Hai semuanya, beberapa informasi "dari bawah tenda" adalah tanggal lokakarya teknik Alfastrakhovaniya - yang menggairahkan pikiran teknis kami.

Apache Spark adalah alat luar biasa yang memungkinkan Anda dengan cepat dan mudah memproses data dalam jumlah besar pada sumber daya komputasi yang cukup sederhana (maksud saya pemrosesan kluster).
Secara tradisional, notebook jupyter digunakan dalam pemrosesan data ad hoc. Dalam kombinasi dengan Spark, ini memungkinkan kita untuk memanipulasi frame data berumur panjang (Spark berurusan dengan alokasi sumber daya, frame data tinggal di suatu tempat di cluster, masa hidup mereka dibatasi oleh masa hidup konteks Spark).
Setelah mentransfer pemrosesan data ke Apache Airflow, masa pakai frame sangat berkurang - konteks Spark "hidup" dalam pernyataan Airflow yang sama. Bagaimana menyiasati ini, mengapa berkeliling dan apa yang harus dilakukan Livy dengan itu - baca di bawah potongan.
Mari kita lihat contoh yang sangat, sangat sederhana: misalkan kita perlu mendenormalisasi data dalam tabel besar dan menyimpan hasilnya dalam tabel lain untuk diproses lebih lanjut (elemen khas dari pipa pemrosesan data).
Bagaimana kita melakukan ini:
- memuat data ke dalam kerangka data (pemilihan dari tabel besar dan direktori)
- melihat dengan "mata" pada hasilnya (apakah itu bekerja dengan benar)
- dataframe disimpan ke tabel Hive (misalnya)
Berdasarkan hasil analisis, kita mungkin perlu memasukkan pada langkah kedua beberapa pemrosesan spesifik (penggantian kamus atau yang lain). Dalam hal logika, kami memiliki tiga langkah
- langkah 1: unduh
- langkah 2: pemrosesan
- langkah 3: simpan
Di jupyter notebook, ini adalah bagaimana kami melakukannya - kami dapat memproses data yang diunduh untuk waktu yang lama, memberikan kontrol sumber daya Spark.
Adalah logis untuk mengharapkan bahwa partisi seperti itu dapat ditransfer ke Airflow. Artinya, memiliki grafik semacam ini

Sayangnya, ini tidak mungkin ketika menggunakan kombinasi Airflow + Spark: setiap pernyataan Airflow dieksekusi dalam interpreter python, oleh karena itu, di antara hal-hal lain, setiap pernyataan harus entah bagaimana "bertahan" hasil dari kegiatannya. Dengan demikian, pemrosesan kami "dikompresi" dalam satu langkah - "mendenormalkan data".
Bagaimana fleksibilitas jupyter notebook dapat dikembalikan ke Airflow? Jelas bahwa contoh di atas adalah "tidak layak" (mungkin, sebaliknya, ternyata langkah pemrosesan yang bisa dimengerti baik). Tapi tetap - bagaimana membuat pernyataan Airflow dieksekusi dalam konteks Spark yang sama pada ruang dataframe umum?
Selamat datang Livy
Produk ekosistem Hadoop lain datang untuk menyelamatkan - Apache Livy.
Saya tidak akan mencoba menggambarkan di sini "binatang" macam apa itu. Jika sangat singkat dan hitam dan putih - Livy memungkinkan Anda untuk "menyuntikkan" kode python ke program yang dijalankan oleh driver:
- pertama kita buat sesi Livy
- setelah itu kita memiliki kemampuan untuk mengeksekusi kode python sewenang-wenang dalam sesi ini (sangat mirip dengan ideologi jupyter / ipython)
Dan untuk semua ini ada REST API.
Kembali ke tugas sederhana kita: dengan Livy kita dapat menyimpan logika asli dari denasionalisasi kita
- pada langkah pertama (pernyataan pertama dari grafik kami) kami akan memuat dan mengeksekusi kode pemuatan data dalam kerangka data
- pada langkah kedua (pernyataan kedua) - jalankan kode untuk pemrosesan tambahan yang diperlukan dari kerangka data ini
- pada langkah ketiga - kode untuk menyimpan dataframe ke tabel
Seperti apa aliran udara yang terlihat seperti ini:
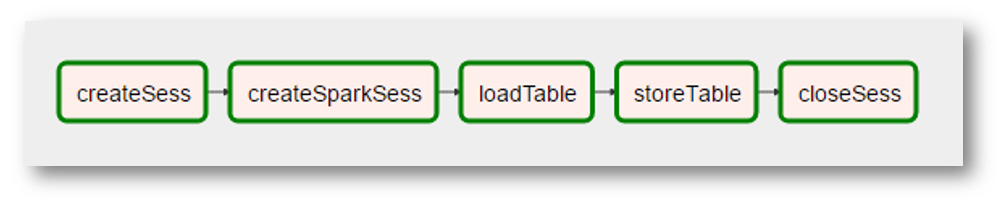
(karena gambar tersebut adalah tangkapan layar yang sangat nyata, ditambahkan "realitas" tambahan - menciptakan konteks Spark menjadi operasi terpisah dengan nama yang aneh, "pemrosesan" data menghilang karena tidak diperlukan, dll.)
Untuk meringkas, kita dapatkan
- pernyataan aliran udara universal yang mengeksekusi kode python dalam sesi Livy
- kemampuan untuk "mengatur" kode python ke dalam grafik yang cukup kompleks (Aliran udara untuk itu)
- kemampuan untuk mengatasi optimasi tingkat yang lebih tinggi, misalnya, dalam urutan mana kita perlu melakukan transformasi sehingga Spark dapat menyimpan data umum dalam memori cluster selama
Sebuah pipa khusus untuk menyiapkan data untuk pemodelan berisi sekitar 25 pertanyaan lebih dari 10 tabel, jelas bahwa beberapa tabel digunakan lebih sering daripada yang lain (sangat "data umum") dan ada sesuatu untuk dioptimalkan.
Apa selanjutnya
Kemampuan teknis telah diuji, kami berpikir lebih jauh - bagaimana menerjemahkan transformasi kami ke dalam paradigma ini secara lebih teknologi. Dan bagaimana cara mendekati optimasi yang disebutkan di atas. Kami masih berada di awal bagian dari perjalanan kami - ketika ada sesuatu yang menarik, kami pasti akan membagikannya.