
Pada tahun 2017, kami memenangkan persaingan untuk pengembangan inti transaksi bisnis investasi Bank Alfa dan mulai bekerja (di HighLoad ++ 2018
, Vladimir Drynkin, Kepala Inti Transaksional Bisnis Investasi Bank Alfa, menyajikan laporan tentang inti bisnis investasi). Sistem ini untuk mengumpulkan data transaksi dari berbagai sumber dalam berbagai format, membawa data ke bentuk terpadu, menyimpannya dan menyediakan akses ke sana.
Dalam proses pengembangan, sistem berevolusi dan menjadi fungsional, dan pada titik tertentu kami menyadari bahwa kami mengkristalkan sesuatu yang lebih dari sekadar perangkat lunak aplikasi yang dirancang untuk memecahkan berbagai tugas yang didefinisikan dengan ketat: kami mendapat
sistem untuk membangun aplikasi terdistribusi dengan penyimpanan persisten . Pengalaman kami membentuk dasar dari produk baru -
Tarantool Data Grid (TDG).
Saya ingin berbicara tentang arsitektur TDG dan solusi yang kami buat selama proses pengembangan, memperkenalkan Anda dengan fungsi dasar dan menunjukkan bagaimana produk kami dapat menjadi dasar untuk membangun solusi lengkap.
Secara arsitektur, kami membagi sistem menjadi
peran yang terpisah, yang masing-masing bertanggung jawab untuk menyelesaikan serangkaian tugas tertentu. Satu instance menjalankan aplikasi mengimplementasikan satu atau lebih tipe peran. Cluster dapat memiliki beberapa peran dengan tipe yang sama:
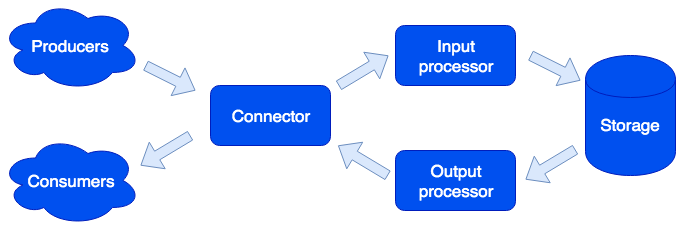
Konektor
Connector bertanggung jawab untuk komunikasi dengan dunia luar; tugasnya adalah menerima permintaan, menguraikannya, dan jika itu berhasil, kemudian mengirim data untuk diproses ke prosesor input. Kami mendukung format HTTP, SOAP, Kafka, FIX. Arsitektur memungkinkan Anda untuk hanya menambahkan dukungan untuk format baru, dukungan IBM MQ segera hadir. Jika parsing permintaan gagal, konektor akan mengembalikan kesalahan; jika tidak, ia akan menjawab bahwa permintaan berhasil diproses, bahkan jika terjadi kesalahan selama proses selanjutnya. Ini dilakukan dengan sengaja, agar dapat bekerja dengan sistem yang tidak tahu cara mengulangi permintaan - atau sebaliknya, melakukannya terlalu agresif. Agar tidak kehilangan data, antrian perbaikan digunakan: objek pertama kali memasukkannya dan hanya setelah pemrosesan berhasil dihapus dari itu. Administrator dapat menerima pemberitahuan tentang objek yang tersisa dalam antrian perbaikan, dan setelah menghilangkan kesalahan perangkat lunak atau kegagalan perangkat keras, coba lagi.
Prosesor masukan
Prosesor input mengklasifikasikan data yang diterima berdasarkan karakteristik dan memanggil penangan yang sesuai. Handler adalah kode Lua yang berjalan di kotak pasir, sehingga tidak dapat memengaruhi fungsi sistem. Pada tahap ini, data dapat direduksi menjadi bentuk yang diinginkan, dan jika perlu, jalankan sejumlah tugas sewenang-wenang yang dapat mengimplementasikan logika yang diperlukan. Misalnya, dalam produk MDM (Master Data Management) yang dibangun di Tarantool Data Grid, saat menambahkan pengguna baru, kami menjalankan tugas terpisah agar tidak memperlambat pemrosesan permintaan. Kotak pasir mendukung permintaan untuk membaca, mengubah, dan menambahkan data, memungkinkan Anda untuk melakukan beberapa fungsi pada semua peran seperti penyimpanan dan mengagregasikan hasilnya (memetakan / mengurangi).
