Beberapa waktu lalu kami
mengumumkan rilis publik dan dibuka di bawah lisensi MIT kode sumber
LuaVela - implementasi Lua 5.1, berdasarkan LuaJIT 2.0. Kami mulai mengerjakannya pada 2015, dan pada awal 2017 itu digunakan di lebih dari 95% proyek perusahaan. Sekarang saya ingin melihat kembali jalan yang dilalui. Keadaan apa yang mendorong kami untuk mengembangkan implementasi bahasa pemrograman kami sendiri? Masalah apa yang kita hadapi dan bagaimana kita menyelesaikannya? Bagaimana LuaVela berbeda dari garpu LuaJIT lainnya?
Latar belakang
Bagian ini didasarkan pada
laporan kami tentang HighLoad ++. Kami mulai aktif menggunakan Lua untuk menulis logika bisnis produk kami di tahun 2008. Awalnya vanua Lua, dan sejak 2009 - LuaJIT. Protokol RTB meletakkan kerangka kerja yang ketat untuk memproses permintaan, sehingga transisi ke implementasi bahasa yang lebih cepat adalah logis dan, dari beberapa titik, solusi yang diperlukan.
Seiring waktu, kami menyadari bahwa ada batasan tertentu pada arsitektur LuaJIT. Yang paling penting bagi kami adalah bahwa LuaJIT 2.0 menggunakan pointer 32-bit. Ini membawa kami ke situasi di mana berjalan di Linux 64-bit membatasi ukuran ruang alamat virtual memori proses menjadi satu gigabyte (dalam versi kernel Linux yang lebih baru, batas ini dinaikkan menjadi dua gigabyte):
void *ptr = mmap((void *)MMAP_REGION_START, size, MMAP_PROT, MAP_32BIT | MMAP_FLAGS, -1, 0);
Keterbatasan ini menjadi masalah besar - pada tahun 2015, 1-2 gigabyte memori tidak lagi cukup untuk banyak proyek untuk memuat data yang bekerja dengan logika. Perlu dicatat bahwa setiap instance dari mesin virtual Lua adalah single-threaded dan tidak tahu cara berbagi data dengan instance lain - ini berarti bahwa dalam praktiknya, setiap mesin virtual dapat mengklaim ukuran memori tidak melebihi 2GB / n, di mana n adalah jumlah alur kerja server kami aplikasi.
Kami melewati beberapa solusi untuk masalah ini: kami mengurangi jumlah utas di server aplikasi kami, mencoba mengatur akses ke data melalui LuaJIT FFI, menguji transisi ke LuaJIT 2.1. Sayangnya, semua opsi ini tidak menguntungkan secara ekonomi atau tidak memiliki skala yang baik dalam jangka panjang. Satu-satunya yang tersisa bagi kami adalah mengambil kesempatan dan bercabang LuaJIT. Pada saat ini, kami membuat keputusan yang sangat menentukan nasib proyek.
Pertama, kami segera memutuskan untuk tidak membuat perubahan pada sintaks dan semantik bahasa tersebut, dengan fokus menghilangkan batasan arsitektur LuaJIT, yang ternyata menjadi masalah bagi perusahaan. Tentu saja, ketika proyek dikembangkan, kami mulai menambahkan ekstensi (kami akan membahas ini di bawah) - tetapi kami mengisolasi semua API baru dari perpustakaan bahasa standar.
Selain itu, kami meninggalkan lintas platform demi mendukung hanya Linux x86-64, satu-satunya platform produksi kami. Sayangnya, kami tidak memiliki sumber daya yang cukup untuk menguji jumlah perubahan raksasa yang akan kami buat ke platform.
Sekilas di bawah kap platform
Mari kita lihat dari mana batasan ukuran pointer berasal. Untuk mulai dengan, tipe
angka dalam Lua 5.1 adalah (dengan beberapa peringatan kecil) tipe C ganda, yang pada gilirannya sesuai dengan tipe presisi ganda yang didefinisikan oleh standar IEEE 754. Dalam pengkodean tipe 64-bit ini, kisaran nilai disorot untuk presentasi NaN. Secara khusus, berapa nilai dalam kisaran [0xFFF8000000000000; 0xFFFFFFFFFFFFFFFFFF].
