Baru-baru ini saya
menemukan dataset Kaggle dengan data 45 ribu film dari Full MovieLens Dataset. Data tidak hanya berisi informasi tentang aktor, kru, plot, dll., Tetapi juga peringkat yang diberikan oleh pengguna film untuk film (26 juta peringkat dari 270 ribu pengguna).
Tugas standar untuk data tersebut adalah sistem pemberi rekomendasi. Tetapi untuk beberapa alasan, terpikir oleh saya untuk
memperkirakan peringkat sebuah film berdasarkan informasi yang tersedia sebelum dirilis . Saya bukan penikmat film, dan karena itu biasanya fokus pada ulasan, memilih apa yang harus dilihat dari berita. Tapi pengulas juga agak bias - mereka menonton film yang jauh lebih berbeda dari rata-rata penonton. Karena itu, sepertinya menarik untuk memprediksi bagaimana film itu akan dihargai oleh masyarakat umum.
Jadi, kumpulan data berisi informasi berikut:
- Informasi tentang film: waktu rilis, anggaran, bahasa, perusahaan dan negara asal, dll. Serta peringkat rata-rata (dan kami akan memperkirakannya)
- Kata kunci (tag) tentang plot
- Nama aktor dan kru
- Sebenarnya peringkat (perkiraan)
Kode yang digunakan dalam artikel (python) tersedia di
github .
Pra-filtering data
Array lengkap berisi data lebih dari 45 ribu film, tetapi karena tugasnya adalah memprediksi peringkat, Anda perlu memastikan bahwa peringkat film tertentu objektif. Misalnya, pada kenyataannya banyak orang yang menghargainya.
Sebagian besar film memiliki peringkat sangat sedikit:

Omong-omong, film dengan jumlah peringkat terbesar (14075) mengejutkan saya - ini adalah
"Inception" . Tetapi tiga berikutnya - "The Dark Knight", "Avatar" dan "Avengers" terlihat cukup logis.
Diharapkan bahwa jumlah peringkat dan anggaran film saling berhubungan (anggaran lebih rendah - peringkat lebih rendah). Oleh karena itu, penghapusan film dengan sejumlah kecil peringkat membuat model bias terhadap film yang lebih mahal:
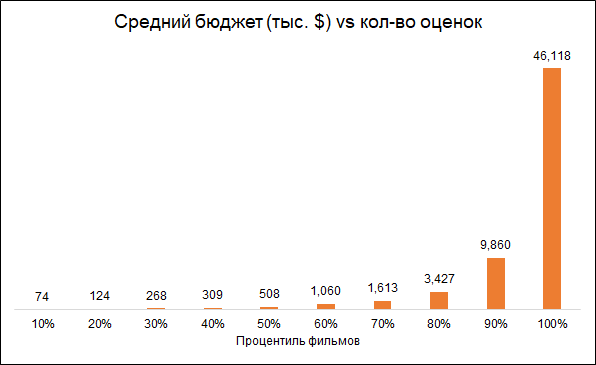
Kami berangkat ke film analisis dengan 50+ peringkat.
Selain itu, kami akan menghapus film yang dirilis sebelum dimulainya layanan pemeringkatan (1996). Di sini masalahnya adalah bahwa film-film modern dinilai rata-rata lebih buruk daripada yang lama, hanya karena di antara film-film lama mereka menonton dan mengevaluasi yang terbaik, dan di antara yang modern itu saja.
Hasilnya, susunan akhir berisi sekitar 6 ribu film.
Fitur yang Digunakan
Kami akan menggunakan beberapa grup fitur:
- Metadata film : apakah film tersebut termasuk dalam "koleksi" (serangkaian film), negara rilis, perusahaan manufaktur, bahasa film, anggaran, genre, tahun dan bulan rilis film, durasinya
- Kata kunci: untuk setiap film ada daftar tag yang menggambarkan alurnya. Karena ada banyak kata, mereka diproses sebagai berikut: dikelompokkan ke dalam kelompok kesamaan (misalnya, kecelakaan dan kecelakaan mobil), berdasarkan pada kelompok-kelompok ini dan kata-kata individual, analisis PCA dibuat, dan komponen yang paling penting dipilih dari hasilnya. Ini mengurangi dimensi ruang fitur.
- “Kelebihan” aktor sebelumnya yang membintangi film ini. Untuk setiap aktor, daftar film dibentuk di mana ia membintangi sebelumnya dan peringkat film-film ini dihitung. Jadi untuk setiap film telah dibentuk indikator yang mengagungkan keberhasilan film yang dibintangi aktor sebelumnya.