Penangan dapat dijelaskan dalam file:
sum.lua local x, y = unpack(...) return x + y
Dan kemudian, dinyatakan dalam konfigurasi:
functions: sum: { __file: sum.lua }
Kenapa Lua? Lua adalah bahasa yang sangat sederhana. Berdasarkan pengalaman kami, beberapa jam setelah bertemu dengannya, orang-orang mulai menulis kode yang memecahkan masalah mereka. Dan ini bukan hanya pengembang profesional, tetapi misalnya, analis. Selain itu, berkat kompiler jit, Lua sangat cepat.
Penyimpanan
Penyimpanan menyimpan data persisten. Sebelum menyimpan, data divalidasi untuk kepatuhan dengan skema data. Untuk menjelaskan skema, kami menggunakan format
Apache Avro yang diperluas. Contoh:
{ "name": "User", "type": "record", "logicalType": "Aggregate", "fields": [ { "name": "id", "type": "string"}, {"name": "first_name", "type": "string"}, {"name": "last_name", "type": "string"} ], "indexes": ["id"] }
Berdasarkan uraian ini, DDL (Data Definition Language) untuk Tarantula DBMS dan skema
GraphQL untuk akses data secara otomatis dihasilkan.
Replikasi data asinkron didukung (rencana untuk menambahkan sinkron).
Prosesor keluaran
Terkadang perlu untuk memberi tahu konsumen eksternal tentang kedatangan data baru, untuk ini ada peran prosesor Output. Setelah menyimpan data, mereka dapat ditransfer ke penangan yang sesuai (misalnya, untuk membawanya ke bentuk yang diminta konsumen) - dan kemudian ditransfer ke konektor untuk pengiriman. Antrian perbaikan juga digunakan di sini: jika tidak ada yang menerima objek, administrator dapat mencoba lagi nanti.
Scaling
Peran konektor, prosesor input, dan prosesor output tidak memiliki kewarganegaraan, yang memungkinkan kami untuk menskala sistem secara horizontal, cukup menambahkan instance aplikasi yang baru dengan memasukkan peran yang termasuk dalam tipe yang diinginkan. Untuk penskalaan penyimpanan horisontal,
pendekatan untuk organisasi kelompok menggunakan ember virtual digunakan. Setelah menambahkan server baru, bagian dari ember dari server lama di latar belakang pindah ke server baru; ini terjadi secara transparan kepada pengguna dan tidak mempengaruhi operasi seluruh sistem.
Properti Data
Objek bisa sangat besar dan berisi objek lain. Kami memastikan keaslian menambahkan dan memperbarui data, menyimpan objek dengan semua dependensi pada satu ember virtual. Ini menghilangkan "noda" objek di beberapa server fisik.
Versi didukung: setiap pembaruan objek membuat versi baru, dan kami selalu dapat membuat irisan waktu dan melihat bagaimana dunia terlihat saat itu. Untuk data yang tidak memerlukan riwayat panjang, kami dapat membatasi jumlah versi atau bahkan hanya menyimpan satu - yang terakhir - yaitu, sebenarnya menonaktifkan versi untuk jenis tertentu. Anda juga dapat membatasi riwayat berdasarkan waktu: misalnya, menghapus semua objek dari jenis tertentu yang lebih tua dari 1 tahun. Pengarsipan juga didukung: kita dapat membongkar objek yang lebih tua dari waktu yang ditentukan, membebaskan ruang di cluster.
Tugasnya
Dari fungsi-fungsi yang menarik, perlu dicatat kemampuan untuk menjalankan tugas sesuai jadwal, atas permintaan pengguna, atau secara terprogram dari kotak pasir:

Di sini kita melihat pelari peran lainnya. Peran ini tidak memiliki status, dan jika perlu, contoh aplikasi tambahan dengan peran ini dapat ditambahkan ke kluster. Tanggung jawab pelari adalah menyelesaikan tugas. Sebagaimana dinyatakan, pembuatan tugas baru dari kotak pasir dimungkinkan; mereka mengantri di penyimpanan dan kemudian dijalankan di pelari. Jenis tugas ini disebut Ayub. Kami juga memiliki jenis tugas yang disebut Tugas - ini adalah tugas yang ditentukan pengguna yang dijadwalkan untuk dijalankan (menggunakan sintaks cron) atau sesuai permintaan. Untuk menjalankan dan melacak tugas-tugas tersebut, kami memiliki pengelola tugas yang praktis. Agar fungsi ini tersedia, Anda harus mengaktifkan peran penjadwal; peran ini memiliki keadaan, oleh karena itu tidak skala, yang, bagaimanapun, tidak diperlukan; Namun, dia, seperti semua peran lain, mungkin memiliki replika yang mulai bekerja jika sang master tiba-tiba menolak.