Dengan demikian, kita dapat mengemas nilai 64-bit tunggal baik nomor presisi ganda "nyata", atau entitas tertentu, yang dari sudut pandang tipe ganda akan ditafsirkan sebagai NaN, dan dari sudut pandang platform kami itu akan menjadi sesuatu yang lebih bermakna - misalnya, menurut jenis objek (32 bit tinggi) dan penunjuk ke isinya (32 bit rendah):
union TValue { double n; struct object { void *payload; uint32_t type; } o; };
Teknik ini kadang-kadang disebut penandaan NaN (atau tinju NaN), dan TValue pada dasarnya menggambarkan bagaimana LuaJIT mewakili nilai variabel dalam Lua. TValue juga memiliki hipostasis ketiga yang digunakan untuk menyimpan pointer ke fungsi dan informasi untuk memutar kembali tumpukan Lua, yaitu, dalam analisis akhir, struktur data terlihat seperti ini:
union TValue { double n; struct object { void *payload; uint32_t type; } o; struct frame { void *func; uintptr_t link; } f; };
Bidang frame.link dalam definisi di atas adalah tipe uintptr_t, karena dalam beberapa kasus ini menyimpan pointer, dan dalam kasus lain itu adalah integer. Hasilnya adalah representasi yang sangat kompak dari tumpukan mesin virtual - pada kenyataannya, itu adalah array nilai TV, dan setiap elemen array ditafsirkan secara situasional sebagai salah satu angka, kemudian sebagai pointer yang diketik ke objek, atau sebagai data tentang bingkai Lua-stack.
Mari kita lihat sebuah contoh. Bayangkan kita mulai dengan LuaJIT kode Lua ini dan mengatur break point di dalam fungsi cetak:
local function foo(x) print("Hello, " .. x) end local function bar(a, b) local n = math.pi foo(b) end bar({}, "Lua")
Lua stack pada titik ini akan terlihat seperti ini:

Dan semuanya akan baik-baik saja, tetapi teknik ini mulai gagal segera setelah kami mencoba memulai pada x86-64. Jika kita menjalankan dalam mode kompatibilitas untuk aplikasi 32-bit, kita bersandar pada pembatasan mmap yang telah disebutkan di atas. Dan pointer 64-bit tidak akan bekerja di luar kotak sama sekali. Apa yang harus dilakukan Untuk memperbaiki masalah saya harus:
- Perpanjang nilai TV dari 64 hingga 128 bit: dengan cara ini kita mendapatkan kekosongan "jujur" pada platform 64-bit.
- Perbaiki kode mesin virtual sesuai.
- Buat perubahan pada kompiler JIT.
Total volume perubahan ternyata sangat signifikan dan cukup mengasingkan kami dari LuaJIT yang asli. Perlu dicatat bahwa ekstensi TValue bukan satu-satunya cara untuk menyelesaikan masalah. Di LuaJIT 2.1, kami pergi dengan cara lain dengan menerapkan mode LJ_GC64. Peter Cawley, yang membuat kontribusi besar untuk pengembangan mode operasi ini, membacanya di sebuah pertemuan di London. Nah, dalam kasus LuaVela, tumpukan untuk contoh yang sama terlihat seperti ini:
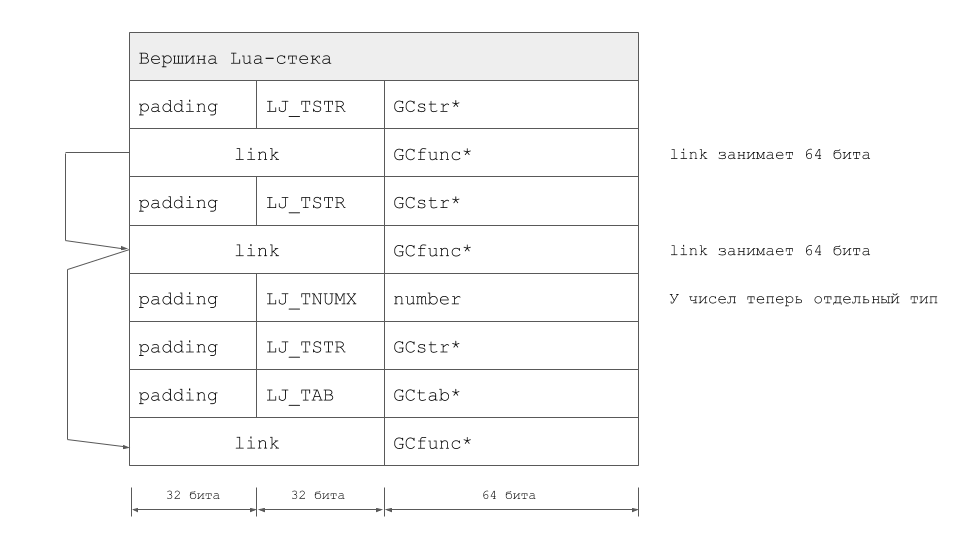
Keberhasilan pertama dan stabilisasi proyek
Setelah berbulan-bulan pengembangan aktif, saatnya untuk mencoba LuaVela dalam pertempuran. Sebagai percobaan, kami memilih proyek yang paling bermasalah dalam hal konsumsi memori: jumlah data yang harus mereka gunakan, jelas melebihi 1 gigabyte, sehingga mereka terpaksa menggunakan berbagai solusi. Hasil pertama menggembirakan: LuaVela stabil dan menunjukkan kinerja yang lebih baik dibandingkan dengan konfigurasi LuaJIT yang digunakan dalam proyek yang sama ini.
