Mengapa kita bahkan ingin menulis kode kompetitif? Karena prosesor berhenti tumbuh di sepanjang dips dan mulai tumbuh di sepanjang core. Jumlah inti prosesor meningkat setiap tahun, dan kami ingin menggunakannya secara efektif. Go adalah bahasa yang dibuat untuk ini. Dokumentasi mengatakan demikian.
Kami mengambil Go, mulai menulis kode kompetitif. Tentu saja, kami berharap bahwa kami dapat dengan mudah mengekang kekuatan setiap inti prosesor kami. Benarkah begitu?
Nama saya Artemy. Posting ini adalah transkrip gratis pembicaraan saya dengan GopherCon Russia. Itu muncul sebagai upaya untuk memberikan dorongan kepada orang-orang yang ingin mengetahui cara menulis kode yang baik dan kompetitif.
Video dari konferensi GopherCon Russia
Model interaksi
Untuk memahami apakah Go benar-benar membuatnya lebih mudah bagi kami, mari kita lihat dua model interaksi: Memori Bersama dan Passing Pesan .

Memori Bersama adalah tentang memori bersama yang digunakan beberapa utas untuk bertukar data. Akses ke memori perlu disinkronkan. Sinkronisasi ini biasanya dilaksanakan oleh beberapa jenis kunci. Pendekatan ini dianggap komunikasi implisit.
Message Passing mengatakan bahwa kami akan berinteraksi secara eksplisit, dan untuk ini kami akan menggunakan saluran di mana kami akan mengirim pesan. CSP ( Communicating Sequential Processes ) dan Actor Model didasarkan pada pendekatan ini.

Rob Pike , yang merupakan bapak pendiri Go, mengatakan bahwa Anda harus meninggalkan pemrograman tingkat rendah menggunakan Memori Bersama dan menggunakan pendekatan Message Passing . Pendekatan ini akan membantu Anda menulis kode lebih mudah, lebih efisien dan, yang paling penting, dengan lebih sedikit bug. Go memilih pendekatan CSP . Pendekatan yang sama sangat memengaruhi perkembangan bahasa seperti Erlang.
Pertanyaan: Apakah benar bahwa jika kita mengambil Go, semuanya akan baik-baik saja?

Saya menemukan sebuah penelitian di mana tablet ini ditemukan. Tablet menunjukkan alasan dan jumlah bug yang terkait dengan kunci. Kolom pertama menunjukkan produk yang dibawa ke dalam penelitian. Ini adalah produk paling populer yang ditulis dalam Go. Kolom Memori Bersama menunjukkan jumlah bug yang muncul karena penggunaan yang tidak benar dari Memori Bersama, dan kolom Passing Pesan, masing-masing, menunjukkan jumlah bug karena Passing Pesan.
Yang paling penting pada plat ini adalah garis Total . Jika Anda melihatnya, Anda akan melihat bahwa ada lebih banyak bug ketika menggunakan Passing Pesan daripada saat menggunakan Memori Bersama . Saya yakin bahwa orang-orang yang menulis Kubernetes, Docker atau etcd adalah pengembang yang cukup berpengalaman, tetapi bahkan Message Passing mereka tidak menyelamatkan dari kesalahan, dan tidak ada yang lebih sedikit daripada kesalahan ini daripada dengan Memori Bersama.
Jadi hanya mengambil Go dan mulai menulis kode bebas kesalahan akan gagal.
Konkurensi dan paralelisme
Ketika kita mulai berbicara tentang pengembangan multi-utas, kita perlu memperkenalkan konsep-konsep seperti Konkurensi dan Paralelisme . Di dunia Go, ada ungkapan "Konkurensi bukan Paralelisme . " Intinya adalah bahwa Concurrency adalah tentang desain, yaitu, bagaimana kami merancang program kami. Paralelisme hanyalah cara untuk mengeksekusi kode kita.

