
Pada artikel ini, saya ingin mengusulkan alternatif untuk gaya desain tes tradisional menggunakan konsep pemrograman fungsional di Scala. Pendekatan ini diilhami oleh rasa sakit selama berbulan-bulan karena mempertahankan puluhan tes yang gagal dan keinginan yang membara untuk menjadikannya lebih mudah dan lebih mudah dipahami.
Meskipun kodenya ada di Scala, ide-ide yang diusulkan cocok untuk pengembang dan insinyur QA yang menggunakan bahasa yang mendukung pemrograman fungsional. Anda dapat menemukan tautan Github dengan solusi lengkap dan contoh di akhir artikel.
Masalah
Jika Anda pernah harus berurusan dengan tes (tidak masalah yang mana: tes unit, integrational atau fungsional), mereka kemungkinan besar ditulis sebagai serangkaian instruksi berurutan. Misalnya:
Dalam pengalaman saya, cara penulisan tes ini lebih disukai oleh kebanyakan pengembang. Proyek kami memiliki sekitar seribu tes pada berbagai tingkat isolasi, dan semuanya ditulis dengan gaya seperti itu hingga baru-baru ini. Ketika proyek tumbuh, kami mulai melihat masalah parah dan perlambatan dalam mempertahankan tes tersebut: memperbaikinya akan memakan waktu setidaknya sama dengan waktu menulis kode produksi.
Saat menulis tes baru, kami selalu harus menemukan cara untuk menyiapkan data dari awal, biasanya dengan menyalin dan menempelkan langkah-langkah dari tes tetangga. Akibatnya, ketika model data aplikasi akan berubah, rumah kartu akan runtuh, dan kami harus memperbaiki setiap tes gagal: dalam skenario terburuk - dengan menyelam jauh ke dalam setiap tes dan menulis ulang.
Ketika sebuah tes akan gagal "jujur" - yaitu karena bug aktual dalam logika bisnis - memahami apa yang salah tanpa debugging tidak mungkin. Karena tes itu sangat sulit untuk dipahami, tidak ada yang memiliki pengetahuan penuh selalu tentang bagaimana sistem seharusnya berperilaku.
Semua rasa sakit ini, menurut pendapat saya, adalah gejala dari dua masalah yang lebih dalam dari desain tes tersebut:
- Tidak ada struktur yang jelas dan praktis untuk tes. Setiap tes adalah kepingan salju yang unik. Kurangnya struktur menyebabkan verbositas, yang memakan banyak waktu dan kehilangan motivasi. Detail tidak penting mengalihkan perhatian dari apa yang paling penting - persyaratan yang ditegaskan oleh tes ini. Menyalin dan menempel menjadi pendekatan utama untuk menulis kasus uji baru.
- Tes tidak membantu pengembang dalam melokalisasi cacat; mereka hanya memberi sinyal bahwa ada semacam masalah. Untuk memahami keadaan di mana tes dijalankan, Anda harus merencanakannya di kepala Anda atau menggunakan debugger.
Pemodelan
Bisakah kita berbuat lebih baik? (Peringatan spoiler: kami bisa.) Mari kita pertimbangkan seperti apa struktur tes ini.
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Sebagai aturan praktis, kode yang sedang diuji mengharapkan beberapa parameter eksplisit (pengidentifikasi, ukuran, jumlah, filter, untuk beberapa nama), serta beberapa data eksternal (dari database, antrian atau layanan dunia nyata lainnya). Agar pengujian kami dapat berjalan dengan andal, diperlukan fixture - keadaan untuk menempatkan sistem, penyedia data, atau keduanya.
Dengan fixture ini, kami menyiapkan dependensi untuk menginisialisasi kode yang sedang diuji - isi database, buat antrian dari tipe tertentu, dll.
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
Setelah menjalankan kode yang sedang diuji pada beberapa parameter input, kami menerima output - baik eksplisit (dikembalikan oleh kode yang diuji) dan implisit (perubahan di negara bagian).
result shouldBe 90
Akhirnya, kami memeriksa bahwa hasilnya seperti yang diharapkan, menyelesaikan tes dengan satu atau lebih pernyataan .
