Kami hadir untuk perhatian Anda bagian kedua dari terjemahan materi tentang perjuangan tim gitlab.com melawan tirani waktu.

→ Di sini, omong-omong, adalah bagian
pertama .
Meminta Batas Kecepatan Pemrosesan
Pada titik ini, kami tidak tertarik hanya menaikkan nilai parameter
MaxStartups . Meskipun peningkatan 50% dalam parameter ini terbukti baik, peningkatan lebih lanjut tanpa alasan yang cukup tampak seperti solusi yang agak kasar untuk masalah ini. Tentunya ada hal lain yang bisa kami lakukan.
Pencarian membawa saya ke tingkat HAProxy, yang terletak di depan server SSH. HAProxy memiliki opsi
rate-limit sessions bagus yang memengaruhi bagian sistem yang menerima permintaan masuk. Jika opsi ini dikonfigurasi, digunakan untuk membatasi jumlah permintaan TCP baru per detik yang dikirimkan oleh frontend ke backend, sementara meninggalkan koneksi masuk tambahan ke soket TCP. Jika kecepatan permintaan yang masuk melebihi batas (dapat diubah setiap milidetik), maka koneksi baru akan tertunda. Klien TCP (dalam hal ini, SSH) hanya melihat penundaan sebelum membuat koneksi TCP. Ini, menurut saya, adalah langkah yang sangat indah. Sampai kecepatan di mana permintaan diterima, untuk periode waktu yang terlalu lama, melebihi batas terlalu banyak, sistem akan bekerja dengan baik.
Pertanyaan selanjutnya adalah pemilihan nilai opsi
rate-limit sessions , yang harus kita gunakan. Menemukan jawaban untuk pertanyaan ini rumit oleh fakta bahwa kami memiliki 27 backend SSH dan 18 frontend HAProxy (16 alt utama dan 2 alt-ssh), serta fakta bahwa frontend tidak berkoordinasi satu sama lain terkait dengan kecepatan pemrosesan permintaan . Selain itu, kami harus memperhitungkan berapa lama langkah otentikasi sesi SSH yang baru. Misalkan nilai pertama
MaxStartups adalah 150. Ini berarti bahwa jika fase otentikasi memakan waktu dua detik, maka kita dapat mentransfer masing-masing backend hanya 75 sesi baru per detik.
Di sini Anda dapat menemukan detail tentang cara menghitung nilai
rate-limit sessions , saya tidak akan masuk ke detail di sini. Saya hanya mencatat bahwa untuk menghitung nilai ini, empat parameter harus diperhitungkan. Yang pertama dan kedua adalah jumlah server dari kedua jenis. Yang ketiga adalah nilai
MaxStartups . Yang keempat adalah
T - berapa lama untuk mengotentikasi sesi SSH. Nilai
T sangat penting, tetapi hanya dapat disimpulkan sekitar. Kami melakukan hal itu, meninggalkan hasilnya pada 2 detik. Hasilnya, kami mendapat nilai
rate-limit nilai untuk ujung depan, yang berjumlah 112,5. Kami membulatkannya menjadi 110.
Dan sekarang, pengaturan baru mulai berlaku. Mungkin Anda berpikir bahwa setelah ini semuanya berakhir dengan bahagia? Pasti jumlah kesalahan yang melesat ke nol dan semua orang di sekitar sangat senang? Sebenarnya itu jauh dari baik. Perubahan ini tidak menghasilkan perubahan yang terlihat dalam tingkat kesalahan. Terus terang, saya cukup kesal. Kami melewatkan sesuatu yang penting atau salah memahami esensi masalah.
Sebagai hasilnya, kami kembali ke log (dan, akhirnya, ke informasi HAProxy) dan dapat memastikan bahwa batas kecepatan pemrosesan kueri setidaknya berfungsi dengan bekerja pada kueri seperti yang kami harapkan. Sebelumnya, indikator yang sesuai lebih tinggi, ini memungkinkan kami untuk menyimpulkan bahwa kami berhasil membatasi kecepatan pengiriman permintaan masuk untuk diproses. Tetapi jelas bahwa tingkat permintaan itu datang masih terlalu tinggi. Meskipun itu juga jelas bahwa itu bahkan tidak mendekati level-level itu ketika itu bisa memiliki efek nyata pada sistem. Ketika kami menganalisis proses memilih backend (menurut log HAProxy), kami melihat satu keanehan di sana. Pada awal jam, koneksi backend didistribusikan tidak merata di server SSH. Dalam interval waktu yang dipilih untuk analisis, jumlah koneksi per detik pada server yang berbeda bervariasi dari 30 hingga 121. Dan ini berarti bahwa load balancing kami tidak melakukan tugasnya dengan baik. Analisis konfigurasi menunjukkan bahwa kami menggunakan opsi
balance source , sehingga klien dengan alamat IP tertentu selalu terhubung ke backend yang sama. Ini dapat dianggap sebagai fenomena positif dalam kasus-kasus di mana pengikatan sesi diperlukan. Tapi kami berurusan dengan SSH, jadi kami tidak membutuhkan ini. Opsi ini pernah dikonfigurasi oleh kami, tetapi kami tidak menemukan petunjuk mengapa ini dilakukan. Kami tidak dapat menemukan alasan yang layak untuk terus menggunakannya. Akibatnya, kami memutuskan untuk beralih ke
leastconn . Berkat opsi ini, koneksi masuk yang baru memberikan backend dengan jumlah minimum koneksi saat ini. Ini memengaruhi penggunaan sumber daya prosesor oleh server SSH (Git) kami. Ini jadwal yang sesuai.
