Dalam beberapa tahun terakhir,
terjemahan mesin saraf (NMP) menggunakan model "transformator" telah mencapai kesuksesan luar biasa. IMF berdasarkan jaringan saraf yang dalam biasanya dilatih dari awal hingga akhir dalam kasus paralel teks yang sangat banyak (pasangan teks) semata-mata berdasarkan data itu sendiri, tanpa perlu menetapkan aturan bahasa yang tepat.
Terlepas dari semua keberhasilan tersebut, model NMP dapat peka terhadap perubahan kecil dalam data input, yang dapat memanifestasikan dirinya dalam bentuk berbagai kesalahan - terjemahan yang kurang, terjemahan yang berlebihan, terjemahan yang salah. Misalnya, proposal Jerman berikutnya, “transformer” model NMP berkualitas tinggi akan diterjemahkan dengan benar.
"Der Sprecher des Untersuchungsausschusses topi angekündigt, vor Gericht zu ziehen, jatuh dan jatuh cinta dengan Zeugen weiterhin weigern sollten, eine Aussage zu machen."
(Terjemahan mesin: "Juru bicara Komite Penyelidikan telah mengumumkan bahwa jika para saksi yang dipanggil terus menolak untuk bersaksi, ia akan dibawa ke pengadilan.")
Terjemahan: Seorang wakil dari Komite Investigasi mengumumkan bahwa jika saksi yang diundang terus menolak untuk bersaksi, dia akan dimintai pertanggungjawaban.
Namun, ketika Anda membuat perubahan kecil pada kalimat yang masuk, menggantikan geladenen dengan sinonim vorgeladenen, terjemahannya berubah secara dramatis (dan menjadi salah):
"Der Sprecher des Untersuchungsausschusses topi angekündigt, vor Gericht zu ziehen, jatuh cinta pada kita, kecuali kita weigern sollten, eine Aussage zu machen."
(Terjemahan mesin: "Komite investigasi telah mengumumkan bahwa ia akan dibawa ke pengadilan jika saksi yang telah diundang terus menolak untuk bersaksi.").
Terjemahan: komite investigasi mengumumkan bahwa dia akan dibawa ke pengadilan jika saksi yang diundang terus menolak untuk memberikan kesaksian.
Kurangnya stabilitas model NMP tidak memungkinkan sistem komersial untuk diterapkan pada tugas-tugas di mana tingkat ketidakstabilan yang serupa tidak dapat diterima. Oleh karena itu, ketersediaan model terjemahan berkelanjutan tidak hanya diinginkan, tetapi sering kali diperlukan. Pada saat yang sama, meskipun stabilitas jaringan saraf dipelajari secara aktif oleh komunitas peneliti visi komputer, ada beberapa bahan tentang model pembelajaran NMP yang stabil.
Dalam
makalah kami
, "Terjemahan mesin berkelanjutan dengan input permusuhan ganda," kami mengusulkan pendekatan yang menggunakan contoh permusuhan yang dihasilkan untuk meningkatkan stabilitas model terjemahan mesin untuk perubahan input kecil. Kami mengajarkan model NMP yang stabil untuk mengatasi contoh kompetitif yang dihasilkan dengan mempertimbangkan pengetahuan tentang model ini dan untuk mendistorsi prediksi. Kami menunjukkan bahwa pendekatan ini meningkatkan efisiensi model NMP dalam tes standar.
Pelatihan Model dengan AdvGen
Model NMP yang ideal harus menghasilkan terjemahan serupa untuk input berbeda yang memiliki sedikit perbedaan. Gagasan pendekatan kami adalah untuk mengganggu model terjemahan menggunakan input kompetitif dengan harapan meningkatkan stabilitasnya. Ini dilakukan dengan menggunakan algoritma Generasi Adversarial (AdvGen), yang menghasilkan contoh kompetitif yang valid yang mengganggu model dan kemudian memasukkannya ke dalam model untuk pelatihan. Meskipun metode ini terinspirasi oleh gagasan jaringan kompetitif generatif (GSS), metode ini tidak menggunakan jaringan yang diskriminatif, tetapi hanya menggunakan contoh kompetitif dalam pelatihan, pada kenyataannya, mendiversifikasi dan memperluas rangkaian pelatihan.
