
TL; DR
- Untuk mencapai observabilitas tinggi terhadap wadah dan layanan mikro, majalah dan metrik primer tidak cukup.
- Untuk pemulihan yang lebih cepat dan peningkatan toleransi kesalahan, aplikasi harus menerapkan Prinsip Observabilitas Tinggi (HOP).
- Di tingkat aplikasi, NRA membutuhkan: pencatatan yang benar, pemantauan yang cermat, pemeriksaan kesehatan, dan pelacakan kinerja / transisi.
- Gunakan pemeriksaan readinessProbe dan livenessProbe Kubernetes sebagai elemen HOP .
Apa itu Template Pemeriksaan Kesehatan?
Saat merancang aplikasi yang sangat penting dan sangat penting untuk misi, sangat penting untuk memikirkan hal seperti toleransi kesalahan. Suatu aplikasi dianggap toleran terhadap kesalahan jika dengan cepat dikembalikan setelah kegagalan. Aplikasi cloud yang khas menggunakan arsitektur microservice - ketika setiap komponen ditempatkan dalam wadah yang terpisah. Dan untuk memastikan bahwa aplikasi pada k8s sangat mudah diakses, ketika Anda mendesain sebuah cluster, Anda harus mengikuti pola-pola tertentu. Di antara mereka adalah Template Cek Kesehatan. Ini menentukan bagaimana aplikasi melaporkan k8 tentang kinerjanya. Ini bukan hanya informasi tentang apakah pod berfungsi, tetapi juga tentang bagaimana pod menerima permintaan dan meresponsnya. Semakin banyak Kubernet tahu tentang kinerja pod, semakin banyak keputusan cerdas yang dibuat tentang perutean lalu lintas dan penyeimbangan muatan. Dengan demikian, prinsip aplikasi yang dapat diamati tinggi pada waktu yang tepat untuk menanggapi permintaan.
Prinsip observability tinggi (NRA)
Prinsip observabilitas tinggi adalah salah satu prinsip merancang aplikasi kemas . Dalam arsitektur microservice, layanan tidak peduli bagaimana permintaan mereka diproses (dan memang demikian), tetapi penting bagaimana mendapatkan jawaban dari menerima layanan. Misalnya, untuk mengautentikasi pengguna, satu wadah mengirim permintaan HTTP lain, menunggu tanggapan dalam format tertentu - itu saja. PythonJS juga dapat menangani permintaan, dan Python Flask dapat merespons. Wadah untuk satu sama lain seperti kotak hitam dengan konten tersembunyi. Namun, prinsip NRA mensyaratkan bahwa setiap layanan mengungkapkan beberapa titik akhir API yang menunjukkan seberapa efisiennya, serta tingkat ketersediaan dan toleransi kesalahannya. Kubernetes meminta metrik ini untuk memikirkan langkah selanjutnya untuk merutekan dan memuat keseimbangan.
Aplikasi cloud yang dirancang dengan baik mencatat peristiwa-peristiwa utamanya menggunakan stream I / O STDERR dan STDOUT standar. Layanan tambahan, misalnya, filebeat, logstash, atau fluentd, yang mengirimkan log ke sistem pemantauan terpusat (seperti Prometheus) dan sistem pengumpulan log (rangkaian perangkat lunak ELK), mengikuti. Diagram di bawah ini menunjukkan bagaimana aplikasi cloud bekerja sesuai dengan Template Pemeriksaan Kesehatan dan Prinsip Observabilitas Tinggi.