Logger
Peran lain disebut logger. Itu mengumpulkan log dari semua anggota cluster dan menyediakan antarmuka untuk mengunggah dan melihatnya melalui antarmuka web.
Layanan
Perlu disebutkan bahwa sistem membuatnya mudah untuk membuat layanan. Dalam file konfigurasi, Anda dapat menentukan permintaan mana yang harus dikirim ke handler yang ditulis pengguna yang berjalan di kotak pasir. Dalam penangan ini, Anda dapat, misalnya, menjalankan beberapa jenis permintaan analitik dan mengembalikan hasilnya.
Layanan dijelaskan dalam file konfigurasi:
services: sum: doc: "adds two numbers" function: sum return_type: int args: x: int y: int
API GraphQL dihasilkan secara otomatis dan layanan menjadi tersedia untuk menelepon:
query { sum(x: 1, y: 2) }
Ini akan memanggil
sum handler, yang akan mengembalikan hasilnya:
3
Profil dan Metrik Permintaan
Untuk memahami sistem dan profil permintaan, kami menerapkan dukungan untuk protokol OpenTracing. Sistem dapat, sesuai permintaan, mengirim informasi ke alat yang mendukung protokol ini, misalnya, Zipkin, yang akan memungkinkan Anda untuk memahami bagaimana permintaan itu dijalankan:
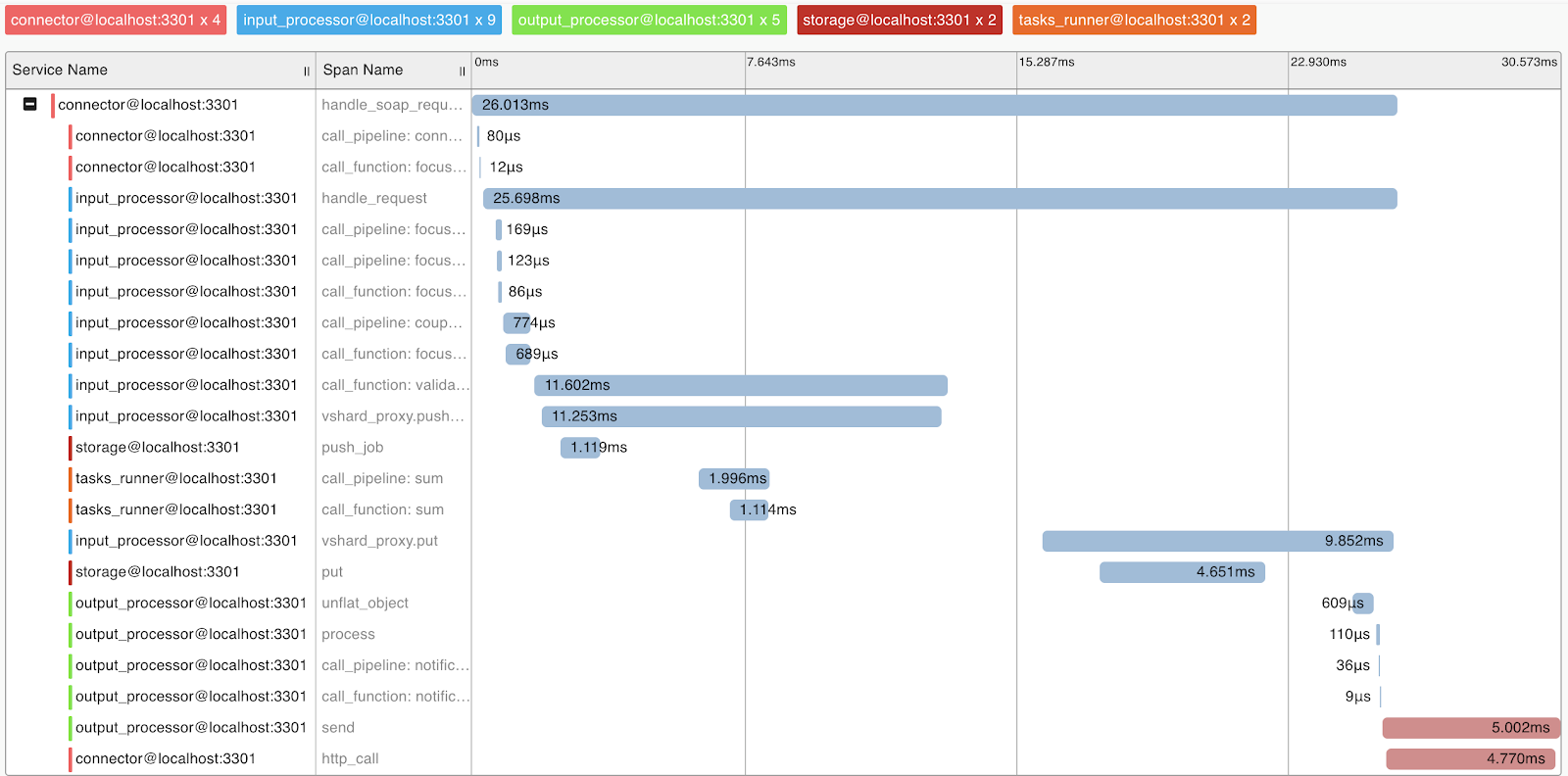
Secara alami, sistem ini menyediakan metrik internal yang dapat dikumpulkan menggunakan Prometheus dan divisualisasikan menggunakan Grafana.
Sebarkan
Tarantool Data Grid dapat digunakan dari paket atau arsip RPM, menggunakan utilitas dari pengiriman atau Ansible, ada juga dukungan untuk Kubernetes (
Operator Tarantool Kubernetes ).
Aplikasi yang mengimplementasikan logika bisnis (konfigurasi, prosesor) dimuat ke dalam cluster Tarantool Data Grid sebagai arsip melalui UI atau menggunakan skrip melalui API yang disediakan oleh kami.
Contoh aplikasi
