Kelanjutan dari terjemahan sebuah buku kecil:
"Memahami Pialang Pesan",
penulis: Jakub Korab, penerbit: O'Reilly Media, Inc., tanggal publikasi: Juni 2017, ISBN: 9781492049296.
Terjemahan selesai: tele.gg/middle_javaBagian sebelumnya:
Memahami Pialang Pesan. Mempelajari mekanisme pengiriman pesan melalui ActiveMQ dan Kafka. Bab 2. ActiveMQBAB 3
Kafka
Kafka dikembangkan di LinkedIn untuk menghindari beberapa batasan dari pialang pesan tradisional dan untuk menghindari kebutuhan untuk mengonfigurasi beberapa pialang pesan untuk interaksi titik-ke-titik yang berbeda, yang dijelaskan dalam bagian “Penskalaan Vertikal dan Horisontal” pada halaman 28 dalam buku ini. LinkedIn sangat bergantung pada penyerapan satu arah data dalam jumlah sangat besar, seperti klik halaman dan log akses, sambil memungkinkan banyak sistem untuk menggunakan data ini. am, tanpa mempengaruhi kinerja produsen atau konsyumerov lainnya. Faktanya, alasan Kafka ada adalah untuk mendapatkan arsitektur perpesanan yang dijelaskan oleh Universal Data Pipeline.
Mengingat tujuan akhir ini, persyaratan lain muncul secara alami. Kafka harus:
- Sangat cepat
- Berikan throughput perpesanan yang lebih besar
- Mendukung model Publisher-Subscriber dan Point-to-Point
- Jangan memperlambat dengan penambahan konsumen. Misalnya, kinerja antrian dan topik di ActiveMQ memburuk seiring dengan meningkatnya jumlah konsumen di tujuan.
- Dapat diskalakan secara horizontal; jika satu pesan tetap hanya dapat melakukan ini pada kecepatan disk maksimum, maka untuk meningkatkan kinerja, masuk akal untuk melampaui batas satu instance broker
- Gambarkan akses ke penyimpanan dan pengambilan pesan
Untuk mencapai semua ini, Kafka telah mengadopsi arsitektur yang mendefinisikan kembali peran dan tanggung jawab klien dan broker pesan. Model JMS sangat fokus pada broker, di mana dia bertanggung jawab atas distribusi pesan, dan pelanggan hanya perlu khawatir tentang mengirim dan menerima pesan. Kafka, di sisi lain, berorientasi pada pelanggan, dengan klien mengambil banyak fungsi dari broker tradisional, seperti distribusi adil pesan yang relevan di antara konsumen, dalam pertukaran menerima broker yang sangat cepat dan dapat diskalakan. Bagi orang yang bekerja dengan sistem pesan tradisional, bekerja dengan Kafka membutuhkan perubahan mendasar dalam sikap.
Arah teknik ini telah mengarah pada penciptaan infrastruktur perpesanan yang dapat meningkatkan throughput oleh banyak pesanan yang besar dibandingkan dengan broker konvensional. Seperti yang akan kita lihat, pendekatan ini penuh dengan kompromi, yang berarti bahwa Kafka tidak cocok untuk jenis beban tertentu dan perangkat lunak yang diinstal.
Model Tujuan Terpadu
Untuk memenuhi persyaratan yang dijelaskan di atas, Kafka menggabungkan publikasi-berlangganan dan pesan point-to-point dalam satu jenis penerima -
topik . Ini membingungkan bagi orang yang bekerja dengan sistem perpesanan, di mana kata "topik" mengacu pada mekanisme penyiaran dari mana (dari topik) pembacaan tidak dapat diandalkan (tidak dapat dipertahankan). Topik-topik Kafka harus dianggap sebagai jenis tujuan campuran, sebagaimana didefinisikan dalam pengantar buku ini.
Di sisa bab ini, kecuali jika kami secara eksplisit menentukan sebaliknya, istilah topik akan merujuk ke topik Kafka.
Untuk sepenuhnya memahami bagaimana topik berperilaku dan jaminan apa yang mereka berikan, pertama-tama kita perlu mempertimbangkan bagaimana mereka diterapkan di Kafka.
Setiap topik di Kafka memiliki jurnal sendiri.Produsen yang mengirim pesan ke Kafka menambahkan ke majalah ini, dan konsumen membaca dari majalah menggunakan petunjuk yang terus bergerak maju. Kafka secara berkala menghapus bagian tertua dari jurnal, terlepas dari apakah pesan di bagian ini dibaca atau tidak. Bagian utama dari desain Kafka adalah bahwa broker tidak peduli apakah pesan dibaca atau tidak - ini adalah tanggung jawab klien.
Istilah "jurnal" dan "indeks" tidak ditemukan dalam dokumentasi Kafka . Istilah-istilah terkenal ini digunakan di sini untuk membantu pemahaman.
Model ini sama sekali berbeda dari ActiveMQ, di mana pesan dari semua antrian disimpan dalam satu jurnal, dan broker menandai pesan setelah dihapus setelah dibaca.
Sekarang mari kita sedikit lebih dalam dan melihat majalah topik secara lebih rinci.
Majalah Kafka terdiri dari beberapa partisi (
Gambar 3-1 ). Kafka menjamin pemesanan ketat di setiap partisi. Ini berarti bahwa pesan yang ditulis ke partisi dalam urutan tertentu akan dibaca dalam urutan yang sama. Setiap partisi diimplementasikan sebagai file log bergulir (log) yang berisi
subset dari semua pesan yang dikirim ke topik oleh produsennya. Topik yang dibuat berisi satu partisi secara default. Partisi adalah ide sentral Kafka untuk penskalaan horizontal.
