Hai Dari tajuk utama, Anda sudah mengerti apa yang akan saya bicarakan. Akan ada banyak hardcore:
kita akan membahas Java, C, C ++, assembler, sedikit Linux, sedikit kernel sistem operasi. Kami juga akan menganalisis kasus praktis, jadi artikelnya akan menjadi tiga bagian besar (cukup banyak).
Pada bagian pertama, kami akan mencoba memeras segala sesuatu dari profiler yang ada.
Di bagian kedua, kami akan membuat profiler kecil kami sendiri, dan di bagian ketiga kita akan melihat bagaimana cara membuat profil yang tidak biasa untuk profil, karena alat yang ada tidak begitu cocok untuk ini. Jika Anda siap untuk pergi dengan cara ini - Saya menunggu Anda di bawah potongan :)
Isi
Waktu dan sarana pemahaman - profiler
Dari sudut pandang sehari-hari, 1 detik sangat kecil. Tetapi kita tahu bahwa 1 detik adalah satu miliar nanodetik. Dan biarkan dibutuhkan sekitar 4 siklus prosesor hanya dalam 1 nanodetik, dalam 1 detik banyak hal dilakukan di komputer yang dapat meningkatkan atau memperburuk kehidupan kita.
Misalkan kita sedang mengembangkan aplikasi yang dengan sendirinya cukup kritis untuk mempercepat, dan untuk beberapa fragmen kode ini umumnya kritis. Potongan-potongan ini dieksekusi, katakanlah, ratusan mikrodetik - cukup cepat, tetapi mereka [
bagian kode ] secara langsung mempengaruhi keberhasilan aplikasi kita dan jumlah uang yang diperoleh atau hilang. Sebagai contoh
saat mengirim pesanan untuk menyelesaikan transaksi pertukaran, keterlambatan 100 mikrodetik mungkin menelan biaya pertukaran 1 juta rubel atau lebih pada setiap transaksi, yang diselesaikan oleh satu, bukan dua, atau bahkan tidak seratus.
Dan
tugas telah ditetapkan untuk saya: di satu sisi, Anda harus mengirim semua pesanan pada saat yang sama, dan di sisi lain, mengirimkannya sehingga varians antara yang pertama dan terakhir minimal. Artinya, itu perlu untuk profil fungsi yang mengirim pesanan ke bursa. Tugas khas, kecuali untuk satu nuansa kecil: waktu eksekusi karakteristik dari fungsi ini
secara signifikan kurang dari 100 μs .
Mari kita pikirkan bagaimana kita membuat profil 100 μs ini untuk memahami apa yang terjadi di dalam.
Apa yang harus dipertimbangkan ketika memilih alat ini?
- Bagian kode yang menarik minat kita jarang dieksekusi, yaitu, 100 mikrodetik dieksekusi di suatu tempat satu detik sekali. Dan ini ada di bangku tes, dan dalam produksi lebih sedikit lagi.
- Sepotong kode ini akan sulit untuk diisolasi ke dalam microbenchmark, karena mempengaruhi sebagian besar proyek, dan bahkan input / output melalui jaringan.
- Dan akhirnya, yang paling penting, saya ingin profil yang dihasilkan sesuai dengan perilaku yang akan ada di server produksi kami.
Bagaimana kita memperhitungkan semua nuansa ini dan membuat profil metode minat yang benar?
Secara konseptual, semua profiler dapat dibagi menjadi dua kelompok profiler yang
menginstruksikan atau
mengambil sampel . Mari kita pertimbangkan setiap kelompok secara terpisah.
Tooler profiler menyumbang banyak overhead karena mereka memodifikasi bytecode kami dan memasukkan catatan waktu ke dalamnya. Oleh karena itu kelemahan utama dari profiler tersebut: mereka dapat secara signifikan mempengaruhi kode yang dapat dieksekusi. Akibatnya, akan sulit untuk mengatakan seberapa banyak profil yang dihasilkan cocok dengan perilaku di server produksi: beberapa optimasi mungkin bekerja secara berbeda, beberapa terjadi, dan beberapa tidak. Mungkin, pada skala waktu lain - detik, menit, jam - kami akan mendapatkan data representatif. Tetapi pada skala 100 μs, optimisasi yang dipicu atau gagal dapat menyebabkan profil benar-benar tidak representatif. Jadi mari kita lihat lebih dekat kelompok profiler lain.
