Hai Tim analitik Ad-hoc Big Data Terhubung dari X5 Retail Group.
Dalam artikel ini, kita akan berbicara tentang metodologi pengujian A / B kami dan tantangan yang kita hadapi setiap hari.
Big Data X5 mempekerjakan sekitar 200 orang, termasuk 70 tanggal Ilmuwan dan tanggal analis. Bagian utama kami bergerak dalam produk spesifik - permintaan, bermacam-macam, kampanye promosi, dll. Selain mereka, ada tim analisis Ad-hoc kami yang terpisah.
Kami adalah:
- kami membantu unit bisnis dengan permintaan analisis data yang tidak sesuai dengan produk yang ada;
- kami membantu tim produk jika mereka membutuhkan tangan ekstra;
- Kami terlibat dalam pengujian A / B - dan ini adalah fungsi utama tim.
Situasi di mana kami bekerja sangat berbeda dari tes A / B pada umumnya. Biasanya, teknik ini dikaitkan dengan metrik online dan online: bagaimana perubahan memengaruhi konversi, retensi, RKT, dll. Sebagian besar eksperimen terkait dengan perubahan antarmuka: menata ulang spanduk, mengecat ulang tombol, mengganti teks, dll.
Bisnis X5 berbeda - tinggal 15.000 toko offline dengan berbagai format, didistribusikan di seluruh negeri. Fitur ini memberlakukan batasan tertentu. Pertama, serangkaian metrik yang dapat diuji sangat bervariasi, dan kedua, pembatasan eksperimen diberlakukan. Tugas mengubah desain etalase toko online tidak sebanding dalam hal tenaga kerja dengan tugas mengubah urutan departemen di toko offline.
Perusahaan memiliki tim yang terlibat dalam program loyalitas dan pilot mereka paling dekat dengan ide klasik pengujian A / B. Pertanyaan-pertanyaan yang datang kepada kami sangat tidak lazim untuk tes A / B "biasa". Sebagai contoh:
- Bagaimana kinerja keuangan toko akan berubah jika saya mengubah urutan departemen Sosis dan Kue?
- Bagaimana model churn pelanggan mempengaruhi hasil keuangan?
- Bagaimana pengaturan postamates akan mempengaruhi kinerja toko?
Pelanggan percaya bahwa perubahan tertentu akan secara positif mempengaruhi salah satu indikator (kami akan membicarakannya nanti). Tugas kami adalah membantu mereka memvalidasi hipotesis mereka berdasarkan data.
Metrik
Indikator apa yang kami uji?
RTO ,
pengecekan rata-rata dan
lalu lintas adalah kata yang paling sering digunakan di sayap ruang terbuka kami.
- RTO (omset ritel) - jumlah uang yang diperoleh toko.
Salah satu metrik utama untuk bisnis dan yang paling sulit untuk diuji.
Omset harian toko diukur dalam jutaan rubel. Dengan demikian, penyebaran indikator diukur dalam setidaknya ribuan rubel. Rumus yang rumit dan panjang untuk menentukan ukuran sampel mengatakan bahwa semakin besar varians, semakin banyak data yang diperlukan untuk kesimpulan yang berarti. Untuk mengetahui efeknya bahkan pada persepuluh persen dengan dispersi PTO yang begitu besar, pilot di toko harus menghabiskan waktu enam bulan.
Bayangkan reaksi dewan, jika pada pertemuan dengan mereka mengatakan bahwa pilot perlu menghabiskan enam bulan, atau bahkan setahun di semua toko? =)
Kami memiliki dua pendekatan standar.
Pendekatan pertama: kami tidak mempertimbangkan RTO dari seluruh toko, tetapi semacam kategori produk. Misalnya, sebagai hasil dari penataan ulang dua bagian di toko ("Kue" dan "Sosis"), peningkatan PTO di kedua kategori diharapkan. RTO satu kategori jauh lebih kecil daripada RTO seluruh toko, oleh karena itu, dispersinya lebih rendah. Dalam hal ini, kami berharap pilot dalam kategori ini terisolasi dari kategori yang tersisa.
Pendekatan kedua: kami mengambil sampel waktu. Unit pengamatan bukan PTO toko untuk seluruh pilot, tetapi PTO per minggu atau hari. Dengan demikian, kami meningkatkan jumlah pengamatan, sambil mempertahankan varians dari data mentah.
- Cek rata-rata , atau RTO / jumlah cek - jumlah rata-rata uang dalam satu cek.