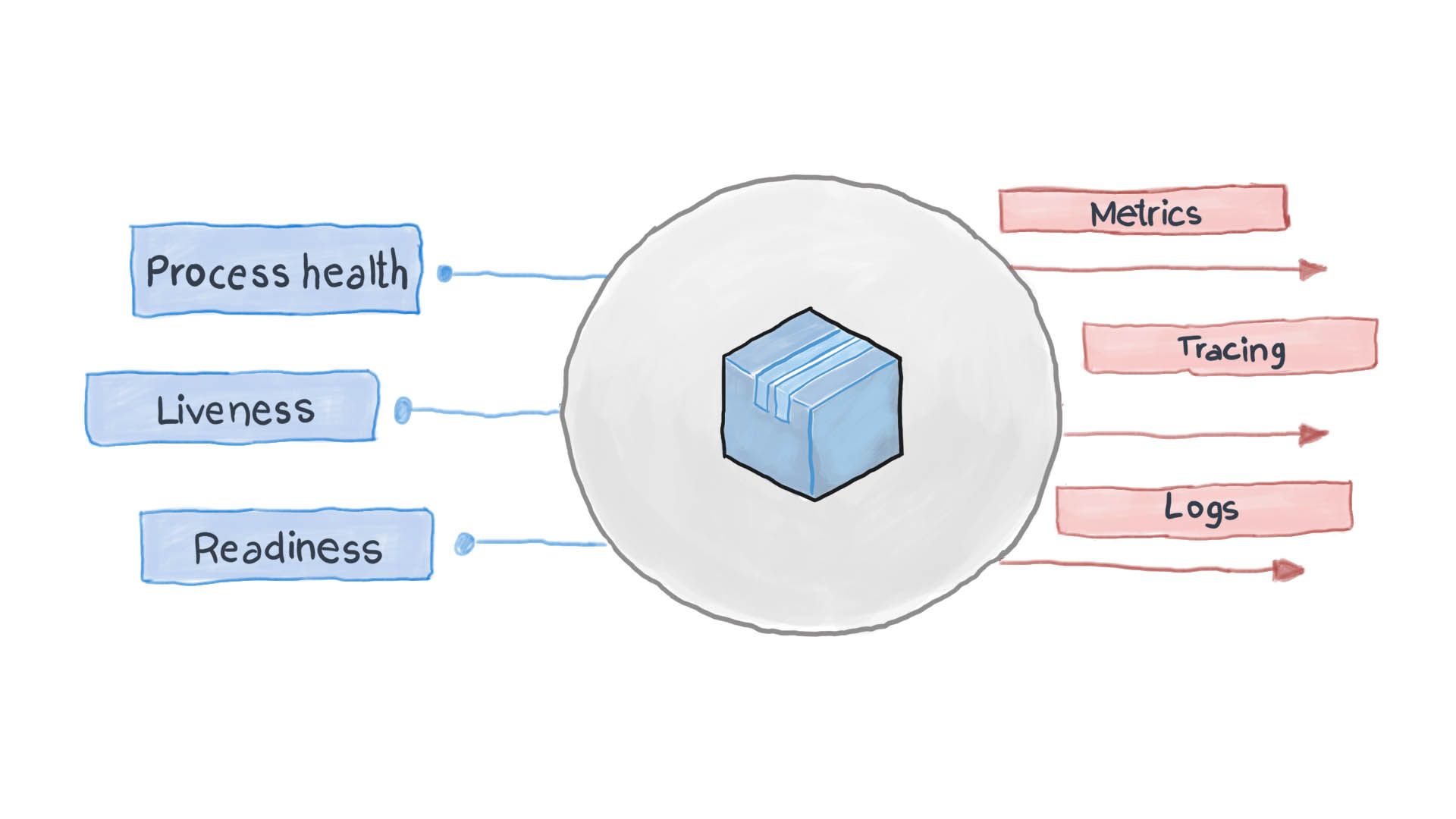
Bagaimana cara menerapkan Pola Pemeriksaan Kesehatan di Kubernetes?
