah dengan memperkenalkan masalahnya?Ya , dan dalam beberapa cara.
Pertama, dengan mensimulasikan penggunaan CPU yang tinggi dengan alat-alat seperti
stress-ng atau
cpuburn :
❯ stress-ng --matrix 1 -t 60s
 stres-ng
stres-ngKedua, overloading instance menggunakan
wrk dan utilitas serupa lainnya:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health
Eksperimennya relatif sederhana, tetapi mereka dapat memberikan makanan yang baik untuk dipikirkan tanpa harus mengalami tekanan kegagalan yang nyata.
Namun,
jangan berhenti di situ . Cobalah untuk mereproduksi kegagalan dalam lingkungan pengujian dan periksa jawaban Anda untuk pertanyaan "
Bisakah ini diramalkan, dan karenanya dicegah dengan memperkenalkan kerusakan?" ". Ini adalah eksperimen kekacauan kecil di dalam eksperimen kekacauan untuk menguji asumsi, tetapi dimulai dengan kegagalan.
 Apakah itu mimpi, atau apakah itu benar-benar terjadi?
Apakah itu mimpi, atau apakah itu benar-benar terjadi?Jadi, pelajari sejarah kegagalan, analisis
COE , tag, dan klasifikasikan berdasarkan "radius kerusakan" - atau, lebih tepatnya, menurut jumlah pelanggan yang terpengaruh - dan kemudian cari pola. Tanyakan kepada diri Anda sendiri apakah ini bisa diramalkan dan dicegah dengan memperkenalkan masalahnya. Periksa jawaban Anda.
Kemudian beralih ke pola paling umum dengan rentang terbesar.
2. Membangun peta ketergantungan
Luangkan waktu sejenak untuk memikirkan aplikasi Anda. Apakah ada peta ketergantungan yang jelas? Apakah Anda tahu apa dampaknya jika terjadi kegagalan?
Jika Anda tidak terlalu terbiasa dengan kode aplikasi Anda atau sudah menjadi terlalu besar, mungkin sulit untuk memahami apa yang dilakukan oleh kode dan apa ketergantungannya. Memahami dependensi ini dan kemungkinan dampaknya pada aplikasi dan pengguna sangat penting untuk memahami di mana memulai rekayasa kekacauan: komponen dengan radius kehancuran terbesar akan menjadi titik awal.
Mengidentifikasi dan mendokumentasikan dependensi disebut "
pemetaan ketergantungan ." Biasanya itu dilakukan untuk aplikasi dengan basis kode yang luas menggunakan alat untuk profiling kode
(code profiling) dan instrumentasi
(instrumentasi) . Anda juga dapat membangun peta dengan memonitor lalu lintas jaringan.
Namun, tidak semua dependensi adalah sama (yang semakin memperumit proses). Beberapa
kritis , yang lain
sekunder (setidaknya secara teoritis, karena crash sering diakibatkan masalah ketergantungan yang dianggap tidak kritis) .
Tanpa ketergantungan kritis, layanan tidak dapat berfungsi. Ketergantungan non-kritis "
seharusnya tidak " berpengaruh pada layanan jika terjadi jatuh. Untuk menangani dependensi, Anda harus memiliki pemahaman yang jelas tentang API yang digunakan oleh aplikasi. Ini bisa menjadi jauh lebih rumit daripada kedengarannya - setidaknya untuk aplikasi besar.
Mulailah dengan menyortir semua API. Sorot yang paling
signifikan dan kritis . Ambil
dependensi dari repositori kode, periksa
log koneksi , lalu lihat
dokumentasi (tentu saja, jika ada, jika tidak, Anda akan memiliki lebih banyak masalah). Gunakan alat untuk
membuat profil dan melacak , menyaring panggilan eksternal.
Anda dapat menggunakan program seperti
netstat , utilitas baris perintah yang menampilkan daftar semua koneksi jaringan (soket aktif) pada sistem. Misalnya, untuk menampilkan semua koneksi saat ini, ketik:
❯ netstat -a | more

Di AWS, Anda dapat menggunakan flow log VPC - metode yang memungkinkan Anda mengumpulkan informasi tentang lalu lintas IP yang menuju atau dari antarmuka jaringan pada VPC. Log semacam itu dapat membantu tugas-tugas lain, misalnya, menemukan jawaban untuk pertanyaan mengapa lalu lintas tertentu tidak mencapai instance.
Anda juga dapat menggunakan
AWS X-Ray . X-Ray memungkinkan Anda untuk mendapatkan gambaran umum permintaan "end"
(end-to-end) yang terperinci saat mereka berkembang melalui aplikasi, dan juga membuat peta komponen-komponen dasar aplikasi. Sangat nyaman jika Anda perlu mengidentifikasi dependensi.
