
Ada banyak artikel dengan tajuk yang serupa, jadi saya akan mencoba menghindari topik yang biasa. Saya harap bahkan pengembang yang sangat berpengalaman pun akan menemukan sesuatu yang bermanfaat di sini. Artikel ini hanya akan mempertimbangkan mekanisme dan pendekatan optimasi sederhana yang akan memungkinkan mereka untuk diterapkan dengan upaya minimal. Dan perubahan ini tidak akan meningkatkan entropi kode Anda. Artikel tidak akan memperhatikan apa dan kapan untuk mengoptimalkan, artikel ini lebih tentang pendekatan penulisan kode secara umum.
1. ToArray vs ToList
public IEnumerable<string> GetItems() { return _storage.Items.Where(...).ToList(); }
Setuju, kode yang sangat khas untuk proyek industri. Tapi apa yang salah dengannya? Antarmuka IEnumerable mengembalikan koleksi yang dapat Anda “datangi”, antarmuka ini tidak menyiratkan bahwa kita dapat menambah / menghapus elemen. Oleh karena itu, tidak perlu mengakhiri ekspresi LINQ dengan casting ke Daftar (Daftar). Dalam hal ini, casting ke Array (ToArray) lebih disukai. Karena List adalah pembungkus di atas Array, dan semua fitur tambahan yang disediakan oleh pembungkus ini, kami memotong antarmuka. Array mengkonsumsi lebih sedikit memori, dan akses ke nilainya lebih cepat. Karena itu, mengapa membayar lebih. Di satu sisi, optimasi ini tidak signifikan, karena mereka mengatakan "optimasi pada kecocokan", tetapi ini tidak sepenuhnya benar. Faktanya adalah bahwa dalam aplikasi khas di mana layanan mengembalikan model untuk lapisan presentasi, mungkin ada segudang panggilan ToList tersebut. Dalam contoh yang dijelaskan di atas, antarmuka IEnumerable diperkenalkan hanya untuk tujuan ilustrasi. Pendekatan ini relevan untuk semua kasus ketika Anda harus mengembalikan koleksi yang tidak akan Anda ubah nanti.
Saya memperkirakan komentar bahwa Array dan Daftar tidak akan berfungsi secara setara dalam hal akses multi-utas ke koleksi. Memang benar. Tetapi jika Anda, sebagai pengembang, sedang mempertimbangkan kemungkinan akses multi-threaded ke koleksi tersebut dengan kemungkinan mengubahnya, maka dengan tingkat probabilitas yang tinggi, Array atau List tidak akan cocok untuk Anda.
2. Parameter “jalur file” tidak selalu merupakan pilihan terbaik untuk metode Anda
Saat mengembangkan API, hindari tanda tangan metode yang menerima jalur file sebagai input (untuk diproses nanti oleh metode Anda). Alih-alih, berikan kemampuan untuk melewatkan array byte ke input, atau
sebagai Stream
upaya terakhir . Faktanya adalah bahwa seiring waktu, metode Anda dapat diterapkan tidak hanya untuk file dari disk, tetapi juga ke file yang ditransfer melalui jaringan, ke file dari arsip, ke file dari database, ke file yang isinya dihasilkan secara dinamis dalam memori, dll. e. Dengan memberikan metode dengan parameter input "jalur file", Anda mewajibkan pengguna API Anda untuk menyimpan data ke disk sebelum membacanya lagi. Operasi yang tidak berarti ini sangat memengaruhi kinerja. Drive adalah hal yang sangat lambat. Untuk kenyamanan, Anda dapat memberikan metode dengan parameter input "path ke file", tetapi di dalamnya selalu menggunakan metode overload publik dengan array byte atau streaming pada input. Ada "penanda" yang dapat membantu menemukan operasi penulisan / baca disk tambahan, coba temukan di proyek Anda menggunakan metode standar:
Path.GetTempPath() dan
Path.GetRandomFileName() (dari System.IO). Dengan tingkat probabilitas yang tinggi, Anda akan menemukan solusi untuk masalah di atas atau yang serupa.
Pembaca yang penuh perhatian dan berpengalaman akan memperhatikan bahwa dalam beberapa kasus, menulis ke disk dapat, sebaliknya, meningkatkan kinerja, misalnya, jika kita berurusan dengan file yang sangat besar. Ini benar, harus diperhitungkan, tetapi saya berasumsi bahwa ini adalah situasi yang sangat langka dengan implementasi yang spesifik.