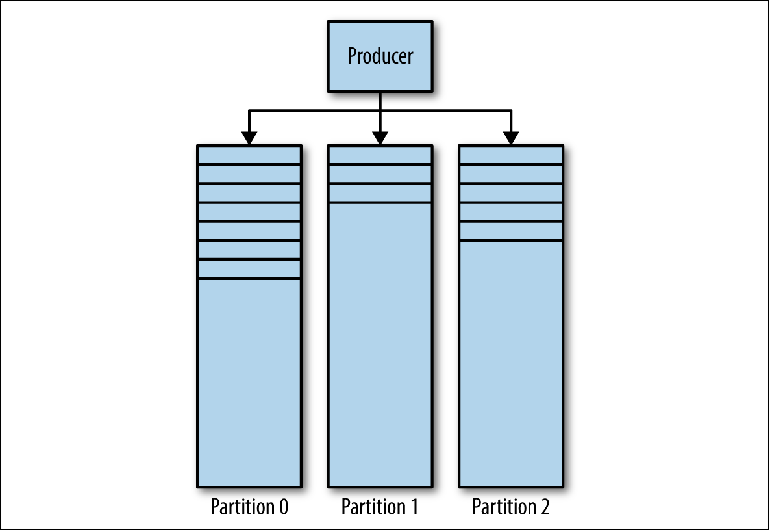 Gambar 3-1. Partisi Kafka
Gambar 3-1. Partisi KafkaKetika produser mengirim pesan ke topik Kafka, ia memutuskan partisi mana yang akan dikirimi pesan. Kami akan mempertimbangkan ini secara lebih rinci nanti.
Membaca pesan
Klien yang ingin membaca pesan mengontrol penunjuk bernama yang disebut
grup konsumen , yang menunjukkan
offset pesan dalam partisi. Offset adalah posisi dengan angka yang bertambah yang dimulai dari 0 pada awal partisi. Kelompok konsumen ini, yang dirujuk dalam API melalui group_id pengenal yang ditentukan pengguna, berhubungan dengan
satu konsumen logis atau sistem .
Sebagian besar sistem pesan membaca data dari penerima melalui beberapa kejadian dan utas untuk memproses pesan secara paralel. Dengan demikian, biasanya akan ada banyak contoh konsumen yang berbagi kelompok konsumen yang sama.
Masalah membaca dapat direpresentasikan sebagai berikut:
- Topik ini memiliki beberapa partisi
- Beberapa kelompok konsumen dapat menggunakan topik pada saat yang bersamaan.
- Sekelompok konsumen dapat memiliki beberapa contoh terpisah.
Ini adalah masalah banyak-ke-banyak nontrivial. Untuk memahami bagaimana Kafka menangani hubungan antara kelompok konsumen, contoh dari konsumen dan partisi, mari kita lihat serangkaian skrip bacaan yang semakin kompleks.
Grup Konsumen dan Konsumen
Mari kita ambil satu topik partisi sebagai titik awal (
Gambar 3-2 ).
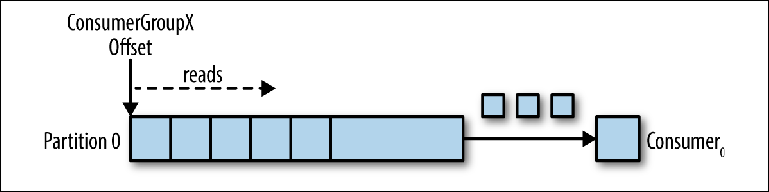 Gambar 3-2. Konsumen membaca dari partisi
Gambar 3-2. Konsumen membaca dari partisiKetika instance konsumen terhubung dengan group_id-nya sendiri ke topik ini, ia diberi partisi untuk dibaca dan offset di partisi ini. Posisi offset ini dikonfigurasikan pada klien sebagai penunjuk ke posisi terbaru (pesan terbaru) atau posisi paling awal (pesan terlama). Konsumen meminta (polling) pesan dari topik, yang mengarah ke pembacaan berurutan dari jurnal.
Posisi ofset secara teratur dikomit kembali ke Kafka dan disimpan sebagai pesan dalam topik internal
_consumer_offsets . Membaca pesan masih belum dihapus, tidak seperti broker biasa, dan klien dapat memundurkan offset untuk memproses ulang pesan yang sudah dilihat.
Ketika konsumen logis kedua terhubung menggunakan group_id lain, itu mengontrol pointer kedua yang independen dari yang pertama (
Gambar 3-3 ). Dengan demikian, topik Kafka bertindak sebagai antrian di mana ada satu konsumen dan, sebagai topik biasa, pelanggan-pelanggan (pub-sub), di mana beberapa pelanggan berlangganan, dengan keuntungan tambahan bahwa semua pesan disimpan dan dapat diproses beberapa kali.