Jika kami memiliki beberapa utas instruksi yang dieksekusi secara bersamaan, maka kami mengeksekusi kode secara paralel. Paralelisme membutuhkan kompetisi. Tidak akan mungkin untuk memparalelkan suatu program tanpa desain yang kompetitif, sementara daya saing tidak memerlukan paralelisme, karena suatu program yang dapat berjalan pada banyak inti, pada kenyataannya, dapat berjalan pada satu inti.
Go adalah bahasa yang membantu kita menulis program kompetitif, membantu kita membangun desain. Ini memungkinkan Anda untuk berpikir sedikit tentang hal-hal tingkat rendah.
Hukum Amdahl
Kami ingin memanfaatkan inti prosesor, kami menulis beberapa kode untuk ini. Tetapi muncul pertanyaan: peningkatan produktivitas seperti apa yang kita dapatkan dengan peningkatan jumlah core. Jadi, akselerasi yang bisa kita dapatkan, justru dibatasi oleh hukum Amdal .
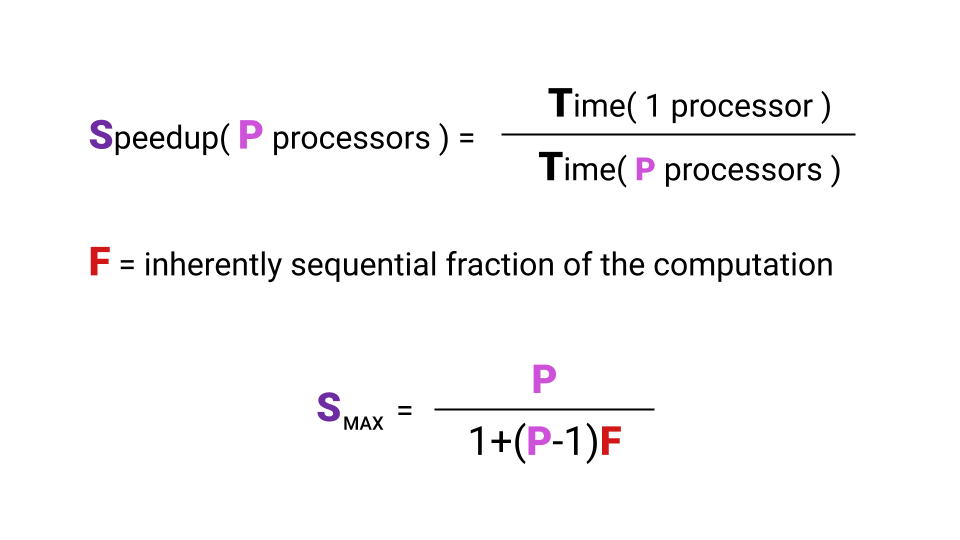
Apa itu akselerasi? Akselerasi adalah waktu ketika suatu program berjalan pada satu prosesor dibagi dengan waktu ketika suatu program berjalan pada prosesor P. Huruf F ( Fraksi ) menunjukkan bagian dari program yang harus dieksekusi secara berurutan. Dan di sini bahkan tidak perlu mempelajari rumusnya, yang terpenting adalah mencatat bahwa akselerasi maksimum yang kita dapatkan dengan peningkatan jumlah core tergantung pada F. Lihatlah grafik untuk memvisualisasikan hubungan ini.
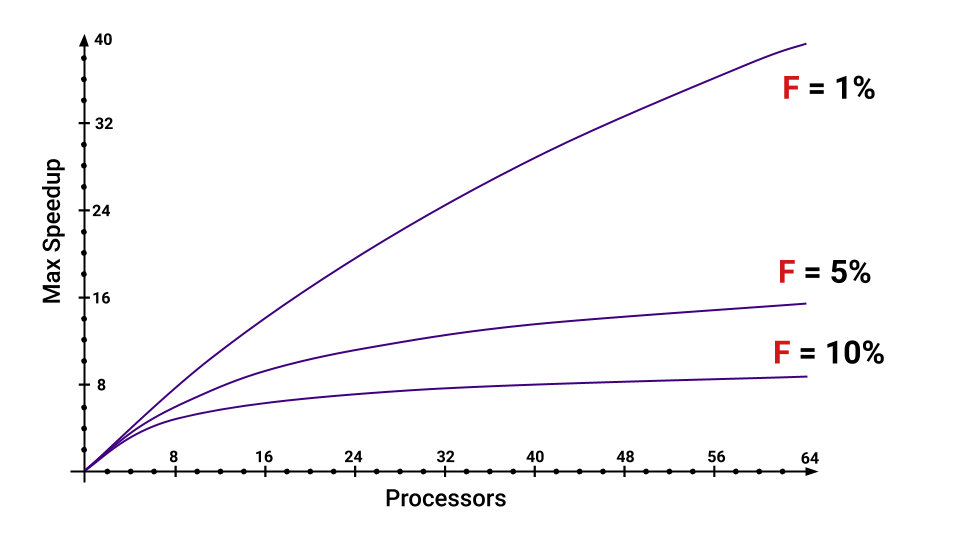
Bahkan jika kita hanya memiliki 5% dari program yang akan dieksekusi secara berurutan, akselerasi maksimum yang kita dapatkan akan sangat berkurang dengan peningkatan jumlah core. Anda dapat memperkirakan bagian apa yang meningkatkan F.
CPU Bound vs I / O Bound
Tidak selalu masuk akal untuk menggunakan multithreading. Pertama, Anda perlu melihat jenis beban. Ada dua jenis beban: CPU Bound dan I / O Bound . Perbedaannya adalah bahwa dengan CPU Bound kita dibatasi oleh kinerja prosesor, dan dengan I / O Bound kita dibatasi oleh kecepatan subsistem I / O kita. Bahkan kecepatan, tetapi waktu menunggu untuk jawaban. Pergi online - menunggu jawaban, pergi ke disk - lagi menunggu jawaban. Apa bedanya, berapa inti yang ada, jika sebagian besar waktu kita menunggu jawaban?
Oleh karena itu, satu inti atau seribu, kami tidak akan mendapatkan peningkatan kinerja di bawah beban I / O Bound. Tetapi jika kita memiliki CPU Bound load, maka ada peluang untuk mendapatkan akselerasi saat memparalelkan program kita.
Meskipun ada beberapa situasi ketika CPU Bound memuat, ia sebenarnya merosot menjadi I / O Bound. Misalnya, jika kita ingin mengambil dan menjumlahkan semua elemen dari array besar, apa yang akan kita lakukan? Kami akan menulis siklus, semuanya akan berhasil. Kemudian kita berpikir: “Jadi kita memiliki banyak inti. Mari kita ambil saja, bagi array menjadi potongan-potongan dan sejajarkan semuanya. " Apa hasilnya?
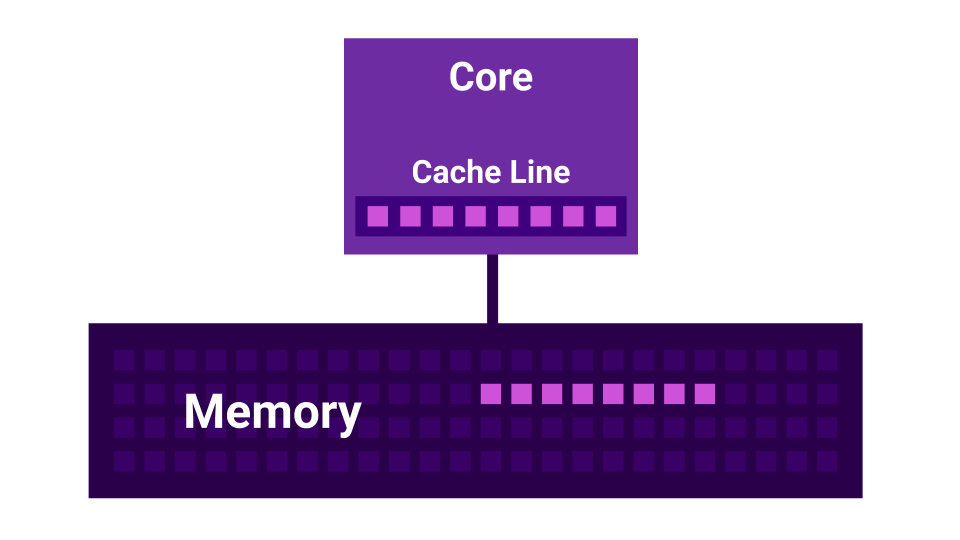
Hasilnya adalah situasi di mana prosesor kami memproses data lebih cepat daripada yang mereka dapat dari memori. Dalam hal ini, sebagian besar waktu kita akan menunggu data dari memori, dan beban, yang tampaknya CPU Bound, sebenarnya ternyata adalah I / O Bound.
Berbagi salah
Apalagi ada cerita seperti False Sharing . Berbagi Palsu adalah situasi ketika kernel mulai saling mengganggu. Ada inti pertama, ada inti kedua, dan masing-masing dari mereka memiliki L1 Cache sendiri. L1 Cache dibagi menjadi beberapa baris ( Cache Line ) sebesar 64 byte. Ketika kami mendapatkan beberapa data dari memori, kami selalu mendapatkan tidak kurang dari 64 byte. Dengan mengubah data ini, kami menonaktifkan cache semua inti.