3. Hindari menggunakan utas sebagai parameter dan hasil pengembalian metode Anda
Apa masalahnya di sini ... ketika kita mendapatkan aliran dari "kotak hitam", kita harus mengingat kondisinya. Yaitu Apakah alirannya terbuka? Di mana penanda baca / tulis? Bisakah kondisinya berubah terlepas dari kode kita? Jika streaming dinyatakan sebagai kelas dasar Stream, kami bahkan tidak memiliki informasi tentang operasi apa yang tersedia. Semua ini diselesaikan dengan pemeriksaan tambahan, dan ini adalah kode dan biaya tambahan. Juga, saya berulang kali menemukan situasi di mana, ketika menerima Stream dari beberapa metode "tidak jelas", pengembang lebih suka memainkannya dengan aman dan "mentransfer" data darinya ke MemoryStream lokal baru yang sepenuhnya terkontrol. Meskipun, aliran sumber bisa sangat aman. Mungkin bahkan ini sudah disiapkan untuk membaca MemoryStream. Kadang-kadang dapat mencapai titik absurditas - di dalam suatu metode, array byte dimasukkan ke dalam MemoryStream, maka MemoryStream ini dikembalikan sebagai hasil dari metode yang dinyatakan sebagai aliran dasar. Di luar, Stream ini berubah menjadi MemoryStream baru, dan kemudian ToArray () mengembalikan array byte, yang awalnya kami miliki. Lebih tepatnya, itu akan menjadi salinan selanjutnya. Ironinya adalah bahwa di dalam dan di luar metode kami, kode tersebut sepenuhnya benar. Menurut pendapat saya, contoh ini tidak keluar dari kepala saya, tetapi ditemukan di suatu tempat dalam kode komersial.
Akibatnya, jika Anda memiliki kemampuan untuk mengirim / menerima data "bersih", jangan gunakan stream untuk ini - jangan membuat jebakan bagi mereka yang akan menggunakannya. Jika aplikasi Anda sudah memiliki aliran transfer / balik, analisis penggunaannya berdasarkan hal tersebut di atas.
4. Warisan enum
Optimalisasi ini biasa, semua orang tahu itu, bahkan siswa. Tapi dari pengalaman saya, ini sangat jarang digunakan. Jadi, secara default, enum mewarisi dari int. Namun, ini dapat diwarisi dari byte, yang memiliki 256 nilai (atau 8 nilai "flaggable"). Yang hampir selalu mencakup fungsionalitas "menengah" enum. Perubahan minimal dalam kode dan semua nilai enum Anda menghabiskan lebih sedikit memori selamanya. Di bawah ini adalah ilustrasi tolok ukur untuk mengisi koleksi dengan nilai enum yang diwarisi dari int dan byte.
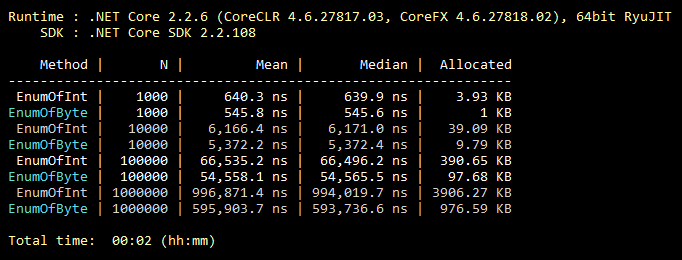
Kode benchmark public class CollectEnums { [Params(1000, 10000, 100000, 1000000)] public int N; [Benchmark] public EnumFromInt[] EnumOfInt() { EnumFromInt[] results = new EnumFromInt[N]; for (int i = 0; i < N; i++) { results[i] = EnumFromInt.Value1; } return results; } [Benchmark] public EnumFromByte[] EnumOfByte() { EnumFromByte[] results = new EnumFromByte[N]; for (int i = 0; i < N; i++) { results[i] = EnumFromByte.Value1; } return results; } } public enum EnumFromInt { Value1, Value2 } public enum EnumFromByte: byte { Value1, Value2 }
5. Beberapa kata lagi tentang kelas Array dan Daftar
Mengikuti logika, iterasi pada array selalu lebih efisien daripada iterasi pada "sheet", karena "sheet" adalah pembungkus atas array. Juga, mengikuti logika, "untuk" selalu lebih cepat dari "foreach", karena "foreach" melakukan banyak tindakan yang diperlukan oleh implementasi antarmuka IEnumerable. Semuanya logis di sini, tapi salah! Mari kita lihat hasil benchmark:

Kode benchmark public class IterationBenchmark { private List<int> _list; private int[] _array; [Params(100000, 10000000)] public int N; [GlobalSetup] public void Setup() { const int MIN = 1; const int MAX = 10; Random rnd = new Random(); _list = Enumerable.Repeat(0, N).Select(i => rnd.Next(MIN, MAX)).ToList(); _array = _list.ToArray(); } [Benchmark] public int ForList() { int total = 0; for (int i = 0; i < _list.Count; i++) { total += _list[i]; } return total; } [Benchmark] public int ForeachList() { int total = 0; foreach (int i in _list) { total += i; } return total; } [Benchmark] public int ForeachArray() { int total = 0; foreach (int i in _array) { total += i; } return total; } [Benchmark] public int ForArray() { int total = 0; for (int i = 0; i < _array.Length; i++) { total += _array[i]; } return total; } }
Faktanya adalah bahwa untuk mengulangi lebih dari satu array, "foreach" tidak menggunakan implementasi IEnumerable. Dalam kasus khusus ini, iterasi paling optimal berdasarkan indeks dilakukan, tanpa memeriksa out-of-bound array, karena konstruk "foreach" tidak beroperasi dengan indeks, sehingga pengembang tidak memiliki kesempatan untuk "mengacaukan" dalam kode. Itulah pengecualian dari aturan. Oleh karena itu, jika di beberapa bagian penting dari kode Anda mengganti penggunaan "foreach" dengan "for" demi optimasi, Anda menembak diri sendiri. Harap dicatat bahwa ini
hanya relevan
untuk array . Ada beberapa cabang di StackOverflow di mana fitur ini dibahas.