Profiler sampel berkontribusi baik overhead minimal atau sedang. Alat-alat ini tidak secara langsung mempengaruhi kode yang dapat dieksekusi, dan penggunaannya memerlukan sedikit perhatian dari Anda. Karena itu, kita akan membahas profiler samping. Mari kita lihat data apa dan dalam bentuk apa kita akan menerima darinya.
Bagaimana cara kerja sampel profiler?
Untuk memahami bagaimana profiler pengambilan sampel bekerja, pertimbangkan contoh berikut - metode
sendToMoex memanggil beberapa metode lain. Kami melihat:
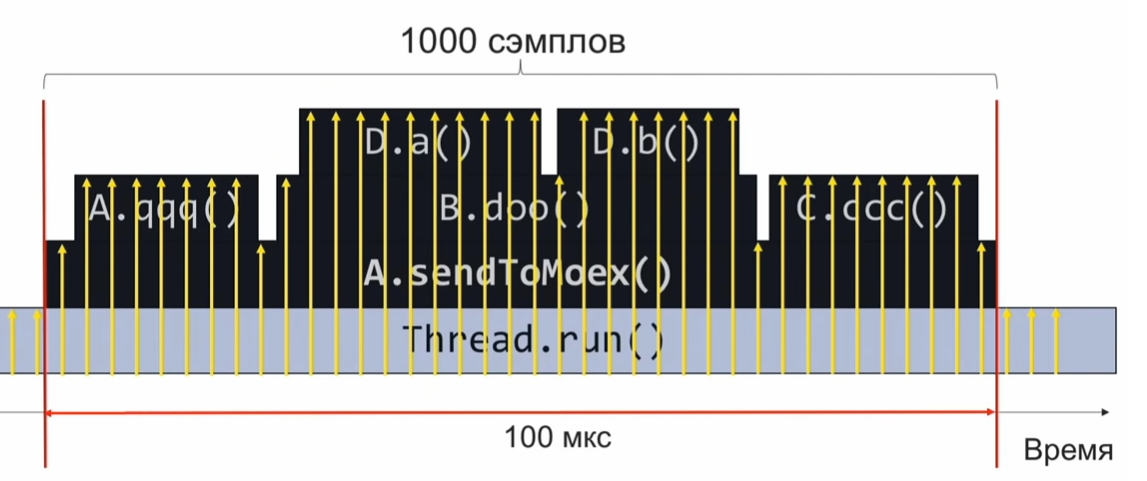
void sendToMoex() { a.qqq(); b.doo(); c.ccc() } void doo() { da(); db(); }
Jika kami memantau keadaan tumpukan panggilan pada saat pelaksanaan bagian program ini dan secara berkala merekamnya, kami akan mendapatkan informasi dalam kira-kira bentuk berikut:

Ini adalah satu set tumpukan panggilan. Dengan asumsi bahwa sampel terdistribusi secara merata, jumlah tumpukan yang identik menunjukkan waktu eksekusi relatif dari metode yang ada di atas tumpukan.
Dalam contoh ini, metode Da dilakukan sebanyak metode C.ccc, dan ini adalah 2 kali lebih banyak daripada metode Db.Namun, asumsi bahwa distribusi sampel bahkan mungkin tidak sepenuhnya benar, dan kemudian perkiraan waktu eksekusi akan salah.
Seberapa sering kita perlu mengambil sampel?
Misalkan kita ingin mengambil 1000 sampel dalam 100 mikrodetik untuk memahami apa yang diputar di dalamnya. Selanjutnya, kita menghitung dengan proporsi sederhana bahwa jika kita perlu melakukan 1000 sampel dalam 100 μs, maka itu adalah 10 juta sampel dalam 1 detik atau 10.000.000 sampel / s.