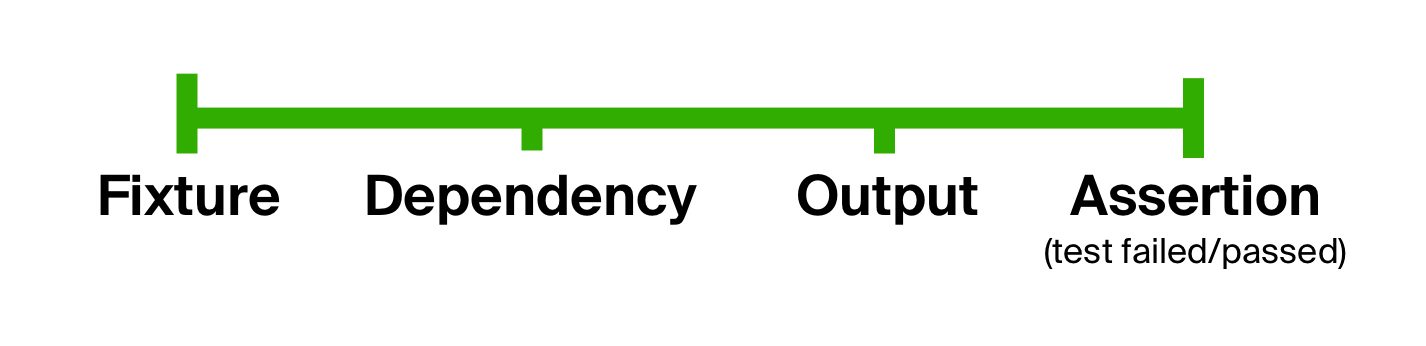
Seseorang dapat menyimpulkan bahwa tes umumnya terdiri dari tahapan yang sama: persiapan input, eksekusi kode, dan pernyataan hasil. Kita dapat menggunakan fakta ini untuk menyingkirkan masalah pertama dari tes kami , mis. Bentuk yang terlalu liberal, dengan secara eksplisit membagi tubuh tes menjadi beberapa tahap. Gagasan semacam itu bukanlah hal baru, karena dapat dilihat dalam tes gaya BDD ( pengembangan yang didorong oleh perilaku ).
Bagaimana dengan perpanjangan? Setiap langkah dari proses pengujian dapat, pada gilirannya, mengandung jumlah jumlah sedang. Sebagai contoh, kita dapat mengambil langkah besar dan rumit, seperti membangun fixture, dan membaginya menjadi beberapa, dirantai satu demi satu. Dengan cara ini, proses pengujian dapat diperpanjang tanpa batas, tetapi pada akhirnya selalu terdiri dari beberapa langkah umum yang sama.

Menjalankan tes
Mari kita coba menerapkan gagasan membagi tes menjadi beberapa tahap, tetapi pertama-tama, kita harus menentukan hasil seperti apa yang ingin kita lihat.
Secara keseluruhan, kami ingin menulis dan mempertahankan tes menjadi kurang padat karya dan lebih menyenangkan. Semakin sedikit instruksi unik dan unik yang dimiliki tes, semakin sedikit perubahan yang harus dilakukan setelah mengubah kontrak atau refactoring, dan semakin sedikit waktu yang dibutuhkan untuk membaca tes. Desain tes harus mempromosikan penggunaan ulang potongan kode umum dan mencegah penyalinan dan menempelkan yang tidak berpikir. Akan lebih baik jika tes akan memiliki bentuk yang seragam. Prediktabilitas meningkatkan keterbacaan dan menghemat waktu. Sebagai contoh, bayangkan berapa banyak waktu yang dibutuhkan para ilmuwan yang bercita-cita untuk mempelajari semua formula jika buku teks akan membuatnya ditulis secara bebas dalam bahasa umum sebagai lawan dari matematika.