- Oscar. Jika aktor, sutradara, produser, penulis skenario, atau juru kamera sebelumnya berpartisipasi dalam film, yang dinominasikan atau menerima Oscar untuk film, arahan atau skenario film terbaik, ini diperhitungkan dalam model. Selain itu, jika aktornya adalah nominasi atau pemenang Academy Award untuk Aktor Pendukung Terbaik atau Peran Pendukung, ini juga diperhitungkan. Informasi tentang Oscar diterima dari Wikipedia.
Beberapa statistik menarik
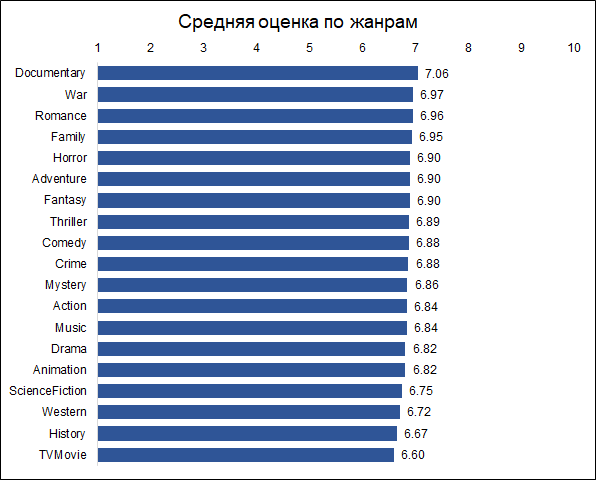
Film dokumenter menerima peringkat tertinggi. Ini adalah alasan yang baik untuk dicatat bahwa film yang berbeda dievaluasi oleh orang yang berbeda, dan jika film dokumenter dinilai oleh penggemar tindakan, maka hasilnya mungkin berbeda. Artinya, estimasi tersebut bias karena preferensi awal publik. Tetapi untuk tugas kami ini tidak penting, karena kami ingin memprediksi penilaian objektif yang tidak kondisional (seolah-olah setiap penonton telah menonton semua film), yaitu film yang akan diberikan kepada film oleh penontonnya.
Ngomong-ngomong, sangat menarik bahwa film-film sejarah dinilai jauh lebih rendah daripada film dokumenter.
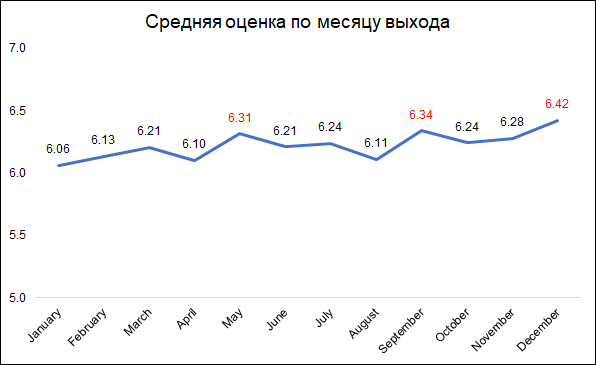
 Peringkat tertinggi diberikan untuk film yang dirilis pada bulan Desember, September dan Mei.
Peringkat tertinggi diberikan untuk film yang dirilis pada bulan Desember, September dan Mei.Ini mungkin dapat dijelaskan sebagai berikut:
- pada bulan Desember, perusahaan merilis film terbaik untuk mengumpulkan box office selama liburan Natal
- pada bulan September, film akan dirilis yang akan berpartisipasi dalam perjuangan untuk Oscar
- Mei adalah waktu rilis untuk film laris musim panas.