Pada saat yang sama, pertanyaan tentang pengujian muncul. Untungnya, kami tidak harus memulai dari awal, karena sejak hari pertama pengembangan, selain melakukan staging server, kami juga siap membantu:
- Tes fungsional dan integrasi server aplikasi yang menjalankan logika bisnis semua proyek perusahaan.
- Tes proyek individu.
Seperti yang telah ditunjukkan oleh praktik, sumber daya ini cukup untuk debugging dan membawa proyek ke kondisi stabil minimum (mereka melakukan perakitan dev - diluncurkan ke pementasan - itu bekerja dan tidak macet). Di sisi lain, pengujian seperti itu melalui proyek-proyek lain benar-benar tidak cocok dalam jangka panjang: proyek dengan tingkat kerumitan seperti implementasi bahasa pemrograman tidak dapat memiliki tes sendiri. Selain itu, kurangnya tes langsung di proyek murni teknis rumit pencarian dan koreksi kesalahan.
Dalam dunia yang ideal, kami ingin menguji tidak hanya implementasi kami, tetapi juga memiliki serangkaian tes yang memungkinkan kami untuk memvalidasinya terhadap
semantik bahasa . Sayangnya, beberapa kekecewaan menunggu kami dalam masalah ini. Terlepas dari kenyataan bahwa komunitas Lua secara sukarela membuat percabangan implementasi yang ada, hingga saat ini, serangkaian uji validasi yang sama tidak ada. Situasi berubah menjadi lebih baik ketika, pada akhir 2018, François Perrad
mengumumkan proyek lua-Harness.
Pada akhirnya, kami menutup masalah pengujian dengan mengintegrasikan suite pengujian paling lengkap dan representatif dalam ekosistem Lua ke dalam repositori kami:
- Tes yang ditulis oleh pencipta bahasa untuk implementasi Lua 5.1.
- Tes disediakan oleh komunitas oleh penulis LuaJIT Mike Pall.
- lua harness
- Subset dari tes proyek MAD sedang dikembangkan oleh CERN.
- Dua set tes yang telah kami buat di IPONWEB dan terus diisi ulang sejauh ini: satu untuk pengujian fungsional platform, yang lain menggunakan kerangka kerja cmocka untuk menguji C API dan semua yang kurang pengujian pada level kode Lua.
Pengenalan setiap kumpulan tes memungkinkan kami untuk mendeteksi dan memperbaiki 2-3 kesalahan kritis - jadi jelas bahwa upaya kami membuahkan hasil. Meskipun topik pengujian runtime dan kompiler bahasa (baik statis maupun dinamis) benar-benar tidak terbatas, kami percaya bahwa kami telah meletakkan dasar yang agak solid untuk pengembangan proyek yang stabil. Kami berbicara tentang masalah pengujian implementasi Lua kami sendiri (termasuk topik seperti bekerja dengan bangku tes dan debugging postmortem) dua kali, di
Lua di Moskow 2017 dan di
HighLoad ++ 2018 - setiap orang yang tertarik pada detail dipersilakan untuk menonton video dari laporan ini. Nah, lihat direktori
tes di repositori kami, tentu saja.
Fitur baru
Dengan demikian, kami memiliki implementasi stabil Lua 5.1 untuk Linux x86-64, yang dikembangkan oleh kekuatan tim kecil yang secara bertahap “menguasai” warisan LuaJIT dan mengumpulkan keahlian. Dalam kondisi seperti itu, keinginan untuk memperluas platform dan menambahkan fitur yang tidak ada di vanilla Lua maupun di LuaJIT, tetapi yang akan membantu kami memecahkan masalah mendesak lainnya, menjadi sangat wajar.