Langkah pertama adalah membuat marah data dengan AdvGen. Kami mulai dengan menggunakan transformator untuk menghitung kehilangan transfer berdasarkan penawaran masuk asli, penawaran input target, dan penawaran output target. AdvGen kemudian secara acak memilih kata-kata dalam kalimat asli, bertindak berdasarkan asumsi distribusi seragam mereka. Setiap kata memiliki daftar kata-kata serupa yang sesuai, yaitu kandidat substitusi. Dari situ, AdvGen memilih kata yang paling mungkin menyebabkan kesalahan dalam output transformator. Kemudian kalimat musuh yang dihasilkan ini diumpankan kembali ke transformator, memulai tahap pertahanan.
 Pertama, model transformator diterapkan pada kalimat yang masuk (kiri bawah), dan kemudian kerugian terjemahan dihitung bersama dengan kalimat output target (di atas atas) dan kalimat input target (di kanan tengah, dimulai dengan "<sos>"). AdvGen kemudian menerima kalimat asli, distribusi pemilihan kata, kandidat kata, dan kehilangan terjemahan sebagai input, dan membuat contoh kode sumber permusuhan.
Pertama, model transformator diterapkan pada kalimat yang masuk (kiri bawah), dan kemudian kerugian terjemahan dihitung bersama dengan kalimat output target (di atas atas) dan kalimat input target (di kanan tengah, dimulai dengan "<sos>"). AdvGen kemudian menerima kalimat asli, distribusi pemilihan kata, kandidat kata, dan kehilangan terjemahan sebagai input, dan membuat contoh kode sumber permusuhan.Pada tahap pertahanan, kode sumber permusuhan diumpankan kembali ke transformator. Kehilangan terjemahan dihitung lagi, tetapi kali ini menggunakan sumber input yang kontroversial. Menggunakan metode yang sama seperti sebelumnya, AdvGen menggunakan kalimat masuk yang ditargetkan, distribusi pemilihan kata yang dihitung dari matriks perhatian, kandidat untuk penggantian kata, dan kehilangan terjemahan untuk membuat contoh kode sumber yang kontroversial.
 Pada tahap pertahanan, kode sumber permusuhan menjadi input untuk transformator, dan kerugian terjemahan dihitung. Menggunakan metode yang sama seperti sebelumnya, AdvGen menciptakan contoh kode sumber yang kontroversial berdasarkan input target.
Pada tahap pertahanan, kode sumber permusuhan menjadi input untuk transformator, dan kerugian terjemahan dihitung. Menggunakan metode yang sama seperti sebelumnya, AdvGen menciptakan contoh kode sumber yang kontroversial berdasarkan input target.Akhirnya, kalimat permusuhan diumpankan kembali ke transformator, dan hilangnya stabilitas dihitung berdasarkan contoh sumber permusuhan, contoh input target permusuhan dan kalimat target. Jika intervensi dalam teks menyebabkan kerugian yang signifikan, mereka diminimalkan sehingga ketika model menghadapi gangguan yang sama, dia tidak mengulangi kesalahan yang sama. Di sisi lain, jika gangguan menyebabkan kerugian kecil, tidak ada yang terjadi, yang menunjukkan bahwa model sudah mampu mengatasi gangguan seperti itu.
Model Performa
Kami menunjukkan efektivitas pendekatan kami dengan menerapkannya pada tes terjemahan standar dari Bahasa Mandarin ke Bahasa Inggris dan dari Bahasa Inggris ke Bahasa Jerman. Kami mendapatkan peningkatan signifikan dalam terjemahan sebesar 2,8 dan 1,6 poin BLEU, masing-masing, dibandingkan dengan model trafo yang bersaing, dan mencapai rekor kualitas terjemahan yang baru.