Sebagian dari perubahan itu bertujuan membuat orang membeli lebih banyak, jadi kami menguji RTO / jumlah cek, atau rata-rata cek, jika kami menggambar analogi dengan metrik biasa.
Kesulitan dalam menguji metrik ini terkait dengan kekhususan ritel. Misalnya, dengan peluncuran uji coba promosi "3 untuk harga 2", seseorang yang berencana membeli satu produk akan membeli tiga, dan jumlah cek akan meningkat. Tetapi bagaimana jika ia kemudian menjadi kurang mungkin pergi ke toko dan pilotnya sebenarnya tidak begitu sukses?
- Lalu lintas - jumlah cek di toko untuk periode waktu tertentu.
Untuk menghindari kesimpulan yang salah saat menguji hipotesis yang memengaruhi pemeriksaan rata-rata, kami secara bersamaan melihat perubahan lalu lintas. Kami tidak dapat melacak secara langsung berapa banyak orang yang datang ke toko tidak semua pengunjung adalah klien dari program loyalitas, oleh karena itu untuk pengujian A / B setiap cek adalah "kunjungan unik" ke klien. Dengan analogi dengan PTO, kami mempertimbangkan lalu lintas dalam berbagai interval waktu: lalu lintas per hari, lalu lintas per jam.
Keterkaitan pengecekan rata-rata dan lalu lintas sangat penting: dapatkah pilot meningkatkan pengecekan rata-rata, tetapi mengurangi lalu lintas dan pada akhirnya tidak mengarah pada peningkatan PTO, tetapi pada penurunannya? Bisakah pilot membantu meningkatkan lalu lintas tanpa mengubah tagihan rata-rata?
- Margin - perbedaan antara harga suatu produk dan biayanya
Ada pilot dalam kerangka yang kita ubah harga barang - untuk beberapa, harga telah meningkat, untuk beberapa sebaliknya. Karena kita tidak memengaruhi biaya produksi, dengan mengubah harga, kita mengubah margin barang. Pilot seperti itu dapat meningkatkan lalu lintas, dan meningkatkan rata-rata pemeriksaan. Tetapi apakah ini berarti pilot berhasil dan layak mengubah harga di semua toko jaringan? Tidak, bisa saja terjadi bahwa orang mulai membeli barang dengan margin negatif atau kecil lebih sering dan meninggalkan barang dengan margin tinggi. Oleh karena itu, tidak selalu peningkatan RTO diikuti oleh peningkatan total margin, oleh karena itu, ada baiknya menguji indikator ini secara terpisah.
Nah, katakanlah kita telah memutuskan metrik target. Pertanyaan-pertanyaan berikut:
- Apa efek ukuran yang akan diterima pelanggan?
- Efek apa yang sebenarnya dapat dideteksi dalam percobaan?
- Berapa lama percobaan berlangsung?
- Kelompok mana?
Ringkasan Eksperimen
Tes A / B yang dilakukan pada pengguna online memiliki keuntungan yang signifikan - mereka memiliki kemampuan generalisasi yang tinggi. Dengan kata lain, kesimpulan yang diperoleh selama percobaan dapat diskalakan ke semua pengguna. Kemampuan generalisasi dijamin oleh pengaturan percobaan: kelompok kontrol dan uji dibentuk secara acak, hampir persis kedua grup dari distribusi yang sama, Anda dapat menangkap banyak lalu lintas di kedua grup - akan ada anggaran.
