Halo semuanya. Dalam artikel ini saya akan memberi tahu Anda mengapa kami memilih Kafka sembilan bulan lalu di Avito, dan apa itu. Saya akan membagikan salah satu kasus penggunaan - broker pesan. Dan akhirnya, mari kita bicara tentang keuntungan apa yang kita dapatkan dari menerapkan Kafka sebagai pendekatan Layanan.
Masalah

Pertama, sedikit konteks. Beberapa waktu yang lalu, kami mulai menjauh dari arsitektur monolitik, dan sekarang di Avito sudah ada beberapa ratus layanan berbeda. Mereka memiliki repositori mereka sendiri, tumpukan teknologi mereka sendiri dan bertanggung jawab atas bagian mereka dari logika bisnis.
Salah satu masalah dengan sejumlah besar layanan adalah komunikasi. Layanan A sering ingin mengetahui informasi yang dimiliki layanan B. Dalam hal ini, layanan A mengakses layanan B melalui API yang sinkron. Layanan B ingin tahu apa yang terjadi dengan layanan G dan D, dan mereka, pada gilirannya, tertarik pada layanan A dan B. Ketika ada banyak layanan "penasaran" seperti itu, koneksi di antara mereka berubah menjadi bola kusut.
Selain itu, kapan saja, layanan A mungkin tidak tersedia. Dan apa yang harus dilakukan dalam hal ini, layanan B dan semua layanan lain yang terkait dengannya? Dan jika Anda perlu membuat rantai panggilan sinkron berurutan untuk menyelesaikan operasi bisnis, probabilitas kegagalan seluruh operasi menjadi lebih tinggi (dan semakin tinggi, semakin lama rantai ini).
Pemilihan teknologi

OK, masalahnya sudah jelas. Anda dapat menghilangkannya dengan membuat sistem pesan terpusat antar layanan. Sekarang, masing-masing layanan sudah cukup untuk mengetahui hanya tentang sistem pesan ini. Selain itu, sistem itu sendiri harus toleran terhadap kesalahan dan dapat diskalakan secara horizontal, serta dalam hal kecelakaan, mengakumulasi buffer panggilan untuk pemrosesan selanjutnya.
Sekarang mari kita memilih teknologi di mana pengiriman pesan akan dilaksanakan. Untuk melakukan ini, pahami dulu apa yang kami harapkan darinya:
- Pesan antar layanan tidak boleh hilang;
- Pesan dapat diduplikasi
- pesan dapat disimpan dan dibaca hingga beberapa hari (buffer persisten);
- layanan dapat berlangganan data yang menarik bagi mereka;
- beberapa layanan dapat membaca data yang sama;
- Pesan dapat berisi rincian, muatan curah (transfer yang dilakukan oleh negara);
- terkadang Anda membutuhkan jaminan pesanan pesan.
Penting juga bagi kami untuk memilih sistem yang paling skalabel dan andal dengan throughput tinggi (setidaknya 100rb pesan dengan beberapa kilobyte per detik).
Pada tahap ini, kami mengucapkan selamat tinggal pada RabbitMQ (sulit untuk tetap stabil di rps tinggi), PGT dari SkyTools (tidak cukup cepat dan kurang skalabel) dan NSQ (tidak persisten). Semua teknologi ini digunakan di perusahaan kami, tetapi mereka tidak sesuai dengan tugas yang ada.
Kemudian kami mulai mencari teknologi baru untuk kami - Apache Kafka, Apache Pulsar dan NATS Streaming.
Yang pertama menjatuhkan Pulsar. Kami memutuskan bahwa Kafka dan Pulsar adalah solusi yang cukup mirip. Dan terlepas dari kenyataan bahwa Pulsar diuji oleh perusahaan besar, itu lebih baru dan menawarkan latensi yang lebih rendah (secara teori), kami memutuskan untuk meninggalkan Kafka dari keduanya, sebagai standar de facto untuk tugas-tugas tersebut. Kami mungkin akan kembali ke Apache Pulsar di masa mendatang.