Jika kita mengambil sampel dengan kecepatan ini, maka dalam satu eksekusi kode kita akan mengumpulkan 1000 sampel, mengumpulkan dan memahami apa yang bekerja dengan cepat atau lambat. Setelah itu, kami akan menganalisis kinerja dan menyesuaikan kode.
Namun, frekuensi 10 juta sampel per detik banyak. Dan jika kita gagal mencapai kecepatan pembuatan profil sejak awal? Misalkan kita mengumpulkan selama 10 μs hanya 10 sampel, bukan 1000. Dalam hal ini, kita perlu menunggu eksekusi kode profil yang selanjutnya, yang akan terjadi setelah 1 detik (setelah semua, kode profil dieksekusi sekali per detik). Jadi kami akan mengumpulkan 10 sampel lagi. Karena mereka didistribusikan secara merata kepada kami, mereka dapat digabungkan menjadi satu set yang sama. Cukup menunggu hingga kode yang diprofilkan dijalankan 1000/10 = 100 kali, dan kami akan mengumpulkan 1000 sampel yang diperlukan (10 sampel masing-masing 100 kali).
Pilih profiler
Berbekal pengetahuan teoretis ini, mari beralih ke praktik.
Ambil
Async-profiler. Alat yang hebat (menggunakan panggilan mesin virtual AsyncGetCallTrace) yang mengumpulkan panggilan hingga instruksi kode byte dari mesin virtual Java. Tingkat sampling async-profiler asli adalah
1000 sampel per detik .
Kami akan memecahkan proporsi sederhana: 10.000.000 sampel / detik - 1 detik, 1000 sampel / detik - X detik.
Kami mendapatkan bahwa pada frekuensi sampling standar async-profiler, pembuatan profil akan memakan waktu sekitar 3 jam. Ini waktu yang lama. Idealnya, saya ingin merakit profil secepat mungkin, tepat pada kecepatan superluminal.
Mari kita coba melakukan overclock
Async-profiler . Untuk melakukan ini, di readme, kita menemukan flag
-i , yang menetapkan interval sampling. Mari kita coba mengatur flag
-i1 (1 nanosecond), atau
-i0 secara umum, sehingga sampel profiler tidak berhenti. Saya mendapat frekuensi sekitar 2,5 ribu sampel per detik. Dalam hal ini, total durasi profil akan sekitar 1 jam. Tentu saja, bukan 3 jam, tetapi juga tidak terlalu cepat. Tampaknya untuk mencapai kecepatan pembuatan profil yang diperlukan, Anda perlu melakukan sesuatu yang berbeda secara kualitatif, untuk mencapai tingkat yang baru.
Untuk mencapai frekuensi yang jauh lebih tinggi, Anda harus meninggalkan panggilan AsyncGetCallTrace dan menggunakan
perf , profiler Linux penuh waktu yang ditemukan di setiap distribusi Linux. Namun, perf tidak tahu apa-apa tentang Java, dan kami belum melatih perf untuk bekerja dengan Java. Sementara itu, mari kita coba menjalankan perf dengan cara yang menakutkan ini:
$ perf record –F 10000 -p PID -g -- sleep 1 [ perf record: Woken up 1 times to write data ] [ perf record: .. 0.215 MB perf.data (4032 samples) ]
Lebih lanjut tentang notasi- catatan perf berarti kami ingin merekam profil.
- Bendera
-F dan argumen 10.000 adalah laju sampling. - Bendera
-p menunjukkan bahwa kami ingin profil hanya PID spesifik dari proses Java kami. - Bendera
-g bertanggung jawab untuk mengumpulkan tumpukan panggilan. - Akhirnya, dengan sleep 1, kami membatasi entri profil menjadi 1 detik.
Mengapa kita perlu mengumpulkan tumpukan panggilan? Kami memetakan segala sesuatu secara berurutan, dan kemudian dari data yang dikumpulkan kami mengekstrak bagian yang menarik minat kami (metode yang bertanggung jawab untuk pembentukan dan pengiriman pesanan). Penanda bahwa sampel yang dikumpulkan milik data yang kami minati adalah keberadaan bingkai tumpukan
panggilan metode
sendToMoex .