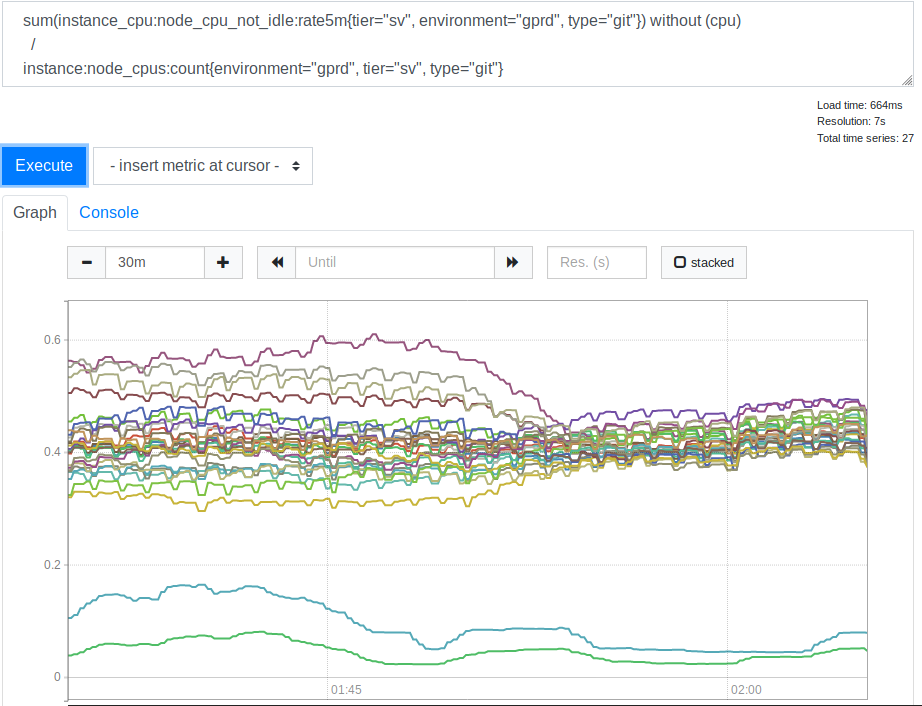 Konsumsi CPU oleh server sebelum dan sesudah menerapkan opsi leastconn
Konsumsi CPU oleh server sebelum dan sesudah menerapkan opsi leastconnSetelah kami melihat ini, kami menyadari bahwa menggunakan
leastconn adalah ide yang baik. Dua baris yang ada di bagian bawah grafik adalah server Canary kami, Anda dapat mengabaikannya. Tetapi sebelumnya, penyebaran nilai beban CPU untuk server yang berbeda berkorelasi sebagai 2: 1 (dari 30% hingga 60%). Ini jelas menunjukkan bahwa sebelumnya beberapa backend kami dimuat lebih dari yang lain karena koneksi klien kepada mereka. Itu mengejutkan saya. Tampaknya masuk akal untuk mengharapkan bahwa berbagai alamat IP klien cukup untuk memuat server kami jauh lebih merata. Tetapi, tampaknya, untuk mengubah indikator beban server, beberapa klien besar sudah cukup, perilaku yang berbeda dari beberapa opsi rata-rata.
Pelajaran nomor 4. Saat Anda memilih pengaturan tertentu yang berbeda dari pengaturan default, beri komentar atau tinggalkan tautan ke materi yang menjelaskan perubahan tersebut. Siapa pun yang harus berurusan dengan pengaturan ini di masa depan akan berterima kasih kepada Anda untuk ini.
Transparansi ini adalah
salah satu nilai inti GitLab .