Deskripsi terperinci dari semua ekstensi disediakan dalam
dokumentasi dalam format RST (gunakan cmake. && buat dokumen untuk membuat salinan lokal dalam format HTML). Deskripsi lengkap tentang ekstensi Lua API dapat ditemukan
di tautan ini , dan C API
di sini . Sayangnya, dalam artikel ulasan tidak mungkin untuk membicarakan semuanya, jadi di sini adalah daftar fungsi yang paling signifikan:
- DataState - kemampuan untuk mengatur akses bersama ke objek dari beberapa instance independen mesin virtual Lua.
- Kemampuan untuk mengatur batas waktu untuk coroutine dan mengganggu eksekusi mereka yang berjalan lebih lama dari itu.
- Serangkaian optimisasi kompiler JIT yang dirancang untuk memerangi peningkatan eksponensial dalam jumlah jejak saat menyalin data di antara objek - kami membicarakan hal ini di HighLoad ++ 2017, tetapi hanya beberapa bulan yang lalu kami memiliki ide kerja baru yang belum didokumentasikan.
- Toolkit Baru: Sampling Profiler. dumpanalyze compiler debug output analyzer, dll.
Masing-masing fitur ini layak mendapat artikel terpisah - tulis di komentar mana yang ingin Anda baca lebih lanjut.
Di sini saya ingin berbicara sedikit tentang bagaimana kami mengurangi beban pada pengumpul sampah.
Sealing memungkinkan Anda untuk membuat objek tidak dapat diakses oleh pengumpul sampah. Dalam proyek khas kami, sebagian besar data (hingga 80%) di dalam mesin virtual Lua sudah merupakan aturan bisnis, yang merupakan tabel Lua yang kompleks. Masa hidup tabel ini (menit) jauh lebih lama dari masa permintaan yang diproses (puluhan milidetik), dan data di dalamnya tidak berubah selama pemrosesan kueri. Dalam situasi seperti itu, tidak masuk akal untuk memaksa pengumpul sampah untuk berulang di sekitar struktur data besar ini berulang kali. Untuk melakukan ini, kami secara rekursif "menyegel" objek dan menyusun ulang data sedemikian rupa sehingga pengumpul sampah tidak pernah mencapai objek "yang disegel" atau isinya. Dalam vanilla Lua 5.4, masalah ini akan
diselesaikan dengan mendukung generasi objek dalam pengumpulan sampah generasi.
Penting untuk diingat bahwa objek "yang disegel" tidak boleh ditulis. Ketidaktaatan terhadap invarian ini mengarah pada munculnya petunjuk yang menggantung: misalnya, objek "tertutup" mengacu pada objek biasa, dan pengumpul sampah, melewatkan objek "tersegel" saat berjalan di sekitar tumpukan, melompati objek biasa - dengan perbedaan bahwa objek "tersegel" tidak dapat dilepaskan, dan yang biasa bisa. Setelah menerapkan dukungan untuk invarian ini, kami pada dasarnya mendapatkan dukungan
imunitas gratis
untuk objek, yang tidak ada yang sering disesalkan di Lua. Saya menekankan bahwa benda-benda yang tidak dapat diubah dan “disegel” bukanlah hal yang sama. Properti kedua menyiratkan yang pertama, tetapi tidak sebaliknya.
Saya juga mencatat bahwa di Lua 5.1 kekebalan dapat diimplementasikan menggunakan metatables - solusinya cukup berhasil, tetapi bukan yang paling menguntungkan dalam hal kinerja. Informasi lebih lanjut tentang kekebalan "pemeteraian", dan bagaimana kita menggunakannya dalam kehidupan sehari-hari dapat ditemukan dalam laporan
ini .
Kesimpulan
Saat ini, kami puas dengan stabilitas dan serangkaian peluang untuk implementasi kami. Dan meskipun karena keterbatasan awal, implementasi kami jauh lebih rendah daripada vanilla Lua dan LuaJIT dalam hal portabilitas, itu memecahkan banyak masalah kami - kami berharap solusi ini bermanfaat bagi orang lain.
Selain itu, bahkan jika LuaVela tidak cocok untuk produksi, kami mengundang Anda untuk menggunakannya sebagai titik masuk untuk memahami cara kerja LuaJIT atau fork-nya. Selain menyelesaikan masalah dan memperluas fungsionalitas, selama bertahun-tahun kami telah refactored bagian penting dari basis kode dan menulis
artikel pelatihan tentang struktur internal proyek - banyak di antaranya berlaku tidak hanya untuk LuaVela, tetapi juga untuk LuaJIT.
Terima kasih atas perhatian Anda, kami menunggu permintaan tarik!