Dalam arsitektur microservice besar atau, layanan yang paling penting tidak selalu yang paling produktif dan kadang-kadang tidak dimaksudkan untuk beban tinggi. Kita berbicara tentang backend. Ini bekerja lambat - kehilangan waktu pemrosesan data dan menunggu respons antara itu dan DBMS, dan tidak skala. Sekalipun aplikasi itu sendiri berskala mudah, hambatan ini tidak berskala sama sekali. Bagaimana mengatasi masalah ini dan memastikan kinerja tinggi? Bagaimana cara memberikan respons sistem ketika sumber-sumber informasi penting diam?

Jika arsitektur Anda sepenuhnya mematuhi manifes Reaktif, komponen skala aplikasi tanpa batas dengan meningkatnya beban secara independen satu sama lain, dan tahan terhadap jatuhnya simpul apa pun - Anda tahu jawabannya. Tetapi jika tidak, maka
Oleg Nizhnikov (
Odomontois ) akan memberi tahu bagaimana masalah skalabilitas diselesaikan di Tinkoff dengan membangun Cache Backback tanpa rasa sakit pada Scala tanpa menulis ulang aplikasi.
Catatan Artikel ini akan memiliki minimal kode Scala dan maksimum prinsip dan gagasan umum.Backend tidak stabil atau lambat
Saat berinteraksi dengan backend, aplikasi rata-rata cepat. Tetapi backend melakukan sebagian besar pekerjaan dan mengerjakan sebagian besar data secara internal - dibutuhkan lebih banyak waktu. Waktu ekstra terbuang sia-sia untuk menunggu backend dan respons DBMS. Sekalipun aplikasi itu sendiri berskala mudah, hambatan ini tidak berskala sama sekali. Bagaimana cara meringankan beban di backend dan memecahkan masalah?
Tembolok yang disematkan
Gagasan pertama adalah mengambil data untuk dibaca, meminta yang menerima data, dan mengonfigurasi cache pada level setiap node dalam memori.
Cache hidup sampai node me-restart dan menyimpan hanya potongan data terakhir. Jika aplikasi macet dan pengguna baru yang belum berada di jam terakhir, hari, atau minggu masuk, aplikasi tidak dapat berbuat apa-apa.
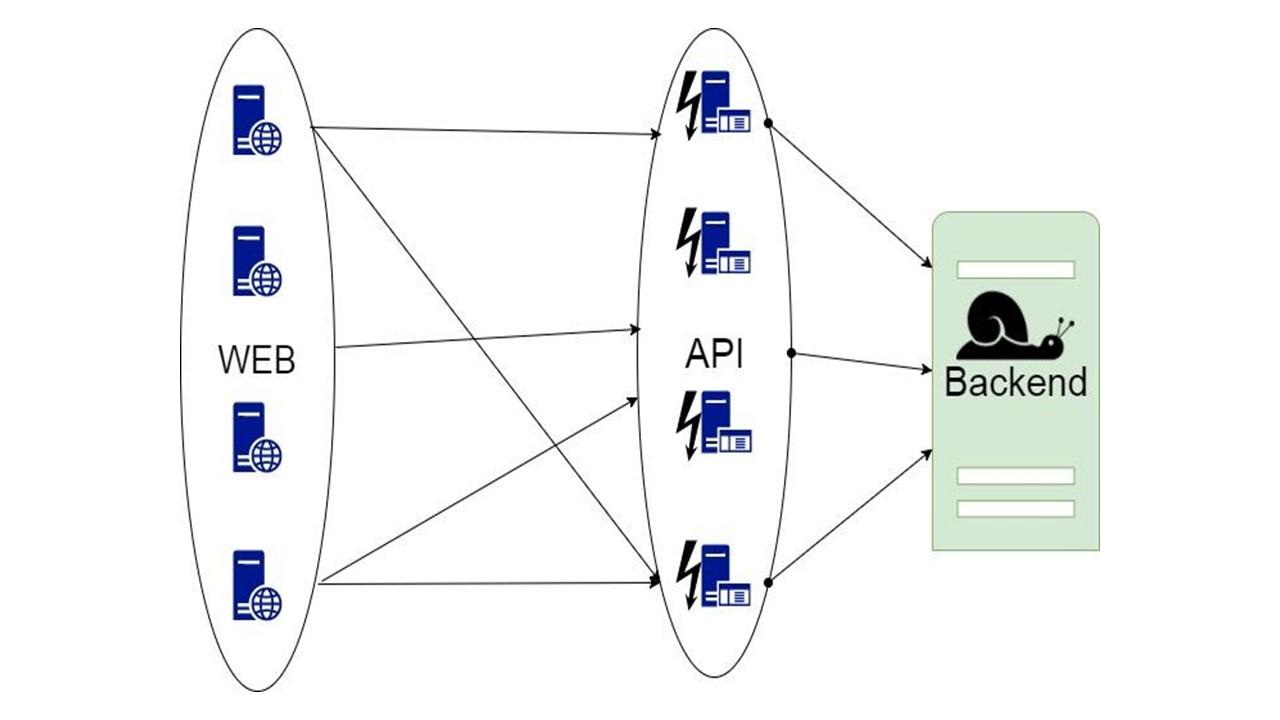
Proksi
Opsi kedua adalah proxy, yang mengambil alih sebagian dari permintaan atau memodifikasi aplikasi.
Tetapi dalam proxy, Anda tidak dapat melakukan semua pekerjaan untuk aplikasi itu sendiri.
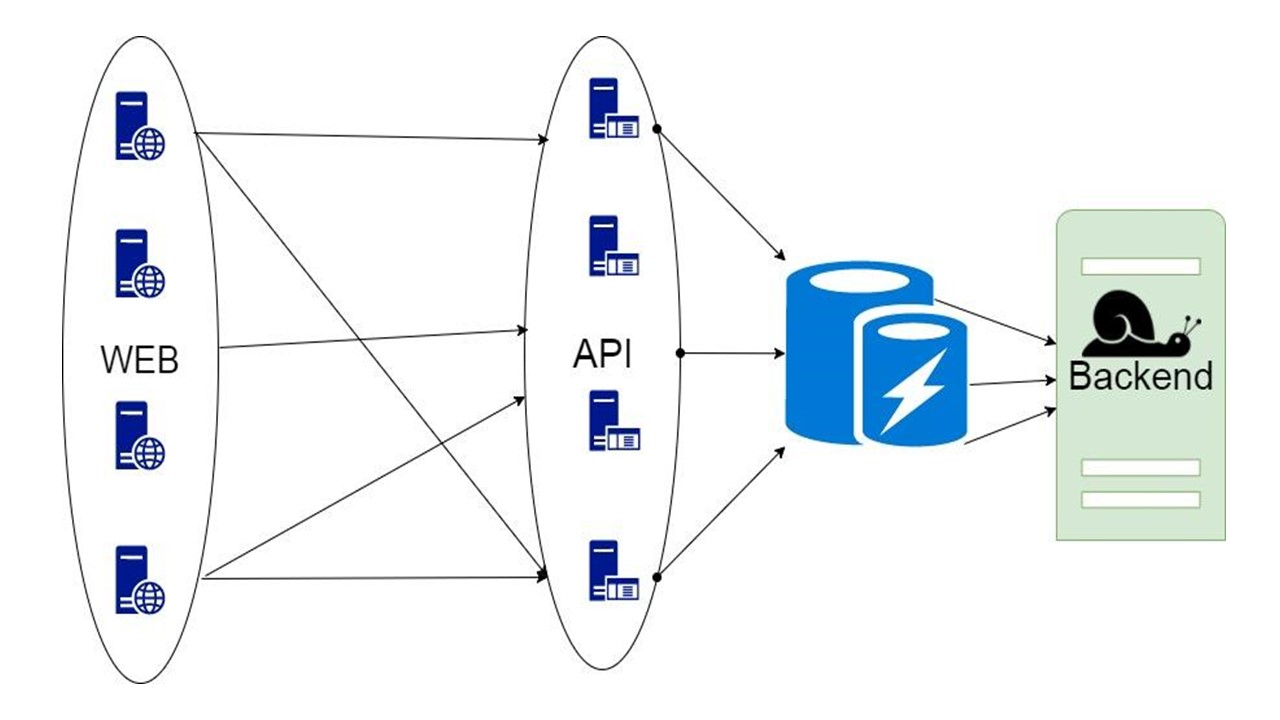
Caching basis data
Opsi ketiga rumit ketika bagian data yang dikembalikan backend dapat disimpan dalam waktu yang lama. Ketika mereka dibutuhkan, kami menunjukkan kepada klien, bahkan jika mereka tidak lagi relevan. Ini lebih baik daripada tidak sama sekali.
Keputusan ini akan dibahas.
