Materi, bagian pertama dari terjemahan yang kami terbitkan hari ini, dikhususkan untuk masalah skala besar yang muncul di gitlab.com. Di sini kita akan berbicara tentang bagaimana mereka menemukannya, bagaimana mereka bertarung dengannya, dan bagaimana, akhirnya, mereka menyelesaikannya. Selain itu, dihadapkan dengan masalah ini, tim gitlab.com menemukan apa tirani jam tangan itu.

→
Bagian kedua .
Masalah
Kami mulai menerima pesan dari klien bahwa, ketika bekerja dengan gitlab.com, mereka secara berkala mengalami kesalahan saat menjalankan permintaan tarik. Kesalahan biasanya terjadi ketika melakukan tugas CI atau selama operasi sistem otomatis serupa lainnya. Pesan kesalahan terlihat seperti ini:
ssh_exchange_identification: connection closed by remote host fatal: Could not read from remote repository
Situasi ini semakin rumit oleh fakta bahwa pesan kesalahan muncul tidak teratur dan, sepertinya, tidak dapat diprediksi. Kami tidak dapat mereproduksi mereka sesuka hati, tidak bisa mengidentifikasi tanda-tanda yang jelas tentang apa yang terjadi di grafik atau di log. Pesan kesalahan itu sendiri tidak membawa banyak manfaat juga. Klien SSH diberitahu bahwa koneksi terputus, tetapi alasannya bisa apa saja: klien gagal atau mesin virtual tidak stabil, firewall yang tidak kami kontrol, tindakan penyedia aneh atau masalah dengan aplikasi kami.
Kami, yang bekerja pada skema GIT-over-SSH, berurusan dengan sejumlah besar koneksi - sekitar 26 juta per hari. Ini rata-rata 300 koneksi per detik. Oleh karena itu, upaya untuk memilih sejumlah kecil koneksi gagal dari aliran data yang ada berjanji akan menjadi tugas yang sulit. Hal yang baik tentang situasi ini adalah kami ingin menyelesaikan masalah yang rumit.
Petunjuk pertama
Kami menghubungi salah satu klien kami (terima kasih kepada Hubert Holtz dari Atalanda), yang menemukan masalah beberapa kali sehari. Ini memberi kami pijakan. Hubert dapat memberi kami alamat IP publik yang sesuai. Ini berarti bahwa kami dapat menangkap paket pada node front-end HAProxy kami untuk mencoba mengisolasi masalah dengan mengandalkan dataset yang lebih kecil dari apa yang disebut "semua lalu lintas SSH". Bahkan lebih baik, perusahaan menggunakan
port ssh-alternatif . Ini berarti bahwa kami perlu menganalisis keadaan hanya pada dua server HAProxy, dan bukan pada enam belas.
Analisis paket, bagaimanapun, tidak terlalu menyenangkan. Meskipun ada pembatasan dalam waktu 6,5 jam, sekitar 500 paket MB dikumpulkan. Kami menemukan senyawa berumur pendek. Koneksi TCP dibuat, klien mengirim pengenal, setelah itu server HAProxy kami segera terputus menggunakan urutan TCP FIN yang benar. Sebagai hasilnya, kami memiliki petunjuk bagus pertama. Dia mengizinkan kami untuk menyimpulkan bahwa koneksi sudah pasti ditutup atas inisiatif gitlab.com, dan bukan karena sesuatu antara kami dan klien. Ini berarti bahwa kami dihadapkan dengan masalah yang dapat kami selidiki dan perbaiki.
Pelajaran nomor 1. Menu Statistik alat Wireshark memiliki banyak alat yang berguna yang saya, sebelum kasus ini, belum terlalu memperhatikan.
Secara khusus, kita berbicara tentang item menu
Conversations , yang dapat menunjukkan informasi dasar tentang data yang diambil tentang koneksi TCP. Ada informasi tentang waktu, paket, byte. Data yang ditampilkan di jendela yang sesuai dapat diurutkan. Saya harus menggunakan alat ini sejak awal alih-alih mengacak data yang diambil secara manual. Kemudian saya menyadari bahwa saya perlu mencari koneksi dengan sejumlah kecil paket. Jendela
Conversations memungkinkan Anda untuk segera memperhatikannya. Setelah itu, saya dapat menemukan senyawa serupa lainnya dan memastikan bahwa koneksi pertama itu bukan fenomena abnormal.