Dan ada dua kandidat yang tersisa: NATS Streaming dan Apache Kafka. Kami mempelajari kedua solusi secara terperinci, dan keduanya sampai pada tugas itu. Tetapi pada akhirnya, kami takut akan generasi relatif dari Streaming NATS (dan fakta bahwa salah satu pengembang utama, Tyler Treat, memutuskan untuk meninggalkan proyek dan memulai proyeknya sendiri - Liftbridge). Pada saat yang sama, mode Clustering Streaming NATS tidak memungkinkan untuk penskalaan horizontal yang kuat (ini mungkin tidak lagi menjadi masalah setelah menambahkan mode partisi pada 2017).
Namun, NATS Streaming adalah teknologi keren yang ditulis dalam Go dan didukung oleh Cloud Native Computing Foundation. Tidak seperti Apache Kafka, Zookeeper tidak perlu bekerja ( mungkin bisa mengatakan hal yang sama tentang Kafka segera ), karena di dalamnya mengimplementasikan RAFT. Pada saat yang sama, Streaming NATS lebih mudah untuk dikelola. Kami tidak mengecualikan bahwa di masa depan kami akan kembali ke teknologi ini.
Namun demikian, Apache Kafka telah menjadi pemenang kami hari ini. Dalam pengujian kami, terbukti cukup cepat (lebih dari satu juta pesan per detik untuk membaca dan menulis dengan volume pesan 1 kilobyte), cukup andal, dapat diukur dengan baik dan pengalaman yang terbukti dalam penjualan oleh perusahaan besar. Selain itu, Kafka mendukung setidaknya beberapa perusahaan komersial besar (misalnya, kami menggunakan versi Confluent), dan Kafka memiliki ekosistem yang dikembangkan.
Tinjau Kafka
Sebelum memulai, saya langsung merekomendasikan buku yang bagus - “Kafka: The Definitive Guide” (juga dalam terjemahan Rusia, tetapi istilah-istilahnya sedikit mematahkan otak). Di dalamnya Anda dapat menemukan informasi yang diperlukan untuk pemahaman dasar tentang Kafka dan bahkan sedikit lagi. Dokumentasi Apache sendiri dan blog Confluent juga ditulis dengan baik dan mudah dibaca.
Jadi, mari kita lihat bagaimana Kafka adalah pandangan mata burung. Topologi dasar Kafka terdiri dari produsen, konsumen, broker, dan penjaga kebun binatang.
Pialang

Pialang bertanggung jawab untuk menyimpan data Anda. Semua data disimpan dalam bentuk biner, dan broker tidak tahu banyak tentang apa mereka dan apa struktur mereka.
Setiap jenis peristiwa logis biasanya terletak di topik yang terpisah (topik). Misalnya, acara pembuatan iklan dapat jatuh ke dalam topik item.created, dan acara perubahannya dapat jatuh ke item.changed. Topik dapat dianggap sebagai pengklasifikasi acara. Di tingkat topik, Anda dapat mengatur parameter konfigurasi seperti:
- volume data yang disimpan dan / atau usianya (retention.bytes, retention.ms);
- faktor redundansi data (faktor replikasi);
- ukuran maksimum satu pesan (max.message.bytes);
- jumlah minimum dari replika konsisten di mana data dapat ditulis ke topik (min.insync.replicas);
- kemampuan untuk failover ke replika lagging non-sinkron dengan kehilangan data potensial (haram.leader.election.enable);
- dan banyak lagi ( https://kafka.apache.org/documentation/#topicconfigs ).