Ternyata jika dua core mengubah data yang sangat dekat satu sama lain ( pada jarak kurang dari 64 byte ), mereka mulai saling mengganggu, cache yang tidak valid. Dalam hal ini, jika program ditulis berurutan, itu akan bekerja lebih cepat daripada ketika menggunakan beberapa core yang saling mengganggu. Semakin banyak core, semakin rendah kinerjanya.
Penjadwal
Kami akan naik ke tingkat abstraksi berikutnya - ke perencana.
Ketika pekerjaan dimulai dengan kode kompetitif, penjadwal muncul. Go memiliki apa yang disebut penjadwal ruang-pengguna yang beroperasi pada goroutine . Sistem operasi juga memiliki penjadwal sendiri, yang beroperasi dengan utas sistem operasi . Dan bahkan prosesornya tidak begitu sederhana. Misalnya, prosesor modern memiliki prediksi cabang dan cara lain untuk merusak gambar indah kita tentang kelurusan linier dunia.
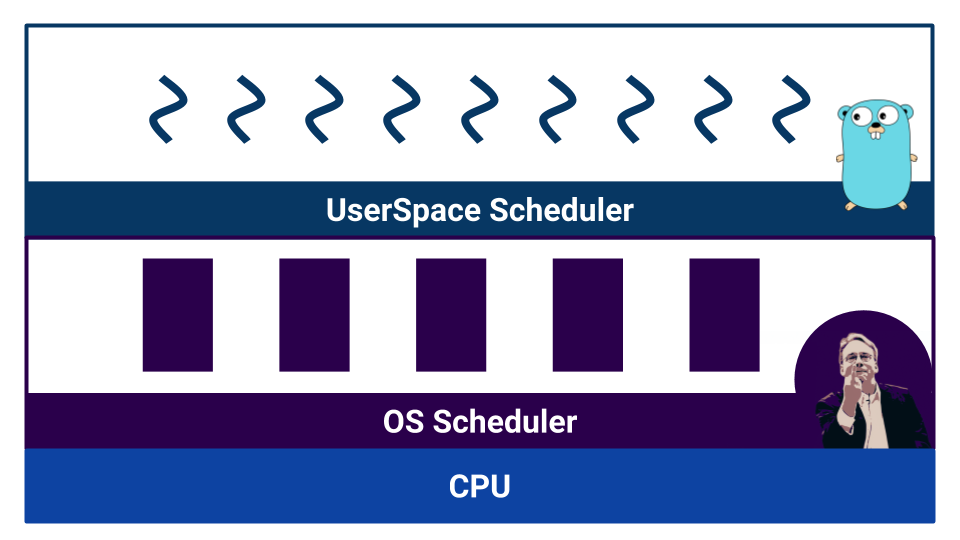
Penjadwal dibagi berdasarkan jenis multitasking. Ada multitasking kooperatif dan multitasking preemptive . Dalam kasus multitasking kooperatif , proses pelaksanaannya sendiri memutuskan kapan perlu mentransfer kontrol ke proses lain, dan dalam kasus multitasking yang ramai, ada komponen eksternal - penjadwal, yang mengontrol berapa banyak sumber daya yang dialokasikan untuk proses tersebut.