Perendaman log
Apa yang menyebabkan HAProxy terputus dari klien? Server, tentu saja, tidak melakukan ini dengan cara yang sewenang-wenang; apa yang terjadi seharusnya memiliki alasan yang lebih dalam; jika Anda suka - "tingkat
kura -
kura lain ." Ada perasaan bahwa objek penelitian selanjutnya adalah log HAProxy. Log kami disimpan di GCP BigQuery. Ini nyaman, karena kami memiliki banyak log, dan kami perlu menganalisisnya secara komprehensif. Tetapi pertama-tama, kami dapat mengidentifikasi entri log untuk salah satu insiden, yang ditemukan dalam paket yang ditangkap. Kami mengandalkan waktu dan port TCP, yang merupakan pencapaian utama dalam penelitian kami. Detail paling menarik dalam catatan yang ditemukan adalah
t_state (Termination State), yang memiliki nilai
SD . Berikut ini kutipan dari dokumentasi HAProxy:
S: , . D: DATA.
Arti makna
D dijelaskan dengan sangat sederhana. Koneksi TCP dibuat dengan benar, data dikirim. Ini bertepatan dengan bukti yang diperoleh dari paket yang ditangkap. Nilai
S berarti bahwa HAProxy menerima pesan kegagalan ICT, atau ICMP dari backend. Tetapi kami tidak dapat segera menemukan petunjuk mengapa ini terjadi. Alasan untuk ini bisa apa saja - dari jaringan yang tidak stabil (misalnya, kegagalan atau kemacetan) ke masalah tingkat aplikasi. Menggunakan BigQuery untuk mengumpulkan data pada backend Git, kami menemukan bahwa masalahnya tidak terkait dengan mesin virtual tertentu. Kami membutuhkan lebih banyak informasi.
Saya ingin mencatat bahwa entri log dengan nilai
SD bukanlah sesuatu yang istimewa, karakteristik hanya untuk masalah kita. Pada port alternatif-ssh, kami menerima banyak permintaan terkait pemindaian HTTPS. Ini mengarah pada fakta bahwa nilai
SD jatuh ke log ketika server SSH melihat pesan
TLS ClientHello sementara itu diharapkan untuk menerima salam SSH. Ini secara singkat mengarahkan penyelidikan kami secara tidak langsung.
Setelah menangkap beberapa lalu lintas antara HAProxy dan server Git dan lagi menggunakan alat Wireshark, kami dengan cepat menemukan bahwa SSHD pada server Git terputus dari TCP FIN-ACK segera setelah jabat tangan tiga arah TCP. HAProxy masih tidak mengirim paket data pertama, tetapi akan melakukannya. Ketika dia mengirim paket, server Git menjawabnya dengan TCP RST. Akibatnya - sekarang kami telah menemukan alasan mengapa HAProxy menulis ke log tentang kegagalan koneksi dengan nilai
SD . SSH menutup koneksi, melakukannya dengan sengaja dan benar, dan RST hanyalah artefak dari fakta bahwa server SSH menerima paket setelah FIN-ACK. Itu tidak berarti apa-apa lagi.
Jadwal fasih
Melihat dan menganalisis log dengan nilai
SD di BigQuery, kami menyadari bahwa kesalahan memiliki hubungan yang jelas dengan waktu. Yaitu, kami menemukan puncak dalam jumlah koneksi yang gagal dalam 10 detik pertama setiap menit. Mereka diamati selama 5-6 detik.