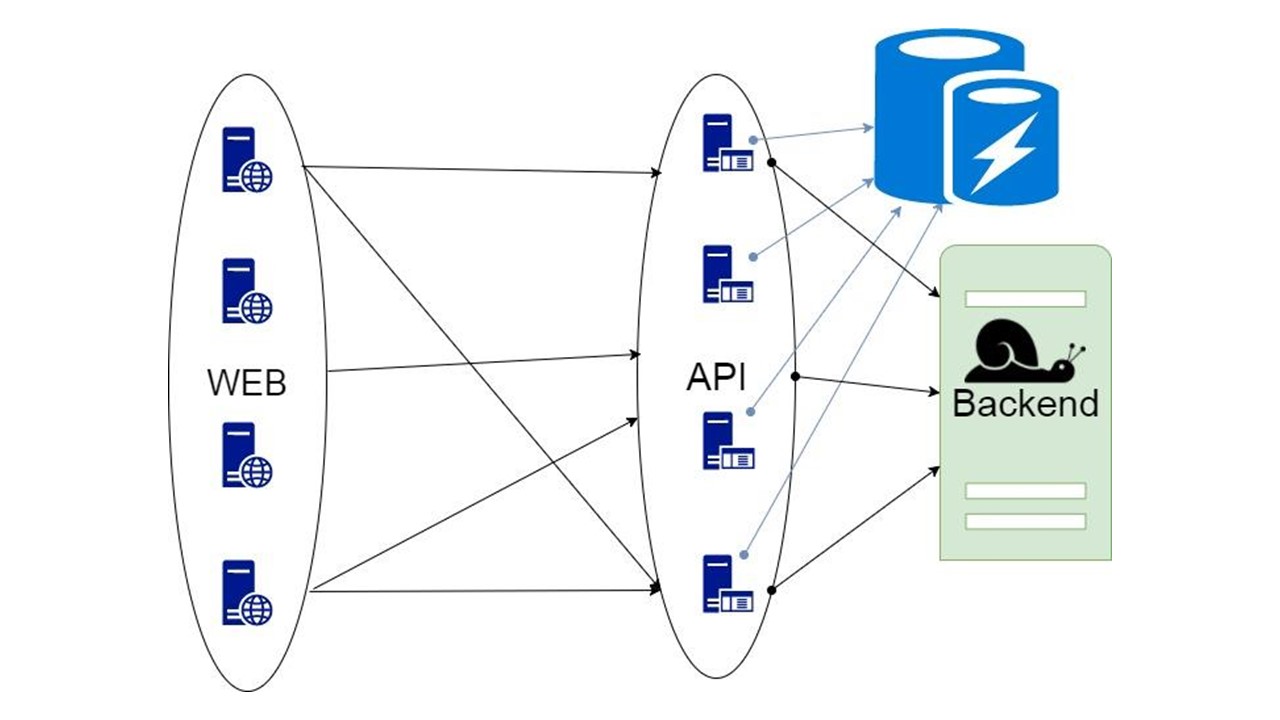
Cache cadangan
Ini perpustakaan kami. Itu tertanam dalam aplikasi dan berkomunikasi dengan backend. Dengan penyempurnaan minimal, ini menganalisis struktur data, menghasilkan format serialisasi dan, dengan bantuan algoritma Circuit Breaker, meningkatkan toleransi kesalahan. Serialisasi yang efektif dapat diimplementasikan dalam bahasa apa pun di mana jenis dapat dianalisis terlebih dahulu jika didefinisikan dengan cukup ketat.
Komponen
Perpustakaan kami terlihat seperti ini.

Bagian kiri dikhususkan untuk berinteraksi dengan repositori ini, yang mencakup dua komponen penting:
- komponen yang bertanggung jawab untuk proses inisialisasi - tindakan awal dengan DBMS sebelum menggunakan Fallback Cache;
- modul generasi serialisasi otomatis.
Sisi kanan adalah fungsi umum yang berhubungan dengan Fallback.
Bagaimana cara kerjanya? Ada pertanyaan di tengah aplikasi dan tipe perantara untuk penyimpanan. Formulir ini mengekspresikan data yang kami terima dari backend untuk satu atau beberapa permintaan. Kami mengirim parameter ke metode kami, dan kami mendapatkan data dari sana. Data ini perlu diserialisasi entah bagaimana agar dapat disimpan, jadi kami membungkusnya dalam kode. Modul terpisah bertanggung jawab untuk ini. Kami menggunakan pola Circuit Breaker.
Persyaratan penyimpanan
Umur simpan panjang - 30-500 hari . Beberapa tindakan bisa memakan waktu lama, dan selama ini diperlukan untuk menyimpan data. Karenanya, kami menginginkan penyimpanan yang dapat menyimpan data untuk waktu yang lama. Memori tidak cocok untuk ini.
Volume data besar - 100 GB-20 TB . Kami ingin menyimpan puluhan terabyte data dalam cache, dan bahkan lebih karena pertumbuhan. Menyimpan semua ini dalam memori tidak efisien - sebagian besar data tidak selalu diminta. Mereka berbohong untuk waktu yang lama, menunggu pengguna mereka, yang akan datang dan bertanya. Memori tidak termasuk dalam persyaratan ini.
Ketersediaan data yang tinggi . Apa pun dapat terjadi pada layanan, tetapi kami ingin agar DBMS tetap tersedia setiap saat.
Biaya penyimpanan rendah . Kami mengirim data tambahan ke cache. Akibatnya, terjadi overhead. Saat menerapkan solusi kami, kami ingin menguranginya.
Mendukung permintaan pada interval waktu tertentu . Basis data kami seharusnya dapat menarik sepotong data tidak hanya secara keseluruhan, tetapi pada interval: daftar tindakan, riwayat pengguna untuk periode tertentu. Karena itu, nilai kunci murni tidak cocok.
Asumsi
Persyaratan mempersempit daftar kandidat. Kami berasumsi bahwa kami telah mengimplementasikan sisanya, dan membuat asumsi berikut, mengetahui mengapa sebenarnya kami membutuhkan Fallback Cache.
Integritas data antara dua permintaan GET yang berbeda tidak diperlukan . Oleh karena itu, jika mereka menampilkan dua keadaan berbeda yang tidak konsisten satu sama lain, kami akan tahan dengan ini.
Relevansi dan pembatalan data tidak diperlukan . Pada saat permintaan, diasumsikan bahwa kami memiliki versi terbaru yang kami tampilkan.
Kami mengirim dan menerima data dari backend.
Struktur data ini diketahui sebelumnya .
Pilihan penyimpanan
Sebagai alternatif, kami mempertimbangkan tiga opsi utama.
Yang pertama adalah
Cassandra . Keuntungan: ketersediaan tinggi, skalabilitas mudah dan mekanisme serialisasi bawaan dengan koleksi UDT.
Jenis UDT atau
Ditentukan Pengguna , berarti beberapa jenis. Mereka memungkinkan Anda untuk menumpuk tipe terstruktur secara efisien. Bidang jenis sudah diketahui sebelumnya. Bidang serialisasi ini ditandai dengan tag terpisah seperti pada Protokol Buffer. Setelah membaca struktur ini, dimungkinkan untuk memahami bidang apa yang ada berdasarkan tag. Metadata yang cukup untuk mengetahui nama dan tipe mereka.
Kelebihan lain dari Cassandra adalah bahwa selain kunci partisi ia memiliki
kunci pengelompokan tambahan. Ini adalah kunci khusus, karena data tersebut dipesan pada satu simpul. Ini memungkinkan Anda untuk mengimplementasikan opsi seperti kueri interval.
Cassandra telah ada sejak lama, ada
banyak solusi pemantauan untuk itu , dan
satu minusnya adalah JVM . Ini bukan opsi paling produktif untuk platform tempat Anda bisa menulis DBMS. JVM memiliki masalah dengan pengumpulan sampah dan overhead.
Opsi kedua adalah
CouchBase . Keuntungan: aksesibilitas data, skalabilitas, dan Schemaless.
Dengan CouchBase, Anda tidak perlu terlalu memikirkan serialisasi. Ini adalah plus dan minus - kita tidak perlu mengontrol skema data. Ada indeks global yang memungkinkan Anda untuk menjalankan kueri interval secara global di seluruh cluster.
CouchBase adalah hibrida tempat
Memcache ditambahkan ke DBMS biasa
- cache cepat . Ini memungkinkan Anda untuk secara otomatis me-cache semua data pada node - terpanas, dengan ketersediaan sangat tinggi. Berkat cache-nya, CouchBase bisa cepat jika data yang sama sangat sering diminta.
Schemaless dan
JSON juga bisa menjadi minus. Data dapat disimpan begitu lama sehingga aplikasi memiliki waktu untuk berubah. Dalam hal ini, struktur data yang akan disimpan dan dibaca CouchBase juga akan berubah. Versi sebelumnya mungkin tidak kompatibel. Anda hanya akan belajar tentang ini ketika membaca, dan bukan ketika mengembangkan data, ketika itu terletak di suatu tempat di produksi. Kami harus memikirkan migrasi yang tepat, dan ini adalah hal yang tidak ingin kami lakukan.
Opsi ketiga adalah
Tarantool . Ini terkenal dengan kecepatan supernya. Ini memiliki mesin LUA luar biasa yang memungkinkan Anda untuk menulis banyak logika yang akan dijalankan tepat di server di LuaJit.
Di sisi lain, ini adalah nilai kunci yang dimodifikasi. Data disimpan dalam tupel. Kita perlu berpikir untuk diri kita sendiri tentang serialisasi yang benar, ini tidak selalu merupakan tugas yang jelas. Tarantool juga memiliki pendekatan spesifik untuk
skalabilitas . Apa yang salah dengannya, kita akan bahas lebih lanjut.
Sharding / replikasi
Mungkin aplikasi kita perlu
Sharding / Replikasi . Tiga repositori menerapkannya secara berbeda.
Cassandra menyarankan struktur yang biasanya disebut "cincin".
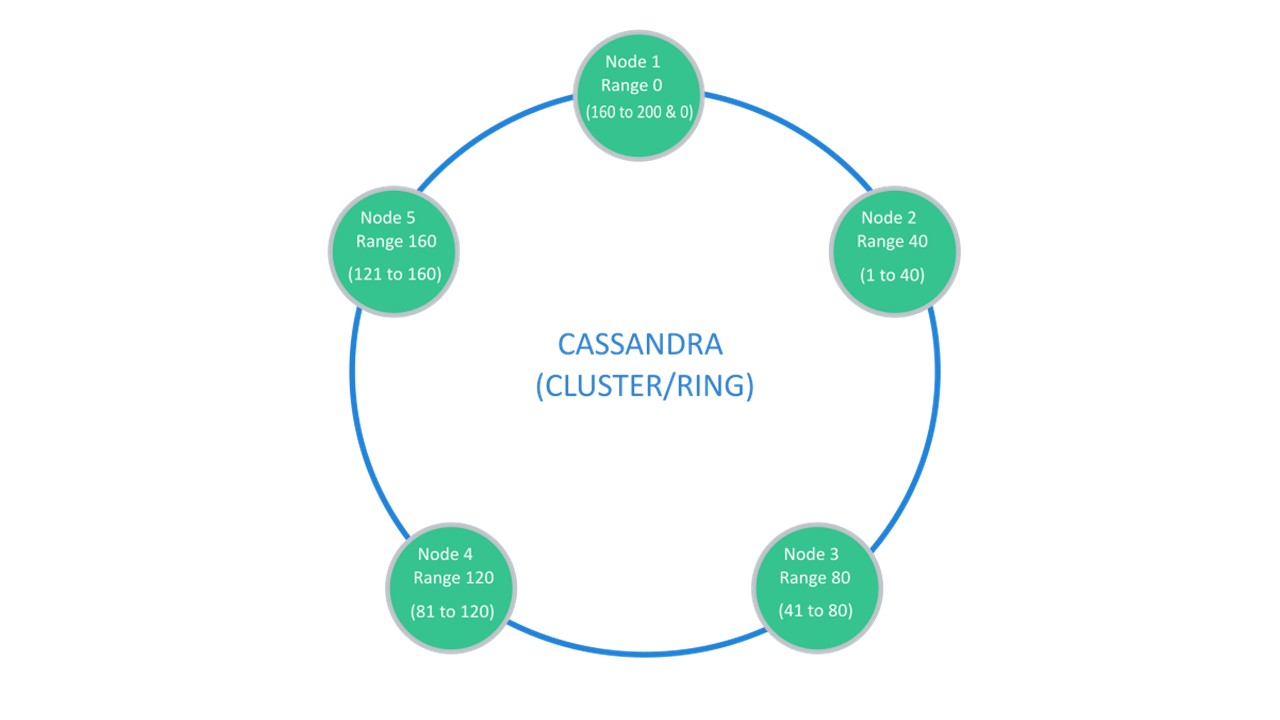
Banyak node tersedia. Masing-masing menyimpan data dan data dari node terdekat sebagai replika. Jika salah satu drop out, node di sebelahnya dapat melayani sebagian dari data sampai dropout naik.