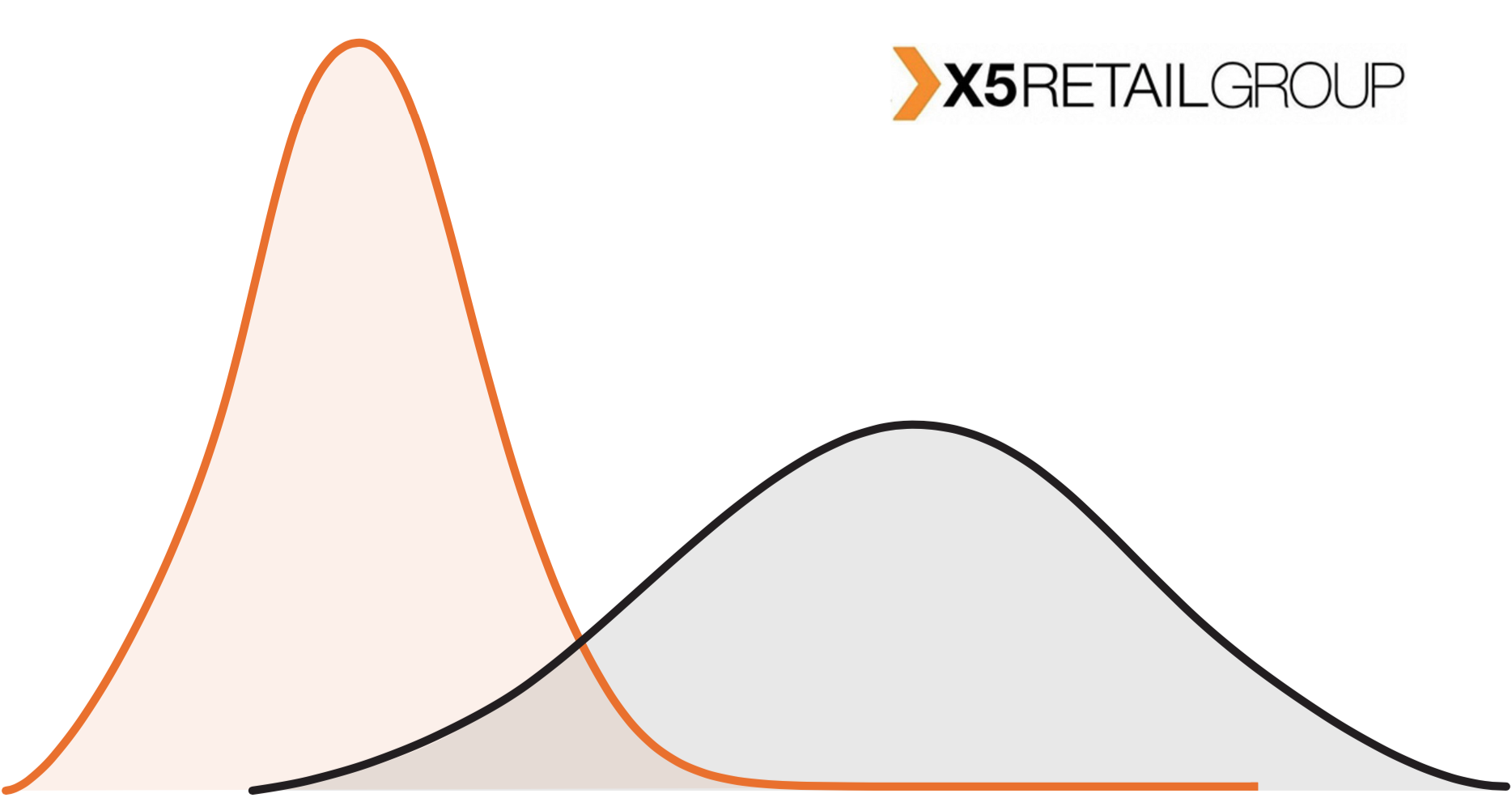
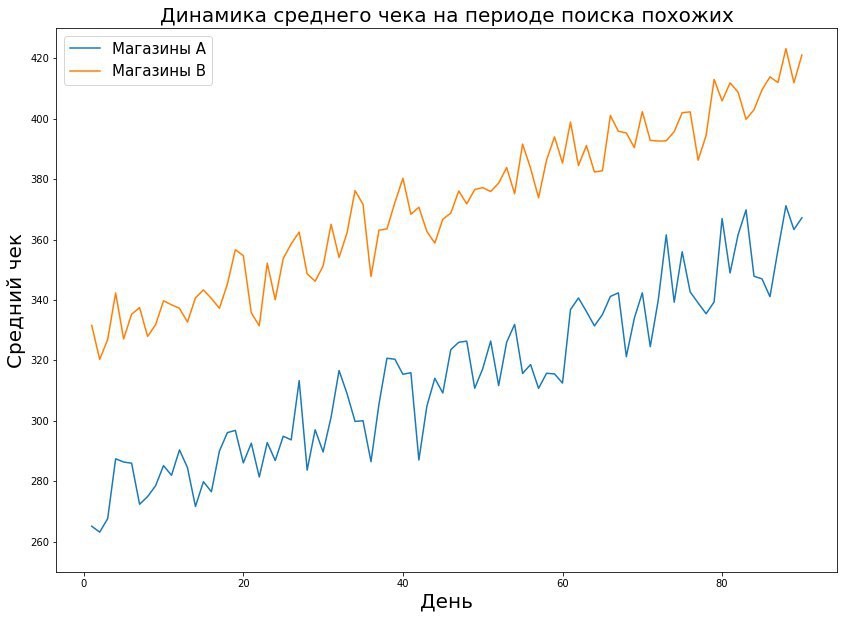
Dalam hal ritel offline, tidak ada pengaturan ini yang berfungsi. Pertama, ada batasan jumlah toko. Kedua, toko sangat berbeda satu sama lain. Toko Perekrestok di area perumahan dan Perekrestok di dekat pusat bisnis, pada kenyataannya, adalah objek yang sangat berbeda dari distribusi yang berbeda.