Dengan demikian, tujuan kami adalah menyembunyikan apa pun yang mengganggu dan tidak perlu, hanya menyisakan apa yang sangat penting untuk dipahami: apa yang sedang diuji, apa input dan output yang diharapkan.
Mari kita kembali ke model struktur pengujian kita.
Secara teknis, setiap langkah dapat diwakili oleh tipe data, dan setiap transisi - oleh suatu fungsi. Untuk mendapatkan dari tipe data awal ke yang terakhir dimungkinkan dengan menerapkan masing-masing fungsi ke hasil yang sebelumnya. Dengan kata lain, dengan menggunakan komposisi fungsi persiapan data (sebut saja prepare ), eksekusi kode ( execute ) dan pengecekan hasil yang diharapkan ( check ). Input untuk komposisi ini akan menjadi langkah pertama - fixture. Mari kita sebut fungsi orde tinggi yang dihasilkan sebagai fungsi siklus uji .
Uji fungsi siklus hidup def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] =
Muncul pertanyaan, dari mana fungsi-fungsi tertentu ini berasal? Nah, untuk persiapan data, hanya ada sejumlah cara untuk melakukannya - mengisi basis data, mengejek, dll. Dengan demikian, sangat berguna untuk menulis varian khusus fungsi prepare dibagikan di semua tes. Akibatnya, akan lebih mudah untuk membuat fungsi siklus hidup tes khusus untuk setiap kasus, yang akan menyembunyikan implementasi konkret persiapan data. Karena eksekusi kode dan pernyataan lebih atau kurang unik untuk setiap tes (atau kelompok tes), execute dan check harus ditulis setiap waktu secara eksplisit.
Fungsi siklus hidup tes diadaptasi untuk pengujian integrasi pada DB Dengan mendelegasikan semua nuansa administratif ke fungsi siklus hidup pengujian, kami mendapatkan kemampuan untuk memperpanjang proses pengujian tanpa menyentuh tes yang diberikan. Dengan memanfaatkan komposisi fungsi, kita dapat mengganggu setiap langkah proses dan mengekstraksi atau menambahkan data.
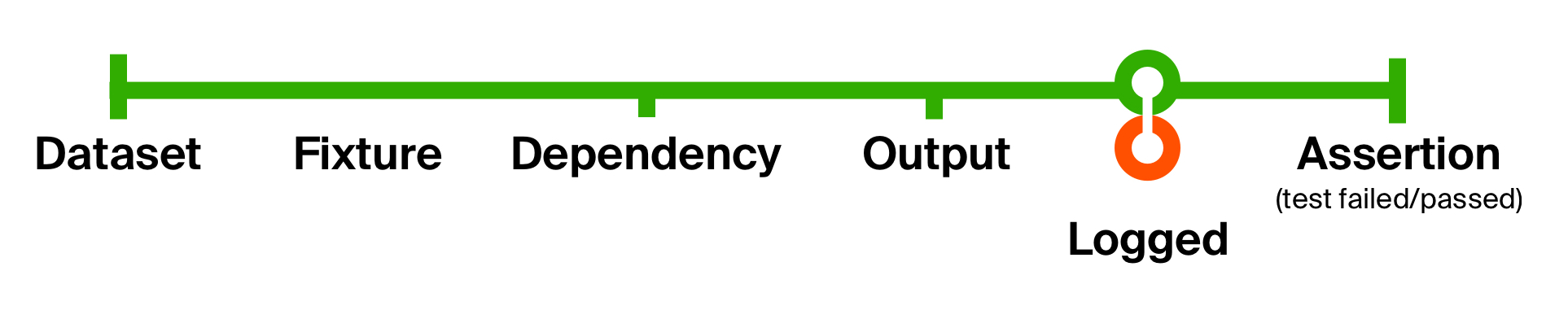
Untuk lebih menggambarkan kemampuan dari pendekatan semacam itu, mari kita selesaikan masalah kedua dari tes awal kami - kurangnya informasi tambahan untuk menunjukkan masalah dengan tepat. Mari kita tambahkan logging dari eksekusi kode apa pun yang telah dikembalikan. Pencatatan kami tidak akan mengubah tipe data; itu hanya menghasilkan efek samping - mengeluarkan pesan ke konsol. Setelah efek samping, kami mengembalikannya apa adanya.