 Peringkat film sedikit tergantung pada anggaran
Peringkat film sedikit tergantung pada anggaran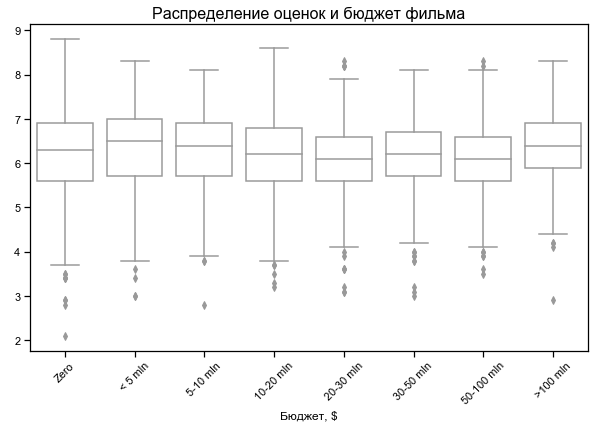
Tidak ada anggaran untuk beberapa film - mungkin tidak ada data
Film dengan peringkat terpendek dan terpanjang teratas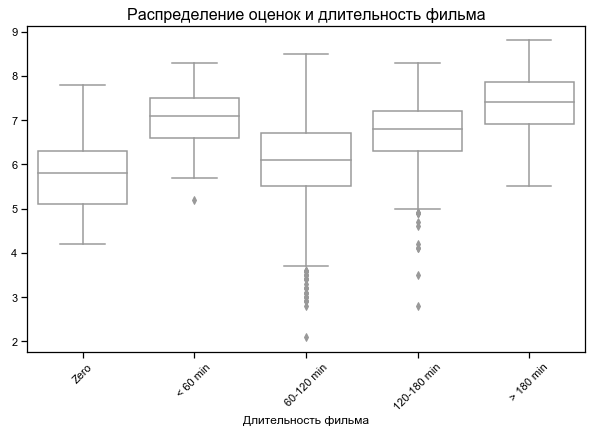
Untuk beberapa film, durasi nol ditunjukkan - mungkin tidak ada data
Hasil pada set fitur yang berbeda
Tugas kita - memperkirakan peringkat - tugas regresi. Kami akan menguji tiga model - regresi linier (seperti baseline), SVM dan XGB. Sebagai metrik kualitas, kami memilih RMSE. Grafik di bawah ini menunjukkan nilai RMSE pada set validasi untuk model yang berbeda dan serangkaian fitur yang berbeda (saya ingin memahami apakah layak untuk mengacaukan kata kunci dan dengan Oscar). Semua model dibangun dengan hiperparameter dasar.
Seperti yang Anda lihat, XGB memiliki hasil terbaik dengan serangkaian fitur lengkap (metadata film + kata kunci + Oscar).
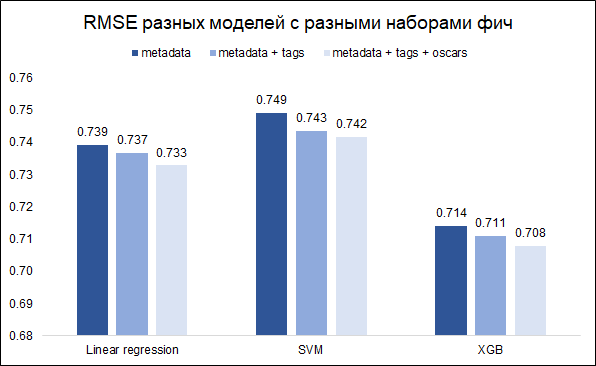
Dengan menyetel hyperparameters, dimungkinkan untuk mengurangi RMSE dari 0,708 menjadi 0,706
Analisis kesalahan dan komentar akhir
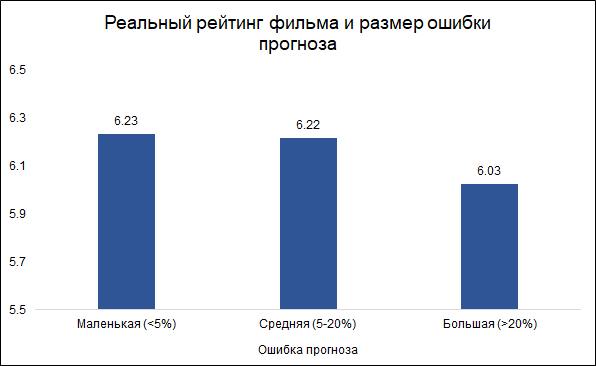
Kami berasumsi bahwa kesalahan kurang dari 5% adalah kecil (sekitar sepertiga), dan kesalahan lebih dari 20% adalah besar (sekitar 10%). Dalam kasus lain (sedikit lebih dari setengah) kami akan mempertimbangkan rata-rata kesalahan.