Multitasking kooperatif memungkinkan satu proses untuk "memonopoli" seluruh sumber daya CPU. Dalam multitasking preemptive, ini tidak akan terjadi, karena ada badan pengontrol. Tetapi dengan multitasking yang kooperatif, alih konteks lebih efisien, karena proses tahu pasti pada titik apa lebih baik untuk memberikan kontrol ke proses lain. Dalam multitasking preemptive, scheduler dapat menghentikan proses kapan saja - itu tidak terlalu efisien. Pada saat yang sama, dalam multitasking preemptive, kami dapat menyediakan sumber daya yang sama untuk setiap proses berkat penjadwal eksternal.
Sistem operasi menggunakan penjadwal berdasarkan multitasking preemptive, karena OS diperlukan untuk menjamin kondisi yang sama untuk setiap pengguna. Bagaimana dengan Go?
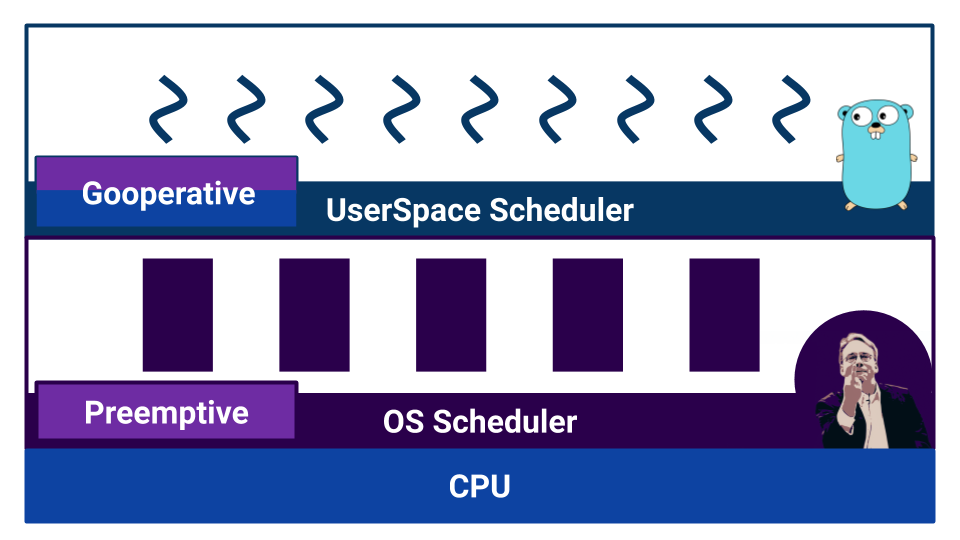
Jika kita membaca dokumentasi, kita mengetahui bahwa scheduler di Go adalah preemptive. Tetapi, ketika kita mulai mengerti, ternyata Go tidak memiliki scheduler sebagai komponen eksternal. Di Go, kompiler menetapkan titik switching konteks. Dan meskipun kita, sebagai pengembang, tidak perlu secara manual beralih konteks, kontrol beralih tidak dibawa ke komponen eksternal. Berkat ini, Go sangat efektif untuk mengganti satu goroutine ke yang lain. Tetapi kesalahpahaman tentang fitur-fitur dari pekerjaan seperti "perencana" dapat menyebabkan perilaku yang tidak terduga. Misalnya, apa yang akan dihasilkan kode ini?