Di luar kotak, k8 memantau status pod menggunakan salah satu pengontrol ( Penyebaran , Replika , DaemonSet , StatefulSets , dll., Dll.). Setelah mengetahui bahwa pod telah jatuh karena suatu alasan, controller mencoba untuk me-restart atau memindahkannya ke node lain. Namun, pod dapat melaporkan bahwa itu sudah aktif dan berjalan, sementara itu sendiri tidak berfungsi. Berikut ini sebuah contoh: aplikasi Anda menggunakan Apache sebagai server web, Anda menginstal komponen pada beberapa pod cluster. Karena perpustakaan tidak dikonfigurasi dengan benar, semua permintaan ke aplikasi merespons dengan kode 500 (kesalahan server internal). Saat memeriksa pengiriman, memeriksa status polong memberikan hasil yang sukses, namun, pelanggan berpikir berbeda. Kami menggambarkan situasi yang tidak diinginkan ini sebagai berikut:
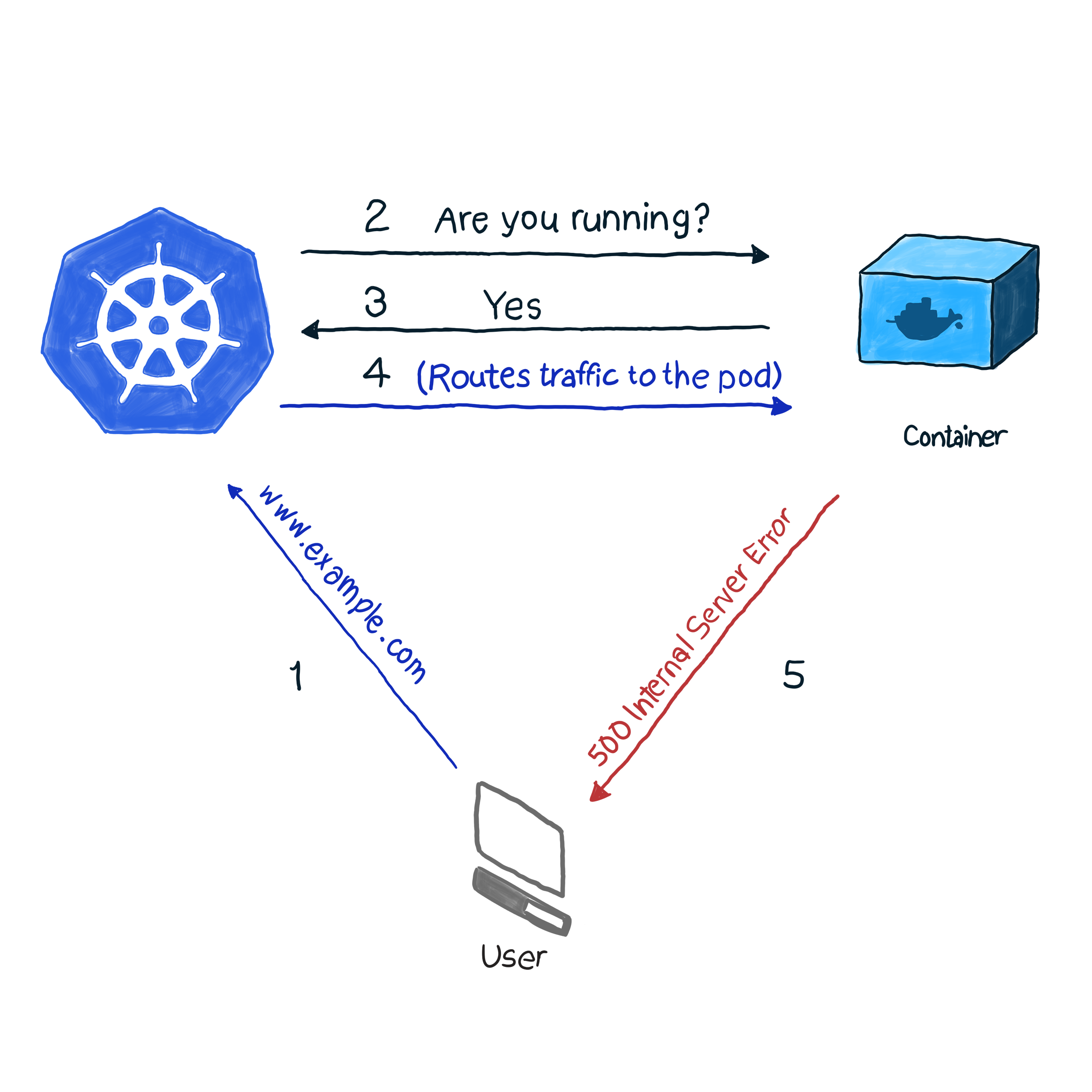
Dalam contoh kami, k8 melakukan pemeriksaan kesehatan . Dalam jenis cek ini, kubelet terus-menerus memeriksa status proses dalam wadah. Begitu dia mengerti bahwa proses telah meningkat, dia akan memulai kembali. Jika kesalahan dihilangkan dengan hanya me-restart aplikasi, dan program ini dirancang untuk mematikan ketika ada kesalahan, maka untuk mengikuti NRA dan Template Pemeriksaan Kesehatan, proses pemeriksaan kesehatan sudah cukup. Sangat disayangkan bahwa tidak semua kesalahan dihilangkan dengan memulai kembali. Untuk kasus ini, k8s menawarkan 2 cara yang lebih dalam untuk memecahkan masalah pod : livenessProbe dan readinessProbe .