Sharding \ Replication bertanggung jawab atas struktur yang sama. Untuk membongkar menjadi 10 buah dan Replikasi faktor 3, 10 node sudah cukup. Setiap node akan menyimpan 2 replika dari yang bertetangga.
Di CouchBase, struktur interaksi antara node disusun dengan cara yang sama:
- ada data yang ditandai sebagai aktif, di mana simpul itu sendiri yang bertanggung jawab;
- Ada replika node tetangga yang disimpan oleh CouchBase.
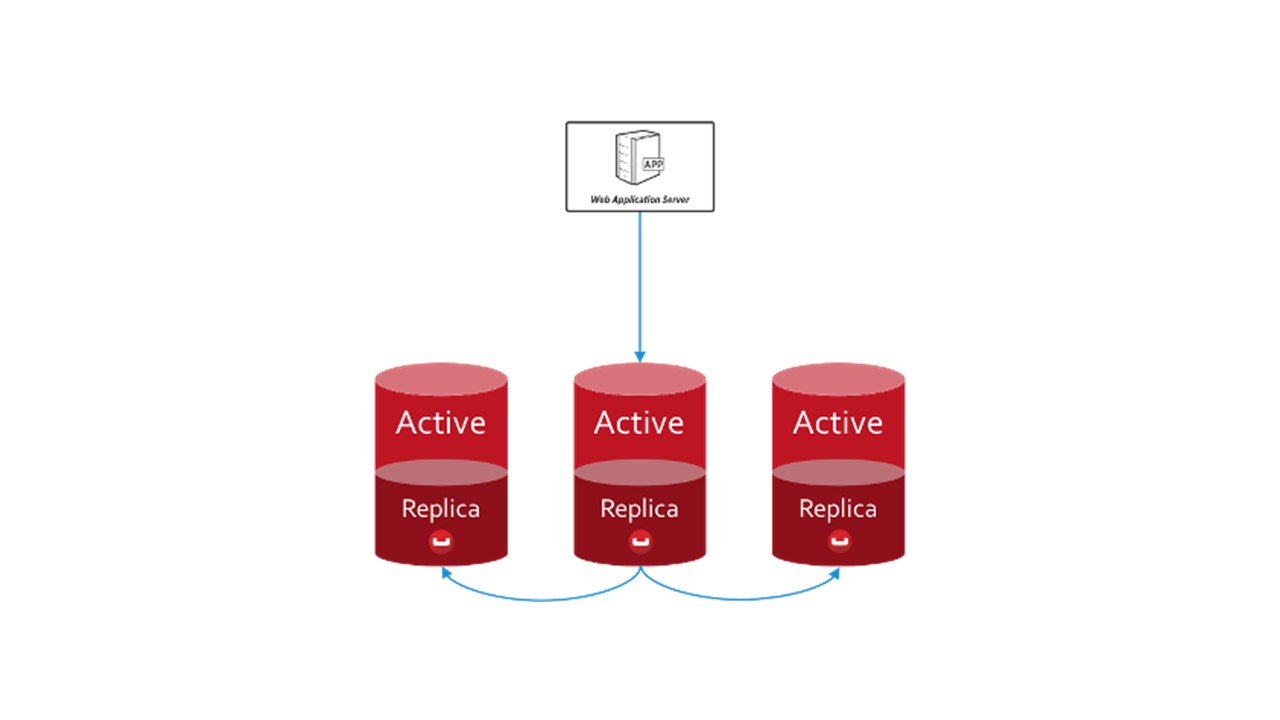
Jika satu simpul keluar, yang berdekatan, yang dibagikan, bertanggung jawab atas pemeliharaan bagian kunci ini.
Di Tarantool, arsitekturnya mirip dengan MongoDB. Tetapi dengan nuansa: ada kelompok sharding yang direplikasi satu sama lain.
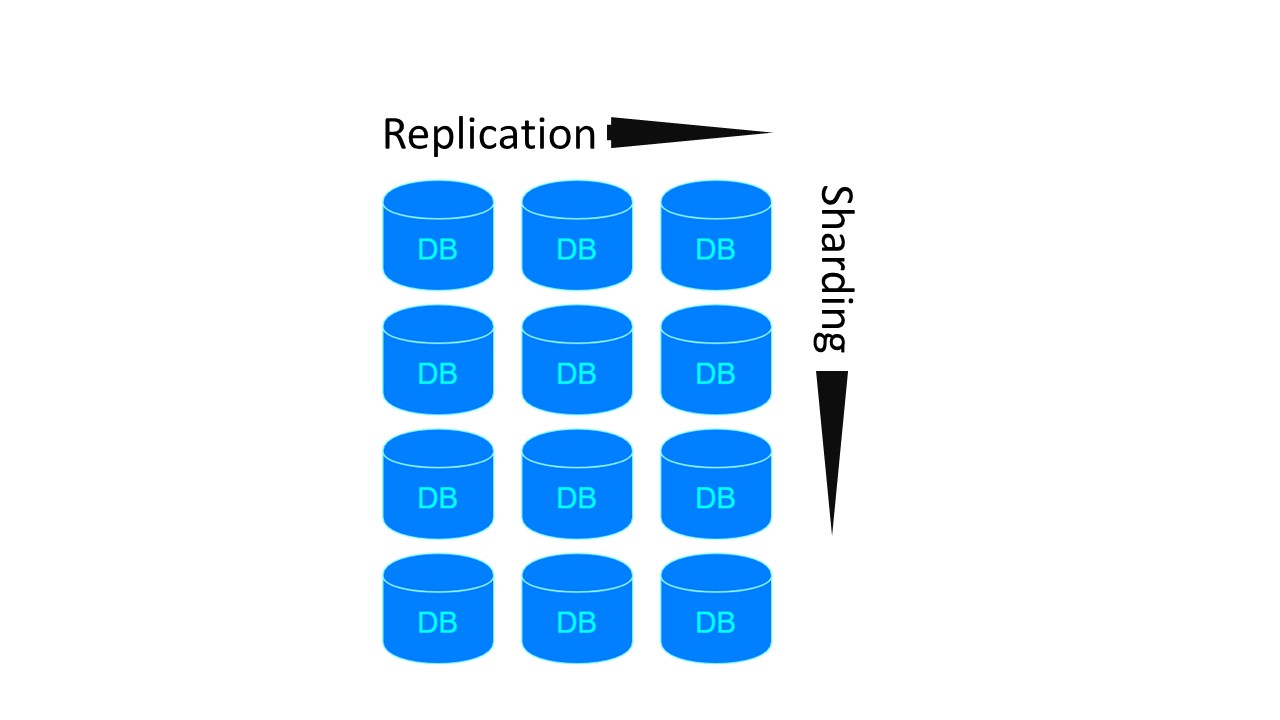
Untuk dua arsitektur sebelumnya, jika kita ingin membuat 4 pecahan dan Replikasi faktor 3, 4 node diperlukan. Untuk Tarantool - 12! Namun kerugiannya diimbangi oleh kecepatan yang dijamin Tarantool.
Cassandra
Modul opsional untuk sharding di Tarantool hanya muncul baru-baru ini. Karena itu, kami memilih Cassandra DBMS sebagai kandidat utama. Ingatlah bahwa kita berbicara tentang serialisasi spesifiknya.
Serialisasi otomatis
Protokol SQL mengasumsikan bahwa Anda cukup bebas untuk mendefinisikan skema data.
Anda bisa menggunakan ini sebagai keuntungan. Sebagai contoh, serialkan data sehingga nama-nama bidang panjang dari struktur rindang kami tidak disimpan setiap waktu dalam nilai kami. Dalam hal ini, kita akan memiliki beberapa metadata yang menggambarkan perangkat data. UDT sendiri juga memberi tahu bidang mana yang sesuai dengan label dan tag.
Oleh karena itu, serialisasi yang dihasilkan secara otomatis berlangsung kira-kira dengan cara yang sama. Jika kita memiliki salah satu tipe dasar yang dapat mencocokkan jenis dari basis data satu ke satu, kita melakukannya. Satu set jenis Int, Long, String, Double juga di Cassandra.
Jika bidang opsional ditemukan dalam beberapa struktur, kami tidak melakukan apa pun tambahan. Kami menunjukkan kepadanya tipe yang harus diubah bidang ini. Struktur akan menyimpan null. Jika kami menemukan nol dalam struktur pada tingkat deserialisasi, kami menganggap bahwa ini adalah tidak adanya nilai.
Semua tipe koleksi dari koleksi di Scala dikonversi ke daftar tipe. Ini adalah koleksi yang dipesan yang memiliki elemen pencocokan indeks.
Kumpulan koleksi Unordered menjamin bahwa ada tepat satu elemen dengan nilai masing-masing. Cassandra juga memiliki tipe set khusus untuk mereka.
Kemungkinan besar, kami akan memiliki banyak pemetaan (), terutama dengan kunci string. Cassandra memiliki tipe peta khusus untuk mereka. Itu juga diketik dan memiliki dua tipe parameter. Sehingga kita bisa membuat tipe yang sesuai untuk kunci apa saja
Ada tipe data yang kami tentukan sendiri dalam aplikasi kami. Dalam banyak bahasa mereka disebut
tipe data aljabar . Mereka didefinisikan dengan mendefinisikan produk bernama jenis, yaitu struktur. Kami menetapkan struktur ini untuk Jenis yang Ditentukan Pengguna. Setiap bidang struktur akan sesuai dengan satu bidang di UDT.
