Meskipun jaringan saraf mulai digunakan untuk sintesis ucapan belum lama ini ( misalnya ), mereka telah berhasil menyalip pendekatan klasik dan setiap tahun mereka mengalami tugas yang lebih baru dan lebih baru.
Sebagai contoh, beberapa bulan yang lalu ada implementasi sintesis pidato dengan kloning suara Real-Time-Voice-Cloning . Mari kita coba mencari tahu apa itu terdiri dan mewujudkan model fonem multibahasa (Rusia-Inggris) kami.
Membangun
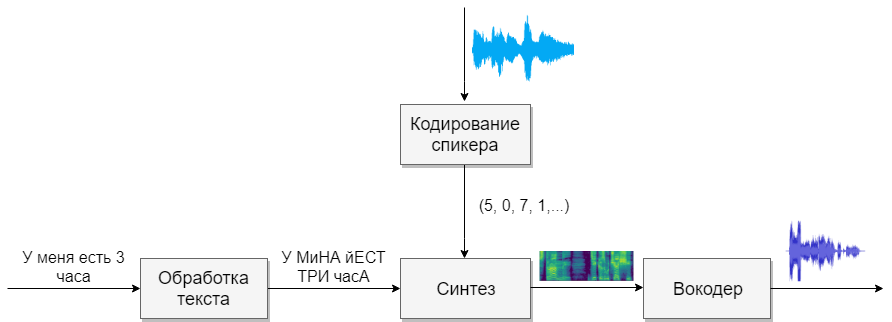
Model kami akan terdiri dari empat jaringan saraf. Yang pertama akan mengubah teks menjadi fonem (g2p), yang kedua akan mengubah ucapan yang ingin kita klon menjadi vektor tanda (angka). Yang ketiga akan mensintesis spektogram Mel berdasarkan output dari dua yang pertama. Dan akhirnya, yang keempat akan menerima suara dari spektogram.
Kumpulan data
Model ini membutuhkan banyak bicara. Di bawah ini adalah pangkalan yang akan membantu dalam hal ini.
Pengolah kata
Tugas pertama adalah pemrosesan teks. Bayangkan teks dalam bentuk yang akan disuarakan lebih lanjut. Kami akan mewakili angka dalam kata-kata, dan kami akan membuka singkatan. Baca lebih lanjut di artikel tentang sintesis . Ini adalah tugas yang sulit, jadi misalkan kita sudah memproses teks (sudah diproses dalam database di atas).
Pertanyaan selanjutnya yang akan ditanyakan adalah apakah akan menggunakan rekaman grapheme atau fonem. Untuk suara monofonik dan monolingual, model huruf juga cocok. Jika Anda ingin bekerja dengan model multibahasa multi-suara, maka saya menyarankan Anda untuk menggunakan transkripsi (Google juga ).
G2p
Untuk bahasa Rusia, ada implementasi yang disebut russian_g2p . Ini dibangun di atas aturan bahasa Rusia dan berupaya dengan baik dengan tugas, tetapi memiliki kelemahan. Tidak semua kata menekankan, dan juga tidak cocok untuk model multibahasa. Oleh karena itu, ambil kamus yang dibuat untuknya, tambahkan kamus untuk bahasa Inggris dan beri makan jaringan saraf (misalnya, 1 , 2 )
Sebelum Anda melatih jaringan, ada baiknya mempertimbangkan suara apa dari berbagai bahasa terdengar serupa, dan Anda dapat memilih satu karakter untuk mereka, dan yang tidak mungkin dilakukan. Semakin banyak suara, semakin sulit model untuk belajar, dan jika ada terlalu sedikit, maka model tersebut akan memiliki aksen. Ingatlah untuk menekankan karakter individu dengan vokal yang ditekankan. Untuk bahasa Inggris, stres sekunder memainkan peran kecil, dan saya tidak akan membedakannya.
Pengodean Speaker
Jaringan ini mirip dengan tugas mengidentifikasi pengguna dengan suara. Pada output, pengguna yang berbeda mendapatkan vektor yang berbeda dengan angka. Saya sarankan menggunakan implementasi CorentinJ itu sendiri, yang didasarkan pada artikel . Model ini adalah LSTM tiga lapis dengan 768 node, diikuti oleh lapisan 256 neuron yang terhubung penuh, memberikan vektor 256 angka.
Pengalaman menunjukkan bahwa jaringan yang terlatih dalam bahasa Inggris berbicara baik dengan bahasa Rusia. Ini sangat menyederhanakan hidup, karena pelatihan membutuhkan banyak data. Saya merekomendasikan mengambil model yang sudah terlatih dan pelatihan ulang dalam bahasa Inggris dari VoxCeleb dan LibriSpeech, serta semua pidato Rusia yang Anda temukan. Encoder tidak memerlukan anotasi teks dari fragmen ucapan.
Pelatihan
- Jalankan
python encoder_preprocess.py <datasets_root> untuk memproses data - Jalankan "visdom" di terminal terpisah.
- Jalankan
python encoder_train.py my_run <datasets_root> untuk melatih encoder
Sintesis
Mari beralih ke sintesis. Model yang saya tahu tidak mendapatkan suara langsung dari teks, karena sulit (terlalu banyak data). Pertama, teks menghasilkan suara dalam bentuk spektral, dan hanya kemudian jaringan keempat akan diterjemahkan menjadi suara yang akrab. Karena itu, pertama-tama kita memahami bagaimana bentuk spektral dikaitkan dengan suara. Lebih mudah untuk mencari tahu masalah terbalik tentang cara mendapatkan spektrogram dari suara.