Pada grafik kita melihat bahwa toko-toko dari kelompok uji berbeda dari toko-toko seluruh jaringan. Ini adalah situasi yang cukup khas: di rantai toko Pyaterochka terletak tidak hanya di kota, tetapi juga di pemukiman kecil. Pilot besar paling sering diadakan di kota-kota. Apa pun efek yang kami tangkap, penskalaan di seluruh jaringan salah.
Efek total
Є dari pilot yang kami evaluasi dengan rumus:

a adalah area perpotongan dari distribusi kelompok pilot dan semua toko dalam jaringan.
Perhatikan bahwa ini bukan konsekuensi dari undang-undang statistik, tetapi asumsi kami tentang bagaimana logis untuk mempertimbangkan efek kumulatif.
Opsi yang ideal adalah merekrut sampel yang representatif ke kelompok uji, yaitu toko-toko yang benar-benar mencerminkan seluruh keadaan jaringan. Tetapi keterwakilan mengarah pada heterogenitas sampel, karena toko-toko dengan PTO rendah atau tinggi akan dijadikan sampel.
Ukuran grup, durasi pilot, dan efek minimal yang terdeteksi
Dan sekarang untuk hal yang paling penting - ukuran efek dan durasi pilot. Sebagai aturan, kita dihadapkan pada satu dari tiga situasi:
- pelanggan memiliki batas waktu untuk pilot dan jumlah toko tempat Anda dapat bekerja;
- pelanggan tahu apa ukuran efek yang ia harapkan untuk diterima dan meminta untuk menunjukkan jumlah toko yang dibutuhkan pilot (dan kemudian toko sendiri);
- pelanggan terbuka untuk penawaran kami.
Tidak dapat dikatakan bahwa skenario mana pun lebih sederhana, karena dalam hal apa pun kami menyiapkan tabel efek-kesalahan.
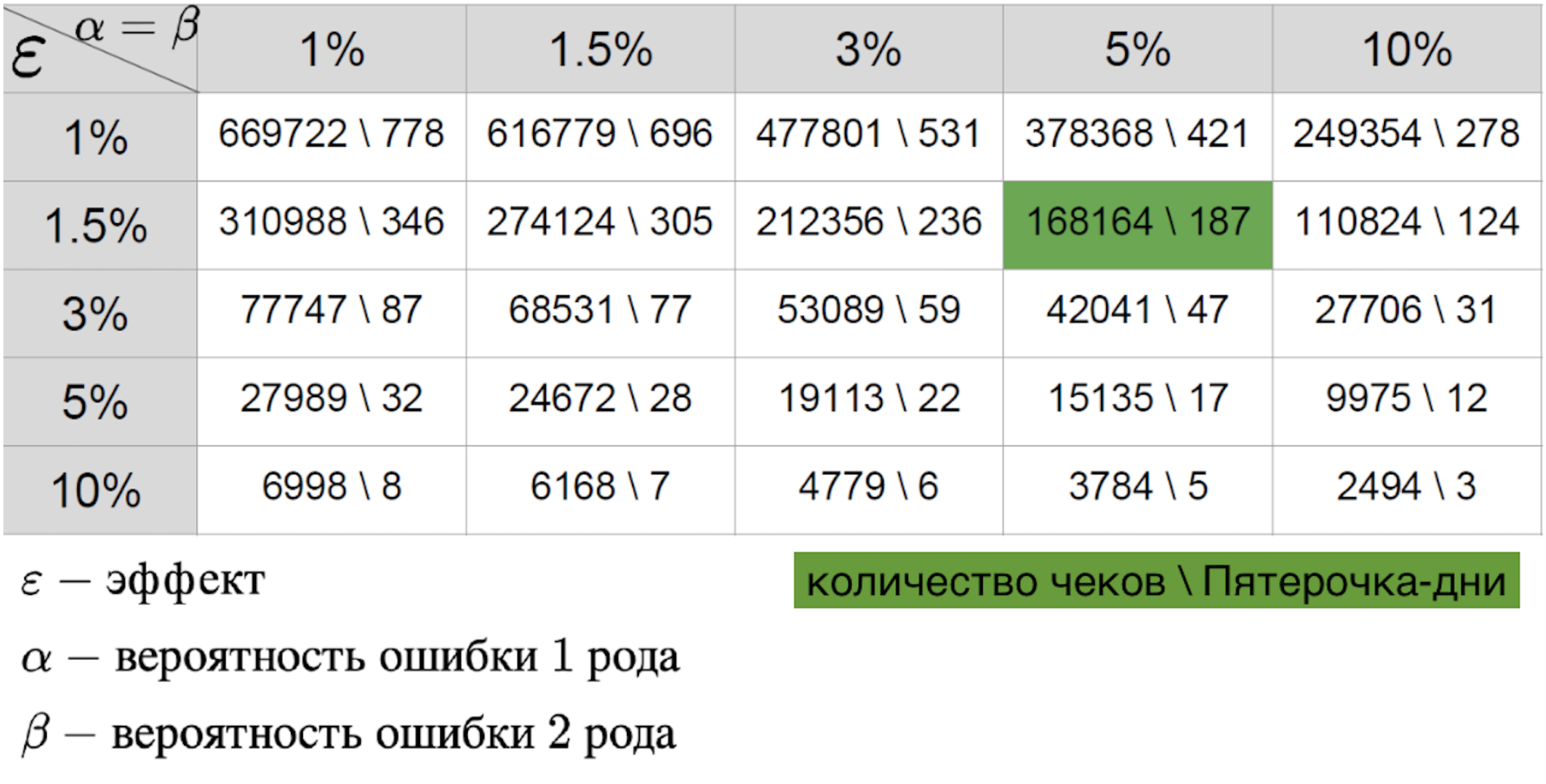