Tipe kedua adalah
jumlah jenis aljabar . Dalam hal ini, jenisnya berhubungan dengan beberapa subtipe atau subspesies yang diketahui sebelumnya. Juga, dengan cara tertentu, kami menetapkan struktur untuk itu.
Abstrak Tipe Data diterjemahkan ke UDT
Kami memiliki struktur, dan kami menampilkannya satu demi satu - untuk setiap bidang, kami menentukan bidang dalam UDT yang dibuat di Cassandra:
case class Account ( id: Long, tags: List[String], user: User, finData: Option[FinData] ) create type account ( id bigint, tags: frozen<list<text>>, user frozen<user>, fin_data frozen<fin_data> )
Tipe primitif berubah menjadi tipe primitif. Tautan ke jenis yang telah ditentukan sebelum ini menjadi beku. Ini adalah pembungkus khusus dalam Cassandra, yang berarti Anda tidak dapat membaca dari bidang ini sepotong demi sepotong. Pembungkus "beku" ke dalam kondisi ini. Kami hanya dapat membaca atau menyimpan pengguna, atau daftar, seperti dalam kasus tag.
Jika kami memenuhi bidang opsional, maka kami membuang karakteristik ini. Kami hanya mengambil tipe data yang sesuai dengan jenis bidang yang akan. Jika kita bertemu bukan di sini - tidak adanya nilai - kita menulis nol di bidang yang sesuai. Saat membaca, kami juga akan menerima korespondensi non-nol.
Jika kita menemukan tipe yang memiliki beberapa alternatif yang sudah diketahui sebelumnya, maka kita juga mendefinisikan tipe data baru di Cassandra. Untuk setiap alternatif, bidang dalam tipe data kami di UDT.
Akibatnya, dalam struktur ini, hanya satu bidang pada waktu tertentu tidak akan menjadi nol. Jika Anda bertemu dengan beberapa jenis pengguna, dan itu ternyata merupakan contoh dari moderator di runtime, bidang moderator akan berisi beberapa nilai, sisanya akan menjadi nol. Untuk admin - admin, sisanya - null.
Ini memungkinkan Anda untuk menyandikan struktur sebagai berikut: kami memiliki 4 bidang opsional, kami menjamin bahwa hanya satu yang akan ditulis darinya. Cassandra hanya menggunakan satu tag untuk mengidentifikasi keberadaan bidang tertentu dalam struktur. Berkat ini, kami mendapatkan struktur penyimpanan tanpa overhead.
Bahkan, untuk menyimpan tipe pengguna, jika itu adalah moderator, dibutuhkan jumlah byte yang sama dengan yang diperlukan untuk menyimpan moderator. Ditambah satu byte untuk menunjukkan alternatif tertentu yang ada di sini.
Inisialisasi
Inisialisasi adalah prosedur awal yang harus diselesaikan sebelum kita dapat menggunakan fallback kami.
Bagaimana proses ini bekerja?
- Pada setiap node kami menghasilkan definisi tabel, tipe, dan teks kueri berdasarkan tipe yang disajikan.
- Baca skema saat ini dari DBMS. Dalam Cassandra, ini mudah dilakukan hanya dengan menghubungkannya. Ketika terhubung, di hampir semua driver, objek "sesi" itu sendiri memompa keluar metadata ruang utama yang terhubung. Maka Anda dapat melihat apa yang mereka miliki.
- Kami menelusuri metadata, membandingkan, dan memverifikasi bahwa segala sesuatu yang ingin kami buat diizinkan dan migrasi inkremental dimungkinkan.
- Jika semuanya normal dan inisialisasi dimungkinkan, kami melakukan migrasi.
- Kami sedang mempersiapkan permintaan.
sealed trait User case class Anonymous extends User case class Registered extends User case class Moderator extends User case class Admin extends User create type user ( anonymous frozen<anonymous>, registered frozen<registered>, moderator frozen<moderator>, admin frozen<admin> )
Itu terjadi seperti ini. Kami memiliki
tipe ,
tabel, dan
kueri . Jenis tergantung pada jenis lain, orang lain. Tabel tergantung pada jenis ini. Kueri sudah bergantung pada tabel tempat mereka membaca data. Inisialisasi akan memeriksa semua dependensi ini dan membuat segala sesuatu yang dapat dibuat dalam DBMS, sesuai dengan aturan tertentu.
Jenis Migrasi
Bagaimana menentukan bahwa suatu tipe dapat dimigrasikan secara bertahap?
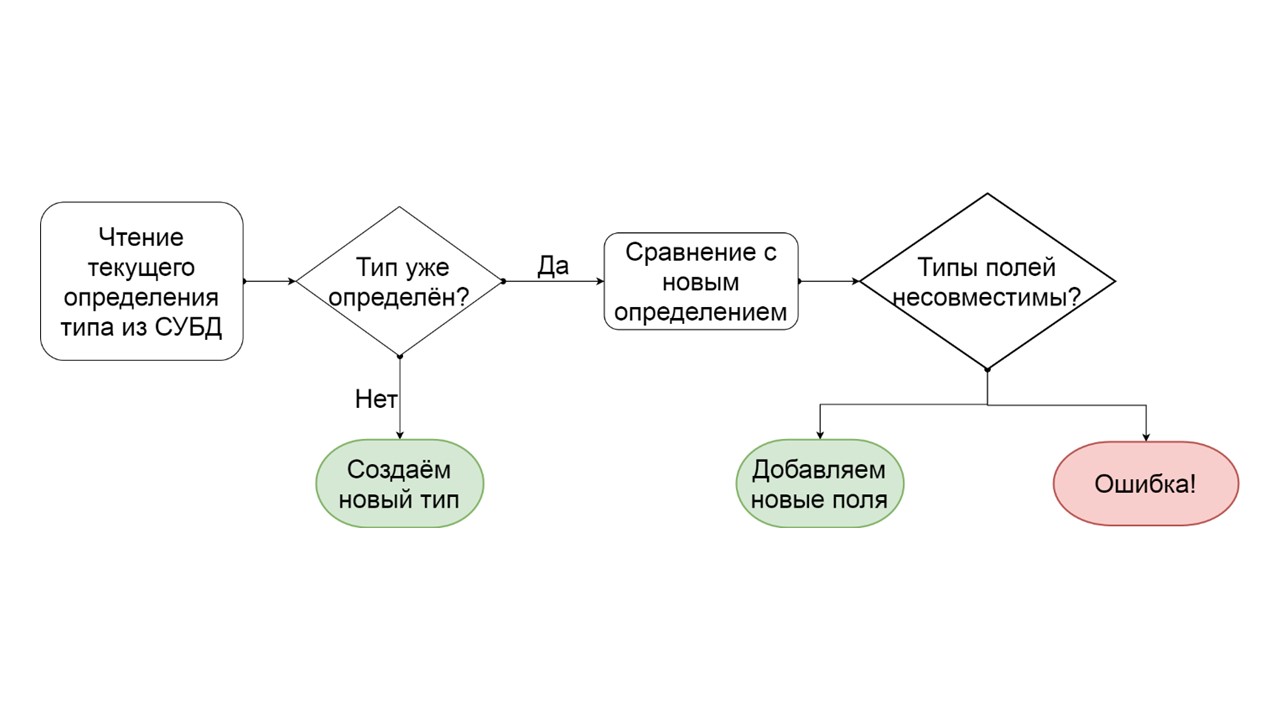
- Kita membaca bagaimana jenis ini didefinisikan dalam DBMS.
- Jika tidak ada jenis seperti itu, yaitu, kami datang dengan yang baru - kami membuatnya.
- Jika jenis tersebut sudah ada, kami mencoba membandingkan bidang demi bidang definisi yang ada dengan definisi yang ingin kami berikan untuk jenis ini.
- Jika ternyata kami ingin menambahkan hanya beberapa bidang yang tidak ada lagi, kami melakukannya. Buat daftar operasi ALTER TYPE bermutasi, dan mulai mereka.
- Jika ternyata kami memiliki beberapa jenis bidang yang berbeda jenis - kami menghasilkan kesalahan. Misalnya, ada daftar - menjadi peta, atau ada tautan ke satu jenis yang ditentukan pengguna, dan kami mencoba membuatnya berbeda.
Pengembang dapat melihat kesalahan ini bahkan sebelum ia memulai fungsionalitas pada produksi. Saya berasumsi bahwa skema data yang sama persis ada di lingkungan pengembangannya. Dia melihat bahwa dia entah bagaimana membuat skema data yang tidak dapat dimigrasikan, dan untuk menghindari kesalahan ini, dia dapat mengganti serialisasi yang dibuat secara otomatis, menambahkan opsi, mengganti nama bidang atau semua jenis dan tabel secara keseluruhan.
Inisialisasi: Jenis
Bayangkan ada beberapa jenis definisi:
case class Product (id: Long, name: ctring, price: BigDecimal) case class UserOffers (valiDate: LocalDate, offers: Seq[Products]) case class UserProducts (user User, products: Map[Date, Product]) case class UserInfo: UserOffers, products: UserProducts)
Kelas kasus - kelas yang berisi sekumpulan bidang. Ini adalah analog dari struct di Rust.