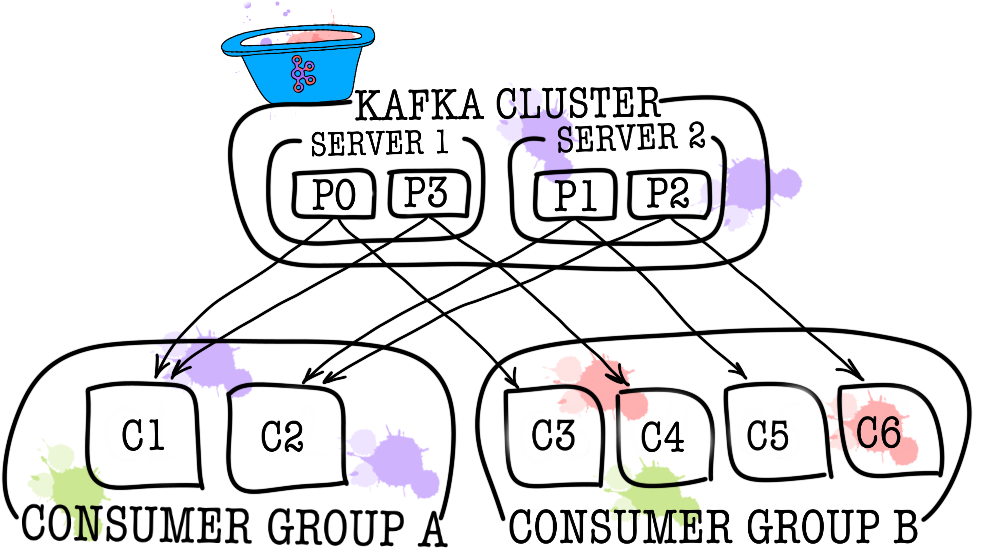
Pada gilirannya, setiap topik dibagi menjadi satu atau lebih partisi (partisi). Di partisi itulah peristiwa akhirnya jatuh. Jika ada lebih dari satu broker di cluster, maka partisi akan didistribusikan secara merata di antara semua broker (sejauh mungkin), yang akan memungkinkan Anda untuk skala beban penulisan dan membaca dalam satu topik ke beberapa broker sekaligus.
Pada disk, data untuk setiap partisi disimpan sebagai file segmen, secara default sama dengan satu gigabyte (dikontrol melalui log.segment.bytes). Fitur penting adalah bahwa data dihapus dari partisi (ketika retensi dipicu) hanya oleh segmen (Anda tidak dapat menghapus satu peristiwa dari partisi, Anda dapat menghapus hanya seluruh segmen, dan hanya tidak aktif).
Penjaga kebun binatang
Zookeeper bertindak sebagai repositori dan koordinator metadata. Dialah yang mampu mengatakan apakah broker hidup (Anda dapat melihatnya melalui mata penjaga kebun binatang melalui perintah zookeeper-shell ls /brokers/ids ), yang mana dari broker adalah pengontrol ( get /controller ), apakah partisi tersebut dalam keadaan sinkron dengan replika mereka ( get /brokers/topics/topic_name/partitions/partition_number/state ). Juga, produsen dan konsumen akan pergi ke penjaga kebun binatang terlebih dahulu untuk mencari tahu di broker mana topik dan partisi disimpan. Dalam kasus ketika faktor replikasi lebih besar dari 1 ditentukan untuk topik, penjaga kebun binatang akan menunjukkan partisi mana yang menjadi pemimpin (mereka akan ditulis dan dibaca dari). Dalam hal terjadi kecelakaan broker, di penjaga kebun itulah informasi tentang partisi pemimpin baru akan direkam (pada versi 1.1.0 secara tidak sinkron, dan ini penting ).
Dalam versi Kafka yang lebih lama, zookeeper juga bertanggung jawab untuk menyimpan offset, tetapi sekarang mereka disimpan dalam topik khusus __consumer_offsets pada broker (walaupun Anda masih bisa menggunakan zookeeper untuk keperluan ini).
Cara termudah untuk mengubah data Anda menjadi labu hanyalah hilangnya informasi dengan penjaga kebun binatang. Dalam skenario seperti itu, akan sangat sulit untuk memahami apa dan dari mana membaca.