Uji fungsi siklus hidup dengan pencatatan def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => {
Dengan perubahan sederhana ini, kami telah menambahkan pencatatan output kode yang dieksekusi di setiap pengujian . Keuntungan dari fungsi sekecil itu adalah mudah dipahami, disusun, dan dihilangkan saat dibutuhkan.

Hasilnya, pengujian kami sekarang terlihat seperti ini:
val fixture: SomeMagicalFixture = ???
Tubuh tes menjadi singkat, fixture dan cek dapat digunakan kembali dalam tes lain, dan kami tidak menyiapkan database secara manual di mana pun lagi. Hanya satu masalah kecil yang tersisa ...
Persiapan perlengkapan
Dalam kode di atas kami bekerja dengan asumsi bahwa fixture akan diberikan kepada kami dari suatu tempat. Karena data merupakan unsur penting dari pengujian yang dapat dipertahankan dan langsung, kami harus menyentuh cara membuatnya dengan mudah.
Misalkan toko kami sedang diuji memiliki basis data relasional berukuran sedang (untuk kesederhanaan, dalam contoh ini hanya memiliki 4 tabel, tetapi dalam kenyataannya, dapat memiliki ratusan). Beberapa tabel memiliki data referensial, beberapa - data bisnis, dan semua itu dapat secara logis dikelompokkan menjadi satu atau lebih entitas yang kompleks. Hubungan terkait dengan kunci asing , untuk membuat Bonus , Package diperlukan, yang pada gilirannya membutuhkan User , dan sebagainya.

Penanganan masalah dan peretasan hanya menyebabkan inkonsistensi data dan, sebagai akibatnya, berjam-jam berjam-jam melakukan debugging. Karena alasan ini, kami tidak akan mengubah skema dengan cara apa pun.
Kita dapat menggunakan beberapa metode produksi untuk mengisinya, tetapi bahkan di bawah pengawasan yang dangkal, ini menimbulkan banyak pertanyaan sulit. Apa yang akan menyiapkan data dalam pengujian untuk kode produksi itu? Apakah kita harus menulis ulang tes jika kontrak kode itu berubah? Bagaimana jika data sepenuhnya berasal dari tempat lain, dan tidak ada metode untuk digunakan? Berapa banyak permintaan yang diperlukan untuk membuat entitas yang bergantung pada banyak lainnya?
Database mengisi tes awal insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Metode pembantu yang tersebar, seperti yang ada dalam contoh pertama kita, adalah masalah yang sama dengan kedok yang berbeda. Mereka menempatkan tanggung jawab mengelola ketergantungan pada diri kita sendiri yang kita coba hindari.
Idealnya, kami ingin beberapa struktur data yang akan menyajikan keadaan seluruh sistem hanya dalam sekejap. Kandidat yang tepat adalah tabel (atau dataset , seperti dalam PHP atau Python) yang tidak memiliki apa-apa selain bidang yang penting untuk logika bisnis. Jika itu berubah, mempertahankan tes akan mudah: kami hanya mengubah bidang dalam dataset. Contoh:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
Dari tabel kami, kami membuat kunci - tautan entitas dengan ID. Jika suatu entitas bergantung pada entitas lain, kunci untuk entitas lain itu juga akan dibuat. Mungkin saja terjadi bahwa dua entitas yang berbeda membuat ketergantungan dengan ID yang sama, yang dapat menyebabkan pelanggaran kunci utama . Namun, pada tahap ini sangat murah untuk mendeduplikasi kunci - karena semua yang dikandungnya adalah ID, kita dapat menempatkannya dalam koleksi yang melakukan deduplikasi bagi kita, misalnya, Set . Jika ternyata tidak cukup, kami selalu dapat menerapkan deduplikasi yang lebih cerdas sebagai fungsi terpisah dan menyusunnya menjadi fungsi siklus hidup pengujian.