Kami akan menghasilkan kira-kira definisi data seperti itu untuk masing-masing dari 4 jenis - yang ingin kami crank:
CREATE TYPE product (id bigint, name text, price decimal); CREATE TYPE user_offers (valid_date date, offers frozen<list<frozen<offer>>>); CREATE TYPE user_products (user frozen<user>, products frozen<map<date, frozen<product>>); CREATE TYPE user_jnfo (offers: frozen<user_offers>, products: frozen<user_products>);
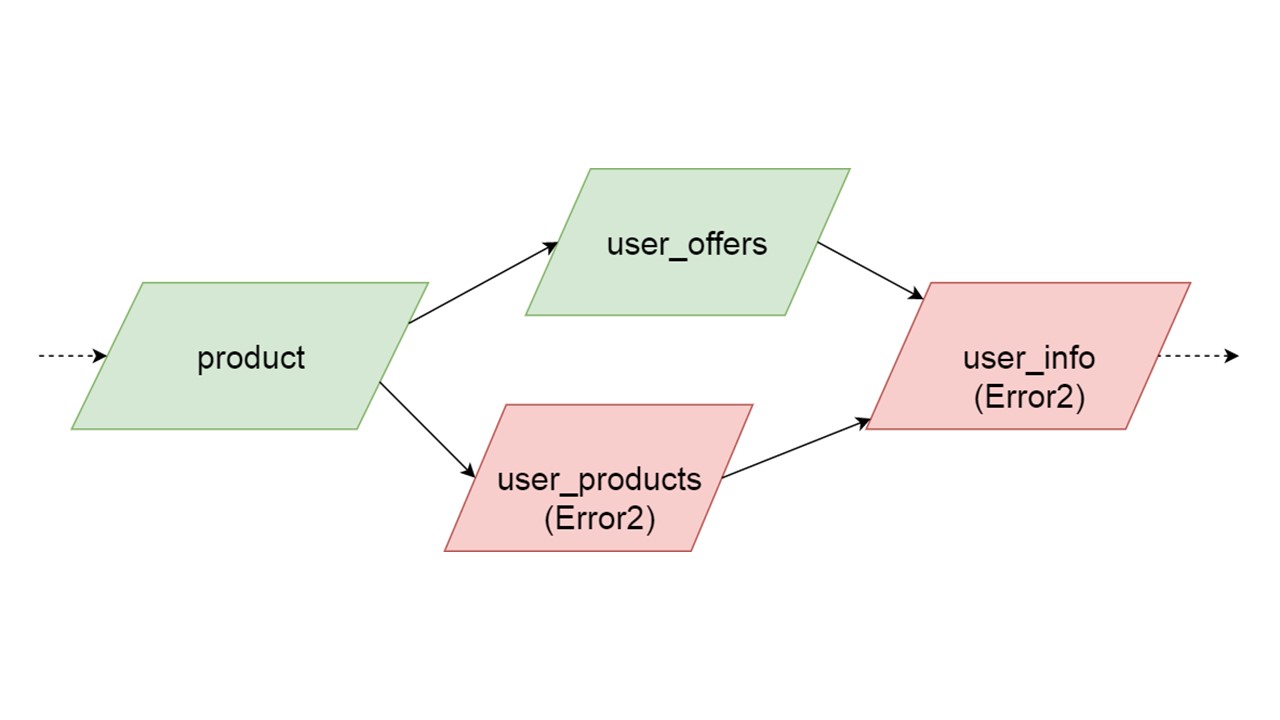
Jenis user_offers tergantung pada jenis penawaran, user_products tergantung pada jenis produk, user_info pada jenis kedua dan ketiga.

Kami memiliki ketergantungan antar tipe, dan kami ingin menginisialisasi dengan benar. Diagram menunjukkan bahwa kita akan menginisialisasi user_offers dan user_products secara paralel. Ini tidak berarti bahwa kami akan meluncurkan dua operasi paralel. Tidak, kami memulai semua pernyataan, semua analisis secara berurutan, agar tidak secara tidak sengaja membuat tipe yang sama dalam dua utas paralel.
Tetapi ada beberapa paralelisme di tingkat koreksi kesalahan. Jika kesalahan jenis terjadi, semua yang bergantung padanya akan menarik kesalahan aslinya.
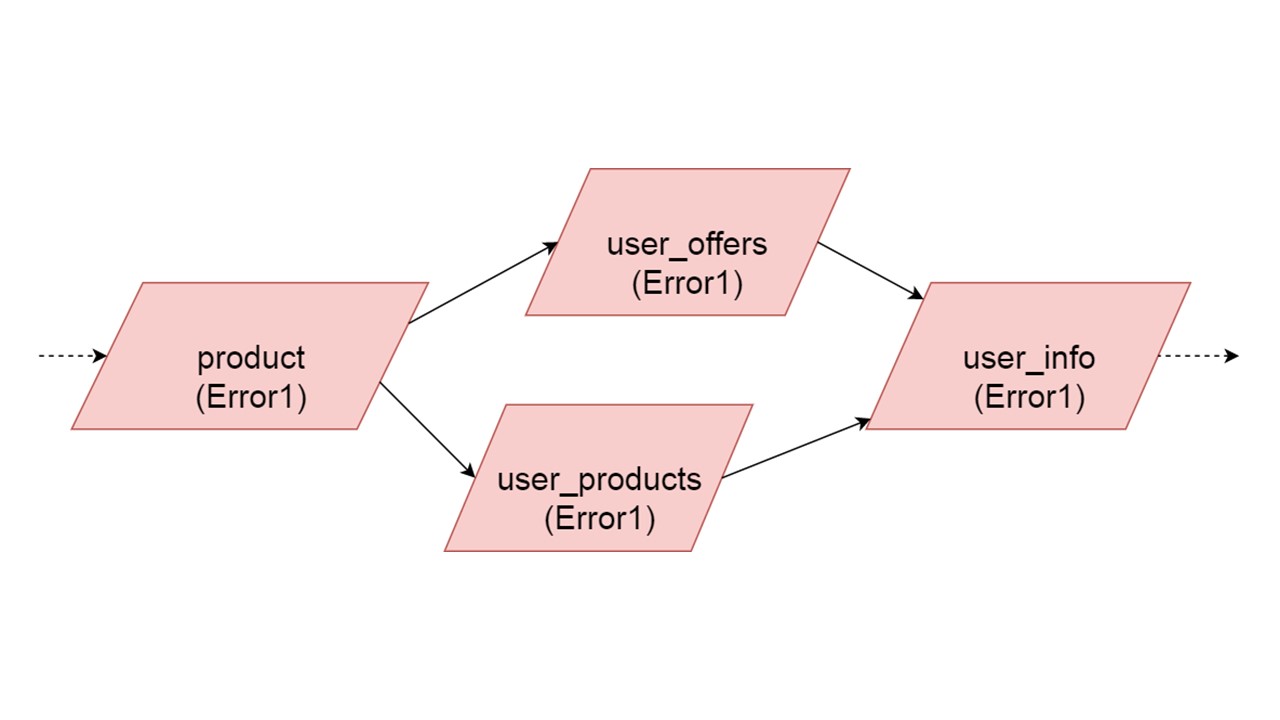
Jika kesalahan dihasilkan oleh salah satu cabang paralel, segala sesuatu yang bergantung pada data yang dimigrasi secara normal akan dihasilkan tanpa kesalahan. Jika ada definisi lebih lanjut dari tabel, pernyataan yang disiapkan dari mereka, kita dapat dengan aman menginisialisasi bagian dari Cache Balik kami ini. Komunikasi akan hilang hanya dengan beberapa bagian dari backend atau dengan beberapa fungsi. Sisanya diinisialisasi.
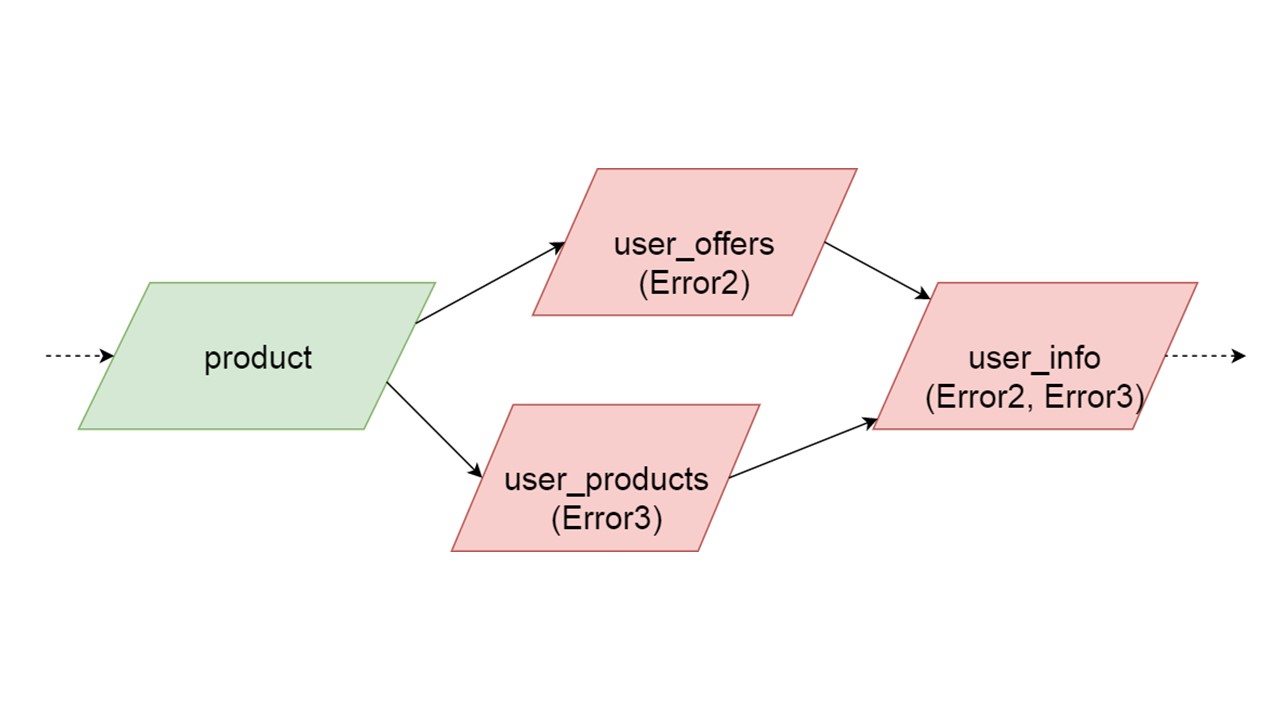
Mungkin saja dua tipe yang secara bersamaan diinisialisasi menghasilkan kesalahan yang berbeda. Dalam hal ini, fungsionalitas yang bergantung pada kedua jenis akan menghasilkan jenis kesalahan penjumlahan. Pengembang, menginisialisasi Fallback-nya di lingkungan pengembangan, akan menerima daftar lengkap data dengan kesalahan. Secara alami, ia dapat memperbaikinya di sini dan mendapatkan kesalahan lebih lanjut. Tetapi itu tidak akan seperti satu cabang yang sepenuhnya independen menutup kesalahan yang bisa kita dapatkan, terlepas dari cabang ini.