Pelajari perf untuk membangun profil aplikasi Java.
Kami menjalankan catatan perf ... perintah, tunggu 1 detik dan jalankan skrip perf untuk melihat apa yang telah diprofilkan? Dan kita akan melihat sesuatu yang tidak terlalu jelas:
$ perf script java 8079 2008793.746571: 3745505 cycles:uppp: 7fa1e88b53f8 [unknown] (/tmp/perf-11038.map) java 8079 2008793.747565: 3728336 cycles:uppp: 7fa1e88b5372 [unknown] (/tmp/perf-11038.map) java 8079 2008793.748613: 3731147 cycles:uppp: 7fa1e88b53ef [unknown] (/tmp/perf-11038.map)
Tampaknya menjadi alamat, tetapi tidak ada nama metode Java. Jadi, Anda perlu mengajar perf agar sesuai dengan alamat ini dengan nama metode.
Dalam dunia C dan C ++, apa yang disebut informasi debug digunakan untuk mencocokkan alamat dan nama fungsi. Korespondensi disimpan di bagian khusus dari file yang dapat dieksekusi: satu metode terletak di alamat tersebut, metode lain terletak di alamat lain. Perf menarik informasi ini dan melakukan pemetaan.
Jelas, kompiler JIT mesin virtual tidak menghasilkan informasi debug dalam format ini. Kami masih memiliki cara lain - untuk menulis data tentang korespondensi alamat dan nama metode dalam file perf-map khusus, yang akan diperlakukan sebagai tambahan untuk informasi debug yang dibaca. File perf-map ini harus ada di folder tmp dan memiliki struktur data berikut:
Kolom pertama adalah alamat awal kode metode, yang kedua adalah panjangnya, kolom ketiga adalah nama metode.
Jadi, kita perlu membuat file serupa. Jelas, ini tidak dapat dilakukan secara manual (bagaimana kita tahu di alamat apa kompiler JIT akan menempatkan kode), jadi kita akan menggunakan skrip create-java-perf-map.sh dari proyek perf-map-agent, memberikan PID dari proses Java kita . File sudah siap, periksa isinya, jalankan perf-script lagi.
$ perf script java 8080 1895245.867498: cycles:uppp: 7fb2dd10f527 Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868176: 2127960 cycles:uppp: 7fb2dd10f57f Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868737: 1959990 cycles:uppp: 7fb2dd10f627 Loop3.doRecursiveCall (/tmp/perf-8079.map)
Voila! Kami melihat nama-nama metode java! Apa yang baru saja terjadi: kami mengajarkan profiler perf, yang tidak tahu apa-apa tentang Java, membuat profil aplikasi Java biasa dan melihat metode hot java aplikasi ini!
Namun, untuk menganalisis kinerja potongan program yang kami interogasi, kami tidak memiliki cukup tumpukan panggilan untuk menyaring data yang diinginkan dari semua sampel yang dikumpulkan.
Bagaimana cara mendapatkan panggilan stack?Sekarang Anda perlu melakukan sesuatu yang lain dengan perf atau mesin virtual untuk mendapatkan tumpukan panggilan. Untuk memahami apa yang perlu dilakukan, mari kita mundur dan melihat bagaimana tumpukan umumnya bekerja. Bayangkan kita memiliki tiga fungsi f1, f2, f3. Selain itu, panggilan f1 f2, dan panggilan f2 f3.
void f1() { f2(); } void f2() { f3(); } void f3() { ... }
Pada saat fungsi
f3 dieksekusi, mari kita lihat status stack. Kami melihat register
rsp , yang menunjuk ke bagian atas tumpukan. Kita juga tahu bahwa stack memiliki alamat frame stack sebelumnya. Dan bagaimana saya bisa mendapatkan panggilan-tumpukan?
Jika kami entah bagaimana bisa mendapatkan alamat area ini, maka kami dapat membayangkan stack sebagai daftar yang terhubung dan memahami urutan panggilan yang membawa kami ke titik eksekusi saat ini.