Kode seperti itu akan membeku.
Mengapa Karena pada awalnya, menggunakan GOMAXPROCS , kami memaksa program untuk menggunakan hanya satu inti. Setelah itu, goroutine dimasukkan ke dalam antrian, di mana siklus yang tidak ada habisnya akan bekerja. Kemudian kita menunggu 500 ms dan mencetak x . Setelah waktu. time.Sleep goroutine akan benar-benar mulai, tetapi tidak akan ada jalan keluar dari loop tak terbatas, karena kompiler tidak akan meletakkan titik saklar konteks. Program membeku.
Dan jika kita menambahkan runtime.Gosched() di dalam loop, maka semuanya akan baik-baik saja, karena kita akan secara eksplisit menunjukkan bahwa kita ingin beralih konteks.
Fitur-fitur seperti itu juga perlu diketahui dan diingat.
Kami berbicara tentang pengalihan konteks, tetapi di mana Go biasanya memasukkan titik pengalih?

runtime.morestack() dan runtime.newstack() biasanya dimasukkan pada saat fungsi dipanggil. runtime.Goshed() kami dapat menyediakan sendiri. Dan tentu saja, pengalihan konteks terjadi selama kunci, kenaikan jaringan, dan panggilan sistem. Anda dapat melihat laporan ini oleh Kirill Lashkevich tentang topik ini . Sangat bagus, saya sarankan.
Mari kita melangkah lebih dekat ke kode. Kami akan melihat kesalahannya.
Kondisi balapan
Salah satu kesalahan paling populer yang kami lakukan adalah Race Condition . Intinya adalah ketika kita melakukan, misalnya, kenaikan, sebenarnya kita tidak melakukan satu operasi, tetapi beberapa: prosesor membaca data dari memori untuk mendaftar, memperbarui register dan menulis data ke memori.

Ketiga operasi ini tidak dilakukan secara atom. Oleh karena itu, penjadwal kapan saja, pada salah satu dari operasi ini, dapat mengambil dan menghentikan aliran kami. Ternyata tindakan belum selesai, dan karena ini kami menangkap bug.
Berikut adalah contoh kode semacam itu ( kenaikan tersebut segera diuraikan menjadi beberapa operasi ).

Penjadwal dapat mendahului utas pertama setelah baris pertama dieksekusi, dan utas kedua setelah memeriksa kondisinya. Dalam hal ini, kedua aliran akan jatuh ke bagian kritis, dan karena itu "kritis" - kedua aliran tidak dapat dimasukkan di sana secara bersamaan.
Kita dapat mengunci menggunakan sync.Mutex dari paket sync standar. Pemblokiran akses memungkinkan kami untuk secara eksplisit menunjukkan bahwa kode harus dijalankan oleh satu utas pada satu waktu. Dengan kode ini, kita mendapatkan apa yang kita butuhkan.