Penting baginya:
- kesalahan jenis pertama - probabilitas melihat efeknya ketika tidak ada;
- kesalahan jenis kedua - probabilitas melewatkan efek ketika itu;
- ukuran efek yang diharapkan dilihat oleh pilot yang sukses.
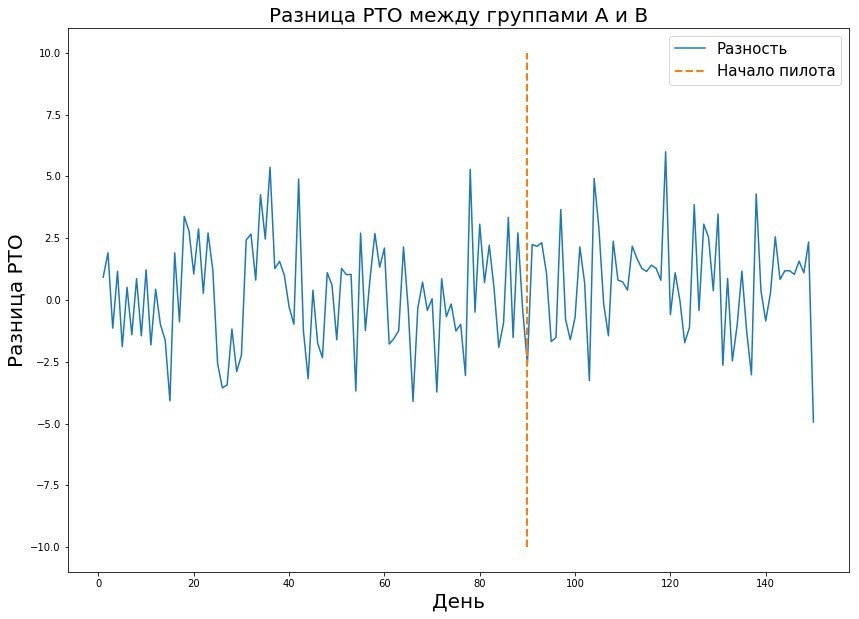
Kombinasi ketiga parameter ini memungkinkan Anda untuk menghitung durasi pilot yang diperlukan. Nilai dalam tabel adalah ukuran sampel - dalam hal ini, jumlah tanda terima atau metrik rata-rata di toko per hari, yang diperlukan untuk melakukan uji coba. Jika kita berbicara tentang dunia nyata, maka biasanya kemungkinan kesalahan jenis pertama dan kedua adalah 5-10 persen. Seperti dapat dilihat dari tabel, dengan kesalahan tetap seperti itu, kita perlu 421 Pyaterochka-hari untuk menangkap efek satu persen. Tampaknya angkanya cukup bagus - lagipula, 421 Pyaterochka-hari adalah pilot di 40 toko selama 10 hari. Namun, ada satu "tetapi" - ada sangat sedikit pilot yang benar-benar mengharapkan efek satu persen. Biasanya kita berbicara tentang persepuluh persen. Mengingat bahwa RTO diukur dalam miliaran, sepersepuluh persen dari efek pilot yang berhasil dapat memberikan peningkatan besar dalam pendapatan. Karena itu, saya ingin mengukur efek sekecil apa pun. Tetapi semakin kecil ukuran efek, semakin tinggi kesalahan jenis kedua. Ini bisa dimengerti: efek kecilnya mirip dengan noise acak dan jarang akan dianggap sebagai penyimpangan nyata dari norma. Ini terlihat jelas pada grafik di bawah ini, di mana kami ingin menangkap efek kecil dalam data dengan varian besar.