 Perbandingan model transformator pada pengujian standar
Perbandingan model transformator pada pengujian standarKemudian kami mengevaluasi kinerja model kami pada kumpulan data yang berisik menggunakan prosedur yang mirip dengan yang dijelaskan untuk AdvGen. Kami mengambil data input murni, misalnya, yang digunakan dalam tes standar penerjemah, dan secara acak memilih kata-kata yang kami ganti dengan yang serupa. Kami menemukan bahwa model kami menunjukkan peningkatan stabilitas dibandingkan dengan model terbaru lainnya.
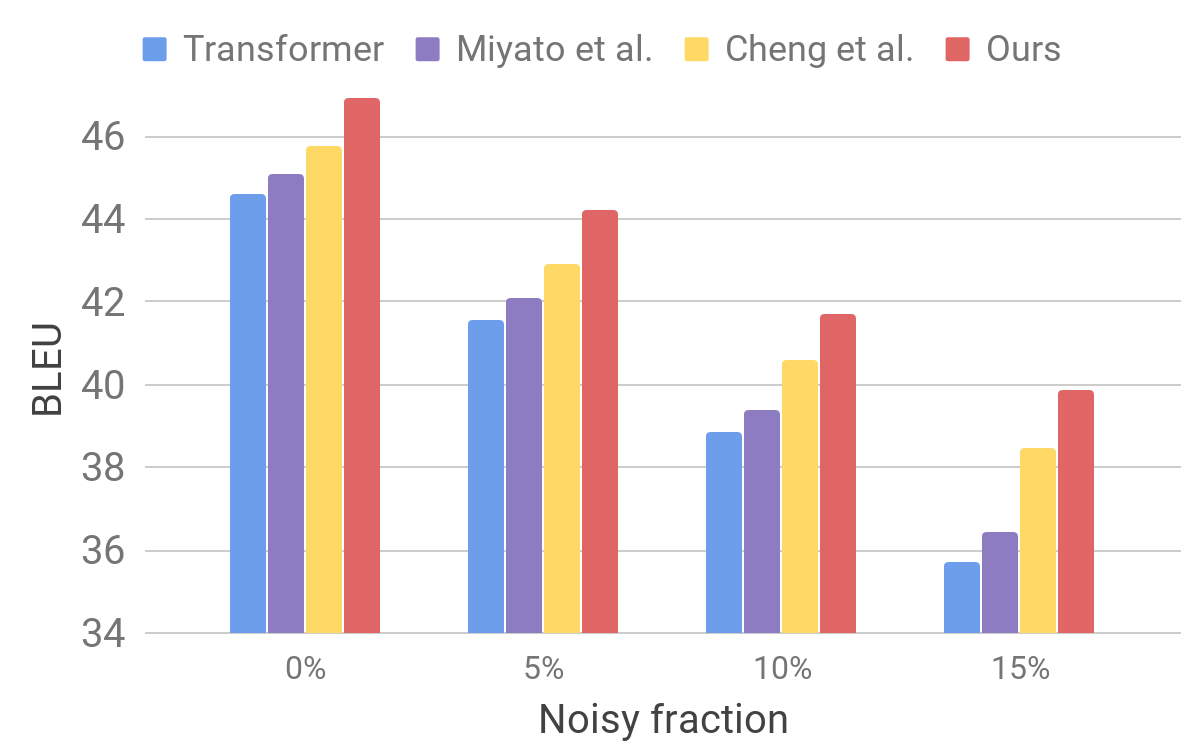 Perbandingan transformator dan model lain pada data input berisik buatan
Perbandingan transformator dan model lain pada data input berisik buatanHasil ini menunjukkan bahwa metode kami mampu mengatasi gangguan kecil yang timbul dalam kalimat yang masuk dan meningkatkan efisiensi generalisasi. Ia unggul dalam model terjemahan yang bersaing dan mencapai efisiensi terjemahan pada tes standar. Kami berharap bahwa model penerjemah kami akan menjadi dasar yang stabil untuk meningkatkan hasil penyelesaian banyak masalah berikut, terutama yang sensitif atau tidak toleran terhadap teks input yang tidak sempurna.