Kunci adalah operasi yang cukup mahal. Oleh karena itu, ada operasi atom pada level prosesor. Dalam hal ini, kenaikan dapat dibuat atom dengan menggantinya dengan operasi atomic . atomic.AddInt64 dari paket atomic .
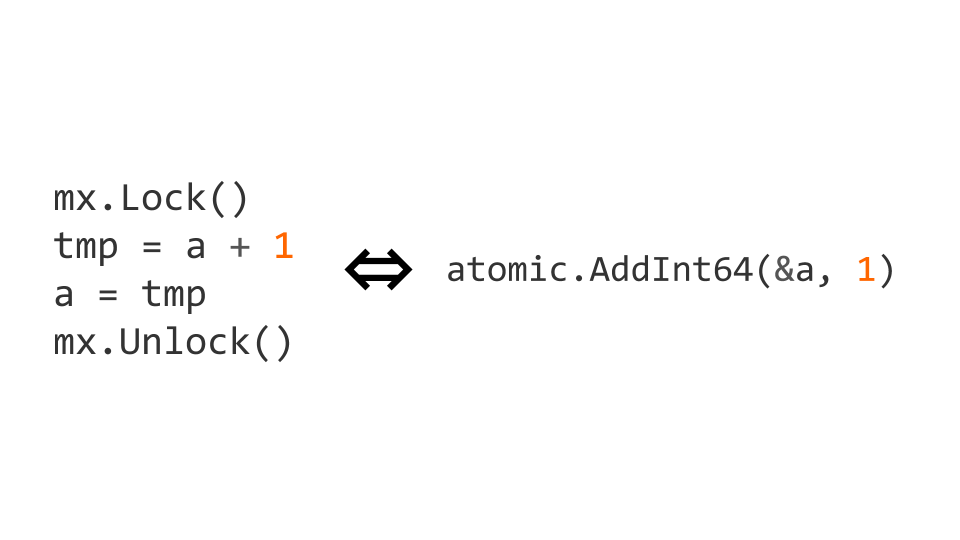
Jika kita mulai bekerja dengan instruksi atom, maka kita tidak hanya perlu menulis secara atom, tetapi juga membaca secara atom. Jika tidak, maka masalah akan muncul.
Optimalisasi - Apa yang Mungkin Salah?
Kunci itu bagus, tetapi bisa mahal. Atom cukup murah untuk tidak khawatir tentang kinerja.
Jadi kami mengetahui bahwa primitif sinkronisasi memperkenalkan overhead, dan memutuskan untuk menambahkan optimisasi - kami akan memeriksa bendera tanpa memperhatikan multithreading, dan kemudian memeriksa ulang menggunakan primitif sinkronisasi. Semuanya terlihat baik dan harus bekerja.

Semuanya baik-baik saja, kecuali bahwa kompiler sedang mencoba untuk mengoptimalkan kode kami. Apa yang dia lakukan Dia menukar instruksi tugas, dan kita mendapatkan perilaku yang tidak valid, karena kita done menjadi true sebelum nilai variabel "
Jangan mencoba melakukan optimasi seperti itu - karena mereka Anda akan mendapatkan banyak masalah. Saya menyarankan Anda untuk membaca spesifikasi The Go Memory Model dan sebuah artikel oleh Dmitry Vyukova ( @dvyukov ) Benign Data Races: Apa yang Mungkin Salah? untuk lebih memahami masalahnya.
Jika Anda benar-benar mengandalkan kinerja pada kunci - tulis kode bebas kunci, tetapi Anda tidak perlu melakukan akses yang tidak disinkronkan ke memori.
Jalan buntu
Masalah selanjutnya yang akan kita hadapi adalah Deadlock. Tampaknya semuanya cukup sepele di sini. Ada dua sumber daya, misalnya, dua Mutex . Di utas pertama, pertama-tama kita menangkap Mutex pertama, dan di utas kedua pertama-tama kita menangkap Mutex kedua. Selanjutnya kami ingin mengambil Mutex kedua di utas pertama, tetapi kami tidak akan dapat melakukan ini, karena sudah diblokir. Di utas kedua, kami akan mencoba untuk mengambil, masing-masing, Mutex pertama dan juga blok. Itu dia, Deadlock.
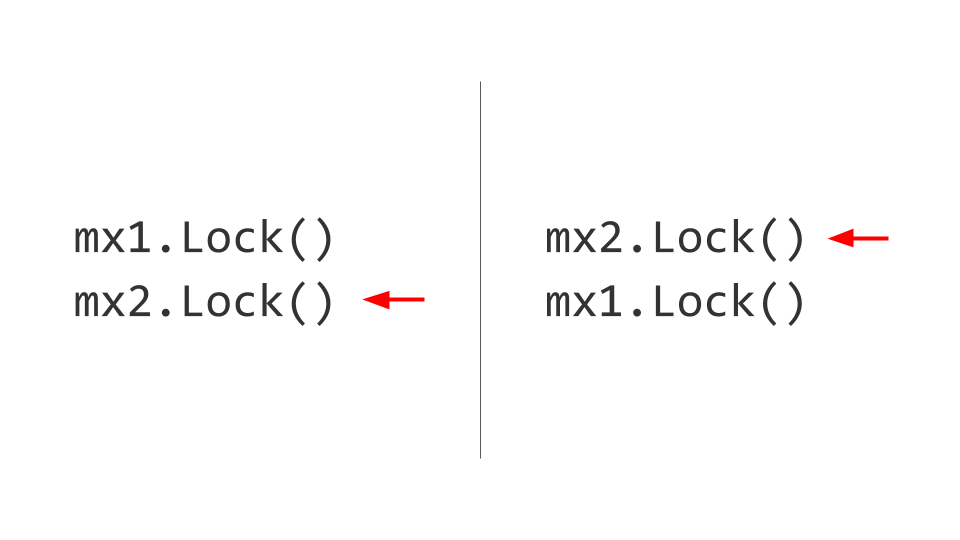
Tidak satu pun dari kedua utas ini yang dapat maju lebih jauh, karena keduanya akan menunggu sumber daya. Bagaimana ini diselesaikan? Kami bertukar kunci, dan kemudian tidak ada masalah yang muncul. Tentu saja, itu mudah untuk dikatakan, tetapi mempertahankan aturan ini sepanjang umur produk tidak mudah. Jika memungkinkan, lakukan - ambil dan berikan kunci dalam urutan yang sama .
Tampaknya pengembang yang berpengalaman tidak menemukan kesalahan seperti itu, tetapi di sini adalah contoh jalan buntu dari kode proyek, dll.