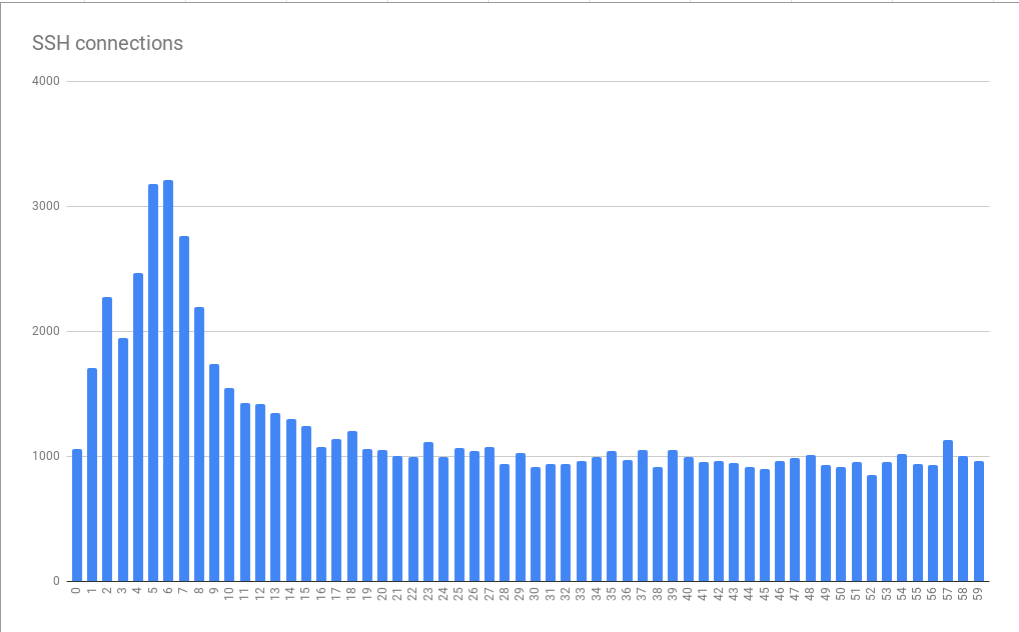 Kesalahan koneksi dikelompokkan dalam beberapa menit hingga detik
Kesalahan koneksi dikelompokkan dalam beberapa menit hingga detikBagan ini didasarkan pada data yang dikumpulkan selama berjam-jam. Fakta bahwa pola distribusi kesalahan yang terdeteksi ternyata stabil menunjukkan bahwa penyebab kesalahan secara stabil memanifestasikan dirinya dalam menit dan jam individu, dan, bahkan mungkin lebih buruk, itu stabil muncul pada waktu yang berbeda dalam sehari. Sangat menarik bahwa ukuran puncak rata-rata sekitar 3 kali lebih besar dari beban dasar. Ini berarti bahwa kami dihadapkan pada masalah penskalaan yang tidak sepele. Akibatnya, hanya menghubungkan "lebih banyak sumber daya" dalam bentuk mesin virtual tambahan, yang dirancang untuk membantu kami mengatasi beban puncak, secara teoritis bisa menjadi sangat mahal. Ini juga menunjukkan bahwa kita sedang mencapai semacam batasan yang parah. Sebagai hasilnya, kami menerima petunjuk pertama tentang masalah sistemik mendasar yang menyebabkan kesalahan. Saya menyebutnya tirani jam.
Cron atau sistem penjadwalan serupa seringkali tidak berbeda dalam kemampuan untuk menyesuaikan pelaksanaan tugas ke detik terdekat. Jika sistem tersebut memiliki kemampuan seperti itu, mereka tidak sering digunakan karena fakta bahwa orang lebih suka mempertimbangkan waktu, dibagi menjadi beberapa interval, dinyatakan dengan angka bulat yang indah. Akibatnya, tugas dimulai pada awal menit atau jam, atau pada saat-saat serupa lainnya. Jika tugas tersebut memerlukan beberapa detik untuk menyiapkan perintah
git fetch untuk mengunduh materi dari gitlab.com, ini dapat menjelaskan pola yang kami temukan ketika beban pada sistem meningkat tajam selama beberapa detik setiap menit. Pada saat-saat seperti itu, jumlah kesalahan bertambah.
Pelajaran nomor 2. Banyak orang, tampaknya, menggunakan sinkronisasi waktu yang dikonfigurasi dengan benar (melalui NTP atau menggunakan mekanisme lain).
