Hai Habr.
Setelah bereksperimen dengan basis 60.000 angka tulisan tangan yang terkenal, MNIST, muncul pertanyaan logis apakah ada sesuatu yang serupa, tetapi dengan dukungan tidak hanya untuk angka, tetapi juga untuk huruf. Ternyata, ada, dan disebut basis seperti itu, seperti yang Anda duga, Extended MNIST (EMNIST).
Jika ada yang tertarik bagaimana menggunakan database ini Anda dapat membuat pengenalan teks sederhana, selamat datang di cat.
 Catatan
Catatan : contoh ini eksperimental dan mendidik, saya hanya tertarik untuk melihat apa yang terjadi. Saya tidak berencana dan tidak berencana untuk melakukan FineReader kedua, jadi banyak hal di sini, tentu saja, tidak dilaksanakan. Karenanya, klaim dengan gaya “mengapa,” “sudah lebih baik,” dll., Tidak diterima. Mungkin sudah ada pustaka OCR siap pakai untuk Python, tapi itu menarik untuk melakukannya sendiri. Ngomong-ngomong, bagi mereka yang ingin melihat bagaimana FineReader asli dibuat, ada dua artikel di blog mereka di Habr pada tahun 2014:
1 dan
2 (tapi tentu saja, tanpa kode sumber dan detail, seperti di blog perusahaan mana pun). Baiklah, mari kita mulai, semuanya terbuka di sini dan semuanya open source.
Sebagai contoh, kami akan mengambil teks biasa. Ini satu:
Neraka dunia
Dan mari kita lihat apa yang bisa dilakukan dengannya.
Memecah teks menjadi huruf
Langkah pertama adalah memecah teks menjadi huruf-huruf terpisah. OpenCV berguna untuk ini, lebih tepatnya fungsi findContours-nya.
Buka gambar (cv2.imread), terjemahkan ke dalam b / w (cv2.cvtColor + cv2.threshold), sedikit meningkat (cv2.erode) dan temukan garis besarnya.
image_file = "text.png" img = cv2.imread(image_file) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY) img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
Kami mendapatkan hierarki hierarki kontur (parameter cv2.RETR_TREE). Pertama datang garis besar umum dari gambar, kemudian garis besar dari surat-surat, kemudian garis besar bagian dalam. Kami hanya perlu garis besar surat-surat, jadi saya memeriksa bahwa "garis besar" adalah garis besar keseluruhan. Ini adalah pendekatan yang disederhanakan, dan untuk pemindaian nyata ini mungkin tidak berfungsi, meskipun tidak penting untuk mengenali tangkapan layar.
Hasil:
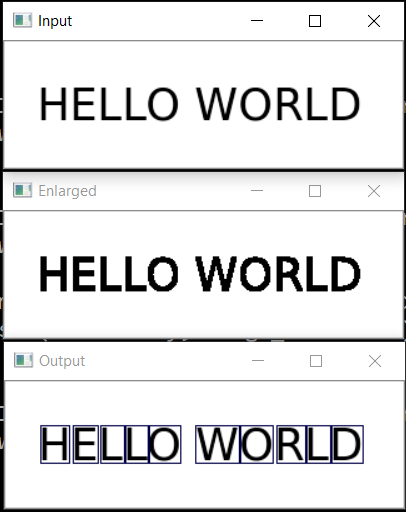
Langkah selanjutnya adalah menyimpan setiap huruf, setelah sebelumnya menskalanya menjadi 28x28 persegi (dalam format inilah database MNIST disimpan). OpenCV dibangun atas dasar numpy, sehingga kita dapat menggunakan fungsi bekerja dengan array untuk memotong dan menskala.
def letters_extract(image_file: str, out_size=28) -> List[Any]: img = cv2.imread(image_file) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY) img_erode = cv2.erode(thresh, np.ones((3, 3), np.uint8), iterations=1)
Pada akhirnya, kami mengurutkan huruf berdasarkan koordinat X, seperti yang Anda lihat, kami menyimpan hasilnya dalam bentuk tuple (x, w, letter), sehingga spasi dapat dipilih dari spasi di antara huruf-huruf.
Pastikan semuanya berfungsi:
cv2.imshow("0", letters[0][2]) cv2.imshow("1", letters[1][2]) cv2.imshow("2", letters[2][2]) cv2.imshow("3", letters[3][2]) cv2.imshow("4", letters[4][2]) cv2.waitKey(0)

