
Salah satu sumber daya paling berharga dari jejaring sosial mana pun adalah "grafik pertemanan" - informasi disebarluaskan melalui koneksi di kolom ini, konten menarik dikirimkan kepada pengguna, dan umpan balik yang konstruktif dikirim ke penulis konten. Pada saat yang sama, grafik juga merupakan sumber informasi penting yang memungkinkan Anda untuk lebih memahami pengguna dan terus meningkatkan layanan. Namun, dalam kasus-kasus ketika grafik tumbuh, secara teknis semakin sulit untuk mengambil informasi darinya. Pada artikel ini kita akan berbicara tentang beberapa trik yang digunakan untuk memproses grafik besar di OK.ru.
Untuk memulai, pertimbangkan tugas sederhana dari dunia nyata: tentukan usia pengguna. Mengetahui usia memungkinkan jaringan sosial untuk memilih konten yang lebih relevan dan lebih baik beradaptasi dengan orang tersebut. Tampaknya usia sudah diindikasikan saat membuat halaman di jejaring sosial, tetapi pada kenyataannya, cukup sering, pengguna licik dan menunjukkan usia yang berbeda dari yang asli. Grafik sosial dapat membantu memperbaiki situasi :).
Ambil contoh, Bob (semua karakter dalam artikel adalah fiksi, setiap kebetulan dengan kenyataan adalah hasil dari kreativitas rumah acak):

Di satu sisi, setengah dari teman Bob adalah remaja, menunjukkan bahwa Bob juga remaja. Tetapi dia juga memiliki teman-teman yang lebih tua, jadi kepercayaan terhadap jawabannya rendah. Informasi tambahan dari grafik sosial dapat membantu menjelaskan jawabannya:

Menambah pertimbangan tidak hanya busur di mana Bob terlibat langsung, tetapi juga busur di antara teman-temannya, kita dapat melihat bahwa Bob adalah bagian dari komunitas remaja yang padat, yang memungkinkan kita untuk membuat kesimpulan tentang usianya dengan tingkat kepercayaan yang lebih besar.
Struktur data seperti itu dikenal sebagai jaringan ego atau subgraf ego; telah digunakan sejak lama dan berhasil digunakan dalam memecahkan banyak masalah: mencari komunitas, mengidentifikasi bot dan spam, merekomendasikan teman dan konten, dll. Namun, perhitungan ego dari subgraph untuk semua pengguna dalam grafik dengan ratusan juta node dan puluhan miliar busur penuh dengan sejumlah "kesulitan teknis kecil" :).
Masalah utama adalah ketika mempertimbangkan informasi tentang "langkah kedua" dalam grafik, ledakan kuadrat dari jumlah koneksi terjadi. Misalnya, untuk pengguna dengan 150 tautan ego langsung, sebuah subgraf dapat mencakup hingga 150+150∗149/2=$11.32 tautan, dan untuk pengguna aktif dengan 5.000 teman, subgraf ego dapat tumbuh hingga lebih dari 12.000.000 tautan.
Komplikasi tambahan adalah kenyataan bahwa grafik disimpan dalam lingkungan terdistribusi, dan tidak ada simpul yang memiliki gambar lengkap grafik dalam memori. Pengerjaan partisi graph seimbang dilakukan baik di akademi dan di industri, tetapi bahkan hasil paling top ketika mengumpulkan ego subgraf mengarah ke komunikasi "semua dengan semua": untuk mendapatkan informasi tentang teman-teman teman pengguna, Anda harus pergi ke semua "partisi" dalam banyak kasus.
Salah satu alternatif yang berfungsi dalam hal ini adalah duplikasi data paksa (misalnya, algoritma 3 dalam artikel dari Google ), tetapi duplikasi ini juga tidak gratis. Mari kita coba mencari tahu apa yang bisa diperbaiki dalam proses ini.
Algoritma naif
Untuk memulai, pertimbangkan algoritma "naif" untuk membuat subgraf ego:

Algoritme mengasumsikan bahwa grafik asli disimpan sebagai daftar adjacency, mis. Informasi tentang semua teman pengguna disimpan dalam satu catatan dengan ID pengguna di kunci dan daftar ID teman di nilai. Untuk mengambil langkah kedua dan mendapatkan informasi tentang teman yang Anda butuhkan:
- Konversi grafik ke daftar tepi, di mana setiap tepi adalah entri yang terpisah.
- Buat daftar tepi bergabung dengan dirinya sendiri, yang akan memberikan semua jalur dalam grafik panjang 2.
- Kelompokkan dengan memulai jalur.