Jika tidak ada yang menyinkronkan waktu, maka masalah kita tidak akan terwujud dengan jelas. Selamat siang, NTP!
Tapi apa yang menyebabkan SSH terputus?
Lebih dekat ke inti masalah
Mempelajari dokumentasi
MaxStartups , kami menemukan parameter
MaxStartups . Ini mengontrol jumlah maksimum koneksi yang tidak diautentikasi. Tampaknya masuk akal bahwa batas koneksi habis ketika pada awal menit sistem mengalami beban yang dibuat oleh kesibukan panggilan tugas terjadwal dari seluruh Internet. Parameter
MaxStartups terdiri dari tiga angka. Yang pertama adalah batas bawah (jumlah koneksi saat mencapai yang istirahat dalam koneksi dimulai). Yang kedua adalah persentase senyawa yang melebihi batas bawah senyawa yang perlu dipecah secara acak. Nilai ketiga adalah jumlah maksimum koneksi absolut, setelah semua koneksi baru ditolak. Nilai default MaxStartups terlihat seperti 10: 30: 100, pengaturan kami kemudian terlihat seperti 100: 30: 200. Ini menunjukkan bahwa di masa lalu kami telah meningkatkan batas koneksi standar. Mungkin - saatnya untuk meningkatkannya lagi.
Ternyata sedikit tidak menyenangkan karena OpenSSH 7.2 diinstal pada server kami, satu-satunya cara untuk mencapai batas yang ditentukan dalam
MaxStartups adalah dengan beralih ke level debugging
Debug . Dengan pendekatan ini, longsoran data masuk ke dalam log. Karena itu, kami secara singkat mengaktifkan mode ini di salah satu server. Untungnya, setelah beberapa menit, menjadi jelas bahwa jumlah koneksi melebihi batas yang ditetapkan dalam
MaxStartups , sebagai akibatnya terjadi pemutusan awal.
Ternyata di OpenSSH 7.6 (versi ini hadir dengan Ubuntu 18.04) pendekatan yang lebih nyaman untuk mencatat apa yang terkait dengan
MaxStartups . Di sini Anda hanya perlu beralih ke mode logging
Verbose . Meskipun tidak ideal, itu masih lebih baik daripada beralih ke level
Debug .
Pelajaran nomor 3. Ini dianggap sebagai bentuk yang baik untuk menulis informasi menarik ke log di tingkat logging standar, dan informasi tentang pemutusan yang disengaja untuk alasan apa pun tentu menarik bagi administrator sistem.
Sekarang kami telah menemukan penyebab masalah, muncul pertanyaan tentang bagaimana menyelesaikannya. Kita dapat meningkatkan nilai dalam parameter
MaxStartups , tetapi berapa biayanya? Tentu saja, ini akan membutuhkan sedikit memori tambahan, tetapi apakah itu akan menimbulkan konsekuensi yang merugikan di bagian-bagian sistem di mana permintaan diproses? Kami hanya bisa memikirkannya, jadi kami memutuskan untuk mengambil dan hanya mencoba pengaturan
MaxStartups baru. Yaitu, kami menukar mereka dengan yang berikut: 150: 30: 300. Sebelumnya, mereka terlihat seperti 100: 30: 200, yaitu - kami meningkatkan jumlah koneksi hingga 50%. Ini memiliki efek positif yang kuat pada sistem. Pada saat yang sama, beberapa efek negatif, seperti meningkatkan beban pada prosesor, tidak diamati.