Surat siap untuk dikenali, kami akan mengenalinya menggunakan jaringan convolutional - jenis jaringan ini sangat cocok untuk tugas-tugas seperti itu.
Jaringan Saraf Tiruan (CNN) untuk pengakuan
Dataset sumber EMNIST memiliki 62 karakter berbeda (A..Z, 0..9, dll.):
emnist_labels = [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122]
Sebuah jaringan saraf, dengan demikian, memiliki 62 output, pada input akan menerima 28x28 gambar, setelah pengakuan "1" akan berada pada output jaringan yang sesuai.
Buat model jaringan.
from tensorflow import keras from keras.models import Sequential from keras import optimizers from keras.layers import Convolution2D, MaxPooling2D, Dropout, Flatten, Dense, Reshape, LSTM, BatchNormalization from keras.optimizers import SGD, RMSprop, Adam from keras import backend as K from keras.constraints import maxnorm import tensorflow as tf def emnist_model(): model = Sequential() model.add(Convolution2D(filters=32, kernel_size=(3, 3), padding='valid', input_shape=(28, 28, 1), activation='relu')) model.add(Convolution2D(filters=64, kernel_size=(3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(len(emnist_labels), activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy']) return model
Seperti yang Anda lihat, ini adalah jaringan konvolusional klasik yang menyoroti fitur-fitur tertentu dari gambar (jumlah filter 32 dan 64), ke "output" yang terhubung ke jaringan MLP "linear", yang membentuk hasil akhir.
Pelatihan jaringan saraf
Kami lolos ke pelatihan tahap jaringan terpanjang. Untuk melakukan ini, kami mengambil basis data EMNIST, yang dapat diunduh
dari tautan (ukuran arsip 536Mb).
Untuk membaca database, gunakan perpustakaan idx2numpy. Kami akan menyiapkan data untuk pelatihan dan validasi.
import idx2numpy emnist_path = '/home/Documents/TestApps/keras/emnist/' X_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-images-idx3-ubyte') y_train = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-train-labels-idx1-ubyte') X_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-images-idx3-ubyte') y_test = idx2numpy.convert_from_file(emnist_path + 'emnist-byclass-test-labels-idx1-ubyte') X_train = np.reshape(X_train, (X_train.shape[0], 28, 28, 1)) X_test = np.reshape(X_test, (X_test.shape[0], 28, 28, 1)) print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, len(emnist_labels)) k = 10 X_train = X_train[:X_train.shape[0] // k] y_train = y_train[:y_train.shape[0] // k] X_test = X_test[:X_test.shape[0] // k] y_test = y_test[:y_test.shape[0] // k]
Kami telah menyiapkan dua set untuk pelatihan dan validasi. Karakter itu sendiri adalah array biasa yang mudah ditampilkan:

Kami juga hanya menggunakan 1/10 dataset untuk pelatihan (parameter k), jika tidak, prosesnya akan memakan waktu setidaknya 10 jam.
Kami memulai pelatihan jaringan, pada akhir proses kami menyimpan model terlatih ke disk.
Proses pembelajaran itu sendiri memakan waktu sekitar setengah jam:
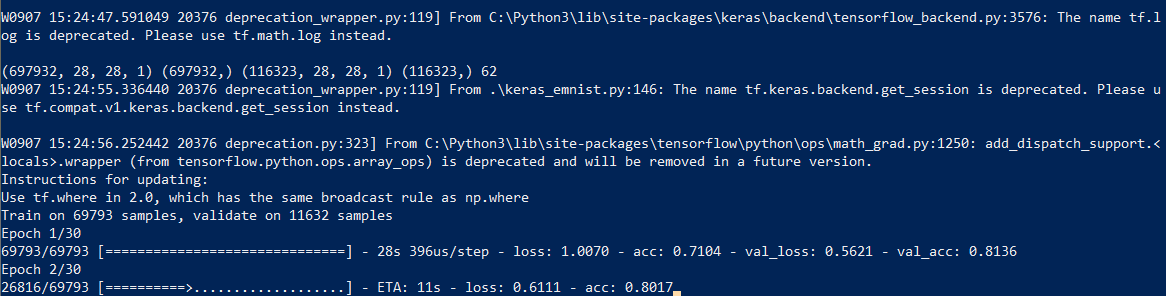
Ini perlu dilakukan hanya sekali, maka kita akan menggunakan file model yang sudah disimpan. Ketika pelatihan selesai, semuanya sudah siap, Anda dapat mengenali teks.
Pengakuan
Untuk pengakuan, kami memuat model dan memanggil fungsi predict_classes.
model = keras.models.load_model('emnist_letters.h5') def emnist_predict_img(model, img): img_arr = np.expand_dims(img, axis=0) img_arr = 1 - img_arr/255.0 img_arr[0] = np.rot90(img_arr[0], 3) img_arr[0] = np.fliplr(img_arr[0]) img_arr = img_arr.reshape((1, 28, 28, 1)) result = model.predict_classes([img_arr]) return chr(emnist_labels[result[0]])
Ternyata, gambar dalam dataset awalnya diputar, jadi kita harus memutar gambar sebelum pengenalan.
Fungsi terakhir, yang menerima file dengan gambar pada input dan memberikan garis pada output, hanya membutuhkan 10 baris kode:
def img_to_str(model: Any, image_file: str): letters = letters_extract(image_file) s_out = "" for i in range(len(letters)): dn = letters[i+1][0] - letters[i][0] - letters[i][1] if i < len(letters) - 1 else 0 s_out += emnist_predict_img(model, letters[i][2]) if (dn > letters[i][1]/4): s_out += ' ' return s_out
Di sini kita menggunakan lebar karakter yang disimpan sebelumnya untuk menambahkan spasi jika jarak antar huruf lebih dari 1/4 karakter.
Contoh penggunaan:
model = keras.models.load_model('emnist_letters.h5') s_out = img_to_str(model, "hello_world.png") print(s_out)
Hasil:

Fitur yang lucu adalah bahwa jaringan saraf "membingungkan" huruf "O" dan angka "0", yang, bagaimanapun, tidak mengejutkan karena Set asli EMNIST berisi huruf dan angka
tulisan tangan yang tidak persis seperti yang dicetak. Idealnya, untuk mengenali teks layar, Anda perlu menyiapkan satu set terpisah berdasarkan font layar, dan sudah melatih jaringan saraf di atasnya.
Kesimpulan
Seperti yang Anda lihat, bukan para dewa yang membakar pot, dan apa yang sebelumnya tampak sebagai "sihir" dengan bantuan perpustakaan modern dibuat cukup sederhana.
Karena Python adalah lintas-platform, kode akan berfungsi di mana saja, di Windows, Linux, dan OSX. Like Keras porting ke iOS / Android, jadi secara teoritis, model yang terlatih juga dapat digunakan pada
perangkat seluler .
Bagi mereka yang ingin bereksperimen sendiri, kode sumbernya ada di bawah spoiler.
Seperti biasa, semua percobaan berhasil.