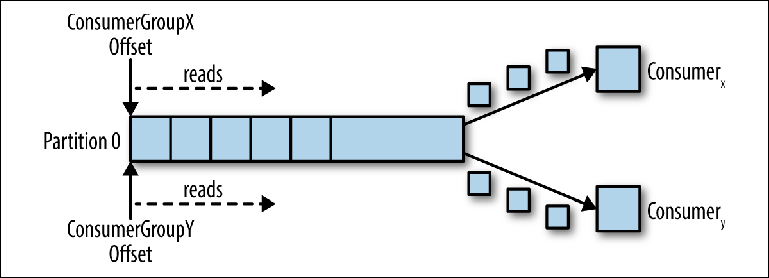 Gambar 3-3. Dua konsumen dalam kelompok konsumen yang berbeda membaca dari partisi yang sama
Gambar 3-3. Dua konsumen dalam kelompok konsumen yang berbeda membaca dari partisi yang samaKonsumen dalam Kelompok Konsumen
Ketika salah satu instance dari konsumen membaca data dari partisi, itu sepenuhnya mengontrol pointer dan memproses pesan, seperti yang dijelaskan di bagian sebelumnya.
Jika beberapa instance dari konsumen terhubung dengan group_id yang sama ke topik dengan satu partisi, maka instance yang terhubung terakhir akan diberikan kontrol atas pointer dan sejak saat itu akan menerima semua pesan (
Gambar 3-4 ).
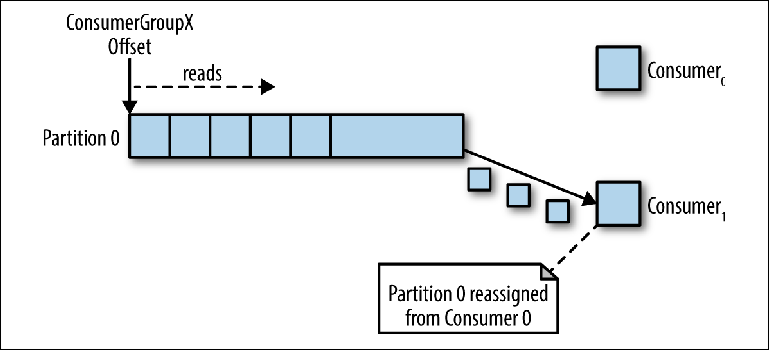 Gambar 3-4. Dua konsumen dalam kelompok konsumen yang sama membaca dari partisi yang sama
Gambar 3-4. Dua konsumen dalam kelompok konsumen yang sama membaca dari partisi yang samaMode pemrosesan ini, di mana jumlah instance konsumen melebihi jumlah partisi, dapat dianggap sebagai semacam konsumen monopoli. Ini dapat berguna jika Anda memerlukan pengelompokan "aktif-pasif" (atau "panas-hangat") dari contoh konsumen Anda, meskipun operasi paralel dari beberapa konsumen ("aktif-aktif" atau "panas-panas") jauh lebih khas daripada konsumen dalam modus siaga.
Perilaku distribusi pesan ini, dijelaskan di atas, bisa mengejutkan dibandingkan dengan bagaimana antrian JMS biasa berperilaku. Dalam model ini, pesan yang dikirim ke antrian akan didistribusikan secara merata antara dua konsumen.
Paling sering, ketika kami membuat beberapa contoh kompiler, kami melakukan ini baik untuk pemrosesan pesan paralel, atau untuk meningkatkan kecepatan membaca, atau untuk meningkatkan stabilitas proses membaca. Karena hanya satu instance dari konsumen yang dapat membaca data dari partisi, bagaimana hal ini dicapai dalam Kafka?
Salah satu cara untuk melakukan ini adalah dengan menggunakan satu instance dari konsumen untuk membaca semua pesan dan mengirimkannya ke kumpulan utas. Meskipun pendekatan ini meningkatkan throughput pemrosesan, itu meningkatkan kompleksitas logika konsumen dan tidak melakukan apa pun untuk meningkatkan stabilitas sistem membaca. Jika salah satu instance dari konsumen mati karena kegagalan daya atau peristiwa serupa, maka proofreading berhenti.
Cara kanonik untuk menyelesaikan masalah ini di Kafka adalah dengan menggunakan lebih banyak partisi.
Partisi
Partisi adalah mekanisme utama untuk memparalelkan pembacaan dan penskalaan topik di luar bandwidth dari satu instance broker. Untuk lebih memahami hal ini, mari kita lihat situasi di mana ada topik dengan dua partisi dan satu konsumen berlangganan topik ini (
Gambar 3-5 ).
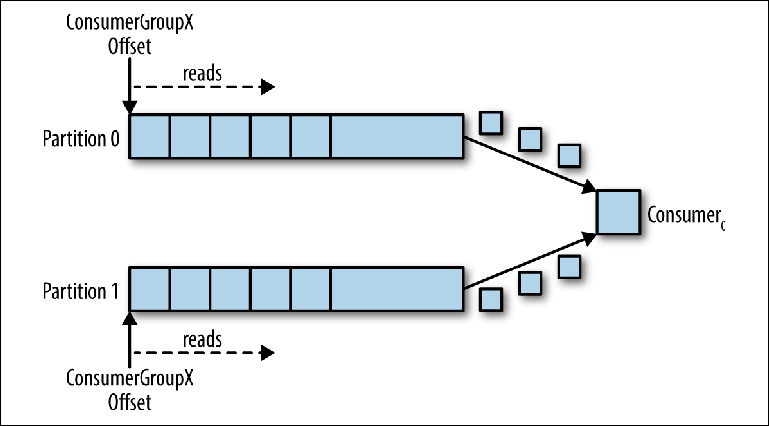 Gambar 3-5. Seorang konsumen membaca dari beberapa partisi
Gambar 3-5. Seorang konsumen membaca dari beberapa partisiDalam skenario ini, konsultan diberikan kendali atas pointer yang sesuai dengan group_id di kedua partisi, dan membaca pesan dari kedua partisi dimulai.
Ketika kompurator tambahan ditambahkan ke topik ini untuk group_id yang sama, Kafka menugaskan kembali (realokasi) salah satu partisi dari yang pertama ke yang kedua. Setelah itu, setiap instance dari konsumen akan dikurangkan dari satu partisi topik (
Gambar 3-6 ).
Untuk memastikan bahwa pesan diproses secara paralel dalam 20 utas, Anda memerlukan setidaknya 20 partisi. Jika ada lebih sedikit partisi, Anda masih akan memiliki konsumen yang tidak memiliki apa-apa untuk dikerjakan, seperti yang dijelaskan sebelumnya dalam diskusi monitor eksklusif.
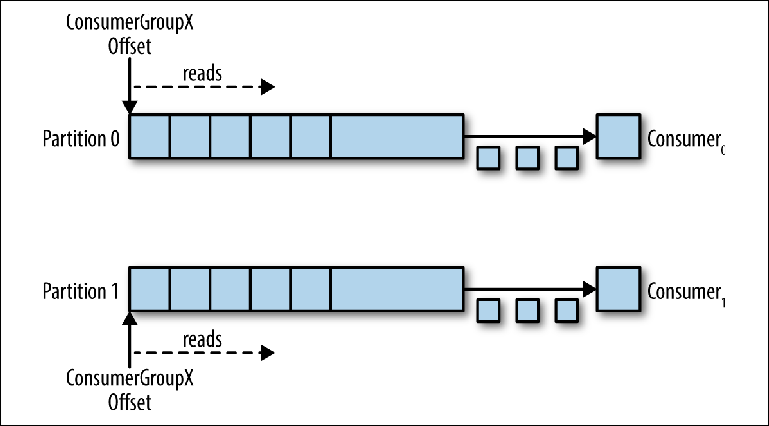 Gambar 3-6. Dua konsumen dalam kelompok konsumen yang sama membaca dari partisi yang berbeda
Gambar 3-6. Dua konsumen dalam kelompok konsumen yang sama membaca dari partisi yang berbedaSkema ini secara signifikan mengurangi kompleksitas broker Kafka dibandingkan dengan distribusi pesan yang diperlukan untuk mendukung antrian JMS. Tidak perlu mengurus hal-hal berikut:
- Konsumen mana yang harus menerima pesan berikutnya berdasarkan distribusi round-robin, kapasitas buffer prefetch saat ini, atau pesan sebelumnya (seperti untuk grup pesan JMS).
- Pesan apa yang dikirim ke konsumen mana dan harus dibenci jika terjadi kegagalan.
Semua yang harus dilakukan oleh broker Kafka adalah secara konsisten mengirim pesan kepada penasihat ketika yang terakhir meminta mereka.
Namun, persyaratan untuk memaralelkan proofreading dan mengirim ulang pesan yang gagal tidak hilang - tanggung jawab untuknya hanya berpindah dari broker ke klien. Ini berarti bahwa mereka harus diperhitungkan dalam kode Anda.
Mengirim pesan
Tanggung jawab untuk memutuskan partisi mana yang akan dikirimi pesan adalah produsen pesan. Untuk memahami mekanisme yang melaluinya ini dilakukan, pertama-tama Anda perlu mempertimbangkan apa yang sebenarnya kami kirim.
Sementara di JMS kami menggunakan struktur pesan dengan metadata (header dan properti) dan badan yang mengandung muatan, di Kafka pesannya adalah
pasangan nilai kunci . Payload pesan dikirim sebagai nilai. Kunci, di sisi lain, digunakan terutama untuk mempartisi dan harus mengandung
kunci logika bisnis khusus untuk meletakkan pesan terkait di partisi yang sama.
Dalam Bab 2, kami membahas skenario taruhan online, ketika acara terkait harus diproses secara berurutan oleh satu konsumen:
- Akun pengguna sudah dikonfigurasikan.
- Uang dikreditkan ke akun.
- Taruhan dibuat yang menarik uang dari akun.
Jika setiap peristiwa adalah pesan yang dikirim ke topik, maka dalam hal ini pengenal akun akan menjadi kunci alami.
Ketika sebuah pesan dikirim menggunakan API Produser Kafka, itu diteruskan ke fungsi partisi, yang, mengingat pesan dan keadaan saat ini dari cluster Kafka, mengembalikan pengidentifikasi partisi yang pesannya harus dikirim. Fitur ini diimplementasikan di Jawa melalui antarmuka Partitioner.
Antarmuka ini adalah sebagai berikut:
interface Partitioner { int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); }
Implementasi Partitioner menggunakan algoritma hashing tujuan umum default atas kunci atau round-robin jika kunci tidak ditentukan untuk menentukan partisi. Nilai default ini berfungsi dengan baik dalam banyak kasus. Namun, di masa depan Anda akan ingin menulis sendiri.
Menulis strategi pemartisian Anda sendiri
Mari kita lihat contoh ketika Anda ingin mengirim metadata bersama dengan payload pesan. Payload dalam contoh kami adalah instruksi untuk melakukan setoran ke akun game. Suatu instruksi adalah sesuatu yang kami ingin jamin untuk tidak dimodifikasi selama transmisi, dan kami ingin memastikan bahwa hanya sistem superior yang tepercaya yang dapat memulai instruksi ini. Dalam hal ini, sistem pengiriman dan penerimaan menyetujui penggunaan tanda tangan untuk mengotentikasi pesan.
Dalam JMS biasa, kami cukup mendefinisikan properti tanda tangan pesan dan menambahkannya ke pesan. Namun, Kafka tidak memberi kami mekanisme untuk mentransmisikan metadata - hanya kunci dan nilainya.
Karena nilainya adalah payload dari transfer bank (pay transfer bank), integritas yang ingin kami pertahankan, kami tidak punya pilihan selain menentukan struktur data untuk digunakan dalam kunci. Dengan asumsi kami membutuhkan pengenal akun untuk dipartisi, karena semua pesan yang terkait dengan akun harus diproses secara berurutan, kami akan membuat struktur JSON berikut:
{ "signature": "541661622185851c248b41bf0cea7ad0", "accountId": "10007865234" }
Karena nilai tanda tangan akan bervariasi tergantung pada payload, strategi hash antarmuka Partitioner default tidak akan secara andal mengelompokkan pesan terkait. Oleh karena itu, kita perlu menulis strategi kita sendiri, yang akan menganalisis kunci ini dan membagikan nilai dari akunId.
Kafka mencakup checksum untuk mendeteksi korupsi pesan di repositori dan memiliki serangkaian fitur keamanan lengkap. Bahkan kemudian, persyaratan spesifik industri terkadang muncul, seperti yang di atas.
Strategi partisi pengguna harus memastikan bahwa semua pesan terkait berakhir di partisi yang sama. Meskipun ini tampak sederhana, persyaratannya bisa rumit karena pentingnya memesan pesan terkait dan seberapa tetap jumlah partisi dalam topik.
Jumlah partisi dalam topik dapat berubah seiring waktu, karena dapat ditambahkan jika lalu lintas melampaui harapan awal. Dengan demikian, kunci pesan dapat dikaitkan dengan partisi yang awalnya dikirim, menyiratkan bagian dari negara yang harus didistribusikan antara instance produsen.
Faktor lain yang perlu dipertimbangkan adalah distribusi seragam dari pesan antar partisi. Sebagai aturan, kunci tidak didistribusikan secara merata di seluruh pesan, dan fungsi hash tidak menjamin distribusi pesan yang adil untuk sekumpulan kunci kecil.
Penting untuk dicatat bahwa, tidak peduli bagaimana Anda memutuskan untuk membagi pesan, pemisah itu sendiri mungkin perlu digunakan kembali.
Pertimbangkan persyaratan untuk replikasi data antara kelompok Kafka di lokasi geografis yang berbeda. Untuk tujuan ini, Kafka dilengkapi dengan alat baris perintah yang disebut MirrorMaker, yang digunakan untuk membaca pesan dari satu cluster dan mentransfernya ke yang lain.
MirrorMaker harus memahami kunci dari topik yang direplikasi untuk mempertahankan urutan relatif antara pesan selama replikasi antar cluster, karena jumlah partisi untuk topik ini mungkin tidak bertepatan dalam dua cluster.
Strategi partisi kustom relatif jarang, karena hash default atau round robin bekerja dengan sukses di sebagian besar skenario. Namun, jika Anda memerlukan jaminan pemesanan yang ketat atau Anda perlu mengekstrak metadata dari payload, partisi adalah sesuatu yang harus Anda perhatikan lebih dekat.
Skalabilitas dan manfaat kinerja Kafka berasal dari mentransfer beberapa tanggung jawab broker tradisional kepada klien. Dalam hal ini, keputusan dibuat pada distribusi pesan yang berpotensi terkait di antara beberapa konsumen yang bekerja secara paralel.
Broker JMS juga harus berurusan dengan persyaratan tersebut. Menariknya, mekanisme untuk mengirim pesan terkait ke akun yang sama diimplementasikan melalui Grup Pesan JMS (semacam strategi penyeimbangan sticky load balancing (SLB)) juga mengharuskan pengirim untuk menandai pesan yang terkait. Dalam kasus JMS, broker bertanggung jawab untuk mengirim grup ini pesan terkait ke salah satu dari banyak pelanggan dan mengalihkan kepemilikan grup jika pelanggan telah jatuh.
Perjanjian produsen
Partisi bukan satu-satunya hal yang perlu dipertimbangkan saat mengirim pesan. Mari kita lihat metode send () dari kelas Produser di Java API:
Future < RecordMetadata > send(ProducerRecord < K, V > record); Future < RecordMetadata > send(ProducerRecord < K, V > record, Callback callback);
Harus segera dicatat bahwa kedua metode mengembalikan Masa Depan, yang menunjukkan bahwa operasi pengiriman tidak dilakukan segera. Akibatnya, ternyata pesan (ProducerRecord) ditulis ke buffer kirim untuk setiap partisi aktif dan dikirim ke broker di aliran latar belakang di perpustakaan klien Kafka. Meskipun ini membuat pekerjaan menjadi sangat cepat, itu berarti bahwa aplikasi yang tidak berpengalaman dapat kehilangan pesan jika prosesnya dihentikan.
Seperti biasa, ada cara untuk membuat operasi pengiriman lebih dapat diandalkan karena kinerja. Ukuran buffer ini dapat diatur ke 0, dan utas aplikasi pengirim akan dipaksa untuk menunggu hingga pesan dikirim ke broker, sebagai berikut:
RecordMetadata metadata = producer.send(record).get();
Sekali lagi tentang membaca pesan
Membaca pesan memiliki kesulitan tambahan yang perlu dipertimbangkan. Tidak seperti JMS API, yang dapat memulai pendengar pesan sebagai respons terhadap pesan, antarmuka Kafka
Konsumen hanya melakukan polling. Mari kita lihat lebih dekat pada
polling () metode yang digunakan untuk tujuan ini:
ConsumerRecords < K, V > poll(long timeout);
Nilai kembali dari metode ini adalah struktur kontainer yang berisi beberapa objek
ConsumerRecord dari beberapa partisi yang berpotensi.
ConsumerRecord sendiri adalah objek pemegang untuk pasangan kunci-nilai dengan metadata terkait, seperti partisi dari mana ia berasal.
Seperti dibahas dalam Bab 2, kita harus terus-menerus mengingat apa yang terjadi pada pesan setelah mereka berhasil atau tidak berhasil diproses, misalnya, jika klien tidak dapat memproses pesan atau jika itu mengganggu pekerjaan. Di JMS, ini ditangani melalui mode pengakuan. Pialang akan menghapus pesan yang berhasil diproses, atau mengirim kembali pesan mentah atau terbalik (asalkan transaksi telah digunakan).
Kafka bekerja dengan cara yang sangat berbeda. Pesan tidak dihapus di broker setelah proofreading, dan tanggung jawab untuk apa yang terjadi setelah kegagalan terletak pada kode itu sendiri.
Seperti yang sudah kami katakan, sekelompok konsumen dikaitkan dengan offset di majalah. Posisi log yang terkait dengan bias ini sesuai dengan pesan berikutnya yang akan dikeluarkan sebagai tanggapan terhadap
jajak pendapat () . Penting dalam membaca adalah saat ketika offset ini meningkat.
Kembali ke model membaca yang dibahas sebelumnya, pemrosesan pesan terdiri dari tiga tahap:
- Ambil pesan untuk dibaca.
- Memproses pesan.
- Konfirmasikan pesan.
Penasihat Konsumen Kafka hadir dengan
opsi konfigurasi
enable.auto.commit . Ini adalah pengaturan default yang umum digunakan, seperti biasanya halnya dengan pengaturan yang mengandung kata "auto".
Sebelum Kafka 0.10, klien yang menggunakan parameter ini mengirim ofset pesan terakhir yang dibaca pada panggilan berikutnya
() setelah pemrosesan. Ini berarti bahwa setiap pesan yang sudah diambil dapat diproses ulang jika klien sudah memprosesnya, tetapi secara tak terduga dihancurkan sebelum memanggil
polling () . Karena pialang tidak mempertahankan status apa pun tentang berapa kali pesan telah dibaca, konsumen berikutnya yang mengambil pesan ini tidak akan tahu bahwa sesuatu yang buruk telah terjadi. Perilaku ini transaksional semu. Offset hanya dilakukan jika berhasil memproses pesan, tetapi jika klien menyela, broker kembali mengirim pesan yang sama ke klien lain. Perilaku ini konsisten dengan jaminan pengiriman pesan "
setidaknya satu kali ".
Dalam Kafka 0.10, kode klien diubah sedemikian rupa sehingga komit mulai secara berkala dimulai oleh perpustakaan klien, sesuai dengan pengaturan
auto.commit.interval.ms . Perilaku ini berada di antara mode JMS AUTO_ACKNOWLEDGE dan DUPS_OK_ACKNOWLEDGE. Ketika menggunakan komit otomatis, pesan dapat dikonfirmasi terlepas dari apakah mereka benar-benar diproses - ini bisa terjadi dalam kasus konsumen yang lambat. Jika compurator terputus, pesan diambil oleh kompurator berikutnya, mulai dari posisi aman, yang dapat menyebabkan pesan dilewati. Dalam hal ini, Kafka tidak kehilangan pesan, kode bacaan tidak memprosesnya.
Mode ini memiliki prospek yang sama seperti dalam versi 0.9: pesan dapat diproses, tetapi jika terjadi kegagalan, offset mungkin tidak ditutup, yang berpotensi menyebabkan duplikasi pengiriman. Semakin banyak pesan yang Anda ambil saat melakukan
polling () , semakin besar masalah ini.
Sebagaimana dibahas dalam bagian "Mengurangi Pesan dari Antrian" pada
Bab 2 , tidak ada pengiriman pesan satu kali dalam sistem pengiriman pesan, mengingat mode kegagalan.
Di Kafka, ada dua cara untuk memperbaiki (melakukan) offset (offset): otomatis dan manual. Dalam kedua kasus, pesan dapat diproses beberapa kali, jika pesan diproses tetapi gagal sebelum melakukan. Anda juga tidak dapat memproses pesan sama sekali jika komit terjadi di latar belakang dan kode Anda selesai sebelum mulai diproses (mungkin di Kafka 0.9 dan versi sebelumnya).
Anda dapat mengontrol proses melakukan offset secara manual di Kafka
Consumer API dengan mengatur
enable.auto.commit untuk false dan secara eksplisit memanggil salah satu metode berikut:
void commitSync(); void commitAsync();
Jika Anda ingin memproses pesan "setidaknya sekali", Anda harus melakukan offset secara manual menggunakan
commitSync () dengan menjalankan perintah ini segera setelah memproses pesan.
Metode-metode ini tidak memungkinkan pesan untuk diakui sebelum diproses, tetapi mereka tidak melakukan apa pun untuk menghilangkan duplikasi pemrosesan yang potensial, sementara pada saat yang sama menciptakan tampilan transaksionalitas. Kafka tidak memiliki transaksi. Klien tidak memiliki kesempatan untuk melakukan hal berikut:
- Secara otomatis memutar kembali pesan rollback. Konsumen sendiri harus menangani pengecualian yang muncul dari muatan bermasalah dan pemutusan sambungan, karena mereka tidak dapat mengandalkan broker untuk mengirim kembali pesan.
- Kirim pesan ke beberapa topik dalam satu operasi atom. Seperti yang akan kita lihat nanti, kontrol atas berbagai topik dan partisi dapat ditemukan di berbagai mesin di cluster Kafka, yang tidak mengoordinasikan transaksi saat mengirim. Pada saat penulisan ini, beberapa pekerjaan telah dilakukan untuk memungkinkan hal ini dengan KIP-98.
- Kaitkan membaca satu pesan dari satu topik dengan mengirim pesan lain ke topik lain. Sekali lagi, arsitektur Kafka tergantung pada banyak mesin independen yang bekerja sebagai satu bus dan tidak ada upaya untuk menyembunyikannya. Misalnya, tidak ada komponen API yang memungkinkan Konsumen dan Produser untuk ditautkan dalam transaksi. Dalam JMS, ini disediakan oleh objek Sesi dari mana MessageProducers dan MessageConsumers dibuat.
Jika kita tidak bisa mengandalkan transaksi, bagaimana kita bisa menyediakan semantik yang lebih dekat dengan yang disediakan oleh sistem pesan tradisional?
Jika ada kemungkinan bahwa offset konsumen dapat meningkat sebelum pesan diproses, misalnya, selama kegagalan pelanggan, maka pelanggan tidak akan tahu apakah grup pelanggan telah melewatkan pesan ketika ia diberi partisi. Dengan demikian, salah satu strategi adalah memundurkan offset ke posisi sebelumnya. API Penasihat Konsumen Kafka menyediakan metode berikut untuk ini:
void seek(TopicPartition partition, long offset); void seekToBeginning(Collection < TopicPartition > partitions);
Metode
seek () dapat digunakan dengan metode tersebut
offsetsForTimes (Peta <TopicPartition, Long> timestampsToSearch) untuk mundur ke keadaan pada titik tertentu di masa lalu.
Secara implisit, menggunakan pendekatan ini berarti sangat mungkin bahwa beberapa pesan yang diproses sebelumnya akan dibaca dan diproses lagi. Untuk menghindari hal ini, kita dapat menggunakan pembacaan idempoten, seperti dijelaskan dalam Bab 4, untuk melacak pesan yang dilihat sebelumnya dan menghilangkan duplikat.
Sebagai alternatif, kode konsumen Anda dapat menjadi sederhana jika kehilangan atau duplikasi pesan diizinkan. Ketika kami mempertimbangkan skenario penggunaan yang biasanya digunakan Kafka, misalnya, memproses peristiwa log, metrik, pelacakan klik, dll., Kami memahami bahwa hilangnya masing-masing pesan tidak akan berdampak signifikan pada aplikasi di sekitarnya. Dalam kasus tersebut, nilai default dapat diterima. Di sisi lain, jika aplikasi Anda perlu mentransfer pembayaran, Anda harus hati-hati mengurus setiap pesan individu. Itu semua bermuara pada konteks.
Pengamatan pribadi menunjukkan bahwa dengan meningkatnya intensitas pesan, nilai setiap pesan individu menurun. Pesan bervolume tinggi cenderung menjadi berharga jika dilihat dalam bentuk agregat.
Ketersediaan Tinggi
Pendekatan ketersediaan tinggi Kafka sangat berbeda dari ActiveMQ. Kafka dikembangkan berdasarkan kelompok yang dapat diskalakan secara horizontal di mana semua instance broker menerima dan mendistribusikan pesan secara bersamaan.
Cluster Kafka terdiri dari beberapa instance broker yang berjalan di server yang berbeda. Kafka dirancang untuk bekerja pada perangkat keras mandiri konvensional, di mana setiap node memiliki penyimpanan khusus sendiri. Menggunakan Network Attached Storage (SAN) tidak dianjurkan karena beberapa node komputasi dapat bersaing untuk slot waktu penyimpanan dan menciptakan konflik.
Kafka adalah sistem yang
konstan . Banyak pengguna Kafka besar tidak pernah memadamkan kelompok mereka dan perangkat lunak selalu memberikan pembaruan melalui restart yang konsisten. Ini dicapai dengan menjamin kompatibilitas dengan versi sebelumnya untuk pesan dan interaksi antara broker.
Broker terhubung ke
cluster server
ZooKeeper , yang bertindak sebagai registri konfigurasi yang diberikan dan digunakan untuk mengoordinasikan peran masing-masing broker. ZooKeeper sendiri adalah sistem terdistribusi yang menyediakan ketersediaan tinggi melalui replikasi informasi dengan membentuk
kuorum .
Dalam kasus dasar, topik dibuat di cluster Kafka dengan properti berikut:
- Jumlah partisi. Seperti dibahas sebelumnya, nilai tepat yang digunakan di sini tergantung pada tingkat bacaan yang diinginkan secara bersamaan.
- Koefisien replikasi (faktor) menentukan berapa banyak instance broker dalam cluster yang harus berisi log untuk partisi ini.
Menggunakan ZooKeepers untuk koordinasi, Kafka mencoba untuk secara adil mendistribusikan partisi baru antara broker di cluster. Ini dilakukan oleh satu instance, yang bertindak sebagai Controller.
Dalam runtime
untuk setiap partisi topik, Pengendali memberikan kepada broker peran
pemimpin (pemimpin, master, pemimpin) dan
pengikut (pengikut, budak, bawahan). Pialang, bertindak sebagai pemimpin untuk partisi ini, bertanggung jawab untuk menerima semua pesan yang dikirim kepadanya oleh produsen, dan mendistribusikan pesan kepada konsumen. Saat mengirim pesan ke partisi topik, mereka direplikasi ke semua simpul broker yang bertindak sebagai pengikut untuk partisi ini. Setiap node yang berisi log untuk partisi disebut
replika . Seorang broker dapat bertindak sebagai pemimpin untuk beberapa partisi dan sebagai pengikut untuk yang lain.
Seorang pengikut yang berisi semua pesan yang disimpan oleh pemimpin disebut
replika tersinkronisasi (replika dalam keadaan tersinkronisasi, replika in-sync). Jika pialang yang bertindak sebagai pemimpin untuk partisi terputus, pialang yang dalam keadaan diperbarui atau disinkronkan untuk partisi ini dapat mengambil peran sebagai pemimpin. Ini adalah desain yang sangat berkelanjutan.
Bagian dari konfigurasi produsen adalah parameter
acks , yang menentukan berapa banyak replika yang harus mengakui penerimaan pesan sebelum aliran aplikasi melanjutkan pengiriman: 0, 1 atau semua. Jika nilainya diatur ke
semua , maka ketika pesan diterima, pemimpin akan mengirimkan konfirmasi kembali ke produser segera setelah ia menerima konfirmasi dari beberapa replika (termasuk dirinya sendiri) yang ditentukan oleh
pengaturan topik
min.insync.replicas (secara default 1). Jika pesan tidak berhasil direplikasi, maka produser akan mengeluarkan pengecualian untuk aplikasi (
NotEnoughReplicas atau
NotEnoughReplicasAfterAppend ).
Dalam konfigurasi tipikal, topik dibuat dengan koefisien replikasi 3 (1 pemimpin, 2 pengikut untuk setiap partisi) dan parameter min.insync.replicas diatur ke 2. Dalam kasus ini, klaster akan memungkinkan salah satu pialang yang mengelola partisi terputus tanpa mempengaruhi aplikasi klien.Ini membawa kita kembali ke kompromi yang sudah lazim antara kinerja dan keandalan. Replikasi terjadi karena waktu tunggu tambahan untuk ucapan terima kasih (followers) dari pengikut. Meskipun, karena berjalan secara paralel, replikasi setidaknya tiga node memiliki kinerja yang sama dengan dua (mengabaikan peningkatan penggunaan bandwidth jaringan).Menggunakan skema replikasi ini, Kafka secara cerdik menghindari kebutuhan untuk secara fisik menulis setiap pesan ke disk menggunakan operasi sinkronisasi () . Setiap pesan yang dikirim oleh produser akan ditulis ke log partisi, tetapi, seperti dibahas dalam Bab 2, penulisan ke file pada awalnya dilakukan di buffer sistem operasi. Jika pesan ini direplikasi ke instance Kafka lain dan ada dalam ingatannya, kehilangan seorang pemimpin tidak berarti bahwa pesan itu sendiri hilang - replika yang disinkronkan dapat mengambilnya sendiri.Menyisih dari sinkronisasi () operasiberarti Kafka dapat menerima pesan dengan kecepatan yang dapat ditulisnya ke memori. Sebaliknya, semakin lama Anda dapat menghindari pembilasan memori ke disk, semakin baik. Karena alasan ini, tidak jarang pialang Kafka mengalokasikan 64 GB atau lebih memori. Penggunaan memori ini berarti bahwa satu instance Kafka dapat dengan mudah bekerja pada kecepatan ribuan kali lebih cepat daripada broker pesan tradisional.Kafka juga dapat dikonfigurasi untuk menggunakan sinkronisasi ()ke paket pesan. Karena semua yang ada di Kafka berorientasi pada paket, sebenarnya berfungsi cukup baik untuk banyak kasus penggunaan dan merupakan alat yang berguna bagi pengguna yang membutuhkan jaminan yang sangat kuat. Sebagian besar kinerja murni Kafka terkait dengan pesan yang dikirim ke broker dalam bentuk paket, dan fakta bahwa pesan ini dibaca dari broker dalam blok berturut-turut menggunakan operasi zero-copy (operasi yang tidak melakukan tugas menyalin data dari satu area memori ke lain). Yang terakhir adalah keuntungan besar dalam hal kinerja dan sumber daya dan hanya dimungkinkan melalui penggunaan struktur data log yang mendasari yang mendefinisikan skema partisi.Dalam sebuah cluster Kafka, kinerja yang jauh lebih tinggi dimungkinkan daripada ketika menggunakan broker Kafka tunggal, karena partisi topik dapat diskalakan secara horizontal pada banyak mesin yang terpisah.Ringkasan
Dalam bab ini, kami memeriksa bagaimana arsitektur Kafka menginterpretasikan ulang hubungan antara klien dan broker untuk menyediakan jalur perpesanan yang sangat kuat, dengan throughput berkali-kali lebih besar daripada broker pesan biasa. Kami membahas fungsionalitas yang digunakannya untuk mencapai tujuan ini, dan secara singkat meninjau arsitektur aplikasi yang menyediakan fungsionalitas ini. Dalam bab berikutnya, kita akan membahas masalah umum yang perlu dipecahkan oleh aplikasi pengiriman pesan dan membahas strategi untuk menyelesaikannya. Kami menyimpulkan bab ini dengan menguraikan cara berbicara tentang teknologi pengiriman pesan secara umum sehingga Anda dapat mengevaluasi kesesuaiannya dengan kasus penggunaan Anda.Terjemahan selesai: tele.gg/middle_javaAkan dilanjutkan ...