Apa yang kita butuhkan untuk ini? Kami membutuhkan register rbp tambahan yang akan menunjuk ke area kuning. Ternyata register rbp memungkinkan untuk mendapatkan stack panggilan, untuk memahami urutan yang membawa kita ke titik saat ini. Saya sarankan membaca detail ini di
Antarmuka Biner Aplikasi Sistem V. Ini menjelaskan bagaimana metode dipanggil di Linux.

Kami mengerti apa masalah kami. Kita perlu memaksa mesin virtual untuk menggunakan register rbp untuk tujuan aslinya - sebagai pointer ke awal frame stack. Ini adalah bagaimana kompiler JIT harus menggunakan register rbp. Ada flag PreserveFramePointer di mesin virtual untuk ini. Ketika kami meneruskan flag ini ke mesin virtual, mesin virtual akan mulai menggunakan register rbp untuk tujuan tradisionalnya. Dan kemudian Perf dapat memutar tumpukan. Dan kami mendapatkan tumpukan panggilan nyata di profil. Bendera dikontribusikan oleh Brendan Gregg yang terkenal jahat hanya dalam JDK8u60.
Kami memulai mesin virtual dengan bendera baru. Jalankan
create-java-perf-map , lalu
perf record dan
perf script . Sekarang kita dapat membuat profil yang akurat dengan tumpukan panggilan:
$ perf script java 18657 1901247.601878: 979583 cycles:uppp: 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7f285d007b10 Interpreter (...) 7f285d0004e7 call_stub (...) 67d0db [unknown] (... libjvm.so) ... 708c start_thread (... libpthread-2.26.so)
Kami mengajarkan perf profiler, termasuk dengan sebagian besar distribusi Linux, untuk bekerja dengan aplikasi Java. Oleh karena itu, sekarang kita tidak hanya dapat melihat bagian kode yang panas, tetapi juga urutan panggilan yang mengarah ke hot spot saat ini. Sebuah pencapaian besar, mengingat bahwa profiler perf tidak tahu apa-apa tentang java. Kami baru saja mengajarkan semua ini!
Meningkatkan laju pengambilan sampel perf
Mari kita coba untuk melakukan overclock hingga 10 juta sampel per detik. Sekarang kita memiliki frekuensi yang jauh lebih rendah.
Untuk mengotomatiskan semua tugas yang baru saja kita lakukan, Anda dapat menggunakan skrip
perf-java-record-stack dari proyek perf-map-agent. Ia memiliki pena yang luar biasa - variabel lingkungan
perf_record-freq , yang dengannya Anda dapat mengatur frekuensi pengambilan sampel. Pertama, mari atur 100 ribu sampel per detik dan coba jalankan. Pesan mengerikan muncul di konsol bahwa kami telah melampaui frekuensi pengambilan sampel maksimum yang diizinkan:
$ PERF_RECORD_FREQ=100000 ./bin/perf-java-record-stack PID ... Maximum frequency rate (30000) reached. Please use -F freq option with lower value or consider tweaking /proc/sys/kernel/perf_event_max_sample_rate. ...
Dalam kasus saya, batasnya adalah 30 ribu sampel per detik. Perf segera mengatakan argumen kernel mana yang perlu diperbaiki, yang akan kita lakukan baik menggunakan gema sudo tee ke file yang diinginkan, atau langsung melalui
sysctl . Jadi:
$ echo '1000000' | sudo tee /proc/sys/kernel/perf_event_max_sample_rate
atau lebih:
$ sudo sysctl kernel.perf_event_max_sample_rate=1000000
Sekarang kami memberi tahu kernel bahwa batas atas frekuensi sekarang 1 juta sampel per detik. Kami memulai profiler lagi dan menunjukkan frekuensi 200 ribu sampel per detik. Profiler akan bekerja selama 15 detik dan memberi kami 1 juta sampel. Segalanya tampak baik-baik saja. Setidaknya tidak ada pesan kesalahan yang tangguh. Tapi frekuensi apa yang sebenarnya kita dapatkan? Ternyata hanya 70 ribu sampel per detik. Apa yang salah?