Inisialisasi: Tabel
Selanjutnya kita buat tabel.
def getOffer (user: User, number: Long): Future[OfferData] create table get_offer( key frozen<tuple<frozen<user>, bigint>>PRIMARY KEY, value frozen<friend_data> )
Permintaan semacam itu dapat langsung meluncurkan permintaan REST atau SOAP, membuat operasi tambahan di dalam, atau bahkan menjalankan beberapa permintaan. Itu semua tergantung pada kode Anda - bagaimana Anda mengatur kode akan demikian. Fallback sepenuhnya tidak menganalisis apa yang terjadi di dalam metode di mana Anda menggantung rintisan seperti itu.
Metode ini harus asinkron, karena Fallback sama.
Di Scala, ini ditandai dengan jenis khusus Masa Depan. Ini berarti bahwa hasilnya akan kembali suatu hari nanti. Kapan tepatnya - tidak diketahui: mungkin segera, atau mungkin tidak.
Untuk metode ini, buat tabel. Kunci dalam tabel adalah tupel dari semua jenis yang sesuai dengan parameter metode ini. Nilai bukan kunci adalah hasilnya, yang dikembalikan secara tidak sinkron. Untuk setiap tabel tersebut, kami menyiapkan dua pertanyaan parametrik terlebih dahulu: memasukkan data dan membaca data.
insert into get_offer(key, value) values (?key, ?value); select value from get_offer where key = ?key;
Semuanya siap berinteraksi dengan DBMS. Tetap mencari tahu bagaimana kita akan membaca data dari Fallback.
Pemutus sirkuit
Di sini, tanggung jawab masuk ke zona pola Pemutus Sirkuit yang terkenal.
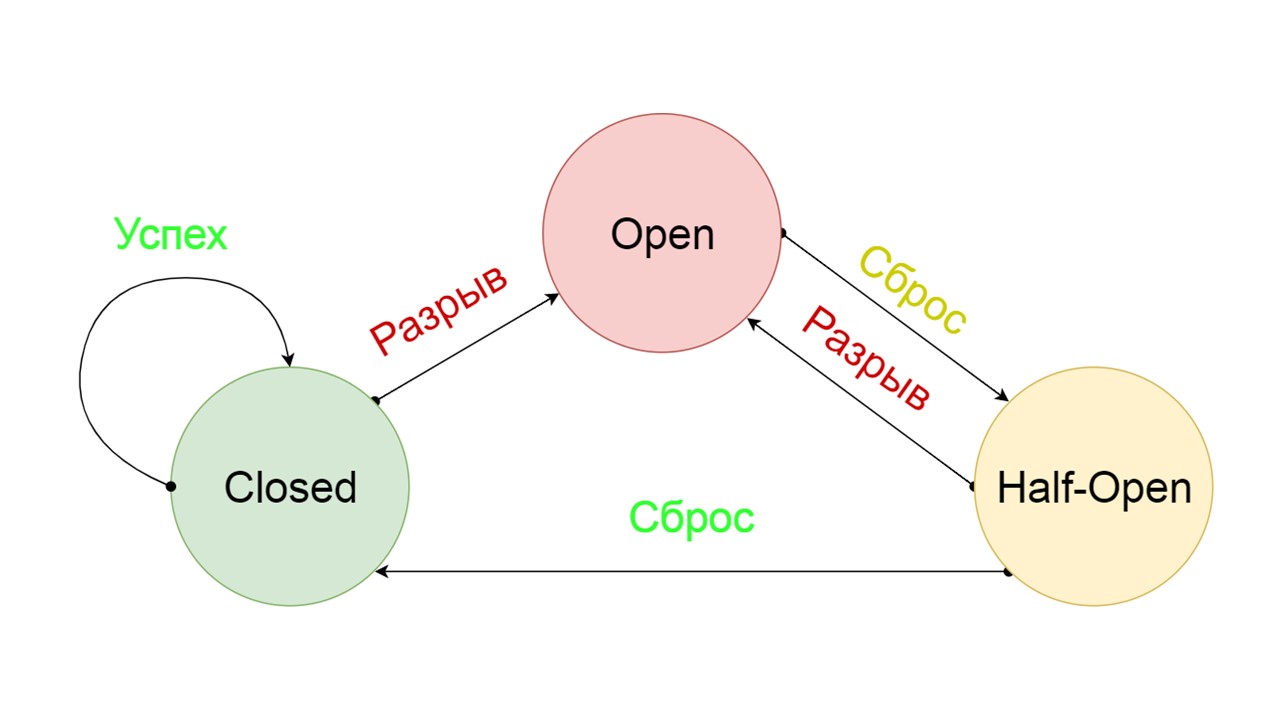
Pemutus Sirkuit khas mencakup tiga negara.
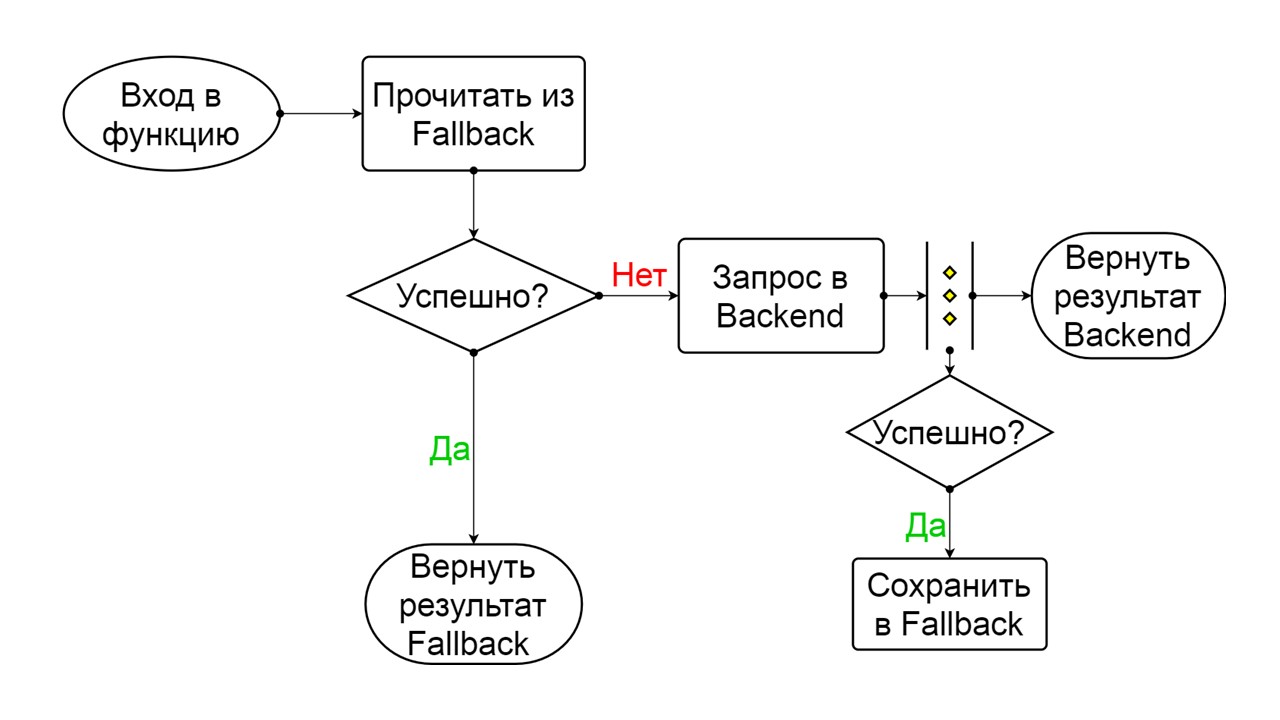
Tertutup - keadaan tertutup default yang menutup backend kami. Prinsipnya adalah bahwa kita membaca data terlebih dahulu dari backend, dan hanya jika kita tidak bisa mendapatkannya, buka Fallback. Jika kami berhasil mendapatkan data, kami tidak mencari di Fallback, tetapi simpan data di dalamnya dan tidak ada yang terjadi.
Jika masalah terjadi satu demi satu, kami menganggap bahwa backend berbohong. Agar tidak melakukan spam dengan permintaan besar dalam jumlah besar, kami beralih ke
Buka - dalam keadaan terkoyak . Di dalamnya, kami mencoba membaca data hanya dari Fallback. Jika tidak berhasil, kami segera mengembalikan kesalahan, dan bahkan tidak menyentuh backend utama.
Setelah beberapa saat, kami memutuskan untuk mencari tahu apakah backend bangun, dan mencoba untuk mengatur ulang kondisi
Setengah Terbuka - keadaan singkat . Masa hidupnya adalah satu permintaan.
Dalam keadaan berumur pendek, kami memilih untuk menutup lagi atau membuka untuk waktu yang lebih lama. Jika dalam kondisi Setengah Terbuka kami berhasil mencapai Fallback dan menerima permintaan berikutnya, kami pergi ke keadaan Tertutup. Jika kami tidak bisa melewatinya, kami kembali ke Open, tetapi untuk waktu yang lama.