6. Apakah mencari melalui tabel hash selalu dibenarkan?
Semua orang tahu bahwa tabel hash sangat efektif untuk pencarian. Tetapi mereka sering lupa bahwa harga untuk pencarian cepat adalah tambahan yang lambat untuk tabel hash. Apa yang mengikuti dari ini? Agar penggunaan tabel hash dapat dibenarkan, perlu bahwa jumlah elemen tabel hash setidaknya 8 (sekitar). Dan agar jumlah operasi pencarian setidaknya urutan besarnya lebih besar dari jumlah operasi penambahan. Jika tidak, gunakan koleksi yang lebih sederhana. Kualitas fungsi hash akan membuat penyesuaian sendiri untuk efisiensi, tetapi artinya ini tidak akan berubah. Dalam praktik saya, ada kasus ketika bottleneck dalam kode dimuat adalah memanggil metode Dictionary.Add (). Kuncinya adalah string biasa, dengan panjang pendek. Mengingat ini dan menjadi pemicu untuk menulis paragraf ini. Sebagai ilustrasi, contoh kode yang sangat buruk:
private static int GetNumber(string numberStr) { Dictionary<string, int> dictionary = new Dictionary<string, int> { {"One", 1}, {"Two", 2}, {"Three", 3} }; dictionary.TryGetValue(numberStr, out int result); return result; }
Mungkin hal serupa terjadi di proyek Anda?
7. Metode penanaman
Kode ini dibagi menjadi beberapa metode yang paling sering karena 2 alasan. Pastikan penggunaan kembali dan pembusukan kode ketika satu tugas dibagi menjadi beberapa subtugas. Lebih mudah bagi seseorang. Inlining adalah proses kebalikan dari dekomposisi, mis. kode metode tertanam di tempat di mana metode harus dipanggil, sebagai hasilnya, kita menghemat tumpukan panggilan dan melewati parameter. Saya sama sekali tidak merekomendasikan mendorong semuanya menjadi satu metode. Tetapi metode-metode yang secara teoritis dapat kita “sebaris” dapat ditandai dengan atribut yang sesuai:
[MethodImpl(MethodImplOptions.AggressiveInlining)]
Atribut ini akan memberi tahu sistem bahwa metode ini dapat disematkan. Ini tidak berarti bahwa metode yang ditandai dengan atribut ini akan selalu built-in. Misalnya, tidak mungkin untuk menanamkan metode rekursif atau virtual. Penting juga dicatat bahwa mekanisme penanaman sangat “halus”. Ada banyak alasan lain mengapa sistem akan menolak untuk menanamkan metode Anda. Namun, tim Microsoft yang mengerjakan .NET Core secara aktif menggunakan atribut ini. Kode sumber untuk .NET Core memiliki banyak contoh penggunaannya.