Aplikasi apa yang dapat saya buat dengan Tarantool Data Grid? Bahkan, sebagian besar tugas bisnis entah bagaimana terkait dengan pemrosesan aliran data, menyimpan dan mengaksesnya. Karena itu, jika Anda memiliki aliran data yang besar yang perlu disimpan dengan aman dan memiliki akses ke sana, maka produk kami dapat menghemat banyak waktu dalam pengembangan dan fokus pada logika bisnis Anda.
Misalnya, kami ingin mengumpulkan informasi tentang pasar real estat untuk selanjutnya, misalnya, memiliki informasi tentang penawaran terbaik. Dalam hal ini, kami membedakan tugas-tugas berikut:
- Robot mengumpulkan informasi dari sumber terbuka - ini akan menjadi sumber data kami. Anda dapat memecahkan masalah ini menggunakan solusi yang sudah jadi atau dengan menulis kode dalam bahasa apa pun.
- Selanjutnya, Tarantool Data Grid akan menerima dan menyimpan data. Jika format data dari sumber yang berbeda berbeda, maka Anda dapat menulis kode dalam bahasa Lua, yang akan mengarah pada konversi ke format tunggal. Pada tahap pra-pemrosesan, Anda juga dapat, misalnya, memfilter penawaran berulang atau memperbarui informasi tentang agen yang beroperasi di pasar dalam database.
- Sekarang Anda sudah memiliki solusi terukur di kluster, yang dapat diisi dengan data dan membuat sampel data. Kemudian Anda dapat mengimplementasikan fungsionalitas baru, misalnya, menulis layanan yang akan meminta data dan mengeluarkan penawaran paling menguntungkan dalam sehari - ini akan memerlukan beberapa baris dalam file konfigurasi dan sedikit kode Lua.
Apa selanjutnya
Prioritas kami adalah meningkatkan kenyamanan pengembangan dengan
Tarantool Data Grid . Misalnya, ini adalah IDE dengan dukungan untuk profil dan debugging penangan kotak pasir.
Kami juga sangat memperhatikan masalah keamanan. Saat ini kami sedang melewati sertifikasi FSTEC Rusia untuk mengkonfirmasi tingkat keamanan yang tinggi dan memenuhi persyaratan untuk sertifikasi produk perangkat lunak yang digunakan dalam sistem informasi data pribadi dan sistem informasi negara.