Di sini tangkapan utamanya adalah bahwa menulis ke saluran yang tidak disadap menghalangi, untuk menulis, Anda memerlukan pembaca di sisi lain. Mengambil mutex, utas pertama menunggu pembaca muncul. Utas kedua tidak lagi dapat menangkap mutex. Jalan buntu
Saya menyarankan Anda untuk mencoba game yang menarik The Deadlock Empire . Dalam permainan ini, Anda bertindak sebagai penjadwal yang harus mengalihkan konteks untuk mencegah kode dieksekusi dengan benar.
Semacam masalah
Masalah apa yang masih ada? Kami mulai dengan Ketentuan Ras . Selanjutnya kita melihat Deadlock (masih ada varian Livelock , inilah saatnya kita tidak dapat menangkap sumber daya, tetapi tidak ada kunci eksplisit). Ada Kelaparan , inilah saatnya kita pergi ke printer untuk mencetak selembar kertas, dan ada antrian, dan kita tidak dapat mengakses sumber daya. Kami melihat perilaku program dengan False Sharing . Masih ada masalah - Lock Contention , ketika kinerja menurun karena banyak kompetisi untuk sumber daya (misalnya, satu mutex yang dibutuhkan sejumlah besar utas).

Deteksi ras
Go sangat kuat dengan kotak peralatan yang disediakan di luar kotak. Race Detector adalah salah satu alat tersebut. Menggunakannya sederhana: kita menulis tes atau menjalankannya pada muatan tempur dan menangkap kesalahan.
Anda dapat membaca lebih lanjut tentang menggunakan Pendeteksi Ras dalam dokumentasi , tetapi ingat bahwa ia memiliki keterbatasan. Mari kita membahasnya lebih detail.

Pertama, kode yang tidak dieksekusi tidak diperiksa oleh Race Detector. Karena itu, cakupan tes harus tinggi. Selain itu, Detektor Balap mengingat riwayat panggilan ke setiap kata dalam memori, tetapi riwayat panggilan ini memiliki kedalaman. Di Go, misalnya, kedalaman ini adalah empat - empat elemen, empat akses. Jika Detektor Balap tidak menangkap perlombaan dalam kedalaman ini, ia percaya tidak ada balapan. Oleh karena itu, meskipun Race Detector tidak pernah salah, ia tidak akan menangkap semua kesalahan. Anda dapat berharap untuk Race Detector, tetapi Anda harus mengingat keterbatasannya. Secara terpisah, Anda dapat membaca tentang algoritma kerja .
Blokir profil
Profil blok adalah alat lain yang memungkinkan kita menemukan dan memperbaiki masalah pemblokiran.

Ini dapat digunakan baik pada level tes benchmark, dan dapat ditonton selama pertempuran. Karena itu, jika Anda mencari masalah yang terkait dengan sinkronisasi akses data, coba mulai dengan Race Detector dan terus menggunakan Block Profile.
Contoh program
Mari kita lihat kode asli yang bisa kita temukan. Kami akan menulis fungsi yang hanya mengambil array permintaan dan mencoba mengeksekusinya: setiap permintaan secara berurutan. Jika salah satu permintaan mengembalikan kesalahan, fungsi menghentikan eksekusi.

Jika kita menulis di Go, kita harus menggunakan kekuatan penuh dari bahasa tersebut. Kami mencoba. Kami mendapatkan kode tiga kali lebih banyak.

Pertanyaan: apakah ada kesalahan dalam kode?
Tentu saja! Mari kita lihat yang mana.
Dalam loop kami menjalankan goroutine. Untuk orkestrasi goroutine, kami menggunakan sync.WaitGroup . Tapi apa yang kita lakukan salah? Sudah di dalam goroutine yang berjalan, kami memanggil wg.Add(1) , mis. Kami menambahkan satu lagi goroutine untuk menunggu. Dan menggunakan wg.Wait() , kami menunggu semua goroutine selesai. Tetapi mungkin terjadi pada saat wg.Wait() dipanggil, tidak ada satu pun goroutine yang akan mulai. Dalam hal ini, wg.Wait() mempertimbangkan bahwa semuanya sudah selesai, kami akan menutup saluran dan keluar dari fungsi tanpa kesalahan, percaya bahwa semuanya baik-baik saja.