Menariknya, ukuran kesalahan dan peringkat film terkait:
model cenderung membuat kesalahan pada film yang baik dan lebih sering pada yang buruk. Kelihatannya logis: film yang bagus, seperti karya lain, dibuat oleh orang yang lebih berpengalaman dan profesional. Tentang film Tarantino dengan partisipasi Brad Pitt, Anda dapat mengatakan sebelumnya bahwa kemungkinan besar film itu akan menjadi baik. Pada saat yang sama, film berbujet rendah dengan aktor yang kurang dikenal bisa baik dan buruk, dan sulit untuk menilai tanpa melihatnya.
Berikut adalah fitur paling penting dari model (variabel PCA merujuk pada kata kunci yang diproses yang menggambarkan plot film):

Dua dari fitur ini adalah milik Oscar, yang sebelumnya dinominasikan oleh salah satu anggota tim (sutradara, produser, penulis skenario, juru kamera), atau film di mana para aktor membintangi. Seperti disebutkan di atas, kesalahan perkiraan dikaitkan dengan evaluasi film, dan dalam hal ini, nominasi sebelumnya untuk Oscar dapat menjadi pembatas yang baik untuk model. Memang, film yang memiliki setidaknya satu nominasi Oscar (di antara aktor atau tim) memiliki kesalahan perkiraan rata-rata sebesar 8,3%, dan mereka yang tidak memiliki nominasi seperti itu - 9,8%. Dari 10 fitur teratas yang digunakan dalam model, nominasi Oscar yang memberikan koneksi terbaik dengan ukuran kesalahan.
Oleh karena itu, muncul ide untuk membangun dua model terpisah: satu untuk film di mana aktor atau tim dinominasikan untuk Oscar, dan yang kedua untuk sisanya. Idenya adalah bahwa ini dapat mengurangi kesalahan keseluruhan. Namun, percobaan gagal: model umum memberi RMSE 0,706, dan dua yang terpisah memberi 0,715.
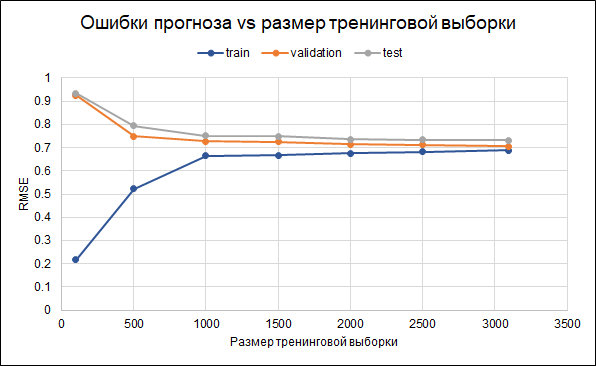
Karena itu, kami akan meninggalkan model aslinya. Hasil akurasinya adalah sebagai berikut: RMSE dalam sampel pelatihan - 0,688, dalam sampel validasi - 0,706, dan dalam sampel uji - 0,732.
Artinya, ada beberapa overfitting. Parameter pengaturan telah ditetapkan dalam model itu sendiri. Cara lain untuk mengurangi overfitting bisa dengan mengumpulkan lebih banyak data. Untuk memahami apakah ini akan membantu, kami akan membuat grafik kesalahan untuk berbagai ukuran sampel pelatihan - dari 100 hingga maksimum yang tersedia 3.000. Grafik ini menunjukkan bahwa mulai dari sekitar 2,5 ribu poin dalam rangkaian pelatihan, kesalahan dalam pelatihan, validasi, dan perubahan set tes kecil, yaitu peningkatan sampel tidak akan memiliki efek yang signifikan.
 Apa lagi yang bisa Anda coba perbaiki model:
Apa lagi yang bisa Anda coba perbaiki model:- Awalnya, film dipilih secara berbeda (batas berbeda pada jumlah suara, batas tambahan pada variabel lain)
- Tidak semua peringkat digunakan untuk menghitung peringkat - dimungkinkan untuk memilih lebih banyak pengguna aktif atau menghapus mereka yang hanya memberikan peringkat buruk
- Cobalah berbagai cara untuk mengganti data yang hilang
Menariknya, film “Batman and Robin” tahun 1997 memiliki kesalahan perkiraan terbesar (7 poin perkiraan daripada 4.2 yang asli). Film dengan Arnold Schwarzenegger, George Clooney dan Uma Thurman menerima
11 nominasi Golden Raspberry Award
(dan satu kemenangan) , menduduki
daftar 50 film terburuk dalam sejarah dari Empire newsreel, dan menyebabkan
pembatalan sekuel dan memulai kembali seluruh seri . Nah, di sini modelnya, mungkin, keliru seperti pria :)