Mari kita lihat output dari
dmesg :
[84430.412898] perf: interrupt took too long (1783 > 200), lowering kernel.perf_event_max_sample_rate to 89700 ... [84431.618452] perf: interrupt took too long (2229 > 2228), lowering kernel.perf_event_max_sample_rate to 71700
Ini adalah output dari kernel Linux. Itu menyadari bahwa kami mengambil sampel terlalu sering, dan itu membutuhkan terlalu banyak waktu, sehingga kernel menurunkan frekuensi. Ternyata kita perlu melepaskan pegangan lain di kernel - ini disebut
kernel.perf_cpu_time_max_percent dan mengontrol jumlah waktu yang dapat dihabiskan kernel untuk interupsi dari perf.
Kami akan memesan frekuensi sampling 200 ribu sampel per detik. Dan setelah 15 detik kami mendapatkan 3 juta sampel - 200 ribu sampel per detik.
$ PERF_RECORD_FREQ=200000 ./bin/perf-java-record-stack PID Recording events for 15 seconds ... ... [ perf record: Captured ... (2.961.252 samples) ]
Sekarang mari kita lihat profilnya. Jalankan
perf script :
$ perf script ... java ... native_write_msr (/.../vmlinux) java ... Loop2.main (/tmp/perf-29621.map) java ... native_write_msr (/.../vmlinux) ...
Kami melihat fungsi-fungsi aneh dan modul yang dapat dieksekusi vmlinux - kernel Linux. Ini jelas bukan kode kita. Apa yang terjadi Frekuensi ternyata sangat tinggi sehingga kode kernel mulai jatuh ke dalam sampel. Artinya, semakin tinggi frekuensi yang kita naikkan, semakin banyak sampel yang tidak terkait dengan kode kita, tetapi dengan kernel Linux.
Jalan buntu.
Kami menggunakan (secara eksplisit) acara PMU / PEBS perangkat keras
Kemudian saya memutuskan untuk mencoba menggunakan teknologi perangkat keras PMU / PEBS - Unit Pemantau Kinerja, Pengambilan Sampel Berbasis Kejadian yang Tepat. Ini memungkinkan Anda untuk menerima pemberitahuan bahwa suatu peristiwa telah terjadi beberapa kali. Ini disebut "periode." Misalnya, kami dapat menerima pemberitahuan tentang eksekusi oleh prosesor dari setiap instruksi ke-20. Mari kita lihat sebuah contoh. Biarkan instruksi xor dieksekusi sekarang, dan penghitung PMU mendapatkan nilai 18; kemudian datang instruksi mov - konter adalah 19; dan instruksi berikutnya,
tambahkan% r14,% r13 , PMU akan ditampilkan sebagai "panas".
Kemudian siklus baru dimulai:
inc dieksekusi - PMU diatur ulang ke 1. Beberapa iterasi lagi dari siklus dilalui. Pada akhirnya, kita berhenti pada instruksi
mov , PMU terkunci 19. Pernyataan tambahan berikutnya, dan lagi kita menandainya panas. Lihat daftar:
mov aaa, bbbb xor %rdx, %rdx L_START: mov $0x0(%rbx, %rdx),%r14 add %r14, %r13 ; (PMU "") cmp %rdx,100000000 jne L_START
Tidak memperhatikan keanehannya? Siklus lima instruksi, tetapi setiap kali kita menandai instruksi yang sama seperti panas. Jelas, ini tidak benar: semua instruksi "panas". Mereka juga menghabiskan waktu, dan kami hanya menandai satu. Faktanya adalah bahwa antara periode dan penghitung jumlah instruksi dalam iterasi kita memiliki faktor umum 4. Ternyata setiap iterasi keempat kita akan menandai instruksi yang sama dengan "panas". Untuk menghindari perilaku ini, Anda harus memilih angka sebagai periode di mana probabilitas pembagi bersama antara jumlah iterasi dalam loop dan penghitung itu sendiri diminimalkan. Idealnya, periode tersebut harus prima, yaitu hanya berbagi pada diri sendiri dan pada unit. Untuk contoh di atas: Anda harus memilih periode yang sama dengan 23. Kemudian kami akan secara merata menandai semua instruksi dalam siklus ini sebagai "panas".