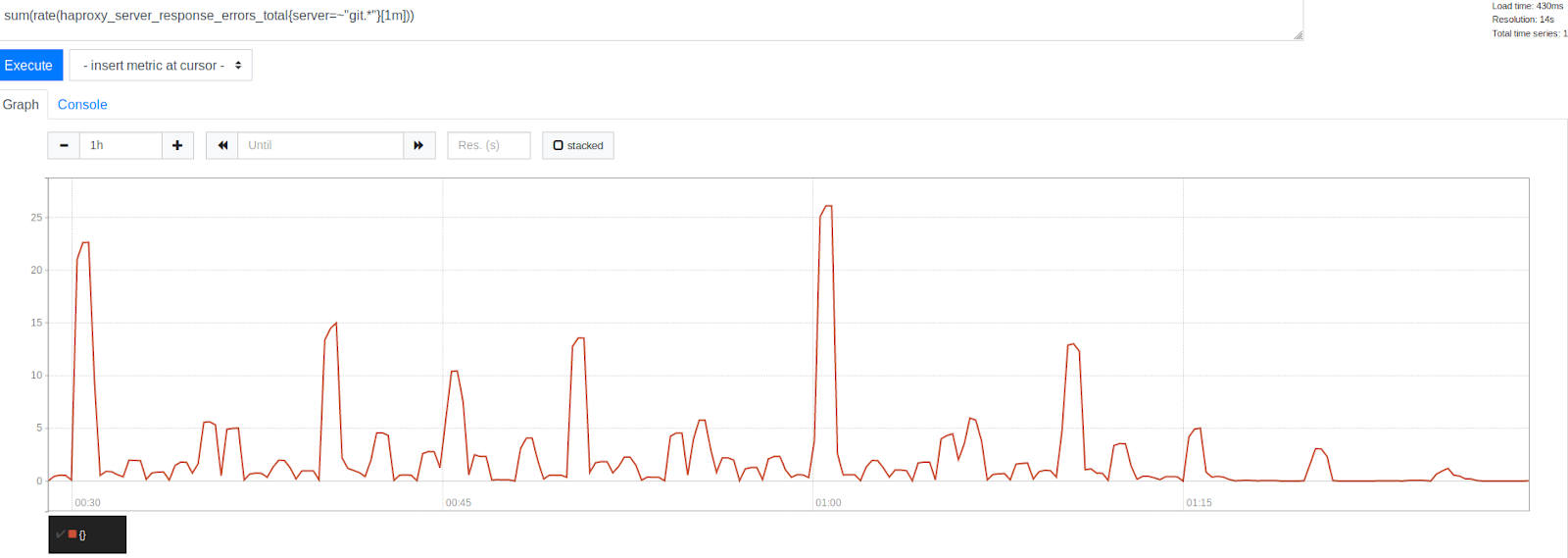 Jumlah kesalahan sebelum dan sesudah meningkatkan MaxStartups sebesar 50%
Jumlah kesalahan sebelum dan sesudah meningkatkan MaxStartups sebesar 50%Perhatikan pengurangan kesalahan yang signifikan setelah stempel waktu 1:15. Ini jelas menunjukkan bahwa kami dapat menyingkirkan sebagian besar kesalahan, meskipun beberapa dari mereka masih ada. Sangat menarik untuk dicatat bahwa kesalahan dikelompokkan di sekitar cap waktu yang diwakili oleh angka bulat yang indah. Ini adalah awal dari jam, setiap 30, 15 dan 10 menit. Tidak diragukan lagi, tirani arloji terus berlanjut. Pada awal setiap jam, puncak kesalahan tertinggi diamati. Ini, mengingat apa yang sudah kita ketahui, terlihat cukup bisa dimengerti. Banyak orang hanya berencana untuk menjalankan tugas setiap jam yang berjalan 0 menit setelah dimulainya jam. Fakta ini mengkonfirmasi teori kami bahwa puncak kesalahan disebabkan oleh peluncuran tugas yang dijadwalkan. Ini menunjukkan bahwa kami berada di jalur yang benar dalam menyelesaikan masalah dengan menyesuaikan batas sistem.
Untuk kesenangan kami, mengubah batas
MaxStartups tidak menyebabkan efek negatif yang nyata. Penggunaan CPU pada server SSH tetap pada tingkat yang sama seperti sebelumnya, beban pada sistem kami juga tidak meningkat. Itu sangat bagus, mengingat kami sekarang menerima lebih banyak koneksi, dari koneksi yang sebelumnya sudah rusak. Selain itu, situasinya tidak diperburuk oleh fakta bahwa kami melakukan ini pada saat sistem kami sangat banyak dimuat. Semuanya tampak menjanjikan.
Dilanjutkan ...
Pembaca yang budiman! Alat apa yang Anda gunakan untuk menganalisis lalu lintas dan log?