Pada output untuk setiap pengguna, kami mendapatkan daftar jalur dengan panjang 2 untuk setiap pengguna. Perlu dicatat di sini bahwa struktur yang dihasilkan sebenarnya adalah lingkungan dua langkah dari pengguna , sedangkan subgraf ego adalah bagiannya. Oleh karena itu, untuk menyelesaikan prosesnya, kita perlu memfilter semua busur yang keluar dari teman dekat.
Algoritma ini bagus karena diimplementasikan dalam dua baris pada Scala di bawah Apache Spark . Tetapi keuntungannya berakhir di sana: untuk grafik ukuran industri, volume komunikasi jaringan di luar batas dan waktu operasi diukur dalam beberapa hari. Kesulitan utama dibuat oleh dua operasi acak yang terjadi ketika kita bergabung dan mengelompokkan. Apakah mungkin untuk mengurangi jumlah data yang dikirim?
Ego subgraph dalam satu acak
Mengingat grafik persahabatan kami simetris, Anda dapat menggunakan pengoptimalan yang diusulkan oleh Tomas Schank :
- Anda bisa mendapatkan semua jalur dengan panjang 2 tanpa bergabung - jika Bob memiliki teman Alice dan Harry, maka ada jalur Alice-Bob-Harry dan Harry-Bob-Alice.
- Saat pengelompokan, dua jalur di pintu masuk sesuai dengan tepi baru yang sama. Jalur Bob-Alice-Dave dan Bob-Dave-Alice berisi informasi yang sama untuk Bob, yang berarti Anda hanya dapat mengirim setiap jalur kedua, menyortir pengguna berdasarkan ID mereka.
Setelah menerapkan optimasi, skema kerja akan terlihat seperti ini:

- Pada tahap generasi pertama, kami mendapatkan daftar jalur panjang 2 dengan filter ID pesanan.
- Pada hari kedua, kami mengelompokkan berdasarkan pengguna pertama di jalan.
Dalam pengaturan ini, algoritma memenuhi satu operasi acak, dan ukuran data yang dikirim melalui jaringan menjadi setengahnya. :)
Susun subgraf ego dalam ingatan
Masalah penting yang belum kita pertimbangkan adalah bagaimana menguraikan data dalam ego subgraph ke dalam memori. Untuk menyimpan grafik secara keseluruhan, kami menggunakan daftar adjacency. Struktur ini nyaman untuk tugas-tugas di mana perlu untuk melalui grafik yang telah selesai secara keseluruhan, tetapi itu mahal jika kita ingin membuat grafik dari potongan-potongan dan melakukan analisis yang lebih halus. Struktur ideal untuk tugas kita harus secara efektif melakukan operasi berikut:
- Penyatuan dua grafik diperoleh dari partisi yang berbeda.
- Mendapatkan semua teman manusia.
- Memeriksa apakah dua orang terhubung.
- Penyimpanan dalam memori tanpa tinju overhead.
Salah satu format yang paling cocok untuk persyaratan ini adalah analog dari matriks CSR yang jarang :
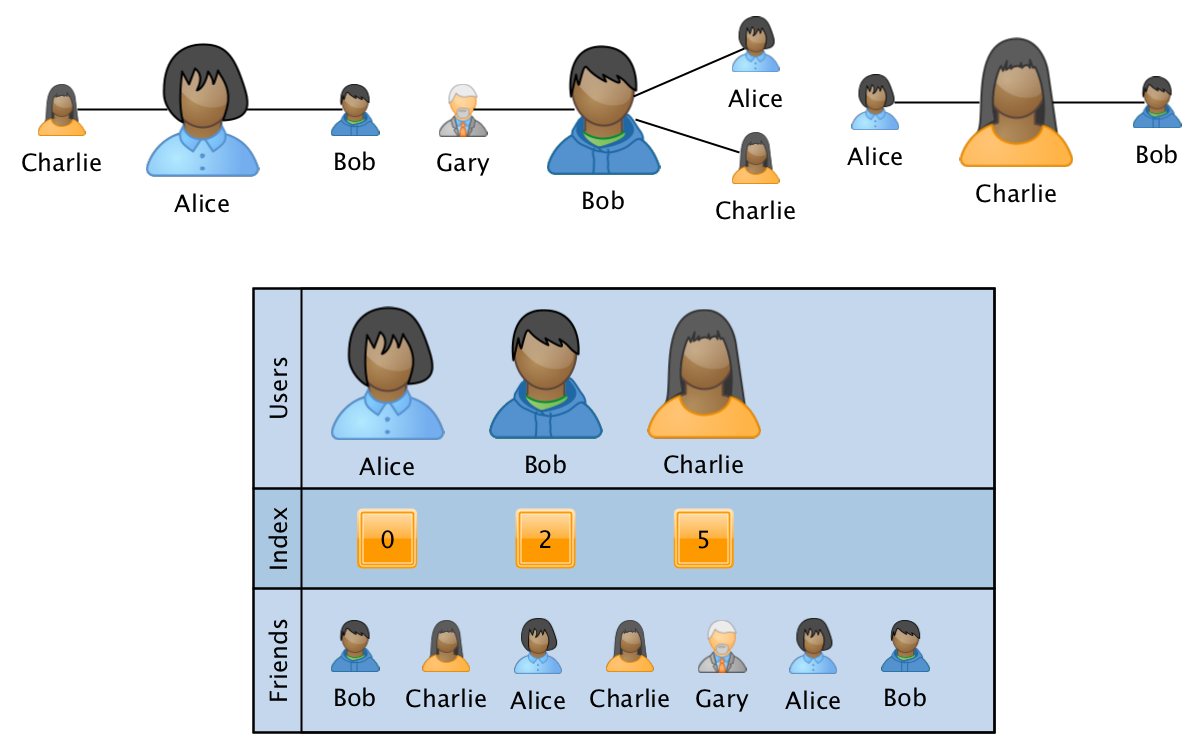
Grafik dalam hal ini disimpan dalam bentuk tiga array:
- pengguna - array yang diurutkan dengan ID dari semua pengguna yang berpartisipasi dalam grafik.