LiveProbe
Selama liveProbe , kubelet melakukan 3 jenis pemeriksaan: ia tidak hanya mengetahui apakah pod berfungsi, tetapi apakah siap menerima dan merespons permintaan:
- Setel permintaan HTTP ke pod. Respons harus berisi kode respons HTTP dalam kisaran 200 hingga 399. Dengan demikian, kode 5xx dan 4xx menunjukkan bahwa pod memiliki masalah, bahkan jika proses sedang berjalan.
- Untuk memeriksa pod dengan layanan non-HTTP (misalnya, server surat Postfix), Anda perlu membuat koneksi TCP.
- Eksekusi perintah arbitrer untuk pod (secara internal). Verifikasi dianggap berhasil jika kode keluar perintah adalah 0.
Contoh cara kerjanya. Definisi pod berikut ini berisi aplikasi NodeJS yang memberikan kesalahan 500 untuk permintaan HTTP. Untuk memastikan bahwa kontainer dimulai ulang setelah menerima kesalahan seperti itu, kami menggunakan parameter livenessProbe:
apiVersion: v1 kind: Pod metadata: name: node500 spec: containers: - image: magalix/node500 name: node500 ports: - containerPort: 3000 protocol: TCP livenessProbe: httpGet: path: / port: 3000 initialDelaySeconds: 5
Ini tidak berbeda dari definisi .spec.containers.livenessProbe lainnya, tetapi kami menambahkan objek .spec.containers.livenessProbe . Parameter httpGet menerima jalur di mana permintaan HTTP GET dikirim (dalam contoh kami, ini adalah / , tetapi dalam skenario pertempuran mungkin juga ada sesuatu seperti /api/v1/status ). Masih livenessProbe menerima parameter initialDelaySeconds , yang menginstruksikan operasi validasi untuk menunggu sejumlah detik tertentu. Penundaan diperlukan karena wadah perlu waktu untuk memulai, dan ketika dinyalakan kembali tidak akan tersedia untuk sementara waktu.
Untuk menerapkan pengaturan ini ke sebuah cluster, gunakan:
kubectl apply -f pod.yaml
Setelah beberapa detik, Anda dapat memeriksa konten pod dengan perintah berikut:
kubectl describe pods node500
Temukan yang berikut di akhir output.
Seperti yang Anda lihat, livenessProbe memprakarsai permintaan GET HTTP, wadah menghasilkan kesalahan 500 (yang diprogram untuk), kubelet memulainya kembali.
Jika Anda tertarik dengan bagaimana aplikasi NideJS diprogram, berikut adalah app.js dan Dockerfile yang digunakan:
app.js
var http = require('http'); var server = http.createServer(function(req, res) { res.writeHead(500, { "Content-type": "text/plain" }); res.end("We have run into an error\n"); }); server.listen(3000, function() { console.log('Server is running at 3000') })
Dockerfile
FROM node COPY app.js / EXPOSE 3000 ENTRYPOINT [ "node","/app.js" ]
Penting untuk memperhatikan hal ini: livenessProbe akan memulai kembali wadah hanya jika terjadi kegagalan. Jika restart tidak memperbaiki kesalahan yang mengganggu pengoperasian wadah, kubelet tidak akan dapat mengambil langkah-langkah untuk menghilangkan kerusakan.
kesiapanProbe
readinessProbe bekerja mirip dengan livenessProbe (MENDAPATKAN permintaan, komunikasi TCP dan eksekusi perintah), dengan pengecualian tindakan pemecahan masalah. Wadah tempat kegagalan dicatat tidak dimulai kembali, tetapi diisolasi dari lalu lintas masuk. Bayangkan salah satu wadah melakukan banyak perhitungan atau berada di bawah beban berat, yang meningkatkan waktu respons untuk permintaan. Dalam kasus livenessProbe, pemeriksaan ketersediaan respons dipicu (melalui parameter periksa timeoutSeconds), setelah itu kubelet memulai kembali wadah. Ketika diluncurkan, wadah mulai melakukan tugas-tugas yang intensif sumber daya dan dimulai kembali. Ini bisa sangat penting untuk aplikasi yang peduli dengan kecepatan respons. Misalnya, sebuah mobil tepat di jalan menunggu respons dari server, responsnya tertunda - dan mobil mogok.