8. Kapasitas Perkiraan
Saya (dan saya berharap sebagian besar pengembang juga) telah mengembangkan refleks: Saya menginisialisasi koleksi - saya memikirkan apakah mungkin untuk mengatur Kapasitas untuk itu. Namun, jumlah pasti elemen koleksi tidak selalu diketahui sebelumnya. Tapi ini bukan alasan untuk mengabaikan parameter ini. Misalnya, jika, berbicara tentang berapa banyak elemen yang akan ada di koleksi Anda, Anda menganggap "beberapa ribu" buram, ini adalah kesempatan untuk mengatur Kapasitas menjadi 1000. Sebuah teori kecil, misalnya, untuk Daftar secara default, Kapasitas = 16, sehingga hanya mencapai 1000, sistem akan membuat 1008 (16 + 32 + 64 + 128 + 256 + 512) elemen tambahan dan membuat 7 array sementara untuk panggilan GC berikutnya. Yaitu semua pekerjaan ini akan sia-sia. Juga, sebagai Kapasitas, tidak ada yang melarang menggunakan rumus. Jika ukuran koleksi Anda diperkirakan sepertiga dari koleksi lainnya, Anda dapat mengatur Kapasitas sama dengan Koleksi lainnya. Penghitungan / 3. Saat mengatur Kapasitas, ada baiknya memahami kisaran ukuran koleksi yang mungkin dan seberapa dekat nilainya didistribusikan. Selalu ada kemungkinan bahaya, tetapi jika digunakan dengan benar, perkiraan Kapasitas akan memberi Anda kemenangan yang baik.
9. Selalu tentukan kode Anda.
Secara aktif menggunakan (sekilas pandang, opsional) kata kunci C #, seperti: statis, const, hanya baca, disegel, abstrak, dll. Secara alami, di mana mereka masuk akal. Dan ini kinerjanya? Faktanya adalah bahwa semakin rinci Anda menggambarkan sistem Anda ke kompiler, semakin optimal kode yang dapat dihasilkannya. Pembaca yang penuh perhatian dan berpengalaman mungkin memperhatikan bahwa, misalnya, kata kunci yang disegel tidak mempengaruhi kinerja. Sekarang ini benar, tetapi dalam versi yang akan datang semuanya dapat berubah. Beri kesempatan pada kompiler dan mesin virtual! Dapatkan bonus, mengidentifikasi banyak kesalahan penggunaan kode Anda yang tidak tepat pada tahap kompilasi. Aturan umum: semakin jelas sistem dijelaskan, semakin optimal hasilnya. Rupanya, dengan orang-orang juga.
Kisah nyata menegaskan aturan ini, tetapi jika Anda membaca kemalasan, Anda dapat melewatiSuatu malam, saat terlibat dalam
proyek hobinya , ia mengatur sendiri tugas untuk meningkatkan kinerja bagian kode di atas level tertentu. Tetapi situs ini singkat dan ada beberapa pilihan untuk apa yang harus dilakukan dengannya. Saya menemukan dalam dokumentasi bahwa, dimulai dengan versi C # 7.2, kata kunci "readonly" dapat digunakan untuk struktur. Dan dalam kasus saya, struktur abadi digunakan, dengan menambahkan satu kata "readonly" Saya mendapatkan apa yang saya inginkan, bahkan dengan margin! Sistem, mengetahui bahwa struktur saya tidak dimaksudkan untuk diubah, dapat menghasilkan kode yang lebih baik untuk kasus saya.
10. Jika memungkinkan, gunakan satu versi .NET untuk semua proyek Solusi
Anda harus berusaha untuk memastikan bahwa semua rakitan dalam aplikasi Anda milik versi .NET yang sama. Ini berlaku untuk kedua paket NuGet (diedit di package.config / json) dan rakitan Anda sendiri (diedit di properti Project). Ini akan menghemat RAM dan mempercepat awal "dingin", karena dalam memori aplikasi Anda tidak akan ada salinan perpustakaan yang sama untuk versi .NET yang berbeda. Perlu dicatat bahwa tidak dalam semua kasus, berbagai versi. NET akan menghasilkan salinan dalam memori. Tapi anggaplah bahwa aplikasi yang dibangun di versi yang sama. NET selalu lebih baik. Juga, ini menghilangkan sejumlah masalah potensial yang berada di luar ruang lingkup artikel ini. Versi konsolidasi semua paket NuGet yang Anda gunakan juga akan berkontribusi untuk meningkatkan kinerja aplikasi Anda.
Beberapa alat yang bermanfaat
ILSpy adalah alat gratis yang memungkinkan Anda untuk melihat kode sumber perakitan yang dipulihkan. Jika saya memiliki pertanyaan tentang mekanisme .NET mana yang lebih efisien, pertama-tama saya buka ILSpy (dan bukan Google atau StackOverflow), dan sudah ada di sana saya melihat bagaimana penerapannya. Misalnya, untuk mengetahui apa yang paling baik digunakan dalam hal kinerja untuk menerima data melalui HTTP, kelas HttpWebRequest atau WebClient, lihat saja implementasinya melalui ILSpy. Dalam kasus khusus ini, WebClient adalah pembungkus atas HttpWebRequest, masing-masing, jawabannya jelas. Kode sumber .NET tidak layak untuk ditakuti, mereka ditulis oleh programmer biasa yang sama.