Apa yang akan terjadi selanjutnya? Kemudian goroutine akan mulai, kode akan dieksekusi, dan mungkin salah satu permintaan akan mengembalikan kesalahan. Kesalahan ditulis ke saluran tertutup, dan menulis ke saluran tertutup adalah panik. Aplikasi kita akan macet. Tidak mungkin ini yang ingin saya dapatkan, jadi kami memperbaikinya dengan menunjukkan sebelumnya berapa banyak goroutine yang akan kami luncurkan.

Mungkin masih ada beberapa masalah?
Ada kesalahan terkait dengan bagaimana objek req muncul di dalam fungsi. Variabel req bertindak sebagai iterator siklus, dan kami tidak tahu nilai apa yang akan dimilikinya pada saat peluncuran goroutine.

Dalam praktiknya, dalam kode ini, nilai req kemungkinan besar akan sama dengan elemen terakhir dari array. Karena itu, Anda hanya mengirim permintaan yang sama sebanyak N kali. Perbaiki: secara eksplisit mengirimkan permintaan kami sebagai argumen ke fungsi.

Mari kita lihat lebih dekat bagaimana kita menangani kesalahan. Kami mendeklarasikan saluran buffered pada satu slot. Ketika kesalahan terjadi, kami mengirimkannya ke saluran ini. Semuanya tampak baik-baik saja: terjadi kesalahan - kami mengembalikan kesalahan ini dari suatu fungsi.

Tetapi bagaimana jika semua permintaan kembali dengan kesalahan?
Kemudian menulis ke saluran hanya akan mendapatkan kesalahan pertama, sisanya akan memblokir eksekusi goroutine. Karena tidak akan ada lagi pembacaan dari saluran pada saat keluar dari fungsi baca, kami mengalami kebocoran goroutine. Yaitu, semua gorutin yang tidak bisa menulis kesalahan ke saluran hanya bertahan di memori.
Kami memperbaikinya dengan sangat sederhana: kami memilih di saluran slot jumlah permintaan. Ini menyelesaikan masalah kita yang tidak terlalu hemat memori, karena jika kita memiliki satu miliar permintaan, kita perlu mengalokasikan satu miliar slot.

Kami memecahkan masalah. Kode sekarang kompetitif. Tetapi masalahnya adalah dengan keterbacaan - dibandingkan dengan versi kode sinkron, ada banyak. Dan ini tidak keren, karena pengembangan program kompetitif sudah sulit, mengapa kita menyulitkannya dengan banyak kode?

Errgroup
Saya menyarankan untuk meningkatkan keterbacaan kode.
Saya suka menggunakan paket errgroup alih-alih sync.WaitGroup . Paket ini tidak memerlukan menentukan berapa banyak goroutine yang diharapkan, dan memungkinkan Anda untuk mengabaikan kumpulan kesalahan. Beginilah fungsi kami akan terlihat saat menggunakan errgroup :

Selain itu, errgroup memungkinkan errgroup untuk dengan mudah mengatur komponen program kami menggunakan konteks . Konteks . Apa yang saya maksud
Misalkan kita memiliki beberapa komponen program kita, jika setidaknya salah satu dari mereka gagal, kita ingin menyelesaikan yang lain dengan hati-hati. Jadi errgroup ketika kesalahan errgroup , menyelesaikan context dan, dengan demikian, semua komponen menerima pemberitahuan tentang perlunya menyelesaikan pekerjaan.

Ini dapat digunakan untuk membangun program multikomponen kompleks yang berperilaku dapat diprediksi.
Kesimpulan
Buat sesederhana mungkin. Lebih baik secara sinkron. Pengembangan program multithreaded umumnya merupakan proses yang kompleks, yang mengarah pada munculnya bug yang tidak menyenangkan.

Jangan gunakan sinkronisasi implisit. Jika Anda benar-benar beristirahat di dalamnya, pikirkan tentang cara menyingkirkan kunci, cara membuat algoritma bebas kunci.
Go adalah bahasa yang baik untuk menulis program yang bekerja secara efektif dengan sejumlah besar inti, tetapi tidak lebih baik dari semua bahasa lain, dan kesalahan akan selalu muncul. Oleh karena itu, walaupun dipersenjatai dengan Go, cobalah untuk memahami beberapa tingkat abstraksi yang lebih rendah dari apa yang Anda bekerja.