Produser
Produser adalah layanan yang paling sering menulis data langsung ke Apache Kafka. Produser memilih topik, di mana pesan tematiknya akan disimpan, dan mulai menulis informasi kepadanya. Misalnya, seorang produser bisa menjadi layanan iklan. Dalam hal ini, ia akan mengirim acara seperti "iklan dibuat", "iklan diperbarui", "iklan dihapus", dll. Ke topik tematik. Setiap acara adalah pasangan nilai kunci.
Secara default, semua acara didistribusikan oleh partisi partisi dengan round-robin jika kunci tidak diatur (kehilangan urutan), dan melalui MurmurHash (kunci) jika kunci ada (memesan dalam partisi yang sama).
Perlu segera dicatat di sini bahwa Kafka menjamin urutan acara hanya dalam satu partisi. Namun pada kenyataannya, seringkali ini bukan masalah. Misalnya, Anda dapat dengan yakin menambahkan semua perubahan pengumuman yang sama ke satu partisi (dengan demikian menjaga urutan perubahan ini dalam pengumuman). Anda juga dapat memasukkan nomor urut di salah satu bidang acara.
Konsumen
Konsumen bertanggung jawab untuk mengambil data dari Apache Kafka. Jika Anda kembali ke contoh di atas, konsumen dapat menjadi layanan moderasi. Layanan ini akan berlangganan ke topik layanan pengumuman, dan ketika iklan baru muncul, ia akan menerimanya dan menganalisisnya untuk kepatuhan dengan beberapa kebijakan tertentu.
Apache Kafka mengingat kejadian terkini apa yang diterima konsumen (topik layanan __consumer__offsets digunakan untuk ini), dengan demikian memastikan bahwa setelah membaca dengan sukses, konsumen tidak akan menerima pesan yang sama dua kali. Namun demikian, jika Anda menggunakan opsi enable.auto.commit = benar dan sepenuhnya memberikan pekerjaan melacak posisi konsumen dalam topik ke Kafka, Anda dapat kehilangan data . Dalam kode produksi, posisi konsumen paling sering dikontrol secara manual (pengembang mengontrol momen ketika komit dari peristiwa baca harus terjadi).
Dalam kasus di mana satu konsumen tidak cukup (misalnya, aliran acara baru sangat besar), Anda dapat menambah beberapa konsumen dengan menghubungkan mereka bersama-sama dalam kelompok konsumen. Kelompok konsumen secara logis adalah konsumen yang persis sama, tetapi dengan distribusi data di antara anggota kelompok. Ini memungkinkan masing-masing peserta untuk mengambil bagian dari pesan mereka, sehingga meningkatkan kecepatan membaca.
Hasil tes

Di sini saya tidak akan menulis banyak teks penjelasan, cukup bagikan hasilnya. Pengujian dilakukan pada 3 mesin fisik (12 CPU, 384GB RAM, 15k SAS DISK, 10GBit / s Net), broker dan penjaga kebun dikerahkan di lxc.
Pengujian kinerja
Selama pengujian, hasil berikut diperoleh.
- Kecepatan merekam pesan dalam ukuran 1KB secara bersamaan oleh 9 produsen - 1.300.000 peristiwa per detik.
- Kecepatan membaca pesan 1KB pada saat yang sama oleh 9 konsumen - 1.500.000 acara per detik.
Pengujian toleransi kesalahan
Selama pengujian, hasil berikut diperoleh (3 broker, 3 penjaga kebun).
- Pengakhiran abnormal salah satu broker tidak mengarah pada penangguhan atau tidak dapat diaksesnya kluster. Pekerjaan berlanjut seperti biasa, tetapi broker lainnya memiliki beban besar.
- Pemutusan abnormal dua broker dalam kasus cluster tiga broker dan min.isr = 2 mengarah pada tidak dapat diaksesnya cluster untuk menulis, tetapi untuk keterbacaan. Dalam kasus min.isr = 1, kluster terus tersedia untuk membaca dan menulis. Namun, mode ini bertentangan dengan persyaratan untuk keamanan data yang tinggi.