Pengujian A / A
Sebelum pilot dimulai, Anda perlu memutuskan kelompok uji dan kontrol. Pelanggan mungkin atau mungkin tidak memiliki kelompok pilot. Kami siap membantunya dalam kedua kasus dengan meminta pembatasan - misalnya, toko harus ketat dari tiga wilayah tertentu.
Misalkan kita telah memilih dalam beberapa cara kelompok uji dan kontrol. Bagaimana memastikan bahwa grup yang dipilih baik dan Anda benar-benar dapat melakukan pengujian A / B pada mereka? Tampaknya semuanya terdengar harmonis: kami mencetak jumlah pengamatan yang diperlukan, menurut rumus kami dapat menangkap efek 0,7%, kami menemukan toko yang sama. Apa yang sekarang tidak cocok untuk kita?
Sayangnya, banyak fakta serius:
- elemen sampel tidak dari distribusi yang sama - sampel kami adalah campuran pengamatan dari toko yang berbeda, dan setiap toko memiliki distribusi sendiri.
- unsur-unsur sampel tidak independen - dalam sampel ada banyak pengamatan dari satu toko, masing-masing, ada hubungan di antara mereka;
- kesetaraan sarana tidak dijamin dengan tidak adanya pilot - yaitu kami sama sekali tidak yakin bahwa jika tidak ada pilot, statistik toko tidak akan berbeda.
Semua masalah ini tidak diperhitungkan dalam perhitungan rumus untuk memilih jumlah pengamatan tergantung pada kesalahan dan efek. Untuk memahami sejauh mana dampak dari masalah di atas, kami melakukan pengujian A / A. Bahkan, ini adalah simulasi dari seluruh pilot di toko pada saat tidak ada pilot di toko. Periode ini disebut pra-pilot.

Selama periode pra-pilot, kami mengulangi tiga langkah berkali-kali:
- pemilihan kelompok serupa;
- pengujian kesetaraan dalam dua kelompok;
- menambah efek ke kelompok uji dan menguji sarana untuk kesetaraan.

Cocok dengan grup serupa
Kami tidak menciptakan sepeda, jadi kami mencari kelompok serupa dengan metode lama yang baik dari tetangga terdekat. Strategi menghasilkan fitur untuk toko adalah seni terpisah. Kami menemukan tiga metode kerja:
- Setiap toko dijelaskan oleh vektor fitur sesuai dengan metrik yang kami uji. Misalnya, ketika memeriksa rata-rata cek, kami menggambarkan rata-rata cek harian selama 8 minggu - kami mendapatkan 56 tanda untuk toko. Lalu kami mengambil jarak Euclidean antara tanda-tanda sepasang toko.