Mari kita menulis definisi readinessProbe yang menetapkan waktu respons untuk permintaan GET menjadi tidak lebih dari dua detik, dan aplikasi akan menanggapi permintaan GET dalam 5 detik. File pod.yaml akan terlihat seperti ini:
apiVersion: v1 kind: Pod metadata: name: nodedelayed spec: containers: - image: afakharany/node_delayed name: nodedelayed ports: - containerPort: 3000 protocol: TCP readinessProbe: httpGet: path: / port: 3000 timeoutSeconds: 2
Perluas pod dengan kubectl:
kubectl apply -f pod.yaml
Tunggu beberapa detik, dan kemudian lihat bagaimana kesiapanProbe bekerja:
kubectl describe pods nodedelayed
Di akhir kesimpulan, Anda dapat melihat bahwa beberapa peristiwa mirip dengan ini .
Seperti yang Anda lihat, kubectl tidak memulai ulang pod ketika waktu pemindaian melebihi 2 detik. Sebaliknya, ia membatalkan permintaan itu. Koneksi masuk dialihkan ke pod lain yang berfungsi.
Catatan: sekarang setelah beban tambahan telah dihapus dari pod, kubectl mengirimkan permintaan lagi: respons terhadap permintaan GET tidak lagi tertunda.
Sebagai perbandingan: berikut ini adalah file app.js yang dimodifikasi:
var http = require('http'); var server = http.createServer(function(req, res) { const sleep = (milliseconds) => { return new Promise(resolve => setTimeout(resolve, milliseconds)) } sleep(5000).then(() => { res.writeHead(200, { "Content-type": "text/plain" }); res.end("Hello\n"); }) }); server.listen(3000, function() { console.log('Server is running at 3000') })
TL; DR
Sebelum munculnya aplikasi berbasis cloud, log adalah sarana utama untuk memantau dan memeriksa status aplikasi. Namun, tidak ada cara untuk mengambil langkah pemecahan masalah. Log berguna hari ini, mereka harus dikumpulkan dan dikirim ke sistem perakitan log untuk analisis situasi darurat dan pengambilan keputusan. [ semua ini bisa dilakukan tanpa aplikasi cloud menggunakan monit, misalnya, tetapi dengan k8 menjadi lebih mudah :) - Ed. ]
Saat ini, koreksi harus dilakukan hampir secara real time, jadi aplikasi seharusnya tidak lagi menjadi kotak hitam. Tidak, mereka harus menunjukkan titik akhir yang memungkinkan sistem pemantauan untuk meminta dan mengumpulkan data berharga tentang status proses sehingga mereka dapat merespons secara instan jika perlu. Ini disebut Template Desain Pemeriksaan Kesehatan, yang mengikuti Prinsip Observabilitas Tinggi (NRA).
Kubernetes secara default menawarkan 2 jenis pemeriksaan kesehatan: readinessProbe dan livenessProbe. Keduanya menggunakan jenis pemeriksaan yang sama (permintaan HTTP GET, komunikasi TCP, dan eksekusi perintah). Mereka berbeda dalam keputusan apa yang dibuat dalam menanggapi masalah dalam polong. livenessProbe me-restart wadah dengan harapan bahwa kesalahan tidak akan terulang, dan readinessProbe mengisolasi pod dari lalu lintas masuk sampai penyebab masalah teratasi.
Desain aplikasi yang tepat harus mencakup kedua jenis validasi dan bahwa mereka mengumpulkan data yang cukup, terutama ketika pengecualian dibuat. Ini juga harus menunjukkan titik akhir API yang diperlukan yang mengirimkan metrik status kesehatan penting ke sistem pemantauan (juga disebut Prometheus).