Saya memutuskan untuk membagikannya, tetapi saya sendiri tidak akan lupa bagaimana alat statistik sederhana dapat digunakan untuk menganalisis data. Sebagai contoh, kami menggunakan survei anonim mengenai gaji, masa kerja, dan posisi programmer Ukraina untuk 2014 dan 2019. (1)
Langkah-langkah analisis
- Pra-pemrosesan data dan analisis pendahuluan ( siapa pun yang tertarik dengan kode di sini )
- Representasi grafis dari data. Fungsi kepadatan distribusi.
- Kami merumuskan hipotesis nol (H0) (2)
- Pilih metrik untuk analisis
- Kami menggunakan metode bootstraping untuk membentuk array data baru.
- Kami menghitung nilai-p (3) untuk mengkonfirmasi atau membantah hipotesis
Pra-pemrosesan data
Setelah beberapa manipulasi (
kode ada di sini ), kami menyajikan data dalam bentuk berikut:
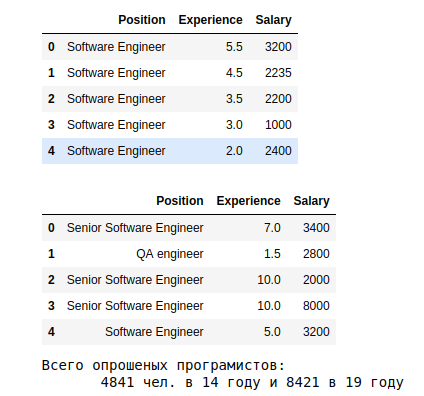
Pengelompokan lebih sedikit selama satu tahun (biarkan tanggal 19):

Estimasi pertama adalah sebagai berikut.
a. Hasilnya menunjukkan bahwa rata-rata pada tahun 19, mereka yang telah bekerja selama lebih dari 10 tahun menerima lebih dari 3,5 ribu. Ketergantungan pengalaman -> zp
c. S.p. rata-rata pada tahun 19, tergantung pada spesialisasi, mereka menunjukkan penyebaran 10 kali - dari 5k untuk Arsitek Sistem, menjadi 575 untuk Junior QA.
s Piring terakhir menunjukkan distribusi menurut profesi. Sebagian besar data tentang Insinyur Perangkat Lunak, tanpa kualifikasi.
Kami menarik perhatian pada kekhasan tahun ke-19: Ada yang salah dengan pengalaman tahun ke-9 dan tidak ada klasifikasi menurut tingkat junior, menengah, senior. Anda dapat lebih memahami alasan outlier tahun ke-9. Tetapi untuk analisis ini, kami menganggapnya apa adanya.
Tetapi dengan kategori - ada baiknya memilah. pada tahun 19, Insinyur Perangkat Lunak 2739 orang (35% dari semuanya) tanpa menunjukkan tingkat kualifikasi. Mari kita menghitung rata-rata dan penyimpangan untuk mereka yang ditunjukkan.
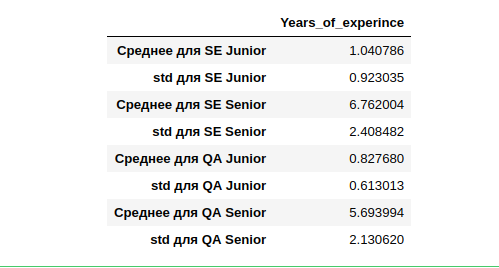
Ternyata pengalaman kerja rata-rata (yang menunjukkannya) untuk SE Junior adalah satu tahun, dengan penyimpangan yang cukup luas dari satu tahun. SE Senior memiliki pengalaman terbanyak dengan deviasi 2,4 tahun yang hampir sama.
Jika kami mencoba menghitung Pertengahan dan menggunakan pengalaman rata-rata dari mereka yang menunjukkannya, maka untuk mengelompokkan yang tidak menunjukkannya, kami mungkin tidak mengelompokkan seluruh sampel dengan benar. Kami terutama akan membuat kesalahan pada spesialisasi lain (bukan SE dan QA) yaitu. terlalu sedikit data. Selain itu, ada beberapa dari mereka untuk perbandingan dengan tahun ke-14.
Apa lagi yang bisa saya gunakan?
Mari kita ambil hanya tingkat gaji sebagai indikator tingkat keterampilan yang dapat diandalkan! (Saya pikir akan ada perbedaan pendapat).
Pertama, kami membangun seperti apa distribusi gaji untuk tahun ke-19.
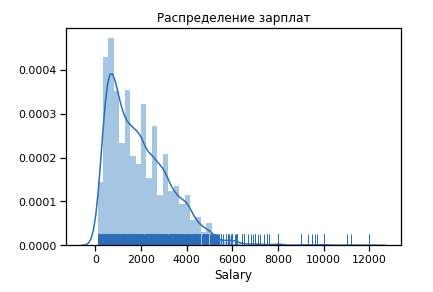
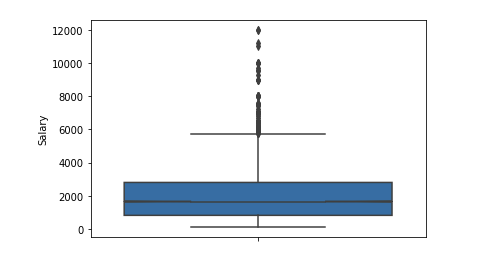
Angka signifikan outlier setelah 6 $ k. Kami meninggalkan rentang batasan [400 - 4000]. Setiap programmer harus mendapatkan lebih dari 400 :)
df_new = data_19_1[(data_19_1['Salary'] > 400) & (data_19_1['Salary'] < 4000)] sns.distplot(df_new['Salary'], rug=True, norm_hist=True)
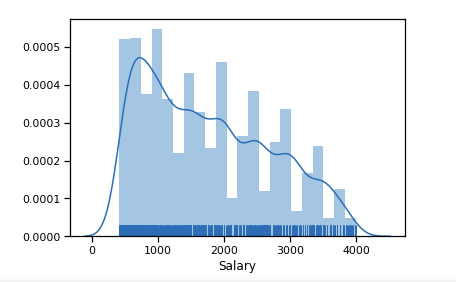
Sudah sedikit lebih dekat dengan distribusi normal.