BenchmarkDotNet adalah perpustakaan tolok ukur gratis. Ada StopWatch yang sederhana dan intuitif (dari System.Diagnostics). Tetapi terkadang itu tidak cukup. Karena dengan cara yang baik perlu diperhitungkan bukan hasil tunggal, tetapi rata-rata dari beberapa perbandingan, lebih baik membandingkan median mereka untuk meminimalkan pengaruh OS. Juga, Anda perlu memperhitungkan "mulai dingin" dan jumlah memori yang dialokasikan. Untuk pengujian yang rumit seperti itu, BenchmarkDotNet telah dibuat. Perpustakaan inilah yang digunakan para pengembang .NET Core dalam pengujian resmi. Perpustakaan mudah digunakan, tetapi jika penulisnya tiba-tiba membaca posting ini, tolong beri kesempatan yang lebih nyaman untuk mempengaruhi struktur tabel hasil.
U2U Consult Performance Analyzers adalah plug-in gratis untuk Visual Studio yang memberikan tips tentang peningkatan kode dalam hal kinerja. 100% mengandalkan saran dari analis ini tidak sepadan. Karena saya menemukan sebuah situasi di mana satu saran sedikit mengejutkan saya dan setelah analisis terperinci ternyata benar-benar keliru. Sayangnya, contoh ini hilang, jadi ambil satu kata. Namun, jika Anda menggunakannya dengan serius, itu adalah alat yang sangat berguna. Misalnya, ia akan menyarankan bahwa alih-alih
myStr.Replace("*", "-") lebih efisien menggunakan
myStr.Replace('*', '-') . Dan dua ekspresi Dimana di LINQ lebih baik digabungkan menjadi satu. Ini semua adalah "optimisasi saat pertandingan", tetapi mudah diterapkan dan tidak menyebabkan peningkatan kode / kompleksitas.
Kesimpulannya
Jika setiap orang ke-10 yang membaca artikel menerapkan pendekatan di atas untuk proyeknya saat ini (atau bagian penting dari itu), dan juga menganut pendekatan ini di masa depan, maka bersama-sama kita dapat menyelamatkan seluruh hutan! Hutan ??? Yaitu sumber daya yang tersimpan dari sistem komputer, dalam bentuk listrik yang diperoleh dari pembakaran kayu, akan tetap tidak digunakan. Dalam hal ini, "hutan" hanya semacam setara. Mungkin kesimpulan aneh keluar, tapi saya harap Anda terinspirasi oleh pemikiran itu.
Pembaruan PS berdasarkan komentar posting
Keuntungan dari ToArray dibandingkan ToList relevan untuk .NET Core. Tetapi jika Anda menggunakan .NET Framework lama, maka ToList mungkin akan lebih disukai untuk Anda. Masalahnya adalah bahwa dalam .NET Framework, panggilan ToArray itu sendiri jauh lebih lambat daripada panggilan ToList. Dan kerugian ini mungkin tidak dapat dikompensasi oleh akses yang lebih cepat ke elemen dan penyimpanan array yang lebih sedikit. Secara umum, masalah ini ternyata lebih rumit, karena kelas yang berbeda yang mengimplementasikan IEnumerable mungkin memiliki implementasi ToArray dan ToList yang berbeda, dengan tingkat efisiensi yang berbeda.
Jika enum yang diwarisi dari byte digunakan sebagai anggota kelas (struktur), dan tidak secara terpisah, maka mungkin tidak ada penghematan memori. Karena keselarasan memori yang ditempati semua anggota kelas (struktur). Poin ini tidak ada dalam artikel. Namun demikian, potensi keuntungan lebih baik daripada ketidakhadirannya, karena selain memori yang digunakan, enum juga digunakan. Karena itu, paragraf 4 masih relevan, tetapi dengan reservasi penting ini.
Terima kasih kepada
KvanTTT dan
epetrukhin untuk komentar konstruktif tentang masalah ini.
Juga, seperti yang dicatat
Taritsyn , optimisasi pada tahap kompilasi JIT untuk kata kunci “disegel” masih ada. Tetapi, ini hanya menegaskan semua tesis dari paragraf ke-9.
Tampaknya semua komentar konstruktif telah diperhitungkan. Saya sangat senang dengan komentar ini. Karena saya sendiri, sebagai penulis, menerima umpan balik dan saya juga belajar sesuatu yang baru untuk diri saya sendiri.