- Penghentian yang tidak normal dari salah satu server Zookeeper tidak mengarah ke shutdown cluster atau tidak dapat diaksesnya. Pekerjaan berlanjut seperti biasa.
- Pengakhiran yang tidak normal dari dua server Zookeeper menyebabkan cluster tidak dapat diakses hingga setidaknya satu dari server Zookeeper dipulihkan. Pernyataan ini berlaku untuk sekelompok server 3 Zookeeper. Akibatnya, setelah penelitian, diputuskan untuk meningkatkan cluster Zookeeper menjadi 5 server untuk meningkatkan toleransi kesalahan.
Kafka sebagai layanan

Kami memastikan bahwa Kafka adalah teknologi luar biasa yang memungkinkan kami untuk menyelesaikan set tugas untuk kami (mengimplementasikan broker pesan). Namun demikian, kami memutuskan untuk melarang layanan mengakses langsung Kafka dan menutupnya dengan layanan data-bus. Kenapa kita melakukan ini? Sebenarnya ada beberapa alasan.
Data-bus mengambil alih semua tugas yang terkait dengan integrasi dengan Kafka (implementasi dan konfigurasi konsumen dan produsen, pemantauan, peringatan, pencatatan, penskalaan, dll.). Dengan demikian, integrasi dengan broker pesan sesederhana mungkin.
Data-bus diizinkan untuk abstrak dari bahasa atau perpustakaan tertentu untuk bekerja dengan Kafka.
Bus data memungkinkan layanan lain untuk abstrak dari lapisan penyimpanan. Mungkin pada titik tertentu kita akan mengubah Kafka menjadi Pulsar, dan tidak ada yang akan melihat apa-apa (semua layanan hanya tahu tentang API data-bus).
Bus data mengambil alih validasi skema acara.
Menggunakan otentikasi data-bus diimplementasikan.
Di bawah sampul data-bus, kita dapat, tanpa downtime, secara diam-diam memperbarui versi Kafka, melakukan konfigurasi terpusat dari produsen, konsumen, broker, dll.
Data-bus memungkinkan kami untuk menambahkan fitur yang kami butuhkan yang tidak ada di Kafka (seperti audit topik, memantau anomali di cluster, membuat DLQ, dll.).
Data-bus memungkinkan failover diimplementasikan secara terpusat untuk semua layanan.
Saat ini, untuk mulai mengirim acara ke broker pesan, cukup sambungkan perpustakaan kecil ke kode layanan Anda. Itu saja. Anda memiliki kesempatan untuk menulis, membaca, dan skala dengan satu baris kode. Seluruh implementasi tersembunyi dari Anda, hanya beberapa batang seperti ukuran bets menonjol. Di bawah tenda, layanan data-bus meningkatkan jumlah instans produsen dan konsumen yang diperlukan di Kubernetes dan menambahkan konfigurasi yang diperlukan untuk mereka, tetapi semua ini transparan untuk layanan Anda.
Tentu saja, tidak ada peluru perak, dan pendekatan ini memiliki keterbatasan.
- Data-bus perlu didukung sendiri, tidak seperti perpustakaan pihak ketiga.
- Data-bus meningkatkan jumlah interaksi antara layanan dan broker pesan, yang mengarah pada kinerja yang lebih rendah dibandingkan dengan Kafka telanjang.
- Tidak semuanya bisa begitu saja disembunyikan dari layanan, kami tidak ingin menduplikasi fungsi KSQL atau Kafka Streaming di bus data, jadi terkadang Anda harus mengizinkan layanan untuk langsung pergi.
Dalam kasus kami, pro lebih besar daripada kontra, dan keputusan untuk meliput broker pesan dengan layanan terpisah dibenarkan. Selama tahun operasi, kami tidak mengalami kecelakaan dan masalah serius.
PS Terima kasih kepada pacar saya, Ekaterina Oblyalyaeva, untuk gambar-gambar keren untuk artikel ini. Jika Anda menyukainya, ada lebih banyak ilustrasi.