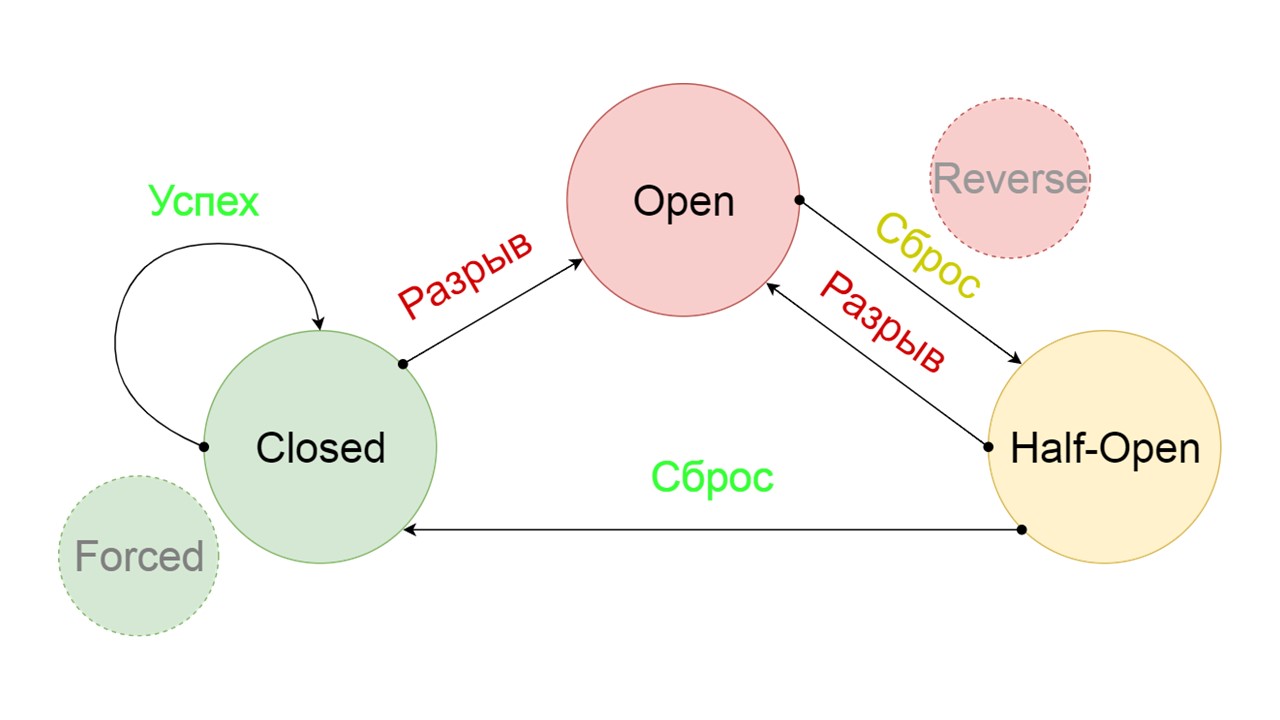
Kami menambahkan dua status tambahan yang jelas tidak terkait dengan sirkuit Circuit Breaker:
- Terpaksa - keadaan tertutup paksa;
- Terbalik - prioritas untuk keadaan terbuka, tertutup, terbalik.
Mari kita lihat apa yang mereka lakukan.
Prinsip operasi negara
Tertutup Skema itu besar, tetapi cukup untuk memahami prinsip umum darinya. Kami menjaga Fallback secara paralel dengan cara kami mengembalikan hasil dari backend, jika semuanya berjalan dengan baik di sana dan membaca dari Fallback. Jika buruk di mana-mana, kami mengembalikan prioritas kesalahan.
Dari dua kesalahan, pilih kesalahan backend.
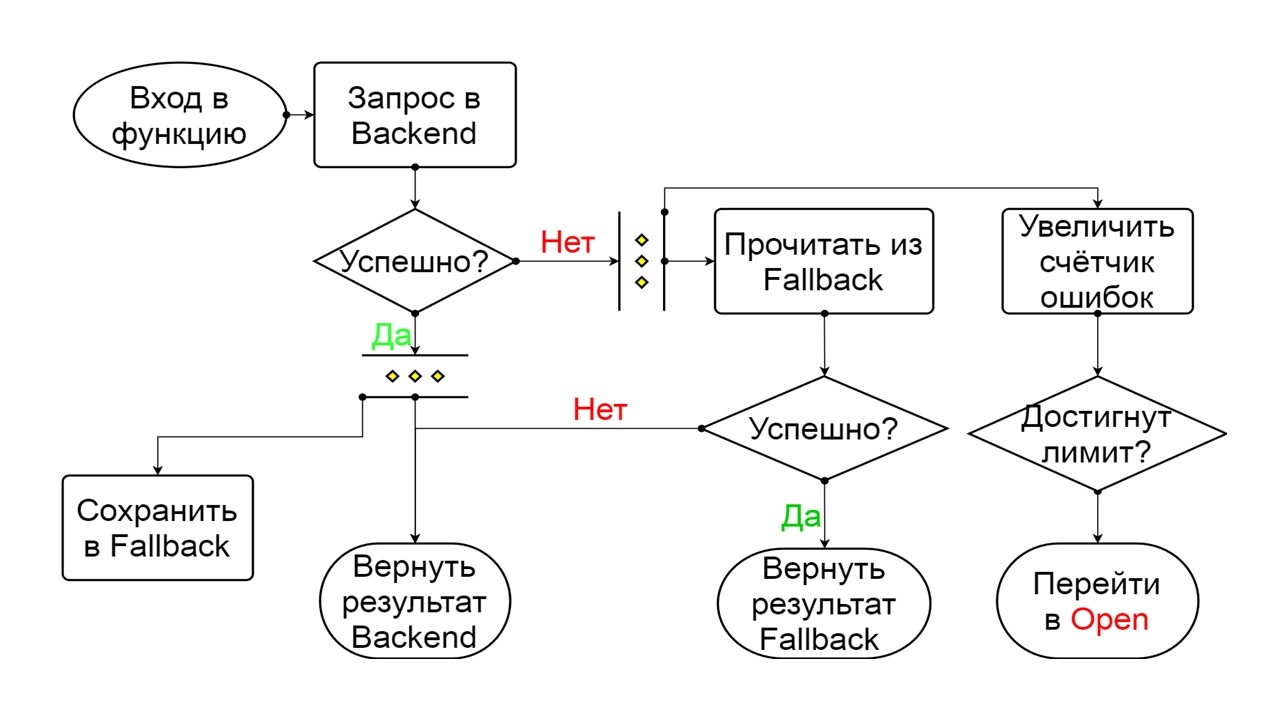
Jika tidak ada kesalahan, kami menambah penghitung secara paralel dengan ini dan masuk ke kondisi terbuka saat ada terlalu banyak permintaan.
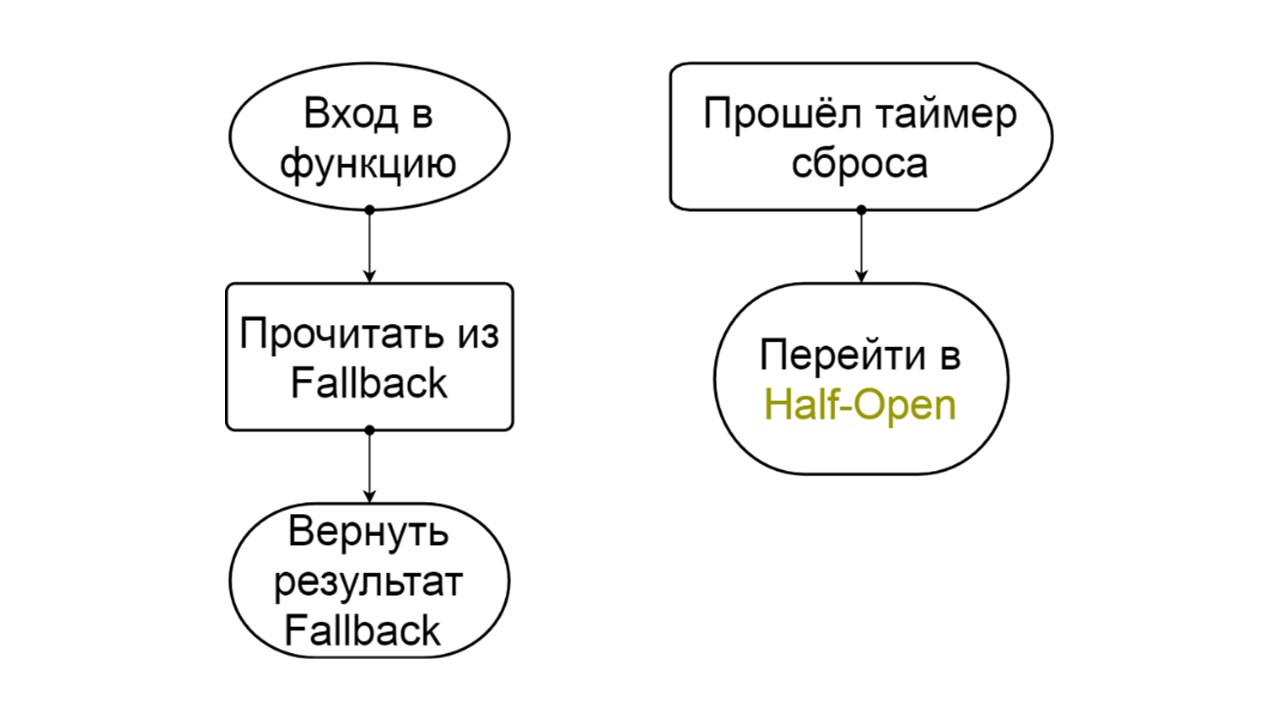 Buka
Buka Status terbuka Open lebih sederhana - kami terus membaca dari Fallback, apa pun yang terjadi, dan setelah beberapa saat kami mencoba beralih ke status Setengah Terbuka.
Setengah terbuka . Keadaan dalam struktur menyerupai Tertutup. Perbedaannya adalah bahwa dalam hal jawaban yang berhasil, kita masuk ke keadaan tertutup. Dalam hal kegagalan - kami kembali ke tempat terbuka dengan interval yang diperpanjang.