Mengaktifkan opsi
leastconn juga membantu mengurangi tingkat kesalahan. Dan itulah tepatnya yang kami perjuangkan. Karena itu, kami memutuskan untuk meninggalkan opsi ini. Tetapi, terus bereksperimen, mereka mengurangi tingkat batas kecepatan pemrosesan permintaan menjadi 100, yang membantu mengurangi tingkat kesalahan lebih lanjut. Ini menunjukkan bahwa pemilihan awal nilai
T mungkin dilakukan secara tidak benar. Tetapi jika demikian, maka indikator ini terlalu kecil, yang menyebabkan batas kecepatan terlalu kuat, dan bahkan 100 permintaan per detik dianggap sebagai nilai yang sangat rendah, dan kami tidak siap untuk menguranginya lebih jauh. Sayangnya, untuk beberapa alasan internal, kedua perubahan ini hanyalah sebuah eksperimen. Kami harus kembali menggunakan opsi
balance source dan membatasi kecepatan pemrosesan permintaan hingga 100 permintaan per detik.
Mengingat bahwa kecepatan pemrosesan kueri diatur ke tingkat rendah yang sesuai dengan kami, dan bahwa kami tidak dapat menggunakan
leastconn , kami mencoba meningkatkan parameter
MaxStartups . Pada awalnya kami meningkatkannya menjadi 200, ini memberi efek. Kemudian - hingga 250. Kesalahan hampir sepenuhnya hilang dan tidak ada hal buruk yang terjadi.
Pelajaran nomor 5. Sementara MaxStartups tinggi mungkin terlihat menakutkan, mereka memiliki dampak yang sangat kecil pada kinerja bahkan ketika mereka jauh lebih tinggi daripada nilai default.
Mungkin ini adalah sesuatu seperti tuas besar dan kuat, yang bisa kita gunakan di masa depan. Mungkin kita akan menghadapi masalah jika kita berbicara tentang angka-angka di wilayah beberapa ribu atau beberapa puluh ribu, tetapi kita masih jauh dari itu.
Apa yang dikatakan di sini tentang perkiraan saya tentang parameter
T , waktu yang diperlukan untuk menginstal dan mengotentikasi sesi SSH? Jika Anda bekerja dengan rumus untuk menghitung indikator batas kecepatan pemrosesan koneksi, mengetahui bahwa 200 tidak cukup untuk indikator
MaxStartups , dan 250 sudah cukup, Anda dapat mengetahui bahwa
T mungkin memiliki nilai 2,7 hingga 3,4 detik. Akibatnya, nilai perkiraan 2 detik tidak jauh dari kebenaran, tetapi nilai sebenarnya, tentu saja, lebih tinggi dari yang diharapkan. Kami akan kembali lagi nanti.
Langkah terakhir
Kami kembali melihat log, dengan mempertimbangkan apa yang sudah kami ketahui, dan, setelah beberapa refleksi, menemukan bahwa masalah yang memulai semuanya dapat diidentifikasi dengan tanda-tanda berikut. Pertama, ini adalah nilai
t_state sama dengan
SD . Kedua, ini adalah nilai
b_read (byte yang dibaca oleh klien), sama dengan 0. Seperti yang telah disebutkan, kami memproses sekitar 26-28 juta koneksi SSH per hari. Tidak menyenangkan mengetahui bahwa, di tengah-tengah bencana, sekitar 1,5% dari koneksi ini rusak parah. Jelas, skala masalahnya jauh lebih besar dari yang kami pikirkan di awal. Selain itu, tidak ada yang tidak dapat kami deteksi sebelumnya (bahkan ketika kami menyadari bahwa
t_state="SD" menunjukkan masalah dalam log), tetapi kami tidak memikirkan bagaimana melakukan ini, walaupun kami dan Anda harus memikirkannya. Mungkin karena ini, kami menghabiskan lebih banyak waktu dan upaya untuk menyelesaikan masalah daripada yang bisa kami habiskan.
Pelajaran nomor 6. Mengukur tingkat kesalahan nyata sedini mungkin.
Jika pada awalnya kami menyadari luasnya masalah, kami bisa lebih memperhatikannya. Meskipun, bagaimana cara melihatnya, masih tergantung pada pengetahuan tentang karakteristik yang memungkinkan kita untuk menggambarkan masalah.
Jika kita berbicara tentang keuntungan yang muncul setelah kita meningkatkan nilai
MaxStartups dan menyetel kecepatan pemrosesan permintaan, kita dapat mengatakan bahwa tingkat kesalahan turun menjadi 0,001%. Itu - hingga beberapa ribu sehari. Situasi ini terlihat jauh lebih baik, tetapi tingkat kesalahan yang serupa masih lebih tinggi daripada yang ingin kami capai. Setelah kami menemukan beberapa hal, kami kembali dapat menggunakan opsi
leastconn dan kesalahannya benar-benar hilang. Setelah itu, kami bisa bernapas lega.