- index - array dengan ukuran yang sama dengan pengguna, di mana untuk setiap pengguna disimpan sebuah pointer-indeks ke awal informasi tentang hubungan pengguna dalam array ketiga.
- teman - array ukuran sama dengan jumlah tepi dalam grafik, di mana ID pengguna terkait ditampilkan secara berurutan untuk ID yang sesuai dari pengguna. Array diurutkan untuk kecepatan pemrosesan dalam informasi tentang tautan dari satu pengguna.
Dalam format ini, operasi penggabungan dua grafik dilakukan dalam waktu linier, dan operasi memperoleh informasi tentang pengguna tertentu atau pada sepasang pengguna per logaritma dari jumlah simpul. Dalam hal ini, overhead dalam memori tidak tergantung pada ukuran grafik, karena jumlah array yang tetap digunakan. Dengan menambahkan susunan data keempat dengan ukuran yang sama dengan ukuran teman, Anda dapat menyimpan informasi tambahan yang terkait dengan hubungan dalam grafik.
Menggunakan properti grafik simetri, Anda dapat menyimpan hanya setengah dari busur "segitiga atas" (ketika busur disimpan hanya dari ID yang lebih kecil ke yang lebih besar), tetapi dalam kasus ini, rekonstruksi semua koneksi pengguna tunggal akan memakan waktu linier. Kompromi yang baik dalam hal ini mungkin merupakan pendekatan yang menggunakan pengkodean "segitiga atas" untuk penyimpanan dan transfer antar node, dan pengkodean simetris saat memuat ego subgraph ke dalam memori untuk dianalisis.
Kurangi shuffle
Namun, bahkan setelah menerapkan semua optimasi yang disebutkan di atas, tugas membangun semua subgraf ego masih bekerja terlalu lama. Dalam kasus kami, sekitar 6 jam dengan pemanfaatan cluster yang tinggi. Pandangan yang lebih dekat menunjukkan bahwa sumber utama kerumitan masih operasi acak, sementara bagian penting dari data yang terlibat dalam acak tersebut dilempar keluar pada tahapan berikut. Faktanya adalah bahwa pendekatan yang dijelaskan membangun lingkungan dua langkah lengkap untuk setiap pengguna, sedangkan subgraf ego hanya sebagian kecil dari lingkungan ini yang hanya mengandung busur internal .
Misalnya, jika, dengan memproses tetangga langsung Bob - Harry dan Frank - kami tahu bahwa mereka bukan teman satu sama lain, maka sudah pada langkah pertama kami bisa menyaring jalur eksternal seperti itu. Tetapi untuk mengetahui bagi semua Gary dan Frenkov apakah mereka teman, Anda harus menyeret grafik persahabatan ke memori di semua node komputasi atau membuat panggilan jarak jauh saat memproses setiap catatan, yang, sesuai dengan kondisi tugas, tidak mungkin.
Namun demikian, ada solusi jika kita membiarkan diri kita, dalam persentase kecil kasus, untuk membuat kesalahan ketika kita menemukan persahabatan di mana sebenarnya tidak ada. Ada seluruh keluarga struktur data probabilistik yang memungkinkan untuk mengurangi konsumsi memori selama penyimpanan data dengan perintah besarnya, sambil memungkinkan sejumlah kesalahan. Struktur yang paling terkenal dari jenis ini adalah filter Bloom , yang selama bertahun-tahun telah berhasil digunakan dalam database industri untuk mengkompensasi kesalahan dalam cache "ekor panjang".