Kunci (contoh) sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
Membuat data palsu untuk bidang (mis., Nama) didelegasikan ke kelas yang terpisah. Setelah itu, dengan menggunakan kelas itu dan aturan konversi untuk kunci, kita mendapatkan objek Row yang dimaksudkan untuk dimasukkan ke dalam database.
Baris (contoh) object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
Data palsu biasanya tidak cukup, jadi kita perlu cara untuk menimpa bidang tertentu. Untungnya, lensa hanyalah yang kita butuhkan - kita dapat menggunakannya untuk beralih ke semua baris yang dibuat dan hanya mengubah bidang yang kita butuhkan. Karena lensa adalah fungsi yang menyamar, kita dapat menyusunnya seperti biasa, yang merupakan titik terkuat mereka.
Lense (contoh) def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
Berkat komposisi, kami dapat menerapkan berbagai optimasi dan peningkatan di dalam proses: misalnya, kami dapat mengelompokkan baris berdasarkan tabel untuk menyisipkannya dengan satu INSERT untuk mengurangi waktu pelaksanaan pengujian atau mencatat seluruh keadaan database.
Fungsi persiapan perlengkapan def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
Akhirnya, semuanya memberi kita perlengkapan. Dalam tes itu sendiri, tidak ada tambahan yang ditampilkan, kecuali untuk dataset awal - semua detail disembunyikan oleh komposisi fungsi.

Test suite kami sekarang terlihat seperti ini:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) "If the buyer's role is" - { "a customer" - { "And the total price of items" - { "< 250 after applying bonuses - no discount" - { "(case: no bonuses)" in calculatePriceFor(dataTable, 1) "(case: has bonuses)" in calculatePriceFor(dataTable, 3) } ">= 250 after applying bonuses" - { "If there are no bonuses - 10% off on the subtotal" in calculatePriceFor(dataTable, 2) "If there are bonuses - 10% off on the subtotal after applying bonuses" in calculatePriceFor(dataTable, 4) } } } "a vip - then they get a 20% off before applying bonuses and then all the other rules apply" in calculatePriceFor(dataTable, 5) }
Dan kode pembantu:
Menambahkan kasus uji baru ke dalam tabel adalah tugas sepele yang memungkinkan kita berkonsentrasi pada mencakup lebih banyak kasus pinggiran dan tidak menulis kode boilerplate.
Menggunakan kembali persiapan perlengkapan pada berbagai proyek
Oke, jadi kami menulis banyak kode untuk menyiapkan perlengkapan dalam satu proyek tertentu, menghabiskan cukup banyak waktu dalam proses. Bagaimana jika kita memiliki beberapa proyek? Apakah kita ditakdirkan untuk menemukan kembali semuanya dari awal setiap saat?
Kita dapat mengabstraksi persiapan fixture melalui model domain yang konkret. Di dunia pemrograman fungsional, ada konsep typeclasses . Tanpa merinci lebih jauh, mereka tidak seperti kelas di OOP, tetapi lebih seperti antarmuka karena mereka mendefinisikan perilaku tertentu dari beberapa kelompok tipe. Perbedaan mendasar adalah bahwa mereka tidak diwariskan tetapi variabel instantiated seperti. Namun, mirip dengan warisan, penyelesaian instance typeclass terjadi pada waktu kompilasi . Dalam pengertian ini, typeclasses dapat dipahami seperti metode ekstensi dari Kotlin dan C # .
Untuk mencatat suatu objek, kita tidak perlu tahu apa yang ada di dalamnya, bidang apa dan metode yang dimilikinya. Yang kami pedulikan hanyalah memiliki log() perilaku log() dengan tanda tangan tertentu. Memperluas setiap kelas tunggal dengan antarmuka Logged akan sangat membosankan dan bahkan tidak mungkin dalam banyak kasus - misalnya, untuk perpustakaan atau kelas standar. Dengan typeclasses, ini jauh lebih mudah. Kita dapat membuat instance dari typeclass yang disebut Logged , misalnya, untuk fixture untuk mencatatnya dalam format yang dapat dibaca manusia. Untuk segala sesuatu yang tidak memiliki instance dari Logged kami dapat memberikan fallback: sebuah instance untuk tipe Any yang menggunakan metode standar toString() untuk mencatat setiap objek dalam representasi internal mereka secara gratis.