Suara dibagi menjadi segmen 25 ms dengan penambahan 10 ms (default di sebagian besar model). Kemudian, menggunakan transformasi Fourier untuk setiap bagian, spektrum dihitung (osilasi harmonik, jumlah yang memberikan sinyal asli) dan disajikan dalam bentuk grafik, di mana strip vertikal adalah spektrum dari satu segmen (dalam frekuensi), dan dalam horizontal - urutan segmen (dalam waktu). Grafik ini disebut spektrogram. Jika frekuensi dikodekan secara nonlinier (frekuensi yang lebih rendah lebih baik daripada yang di atas), maka skala vertikal akan berubah (diperlukan untuk mengurangi data), maka grafik ini disebut spektogram Mel. Beginilah cara kerja pendengaran manusia, bahwa kita mendengar sedikit penyimpangan pada frekuensi yang lebih rendah daripada pada yang lebih tinggi, oleh karena itu kualitas suaranya tidak akan berkurang.
Ada beberapa implementasi sintesis spektrogram yang baik seperti Tacotron 2 dan Deepvoice 3 . Masing-masing model memiliki implementasi sendiri, misalnya 1 , 2 , 3 , 4 . Kami akan menggunakan (seperti CorentinJ) model Tacotron dari Rayhane-mamah.
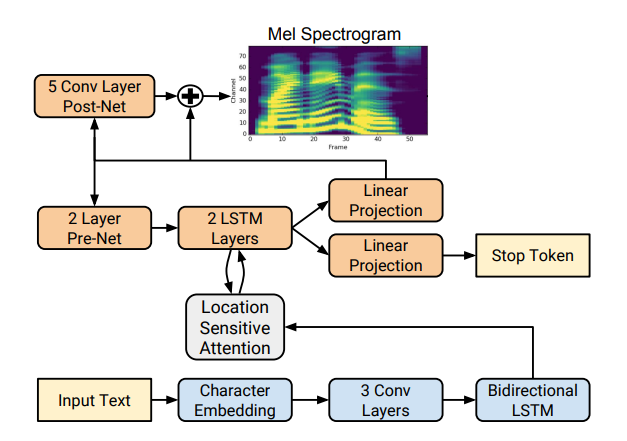
Tacotron didasarkan pada jaringan seq2seq dengan mekanisme perhatian. Baca detailnya di artikel .
Pelatihan
Jangan lupa untuk mengedit utils / symbols.py jika Anda mensintesis tidak hanya bahasa Inggris, hparams.p, tetapi juga preprocess.py.
Sintesis membutuhkan banyak suara yang bersih dan ditandai dengan baik dari speaker yang berbeda. Di sini bahasa asing tidak akan membantu.
- Jalankan
python synthesizer_preprocess_audio.py <datasets_root> untuk membuat suara dan spektogram yang diproses - Jalankan
python synthesizer_preprocess_embeds.py <datasets_root> untuk menyandikan suara (dapatkan tanda-tanda suara) - Jalankan
python synthesizer_train.py my_run <datasets_root> untuk melatih synthesizer
Vocoder
Sekarang tinggal mengubah konversi spektogram menjadi suara. Untuk ini, jaringan terakhir adalah vocoder. Muncul pertanyaan, jika spektogram diperoleh dari suara menggunakan transformasi Fourier, apakah mungkin untuk mendapatkan suara lagi menggunakan transformasi terbalik? Jawabannya adalah ya dan tidak. Osilasi harmonik yang membentuk sinyal asli mengandung amplitudo dan fase, dan spektogram kami hanya berisi informasi tentang amplitudo (demi mengurangi parameter dan bekerja dengan spektrogram), jadi jika kita melakukan invers Fourier transform, kita mendapatkan suara yang buruk.
Untuk mengatasi masalah ini, mereka menemukan algoritma Griffin-Lim yang cepat. Dia melakukan transformasi Fourier terbalik dari spektogram, mendapatkan suara "buruk". Kemudian ia membuat konversi langsung dari suara ini dan menerima spektrum yang sudah berisi sedikit informasi tentang fase, dan amplitudo tidak berubah dalam proses. Selanjutnya, transformasi terbalik diambil lagi dan suara yang lebih bersih diperoleh. Sayangnya, kualitas bicara yang dihasilkan oleh algoritma seperti itu menyisakan banyak yang diinginkan.
Itu digantikan oleh neural vocoder seperti WaveNet , WaveRNN , WaveGlow dan lainnya. CorentinJ menggunakan model WaveRNN oleh fatchord

Untuk preprocessing data, dua pendekatan digunakan. Entah mendapatkan spektogram dari suara (menggunakan transformasi Fourier), atau dari teks (menggunakan model sintesis). Google merekomendasikan pendekatan kedua.
Pelatihan
- Jalankan
python vocoder_preprocess.py <datasets_root> untuk mensintesis spektrogram - Jalankan
python vocoder_train.py <datasets_root> untuk vocoder
Total
Kami mendapat model sintesis bicara multibahasa yang dapat mengkloning suara.
Jalankan toolbox: python demo_toolbox.py -d <datasets_root>
Contohnya bisa didengar di sini
Kiat dan kesimpulan
- Perlu banyak data (> 1000 suara,> 1000 jam)
- Kecepatan operasi sebanding dengan waktu nyata hanya dalam sintesis setidaknya 4 kalimat
- Untuk pembuat enkode, gunakan model pra-terlatih untuk bahasa Inggris, sedikit pelatihan ulang. Dia baik-baik saja
- Sebuah synthesizer yang dilatih tentang data "bersih" berfungsi lebih baik, tetapi klon lebih buruk daripada yang dilatih pada volume yang lebih besar, tetapi data kotor
- Model ini hanya berfungsi dengan baik pada data yang saya pelajari
Anda dapat mensintesis suara Anda secara online menggunakan colab , atau lihat implementasi saya di github dan unduh bobot saya.