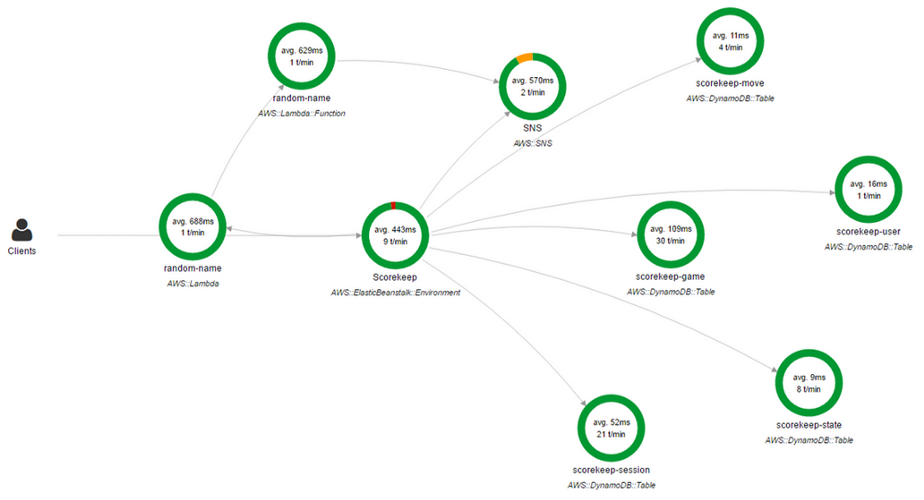 Konsol AWS X-Ray
Konsol AWS X-RayPeta ketergantungan jaringan hanya merupakan solusi parsial. Ya, ini menunjukkan aplikasi mana yang terkait dengan itu, tetapi ada dependensi lainnya.
Banyak aplikasi menggunakan DNS untuk terhubung ke dependensi, sementara yang lain dapat menggunakan mekanisme penemuan layanan atau bahkan alamat IP hard-coded dalam file konfigurasi (misalnya, di
/etc/hosts ).
Misalnya, Anda dapat membuat
DNS blackhole menggunakan
iptables dan melihat apa yang terjadi. Untuk melakukan ini, masukkan perintah berikut:
❯ iptables -I OUTPUT -p udp --dport 53 -j REJECT -m comment --comment "Reject DNS"
 DNS Lubang Hitam
DNS Lubang HitamJika Anda menemukan alamat IP di
/etc/hosts atau file konfigurasi lain yang tidak Anda ketahui (ya, sayangnya, itu terjadi),
iptables dapat datang untuk menyelamatkan lagi. Katakan Anda menemukan
8.8.8.8 dan tidak tahu bahwa ini adalah alamat server DNS publik Google. Menggunakan
iptables Anda dapat menutup lalu lintas masuk dan keluar ke alamat ini menggunakan perintah berikut:
❯ iptables -A INPUT -s 8.8.8.8 -j DROP -m comment --comment "Reject from 8.8.8.8" ❯ iptables -A OUTPUT -d 8.8.8.8 -j DROP -m comment --comment "Reject to 8.8.8.8"
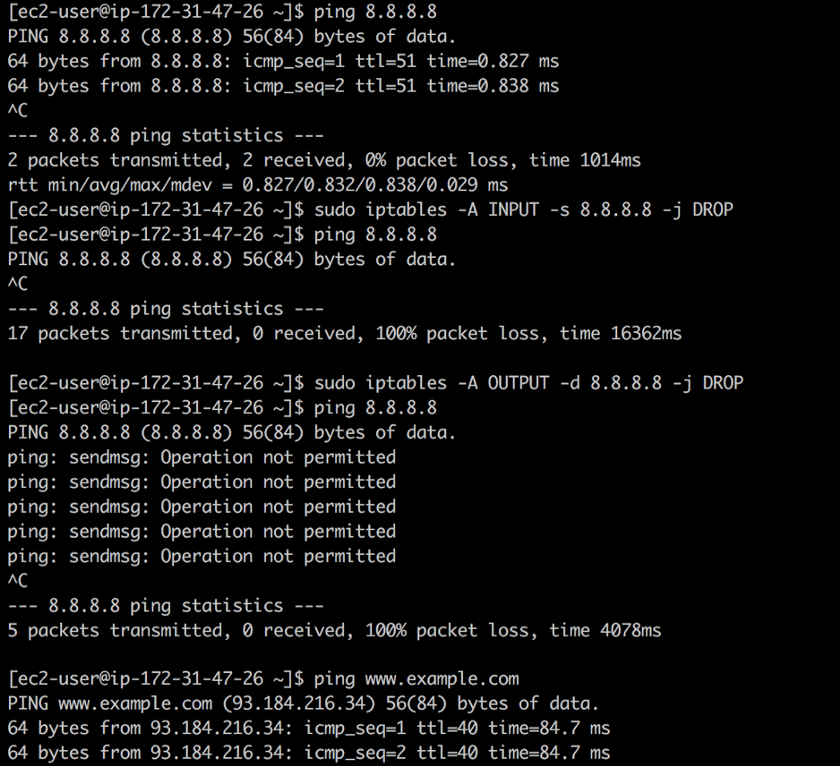 Tutup akses
Tutup aksesAturan pertama menghapus semua paket dari DNS publik Google:
ping berfungsi, tetapi paket tidak dikembalikan. Aturan kedua membuang semua paket yang berasal dari sistem Anda ke arah DNS publik Google - sebagai tanggapan atas
ping kami dapatkan
Operasi tidak diizinkan .