Contoh dari typeclass Logged dan instansnya trait Logged[A] { def log(a: A)(implicit logger: Logger): A }
Selain logging, kita bisa menggunakan pendekatan ini di seluruh proses pembuatan fixture. Solusi kami mengusulkan cara abstrak untuk membuat perlengkapan basis data dan satu set typeclasses untuk pergi dengannya. Ini adalah proyek yang menggunakan tanggung jawab solusi untuk mengimplementasikan contoh-contoh kacamata ini agar semuanya berfungsi.
Saat merancang alat persiapan fixture ini, saya menggunakan prinsip - prinsip SOLID sebagai kompas untuk memastikan itu dapat dipertahankan dan dapat diperpanjang:
- Prinsip Tanggung Jawab Tunggal : setiap typeclass menggambarkan satu dan hanya satu perilaku jenis.
- Prinsip Terbuka / Tertutup : kami tidak memodifikasi kelas produksi mana pun; sebagai gantinya, kami memperluas mereka dengan contoh dari typeclasses.
- Prinsip Pergantian Liskov tidak berlaku di sini karena kami tidak menggunakan warisan.
- Prinsip Segregasi Antarmuka : kami menggunakan banyak jenis kacamata khusus yang bertentangan dengan kacamata jenis global.
- Prinsip Ketergantungan Inversi : fungsi persiapan fixture tidak tergantung pada jenis beton, tetapi lebih pada jenis kacamata abstrak.
Setelah memastikan bahwa semua prinsip terpenuhi, kami dapat dengan aman mengasumsikan bahwa solusi kami dapat dipertahankan dan cukup diperpanjang untuk digunakan dalam berbagai proyek.
Setelah menulis fungsi siklus hidup tes dan solusi untuk persiapan fixture, yang juga terlepas dari model domain konkret pada aplikasi yang diberikan, kami siap untuk memperbaiki semua tes yang tersisa.
Intinya
Kami telah beralih dari gaya desain uji tradisional (langkah-demi-langkah) ke fungsional. Gaya selangkah demi selangkah berguna sejak awal dan dalam proyek berukuran lebih kecil, karena tidak membatasi pengembang dan tidak memerlukan pengetahuan khusus. Namun, ketika jumlah tes menjadi terlalu besar, gaya seperti itu cenderung rontok. Menulis tes dengan gaya fungsional mungkin tidak akan menyelesaikan semua masalah pengujian Anda, tetapi mungkin secara signifikan meningkatkan penskalaan dan mempertahankan tes dalam proyek, di mana ada ratusan atau ribuan dari mereka. Tes yang ditulis dengan gaya fungsional ternyata lebih ringkas dan terfokus pada hal-hal penting (seperti data, kode yang diuji, dan hasil yang diharapkan), bukan pada langkah-langkah perantara.
Selain itu, kami telah mengeksplorasi seberapa kuat komposisi fungsi dan jenis kacamata dalam pemrograman fungsional. Dengan bantuan mereka, cukup mudah untuk merancang solusi dengan mempertimbangkan kemampuan untuk diperluas dan digunakan kembali.
Sejak mengadopsi gaya beberapa bulan lalu, tim kami harus meluangkan upaya untuk beradaptasi, tetapi pada akhirnya, kami menikmati hasilnya. Tes baru ditulis lebih cepat, log membuat hidup lebih nyaman, dan set data berguna untuk memeriksa setiap kali ada pertanyaan tentang seluk-beluk logika tertentu. Tim kami bertujuan untuk mengalihkan semua tes ke gaya baru ini secara bertahap.
Tautan ke solusi dan contoh lengkap dapat ditemukan di sini: Github . Bersenang-senang dengan pengujian Anda!