Pekerjaan di masa depan
Jelas, fase otentikasi SSH masih membutuhkan banyak waktu. Mungkin hingga 3,4 detik. GitLab dapat menggunakan
AuthorizedKeysCommand untuk secara langsung mencari kunci SSH dalam database. Ini sangat penting untuk operasi cepat ketika ada sejumlah besar pengguna. Jika tidak, SSHD perlu membaca secara berurutan file otor_keys yang sangat besar untuk menemukan kunci publik pengguna. Tugas ini tidak skala dengan baik. Kami menerapkan pencarian menggunakan sejumlah kode Ruby yang melakukan panggilan ke API HTTP eksternal.
Stan Hugh , kepala departemen teknik kami dan sumber pengetahuan yang tidak ada habisnya tentang GitLab, menemukan bahwa contoh Unicorn dari server Git / SSH berada di bawah beban konstan dari permintaan yang dibuat kepada mereka. Ini dapat memberikan kontribusi signifikan pada tiga detik yang diperlukan untuk mengautentikasi permintaan. Sebagai hasilnya, kami menyadari bahwa di masa mendatang kami harus menyelidiki masalah ini. Mungkin kita akan menambah jumlah instance Unicorn (atau Puma) pada node-node ini sehingga server SSH tidak perlu menunggu untuk mengaksesnya. Namun, ada risiko tertentu di sini, jadi kita harus berhati-hati dan memperhatikan pengumpulan dan analisis indikator sistem. Bekerja pada produktivitas terus berlanjut, tetapi sekarang, setelah masalah utama diselesaikan, segalanya menjadi lebih lambat. Kita mungkin dapat mengurangi nilai
MaxStartups , tetapi karena level tinggi tidak menciptakan dampak negatif pada sistem yang tampaknya dibuat, ini tidak terlalu diperlukan. Akan lebih mudah bagi semua orang untuk hidup jika OpenSSH kapan saja dapat memberi tahu kami seberapa dekat kami dengan batas
MaxStartups . Akan lebih baik jika kita selalu tahu. Ini jauh lebih baik daripada belajar bahwa batas terlampaui ketika dihadapkan dengan koneksi yang terputus.
Selain itu, kita memerlukan semacam sistem notifikasi ketika entri log HAProxy muncul, menunjukkan masalah dengan koneksi terputus. Faktanya adalah bahwa ini, dalam praktiknya, tidak boleh terjadi sama sekali. Jika ini terjadi lagi, kita perlu lebih meningkatkan nilai
MaxStartups , atau jika kita mengalami kekurangan sumber daya, kita perlu menambahkan lebih banyak node Git / SSH ke sistem.
Ringkasan
Bagian dari sistem yang kompleks berinteraksi dalam pola yang kompleks. Dan di dalamnya, untuk menyelesaikan berbagai masalah, orang sering dapat menemukan jauh dari satu "tuas". Ketika berhadapan dengan sistem seperti itu, ada baiknya untuk mengetahui tentang alat yang ada di dalamnya. Faktanya adalah mereka semua memiliki pro dan kontra. Selain itu, perlu dicatat bahwa mungkin berisiko untuk melakukan pengaturan tertentu berdasarkan asumsi dan nilai estimasi. Sekarang, melihat jalan yang telah kami lalui, saya akan mencoba mengukur seakurat mungkin waktu yang dibutuhkan untuk menyelesaikan otentikasi permintaan, yang akan mengarah pada nilai perkiraan
T yang saya simpulkan akan lebih dekat dengan kebenaran.
Tetapi pelajaran utama yang kami pelajari dari semua ini adalah bahwa ketika banyak orang merencanakan tugas berdasarkan beberapa metrik waktu yang menyenangkan, ini, untuk penyedia layanan terpusat seperti GitLab, mengarah ke masalah penskalaan yang benar-benar tidak biasa.
Jika Anda salah satu dari mereka yang menggunakan alat peluncuran tugas terjadwal, maka Anda mungkin perlu mempertimbangkan mengatur waktu untuk meluncurkan tugas Anda dengan cara baru. Misalnya, Anda dapat membuat tugas "tertidur" untuk sementara waktu, mulai benar-benar bekerja hanya 30 detik setelah diluncurkan. Anda dapat, misalnya, menunjukkan waktu acak dalam satu jam dalam jadwal peluncuran tugas (di sini Anda dapat menambahkan waktu tunggu acak sebelum pelaksanaan tugas yang sebenarnya). Ini akan membantu kita semua dalam perang melawan tirani arloji.
Pembaca yang budiman! Pernahkah Anda mengalami masalah yang serupa dengan kisah yang didedikasikan untuk bahan ini?