Teknologi PMU / PEBS telah didukung dalam bentuk modern sejak setidaknya 2009, yaitu, tersedia di hampir semua komputer. Untuk menerapkannya secara eksplisit, mari kita modifikasi skrip
perf-java-record-stack . Ganti flag
-F dengan
-e , yang secara eksplisit menentukan penggunaan PMU / PEBS.
... sudo perf record -F $PERF_RECORD_FREQ ... ...
Mengubah naskah:
... sudo perf record -e cycles –c 10007 ... ...
Anda sudah tahu properti apa yang harus dimiliki suatu periode - kita perlu bilangan prima. Untuk kasus kami, ini akan menjadi periode 10007.
Kami meluncurkan skrip perf-java-record-stack yang dimodifikasi dan dalam 15 detik menerima 4,5 juta sampel - ini hampir 300 ribu per detik, satu sampel setiap 3 μs. Yaitu, untuk satu eksekusi kode profil kami, untuk 100 μs kami akan mengumpulkan 33 sampel. Pada frekuensi ini, total waktu pengumpulan profil hanya 30 detik. Jangan minum secangkir kopi! Pada kenyataannya, semuanya sedikit lebih rumit. Apa yang terjadi jika kode kita mulai dijalankan bukan sekali per detik, tetapi setiap 5 detik? Kemudian durasi profil akan tumbuh hingga 2,5 menit, yang juga merupakan hasil yang cukup baik.
Jadi, dalam 30 detik Anda bisa mendapatkan profil yang sepenuhnya mencakup semua kebutuhan penelitian kami. Kemenangan
Tetapi perasaan beberapa trik kotor tidak meninggalkan saya. Mari kita kembali ke situasi di mana kode kita dieksekusi setiap 5 detik. Kemudian pembuatan profil akan memakan waktu 150 detik, dan selama itu kami akan mengumpulkan sekitar 45 juta sampel. Dari jumlah tersebut, kita hanya membutuhkan 1000, yaitu, 0,002% dari data yang dikumpulkan. Yang lainnya adalah sampah, yang memperlambat kerja alat lain dan menambah biaya overhead. Ya, masalahnya sudah dipecahkan, tetapi itu diselesaikan dengan dahi, kotor, gaya tumpul.
Dan malam itu, ketika saya pertama kali mendapatkan profil yang begitu rinci dengan bantuan perf, saya bermimpi. Saya pulang dari kerja dan berpikir, tetapi alangkah baiknya jika setrika mampu menyusun profil itu sendiri dan bahkan untuk keakuratan struktur mikro dan mikrodetik, dan kami hanya akan menganalisis hasilnya. Akankah mimpi saya menjadi kenyataan? Apa yang kamu pikirkan
Ringkasan singkat:
- Untuk membuat profil aplikasi Java menggunakan perf, Anda perlu membuat file dengan informasi tentang simbol menggunakan skrip dari proyek perf-map-agent
- Untuk mengumpulkan informasi tidak hanya tentang bagian kode yang panas, tetapi juga tumpukan, Anda perlu menjalankan mesin virtual dengan -XX: + flag PreserveFramePointer
- Jika Anda ingin meningkatkan frekuensi pengambilan sampel, Anda harus memperhatikan sysctl'i dan kernel.perf_cpu_time_max_percent dan kernel.perf_event_max_sample_rate.
- Jika sampel dari kernel yang tidak terkait dengan aplikasi mulai masuk ke profil, Anda harus berpikir tentang menentukan secara eksplisit periode PMU / PEBS.
Artikel ini (dan bagian selanjutnya) adalah transkrip laporan, yang diadaptasi dalam bentuk teks. Jika Anda ingin tidak hanya membaca, tetapi juga mendengarkan tentang pembuatan profil,
referensi untuk presentasi.