Catatan: dalam kasus khusus ini, akan lebih baik menggunakan whois 8.8.8.8 , tetapi ini hanya sebuah contoh.Anda bisa masuk lebih dalam ke dalam lubang kelinci, karena semua yang menggunakan TCP dan UDP sebenarnya tergantung pada IP. Dalam kebanyakan kasus, IP terikat dengan ARP. Jangan lupakan firewall ...
 Jika Anda memilih pil merah, Anda akan tetap di Wonderland dan saya akan menunjukkan seberapa dalam lubang kelinci ”
Jika Anda memilih pil merah, Anda akan tetap di Wonderland dan saya akan menunjukkan seberapa dalam lubang kelinci ”Pendekatan yang lebih radikal adalah
mematikan mobil satu per satu dan melihat apa yang rusak ... menjadi "monyet kekacauan." Tentu saja, banyak sistem produksi tidak dirancang untuk serangan kasar seperti itu, tetapi setidaknya dapat dicoba di lingkungan pengujian.
Membangun peta ketergantungan seringkali merupakan latihan yang sangat panjang. Baru-baru ini saya berbicara dengan klien yang saya habiskan hampir 2 tahun untuk mengembangkan alat yang, dalam mode semi-otomatis, menghasilkan peta ketergantungan untuk ratusan layanan dan tim mikron.
Namun hasilnya sangat menarik dan bermanfaat. Anda akan belajar banyak tentang sistem Anda, dependensi dan operasinya. Sekali lagi, bersabarlah: perjalanan itu sendiri adalah yang paling penting.
3. Waspadalah terhadap kesombongan
"Siapa pun yang memimpikan apa, percayalah pada itu." - Demosthenes
Pernahkah Anda mendengar tentang
efek terlalu percaya diri ?
Menurut Wikipedia, efek dari terlalu percaya diri adalah "distorsi kognitif di mana kepercayaan seseorang dalam tindakan dan keputusannya jauh lebih tinggi daripada akurasi objektif penilaian ini, terutama ketika tingkat kepercayaan relatif tinggi."
 Berdasarkan insting dan pengalaman ...
Berdasarkan insting dan pengalaman ...Dari pengalaman saya sendiri, saya dapat mengatakan bahwa distorsi ini merupakan petunjuk yang bagus di mana untuk memulai chaos engineering.
Waspadalah terhadap operator yang percaya diri:
Charlie: "Benda ini belum jatuh selama sekitar lima tahun, semuanya baik-baik saja!"
Kegagalan: "Tunggu ... saya akan segera!"
Bias sebagai konsekuensi dari kepercayaan diri adalah hal yang berbahaya dan bahkan berbahaya karena berbagai faktor yang mempengaruhinya. Ini terutama benar ketika anggota tim menempatkan jiwa mereka ke dalam teknologi tertentu atau menghabiskan banyak waktu pada "perbaikan".
Untuk meringkas
Pencarian titik awal untuk rekayasa kekacauan selalu menghasilkan lebih banyak hasil dari yang diharapkan, dan tim yang mulai menghancurkan segalanya terlalu cepat melupakan esensi
rekayasa (kekacauan) yang lebih global dan menarik - aplikasi kreatif
metode ilmiah dan
bukti empiris untuk desain, pengembangan , operasi, pemeliharaan dan peningkatan sistem (perangkat lunak).
Pada bagian ini, bagian kedua berakhir. Silakan tulis ulasan, bagikan pendapat, atau tepuk tangan Anda di
Medium .
Pada bagian selanjutnya, saya akan benar - benar melihat alat dan teknik untuk memperkenalkan kegagalan sistem. Sampai - sampai jumpa! DIPERBARUI (19 Desember):
Terjemahan bagian ketiga telah tersedia.
PS dari penerjemah
Baca juga di blog kami: