Di Internet, captcha masih tetap relevan, yang sebagai opsi menawarkan untuk mendengarkan teks dari gambar dengan mengklik tombol yang sesuai. Jika seseorang terbiasa dengan gambar di bawah ini dan / atau tertarik pada cara menyiasatinya menggunakan sistem pengenalan suara offline, disarankan untuk membacanya.
Kami tidak akan menyiksa intrik para ahli di bidang pengenalan ucapan, segera menyatakan bahwa tidak ada sistem pengenalan suara yang dipatenkan untuk tujuan yang disebutkan telah dikembangkan. Artikel ini menggunakan Pocketsphinx tua yang bagus, tetapi dengan tingkat penyesuaian tertentu.
Persiapan
"Anda berlari ke kantor pesaing yang memiliki kontrol suara di komputer, berteriak" Era Sudo minus Eref Home "dan melarikan diri." Dari komentar.
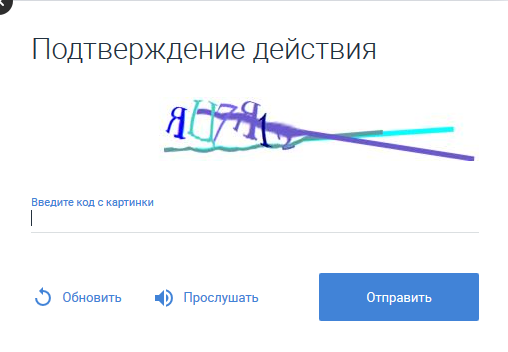
Jadi, captcha menawarkan untuk mendengarkan dirinya sendiri dengan mengklik tombol yang sesuai. Jika Anda menyimpan file suara yang dihasilkan, Anda bisa mencari tahu seperti apa audio pendek di .mp3. Pada saat yang sama, ternyata, captcha ditawarkan dengan akting suara dalam suara wanita atau pria. "Gambar" dari suara yang sama yang dibuat oleh pria dan wanita berbeda:
Mereka membunyikan kedua huruf (dan Rusia), dan angka.
Sekilas, semuanya menyedihkan. Tetapi ada poin positif di mana suara untuk huruf yang sama bertepatan.
Sejauh ini, pengetahuan ini tidak banyak membantu. Bagaimana cara mendorong semua ini ke dalam paket Sphinx?
Instal Pocketsphinx, model suara Rusia
* Ada
artikel tentang Habré di mana suara dimasukkan ke penerjemah google online melalui pengalihan output suara. Dan ini bisa menyelesaikan posting ini, jika semua ini berhasil untuk kasus ini.
Memasang Pocketsphinx sendiri di windows (dan juga di linux) tidak terlalu rumit -
unduh , instal.
Karena secara default pocketsphinx hadir dengan bahasa Inggris, model akustik, kamus, Anda akan memerlukan semua yang sama untuk bahasa Rusia.
Unduh versi Rusia -
tautan .
Setelah membongkar model Rusia dalam struktur file, Anda dapat mencoba tes .wav file decoder-text.wav dengan kode python berikut:
import os from pocketsphinx import AudioFile, get_model_path, get_data_path
Isi file audio harus ditampilkan pada baris: "Ilya Ilf Evgeny Petrov Golden Calf."
Jika tidak menghasilkan (seperti dalam situasi saya), maka Anda perlu mengkonversi decoder-test.wav ke format audio lain.
Anda perlu ffmpeg untuk ini.
Ffmpeg
Setelah mengunduh utilitas ffmpeg, masukkan decoder-test.wav di C: \ python3 \ ffmpeg \ bin.
Selanjutnya, konversikan baris perintah:
ffmpeg -i decoder-test.wav -ar 16000 decoder-test-.wav
Selanjutnya, perbaiki tautan ke file audio sumber dalam kode python:
'audio_file': os.path.join(data_path, 'C://python3//decoder-test-.wav'),
Sekarang, setelah mengerjakan kode:

Benar, Anda harus menunggu sampai kedatangan kedua, kodenya bekerja sangat lambat - sekitar 20 detik.
Kami mengonversi captcha audio dengan prinsip yang sama dari mp3 ke wav dan mengumpankan audio dari captcha. Lihatlah kodenya:

Semacam ketidaktahuan, tetapi ada hasilnya. Akan jauh lebih buruk jika tidak ada yang keluar. Seperti suara wanita:

Mari kita lihat bagaimana cara meningkatkan hasil dan sekaligus mempercepatnya.
Kosakata
Anda akan membutuhkan kamus Anda sendiri. Dalam hal ini, itu akan terdiri dari semua huruf alfabet Rusia (kecuali untuk b, s, b) dan angka.
Semua karakter harus ditempatkan dalam file teks biasa, satu pada setiap baris dalam pengkodean UTF-8.
Sekarang Anda perlu mengonversi kamus.
Anda harus menginstal perl (diperlukan agar konverter berfungsi).
Selanjutnya, unduh proyek untuk mengonversi
ru4sphinx .
Dan konversi kamus yang dibuat sebelumnya:
C:\ru4sphinx-master\ru4sphinx-master\text2dict> perl dict2transcript.pl my_dictionary.txt my_dictionary_out.txt.
Outputnya adalah kamus untuk bekerja:

Ekstensi kamus harus diganti nama dari .txt ke format .dic, dan file itu sendiri harus diletakkan di tempat yang dapat diakses.
Dalam kode python, kami akan menunjukkan lokasi kamus dengan mengomentari kamus lama:
Jalankan melalui program dan lihat hasilnya:

Lebih baik, tetapi sama lambatnya, dan tidak semua huruf diidentifikasi dengan benar.
Buat model Anda sendiri
Ini secara signifikan akan meningkatkan kecepatan kerja dan sedikit akurasi hasilnya.
Mari kita pergi jauh dari
instruksi .
Ikuti
tautan dan unggah kamus kami, yang sebelumnya dibuat dalam format .txt (bukan .dic!) Ke situs web:
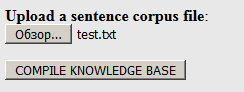
Klik "Kompilasi ...". Pada output, Anda dapat mengunduh paket yang dihasilkan di arsip .tgz (berisi semua file yang diperlukan):
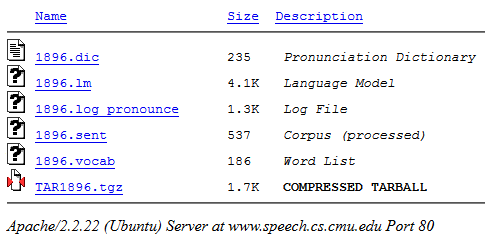
Selanjutnya, kami mengambil file dengan ekstensi .lm (model kami) dari arsip.
Mari kita perbaiki skrip pengenalan python dengan mengganti model dengan yang baru dibuat:
Kami mencoba:

Ini bekerja jauh lebih cepat - kurang dari satu detik, di samping itu, semua huruf didefinisikan.
Tapi di sini sedikit komentar diperlukan.
Tidak semua karakter dikenali dengan benar, dan jika alih-alih huruf yang benar, karakter yang berbeda ditampilkan, maka Anda dapat secara manual memperbaiki kamus .dic yang dibuat sebelumnya dengan mencocokkan korespondensi surat tersebut.
Misalnya, alih-alih huruf a, menampilkan e. Diperlukan untuk mengambil garis dari kamus e:
rydan
mentransfer (menghapus yang lama) itu, mengubah surat itu:
ryTetapi karena huruf "a" sudah ada di kamus, maka Anda perlu menambahkan "(2)" (atau 3,4) ke surat itu, secara umum, nomor seri, tergantung pada berapa banyak suara yang sudah ada dalam kamus:
a(2) ryKonversi ulang kamus tidak perlu dilakukan. Sedemikian sederhana sehingga Anda dapat "mengambil" fonem dari semua huruf, hampir.
Cherchez la femme
Model dan kerja kosa kata, tetapi tidak dengan suara wanita. Jika suara captcha adalah wanita, maka kita tidak mendapatkan apa-apa di output. Ini baik dan buruk pada saat bersamaan. Pertama tentang yang baik.
Jika Anda tidak mengenali apa pun saat memulai program, itu berarti kami berhadapan dengan suara wanita, sehingga Anda dapat memfilter captcha "wanita".
Tetapi apa yang harus dilakukan dengan mereka?
Di sini Anda perlu bekerja dengan konversi.
Misalnya, dengan captcha "pria", frekuensinya adalah 16000, dan untuk "captcha" wanita 24000:
ffmpeg -i acap(3).mp3 -ar 24000 acap(3)2.wav

Semua suara didefinisikan (di setiap baris dengan suara), tetapi korespondensinya lemah.
Lebih baik membuat kamus terpisah untuk model wanita dan kemudian mengeditnya.
Namun, ini untuk belajar sendiri.
Tautan yang bermanfaat:
1.home-smart-home.ru/raspberry-pi-pocketsphinx-offlajn-raspoznavanie-rechi-i-upravlenie-golosom2.https: //itnan.ru/post.php? C = 1 & p = 351376
3.
ru.wikipedia.org/wiki/Cherchez_la_femmeFile:
1.
Program .
2.
Model .
3.
Model Rusia .
4.
Kamus .
5.
Uji captcha .
6.
ffmpeg .
7.
Satu pak captcha .