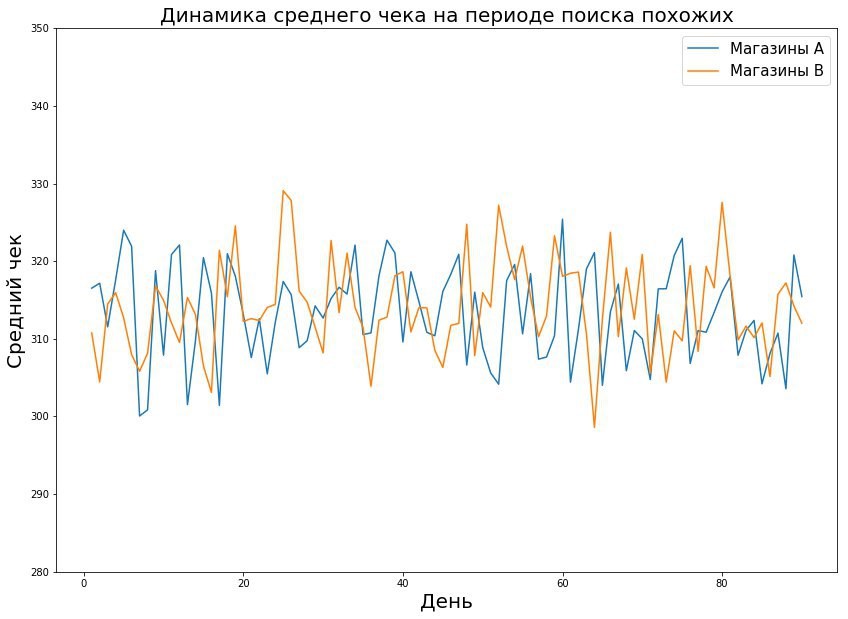
- Temukan toko yang serupa dalam dinamika. Toko mungkin berbeda dalam nilai metrik absolut, tetapi bertepatan dalam tren - dan dengan manipulasi matematika tertentu, toko ini dapat dianggap sama.
- Prediksi kinerja toko selama periode uji coba (di masa depan) dan pilih yang serupa berdasarkan itu - tetapi di sini kita membutuhkan oracle yang dapat memprediksi kinerja untuk pilot dengan cukup akurat.
Kami berpegang pada hipotesis yang sangat sederhana: jika toko serupa sebelum pilot, maka seandainya tidak ada perubahan pilot, mereka akan tetap serupa.
Anda dapat memperhatikan bahwa bahkan dalam tiga metode kerja ini ada banyak aspek yang dapat bervariasi: jumlah hari / minggu di mana fitur dipertimbangkan, metode untuk menilai dinamika indikator, dll.
Tidak ada pil universal, dalam setiap percobaan kami melewati berbagai opsi berdasarkan tujuan kami. Tapi ini sangat sederhana: temukan metode untuk memilih tetangga terdekat yang memberikan kesalahan yang masuk akal dari jenis pertama dan kedua. Dari mana mereka berasal, kami beri tahu lebih lanjut.
Menguji persamaan cara, atau kesalahan jenis metode pertama
Ingatlah bahwa pada titik ini kita:
- ditentukan dengan pelanggan ukuran efek dan durasi pilot
- menjelaskan esensi kesalahan jenis pertama dan kedua
- membangun metode untuk memilih grup yang serupa
Tujuan dari tahap ini adalah untuk memastikan bahwa metode yang kami pilih di Bagian 3 menemukan kelompok-kelompok seperti itu sebelum pilot memulai indikator (RTO, pengecekan rata-rata, lalu lintas) di toko-toko ini tidak berbeda secara statistik.
Dalam siklus, kami memilih grup yang dipilih berulang kali untuk kesetaraan dengan beberapa jenis uji statistik dan bootstrap. Jika proporsi kesalahan (mis., Grup tidak sama satu sama lain) lebih tinggi dari ambang, maka metode ditolak dan yang baru dipilih. Jadi sampai kita mencapai ambang kesalahan yang diinginkan.
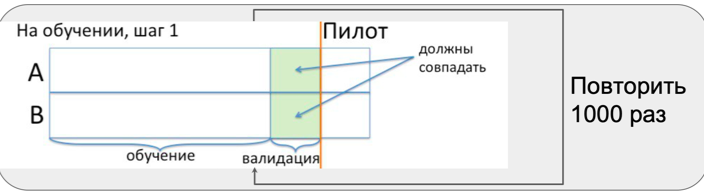
Penting untuk mengetahui seberapa sering kita menangkap efek ketika tidak ada, yaitu apakah metode seleksi kami merespons perbedaan acak antara toko atau tidak.
Menambahkan efek, atau kesalahan metode jenis kedua
Sebuah pertanyaan yang masuk akal, tetapi bukankah kita melatih kembali diri kita sedemikian rupa sehingga kita juga akan merasakan efek nyata sebagai kebisingan dan mengabaikannya? Dengan kata lain, apakah kita dapat mendeteksi efek saat itu?
Setelah memastikan pada langkah terakhir bahwa kelompok-kelompok tersebut bertepatan, kami menambahkan efek buatan ke salah satu kelompok, yaitu Kami menjamin bahwa pilot berhasil dan efeknya seharusnya.
Kali ini tujuannya adalah untuk mengetahui seberapa sering hipotesis kesetaraan ditolak, yaitu tes ini mampu membedakan antara dua kelompok. Kesalahan dalam hal ini adalah mengasumsikan bahwa kelompok-kelompok itu sama. Kami menyebut kesalahan ini sebagai kesalahan jenis kedua.
Sekali lagi dalam siklus kami menguji kesetaraan kelompok kontrol dan kelompok uji "berisik". Jika kami melakukan kesalahan yang cukup jarang, maka kami percaya bahwa metode pemilihan grup telah melewati validasi. Ini dapat digunakan untuk memilih grup dalam periode uji coba dan memastikan bahwa jika uji coba memberikan efek, kami akan dapat mendeteksinya.

Tentang heterogenitas
Kami telah menyebutkan bahwa heterogenitas data adalah salah satu musuh terburuk yang kami lawan. Inhomogeneities muncul dari berbagai akar penyebab:
- heterogenitas belanja - setiap toko memiliki nilai metrik rata-rata sendiri (di Moskow toko RTO dan lalu lintas jauh lebih banyak daripada di toko desa)
- heterogenitas berdasarkan hari dalam seminggu - distribusi lalu lintas yang berbeda dan pemeriksaan rata-rata yang berbeda pada hari yang berbeda dalam seminggu: lalu lintas pada hari Selasa tidak terlihat seperti lalu lintas pada hari Jumat
- heterogenitas dalam cuaca - orang pergi berbelanja secara berbeda dalam kondisi cuaca yang berbeda
- heterogenitas dalam tahun - lalu lintas di bulan-bulan musim dingin berbeda dengan lalu lintas di musim panas - ini harus diperhitungkan jika pilot berlangsung beberapa minggu.
Inhomogeneity meningkatkan varians, yang, sebagaimana disebutkan di atas, dalam evaluasi toko PTO sudah sangat penting. Ukuran efek yang ditangkap secara langsung tergantung pada varians. Misalnya, mengurangi dispersi dengan faktor empat memungkinkan Anda mendeteksi efek setengah.
Dalam kasus yang paling sederhana, kami berjuang dengan heterogenitas linierisasi.
Misalkan kita memiliki pilot di dua toko selama tiga hari (ya, ini bertentangan dengan semua formula yang ditentukan tentang ukuran efek, tetapi ini adalah contoh). Rata-rata
RTO di toko masing-masing 200 ribu dan 500 ribu, sedangkan varians di kedua kelompok adalah 10.000, dan menurut semua pengamatan - 35.000
Setelah uji coba, rata-rata berada di 300 dan 600 kelompok dan varians masing-masing 10.000 dan 22.500, dan seluruh kelompok adalah 40.000.

Langkah sederhana dan elegan adalah untuk membuat linierisasi data, mis. kurangi dari setiap nilai periode rata-rata untuk yang sebelumnya.

Pada output, sampel: 100, 0, 200, -50, 100, 250. Dispersi pada periode uji coba berkurang 3 kali menjadi 13000.
Ini berarti bahwa kita dapat melihat efek yang jauh lebih halus daripada dengan nilai absolut aslinya.
Ini bukan satu-satunya cara untuk berurusan dengan heterogenitas. Kami akan berbicara tentang orang lain di artikel selanjutnya.
Pendekatan umum untuk pengujian A / B
Persiapan untuk pilot besar dan penilaian mereka melewati tim kami dan diuji secara menyeluruh.
Protokol kami:
- menerima informasi dari pelanggan tentang metrik dan efek yang diharapkan;
- tentukan ukuran kelompok dan durasi pilot;
- untuk mengembangkan suatu algoritma untuk distribusi toko oleh kelompok-kelompok;
- melakukan uji A / A antar kelompok dan memvalidasi algoritma ini;
- tunggu pilot menyelesaikan dan menghitung efeknya.
Tidak satu pun dari tahap-tahap ini berlalu tanpa kesulitan, masing-masing dari mereka memiliki fitur. Bagaimana kami menangani beberapa dari mereka, kami jelaskan dalam artikel ini. Selanjutnya, kita akan berbicara tentang ....
Tim
Pada akhirnya, saya ingin menyebutkan semua aktor:
- Valery Babushkin
- Alexander Sakhnov
- Denis Ivanov
- Sergey Demchenko
- Nikolay Nazarov
- Sergey Kabanov
- Yuri Galimullin
- Helen Tevanyan
- Vladislav Ladenkov
- Sergey Zakharov
- Cerita dengan mudah
- Alexander Belyaev
- Kismat Magomedov
- Egor Krashennikov
- Egor Karnaukh
- Svyatoslav Oreshin
- Yuri Trubitsyn