Kami menyusun selama 19 tahun, tingkat keterampilan tergantung pada RFP. Rentang $ 3600 memberi kami pembagi yang baik menjadi 3 kategori - $ 1.200
df_new.reset_index() df_new.loc['level'] = 0 df_new.loc[df_new.Salary <= 1200, 'level'] = 'Junior' df_new.loc[(df_new.Salary > 1200) & (df_new.Salary <= 2400), 'level'] = 'Middle' df_new.loc[df_new.Salary > 2401, 'level'] = 'Senior'
Draw - kategori kepadatan selama 19 tahun.
sns.set(style="whitegrid") fig, ax = plt.subplots() fig.set_size_inches(11.7, 8.27) plt.title(' 19 ') sns.barplot(x='level', y='Salary', hue='Experience', hue_order=[1,3,5,7,10], palette='Blues', \ data=df_new, ci='sd')

Dengan menambahkan jumlah pengalaman yang ditentukan (sudut kiri), Anda dapat melihat berbagai nuansa. Sebagai contoh, bahwa rata-rata Junior mendapatkan hingga 1k dan pengalaman kerjanya 5 tahun. Penyebaran terbesar di sn at Senior (garis pendek hitam di bagian atas setiap kolom) dan banyak detail menarik lainnya.
Di sinilah dua tahap pertama selesai, kami melanjutkan ke pengujian hipotesis menggunakan bootstraping.
Kami merumuskan hipotesis nol (H0)
Pada tahap pertama, kami menemukan bahwa pengalaman kerja yang ditentukan tidak terlalu akurat berarti tingkat kualifikasi. Kemudian kita membentuk hipotesis nol (hipotesis yang perlu disangkal)
Ada banyak opsi (misalnya):
- Ketergantungan gaji pada senioritas pada tahun 14 sama dengan pada tanggal 19.
- Gaji junior belum berubah sejak 14 tahun.
Namun, karena pengalaman yang ditunjukkan adalah indikator yang buruk, dan perhitungan untuk kategori tertentu dapat membingungkan, maka kami mengambil pilihan yang lebih sederhana dan lebih substantif: Tingkat
rata -
rata pada 14, sama seperti pada 19, adalah hipotesis nol kami H0 (2).
Artinya, kami menganggap bahwa gaji selama 5 tahun tidak berubah.
BUKAN kesetiaan hipotesis, terlepas dari semua kejelasannya, kita dapat memeriksa secara akurat dengan menghitung nilai-P untuk hipotesis nol.
Gaji rata-rata pada tahun 14 adalah $ 1797, di mana interval kepercayaannya adalah 95% [300,0 4000,0]
Gaji rata-rata pada tahun 19 adalah $ 1949, di mana interval kepercayaannya adalah 95% [300,0 5000,0]
Perbedaan rata-rata gaji pada tahun 14 dan 19: $ 152
Metrik untuk analisis
Adalah logis untuk memilih nilai rata-rata sebagai metrik kami. Pilihan lain dimungkinkan, misalnya median, yang sering dilakukan dalam kasus sejumlah besar pencilan. Namun, rata-rata sebagai perkiraan mudah dipahami dan juga memberikan ide yang bagus.
Menulis fungsi bootstrap.
Kami menghitung statistik kami.
p-value = 0,0
Nilai P hingga 0,05 dianggap tidak signifikan, dan dalam kasus kami sama dengan 0. Yang berarti hipotesis nol
ditolak - gaji rata-rata pada tahun 14 dan 19 berbeda dan ini bukan hasil yang tidak disengaja atau jumlah outlier yang signifikan.
Kami menghasilkan 10 ribu array seperti itu, rata-rata, tidak bisa mendapatkan lebih banyak detasemen seperti itu daripada data itu sendiri.
Meskipun kami menghabiskan banyak perhatian pada dua tahap pertama, kami merumuskan hipotesis yang benar dan memilih metrik yang tepat. Dalam tugas yang lebih kompleks, dengan sejumlah besar variabel, tanpa langkah awal seperti itu, analitik dapat menyebabkan penafsiran yang salah. Jangan lewati mereka.
Sebagai hasil dari studi kami tentang tingkat gaji selama 14 dan 19 tahun, kami sampai pada kesimpulan sebagai berikut:
- Berdasarkan data survei, pengalaman yang ditentukan bukanlah kriteria yang sepenuhnya cocok untuk menentukan tingkat gaji dan kualifikasi.
- Pembagian ke dalam tingkat keterampilan kemungkinan besar akan didasarkan pada tingkat gaji.
- Gaji programmer meningkat dari 14 menjadi 19 (rata-rata 8,5%) dan ini bukan hasil yang tidak disengaja.
Terima kasih atas perhatian anda Saya akan senang memberikan komentar dan kritik.
Sumber
- https://jobs.dou.ua/salaries/ (hasil survei)
- https://en.wikipedia.org/wiki/Null_hypothesis
- https://en.wikipedia.org/wiki/P-value