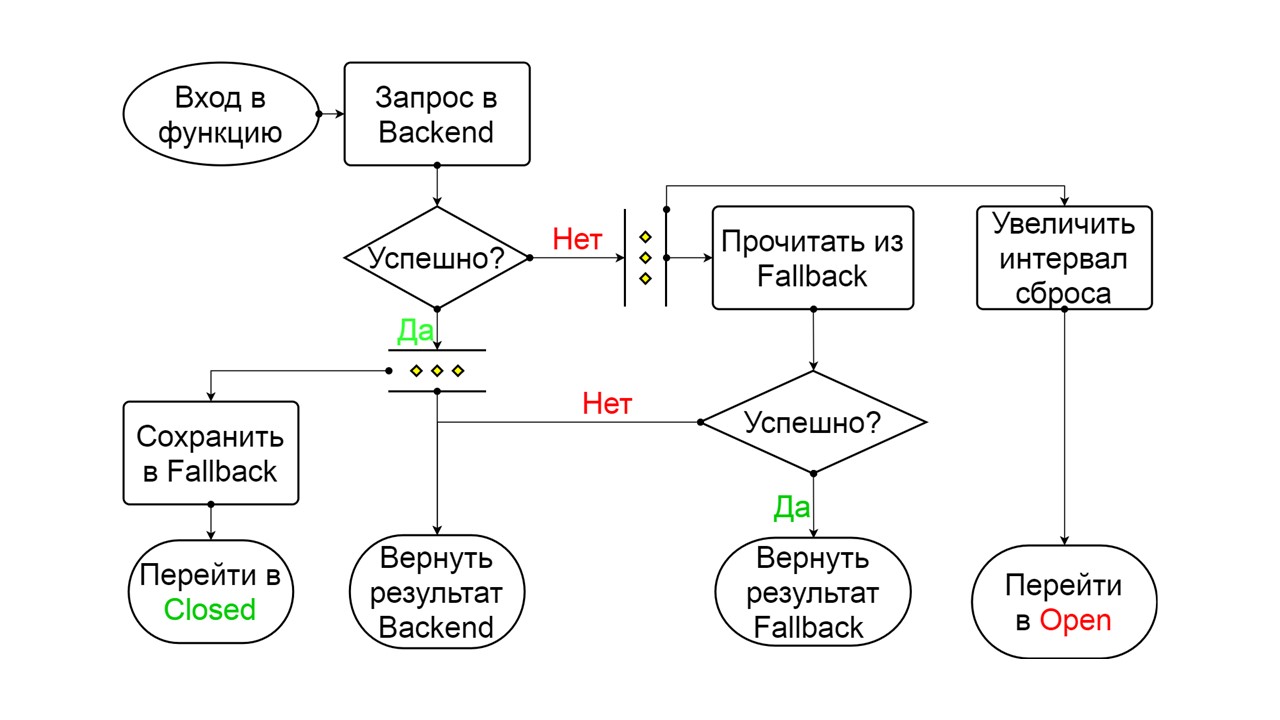 Terpaksa adalah kondisi ekstra untuk menghangatkan cache
Terpaksa adalah kondisi ekstra untuk menghangatkan cache . Ketika kami mengisinya dengan data, itu tidak pernah mencoba membaca dari Fallback, tetapi hanya menambahkan catatan.
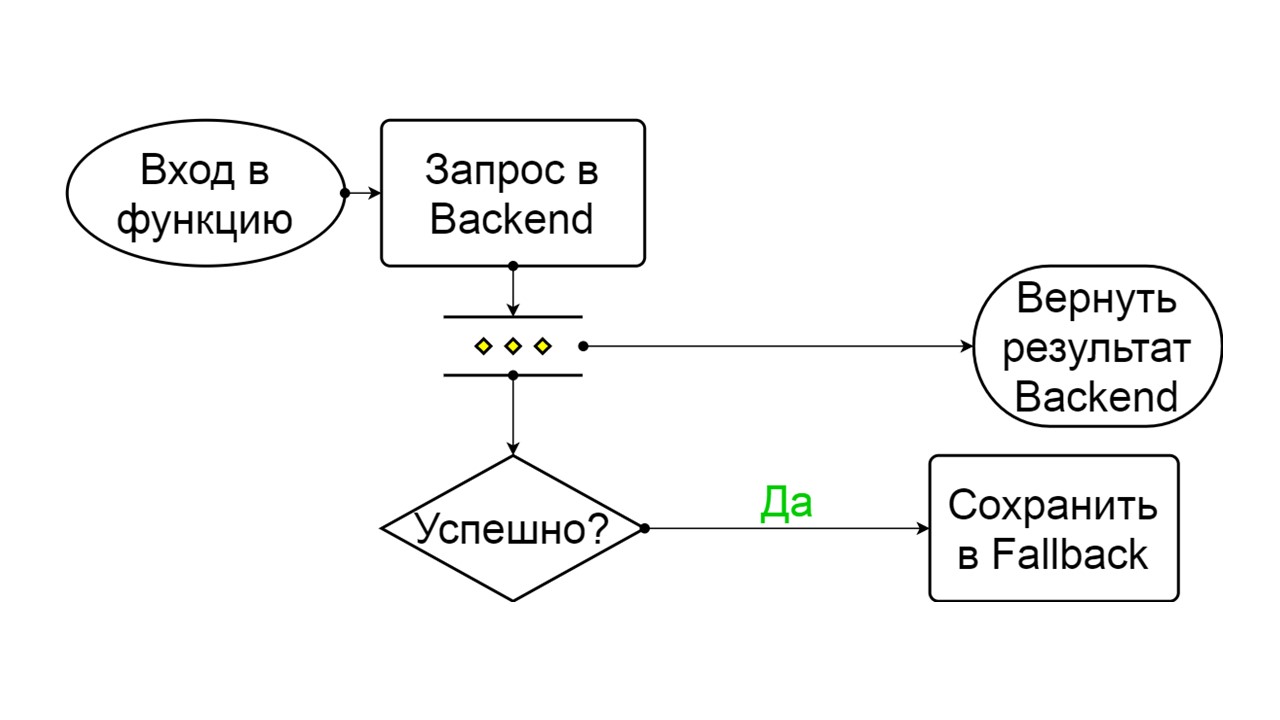 Terbalik adalah keadaan yang dibuat-buat kedua
Terbalik adalah keadaan yang dibuat-buat kedua . Ini berfungsi seperti cache persisten. Kami mengaktifkan status saat kami ingin menghapus secara permanen beban dari backend, bahkan jika datanya mungkin tidak relevan. Membalik pencarian pertama di Fallback, dan jika pencarian gagal, ia pergi ke backend dan mengatasinya.
Masalahnya
Dengan seluruh skema ini, kami memiliki beberapa masalah. Yang paling serius adalah dengan pemahaman tentang bagaimana
pernyataan yang disiapkan bekerja di Cassandra. Masalah ini diperbaiki pada versi 4.0, yang belum dirilis, jadi saya akan memberi tahu Anda.
Cassandra dirancang untuk menghubungkan jutaan pelanggan pada saat yang sama, dan semua orang berusaha menyiapkan pernyataan yang sudah disiapkan. Secara alami, Cassandra tidak menyiapkan setiap pernyataan yang disiapkan, jika tidak maka akan kehabisan memori. Ini menghitung parameter MD5 berdasarkan pada teks, ruang kunci, dan opsi permintaan. Jika dia menerima permintaan yang persis sama dengan MD5 yang persis sama, dia menerima permintaan yang sudah disiapkan. Sudah memiliki informasi tentang metadata dan cara menanganinya.
Tetapi ada masalah versi. Kami merilis rilis baru, itu berhasil menggulir migrasi, menambahkan bidang dalam tipe, dan menjalankan pernyataan yang disiapkan. Mereka kembali dengan versi sebelumnya dari negara kita dan metadata - dengan tipe tanpa bidang. Pada saat membaca data, kami mencoba untuk menulis kolom baru yang diperlukan, dan dihadapkan dengan fakta bahwa mereka tidak ada! Cassandra mengatakan bahwa ini umumnya jenis yang berbeda yang dia tidak tahu.
Kami menangani masalah ini sebagai berikut: kami
menambahkan teks unik ke setiap permintaan yang kami siapkan .
create table get_offer( key frozen<tuple<frozen<user>, bigint>> PRIMARY KEY, value frozen<friend_data>, query_tag text ) insert into get_offer (key, value, query_tag) values (?key, ?value, 'tag_123'); select value as tag_123 from get_offer where key = ?key;
Kami tidak akan memiliki jutaan klien yang terhubung, tetapi hanya satu sesi untuk setiap node yang memiliki beberapa koneksi. Untuk setiap menyiapkan pernyataan sekali. Kami berasumsi bahwa tidak apa-apa jika untuk setiap versi aplikasi atau untuk setiap permulaan node, teks unik dihasilkan, yang jelas akan ada dalam teks permintaan kami.
Kami menambahkan bidang khusus untuk menipunya. Saat memasukkan, kami menulis konstanta di bidang ini. Ini unik untuk setiap peluncuran atau versi aplikasi - ini dikonfigurasi di perpustakaan. Saat membaca, kami menggunakan nama ini sebagai alias untuk nilai yang kami dapatkan. Permintaannya persis sama, kami masih melakukan nilai pilih, tetapi teksnya berbeda. Cassandra tidak menyadari bahwa ini adalah permintaan yang sama, menghitung MD5 lain dan mempersiapkan permintaan lagi dengan metadata baru.
Masalah kedua adalah
ras migrasi . Misalnya, kami ingin membuat beberapa migrasi paralel. Mari kita mulai beberapa catatan dan pada saat yang sama mereka akan memulai perhitungan, mereka akan menjalankan tabel buat, membuat jenis. Ini dapat mengarah pada fakta bahwa pada setiap node atau di setiap thread paralel semuanya akan berhasil dan dua tabel tampaknya dibuat dengan sukses. Tetapi di dalam Cassandra menjadi bingung, dan kami akan menerima batas waktu untuk menulis dan membaca.
Anda dapat memecahkan Cassandra jika Anda mencoba untuk memparalelkan proses dari banyak utas atau dari beberapa simpul.
Jika kita tahu bahwa kita harus memiliki migrasi mundur, kita
bermigrasi dari satu node khusus sebelum rilis . Hanya dengan begitu kita akan memulai semua node kita selama rilis. Jadi kami memecahkan masalah ini.
Masalah ketiga adalah
kurangnya data di Fallback Cache . Mungkin kita "mundur" metode, itu harus menyimpan data historis selama setahun yang lalu, tetapi pada kenyataannya kita meluncurkannya kemarin.
Masalahnya diselesaikan dengan pemanasan . Kami menggunakan status Paksa dan meluncurkan node khusus yang tidak akan berkomunikasi dengan pengguna nyata. Mereka akan mengambil semua kunci yang mungkin kami asumsikan dan akan menghangatkan cache dalam lingkaran. Pemanasan berlangsung sangat cepat agar tidak membunuh backend yang kita baca.
Aplikasi penskalaan, backend, data besar, dan frontend - Scala cocok untuk semua ini. 26 November, kami mengadakan konferensi profesional untuk pengembang Scala . Gaya, pendekatan, lusinan solusi untuk masalah yang sama, nuansa menggunakan pendekatan lama dan terbukti, praktik pemrograman fungsional, teori kosmonotika fungsional radikal - kita akan membicarakan semua ini di konferensi. Ajukan laporan jika Anda ingin membagikan pengalaman Scala Anda sebelum 26 September, atau pesan tiket Anda .