Tugas utama filter Bloom adalah menjawab pertanyaan "apakah elemen ini termasuk dalam banyak elemen yang sebelumnya terlihat?" Selain itu, jika filter menjawab "tidak", maka elemen tersebut mungkin tidak termasuk dalam set, tetapi jika itu menjawab "ya" - ada kemungkinan kecil bahwa elemen tersebut masih tidak ada.
Dalam kasus kami, "elemen" akan menjadi pasangan pengguna, dan "set" akan menjadi semua sisi grafik. Kemudian filter Bloom dapat berhasil diterapkan untuk mengurangi ukuran shuffle:

Setelah menyiapkan filter Bloom terlebih dahulu dengan informasi tentang grafik, kita dapat melihat melalui teman-teman Harry untuk mengetahui bahwa Bob dan Ilona bukan teman, yang berarti bahwa kita tidak perlu mengirim informasi Bob tentang koneksi antara Gary dan Ilona. Namun, informasi bahwa Harry dan Bob adalah teman mereka sendiri masih harus dikirim sehingga Bob dapat sepenuhnya mengembalikan grafik persahabatannya setelah pengelompokan.
Hapus acak
Setelah menerapkan filter, jumlah data yang dikirim berkurang sekitar 80%, dan tugas selesai dalam 1 jam dengan beban gugusan sedang, memungkinkan Anda untuk dengan bebas melakukan tugas-tugas lain secara paralel. Dalam mode ini, itu sudah bisa diambil "ke dalam operasi" dan diletakkan setiap hari, tetapi masih ada potensi untuk optimasi.
Paradoksikal kedengarannya, masalah dapat diselesaikan tanpa menggunakan shuffle, jika Anda membiarkan diri Anda persentase kesalahan tertentu. Dan filter Bloom dapat membantu kami dengan ini:

Jika melihat melalui daftar teman Bob menggunakan filter, kami mengetahui bahwa Alice dan Charlie hampir pasti adalah teman, kami dapat segera menambahkan busur yang sesuai ke subgraf ego Bob. Seluruh proses dalam kasus ini akan memakan waktu kurang dari 15 menit dan tidak akan memerlukan transfer data melalui jaringan, namun, persentase tertentu dari busur, tergantung pada pengaturan filter, mungkin tidak ada dalam kenyataan.
Busur tambahan yang ditambahkan oleh filter tidak menimbulkan distorsi yang signifikan untuk beberapa tugas: misalnya, ketika menghitung segitiga, kita dapat dengan mudah memperbaiki hasilnya, dan ketika menyiapkan atribut untuk algoritma pembelajaran mesin, koreksi ML itu sendiri dapat dipelajari pada langkah berikutnya.
Tetapi dalam beberapa tugas, busur tambahan menyebabkan kerusakan fatal dalam kualitas hasil: misalnya, ketika mencari komponen yang terhubung dalam subgraph ego dengan ego jarak jauh (tanpa titik sudut pengguna), kemungkinan "jembatan hantu" antara komponen tumbuh secara kuadrat relatif terhadap ukurannya, yang mengarah ke bahwa hampir di mana-mana kita mendapatkan satu komponen besar.
Ada area perantara di mana efek negatif dari busur tambahan perlu dievaluasi secara eksperimental: misalnya, beberapa algoritma pencarian komunitas dapat berhasil mengatasi sedikit kebisingan, mengembalikan struktur komunitas yang hampir identik.
Alih-alih sebuah kesimpulan
Subgraf pengguna Ego adalah sumber informasi penting yang secara aktif digunakan dalam OK untuk meningkatkan kualitas rekomendasi, memperbaiki demografi, dan memerangi spam, tetapi perhitungan mereka penuh dengan sejumlah kesulitan.
Dalam artikel tersebut, kami memeriksa evolusi pendekatan untuk tugas membangun subgraf ego untuk semua pengguna jejaring sosial dan mampu meningkatkan waktu kerja dari 20 jam awal hingga 1 jam, dan dalam kasus persentase kesalahan yang kecil, hingga 10-15 menit.
Tiga "pilar" yang menjadi dasar keputusan akhir adalah:
- Menggunakan properti grafik simetri dan algoritma Tomas Schank .
- Secara efisien menyimpan subgraf ego menggunakan matriks CSR yang jarang .
- Gunakan filter Bloom untuk mengurangi transfer data melalui jaringan.
Contoh bagaimana kode algoritma telah berevolusi dapat ditemukan di notebook Zeppelin .