Dalam
artikel pertama dari seri ini, saya secara aktif mempromosikan gagasan bahwa pengembangan kode untuk Redd adalah yang kedua, dan proyek utamanya adalah yang utama. Redd adalah alat bantu, jadi menghabiskan banyak waktu untuk itu salah. Artinya, pengembangan untuk itu harus berjalan cepat. Tetapi ini tidak berarti sama sekali bahwa program yang dihasilkan tidak harus optimal. Sebenarnya, jika mereka tidak dioptimalkan sama sekali, maka kekuatan peralatan tidak akan cukup untuk menerapkan sistem pengujian yang diinginkan. Karena itu, prosesnya, seperti yang saya katakan, harus cepat dan mudah, tetapi pengembang harus selalu mengingat beberapa prinsip optimasi.
Buku tebal telah diterbitkan tentang pengoptimalan. Beberapa buku ini bermanfaat, ada yang sudah ketinggalan zaman, karena prinsip-prinsip yang dijelaskan di dalamnya telah lama bermigrasi ke tahap optimasi otomatis ketika membuat kode ... Tapi ada beberapa hal yang tidak memiliki nilai ketika mengembangkan program biasa untuk prosesor biasa, jadi buku-buku biasa biasanya tidak menjelaskan . Kita sekarang akan mulai mempertimbangkannya.
Pendahuluan
Sampai sekarang, saya menulis pada prinsip "satu masalah - satu artikel." Dan artikel-artikel itu diperoleh dalam format kuliah, memengaruhi beberapa topik sekaligus, disatukan oleh masalah umum. Tetapi beberapa pembaca mengatakan bahwa artikel seperti itu tidak dapat dibaca dalam sekali jalan. Oleh karena itu, sekarang kami akan mencoba membicarakan hanya satu topik dalam satu artikel. Juga lebih mudah bagi saya untuk menulis seperti itu. Mari kita lihat, tiba-tiba akan lebih nyaman bagi semua orang.
Juga, senangilah minus misterius. Jika sebuah artikel diterbitkan di pagi hari, maka minus pertama untuk itu tiba setelah periode waktu di mana tidak mungkin untuk membaca seluruh teks. Seseorang melakukan ini murni dari prinsip, hanya menyisakan topik tentang UDB dan balalaika. Jika publikasi itu bukan di pagi hari, tetapi di sore hari, maka ia membuang minus dengan penundaan. Minus kedua tiba pada siang hari (dan teman itu, ngomong-ngomong, juga menyisakan topik tentang UDB dan tentang balalaika). Dalam format baru akan ada lebih banyak artikel, yang berarti momen yang lebih menyenangkan bagi pasangan ini (meskipun, secara pribadi bagi saya, sebagai penulis, itu menjadi sedih dan menghina dari tindakan mereka).
Artikel sebelumnya dalam seri:
- Pengembangan "firmware" paling sederhana untuk FPGA yang dipasang di Redd, dan debugging menggunakan tes memori sebagai contoh.
- Pengembangan "firmware" paling sederhana untuk FPGA yang dipasang di Redd. Bagian 2. Kode program.
- Pengembangan intinya sendiri untuk ditanamkan dalam sistem prosesor berbasis FPGA.
- Pengembangan program untuk prosesor pusat Redd pada contoh akses ke FPGA.
- Eksperimen pertama menggunakan protokol streaming pada contoh koneksi CPU dan prosesor di FPGA kompleks Redd.
- Merry Quartusel, atau bagaimana prosesor telah hidup seperti itu.
Perilaku misterius dari sistem tipikal
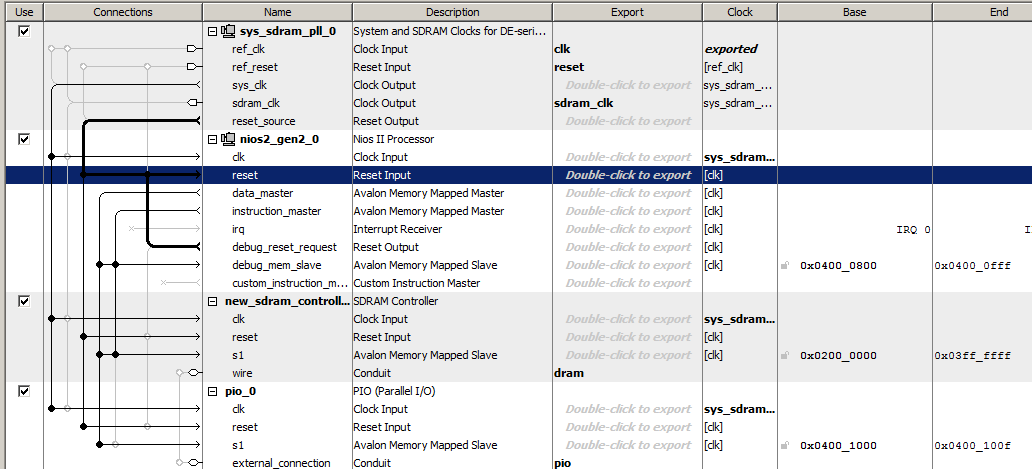
Mari kita lakukan sistem prosesor paling sederhana dengan memasukkan jam, prosesor Nios II / f, pengontrol SDRAM, dan port keluaran. Begitulah Spartan sistem ini terlihat di Platform Designer
Kode program untuk itu hanya akan berisi satu fungsi, tubuh yang terlihat agak aneh, karena mengandung banyak baris berulang, tetapi ini akan berguna bagi kita.
Kode disembunyikan karena terlalu ketat.extern "C" { #include "sys/alt_stdio.h" #include <system.h> #include <io.h> } void MagicFunction() { while (1) { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } } int main() { MagicFunction(); /* Event loop never exits. */ while (1); return 0; }
Letakkan breakpoint di baris terakhir:
IOWR (PIO_0_BASE,0,0);
di
MagicFunction dan jalankan program. Apa yang kita dapatkan di pintu keluar pelabuhan? Impuls yang sangat kasar:
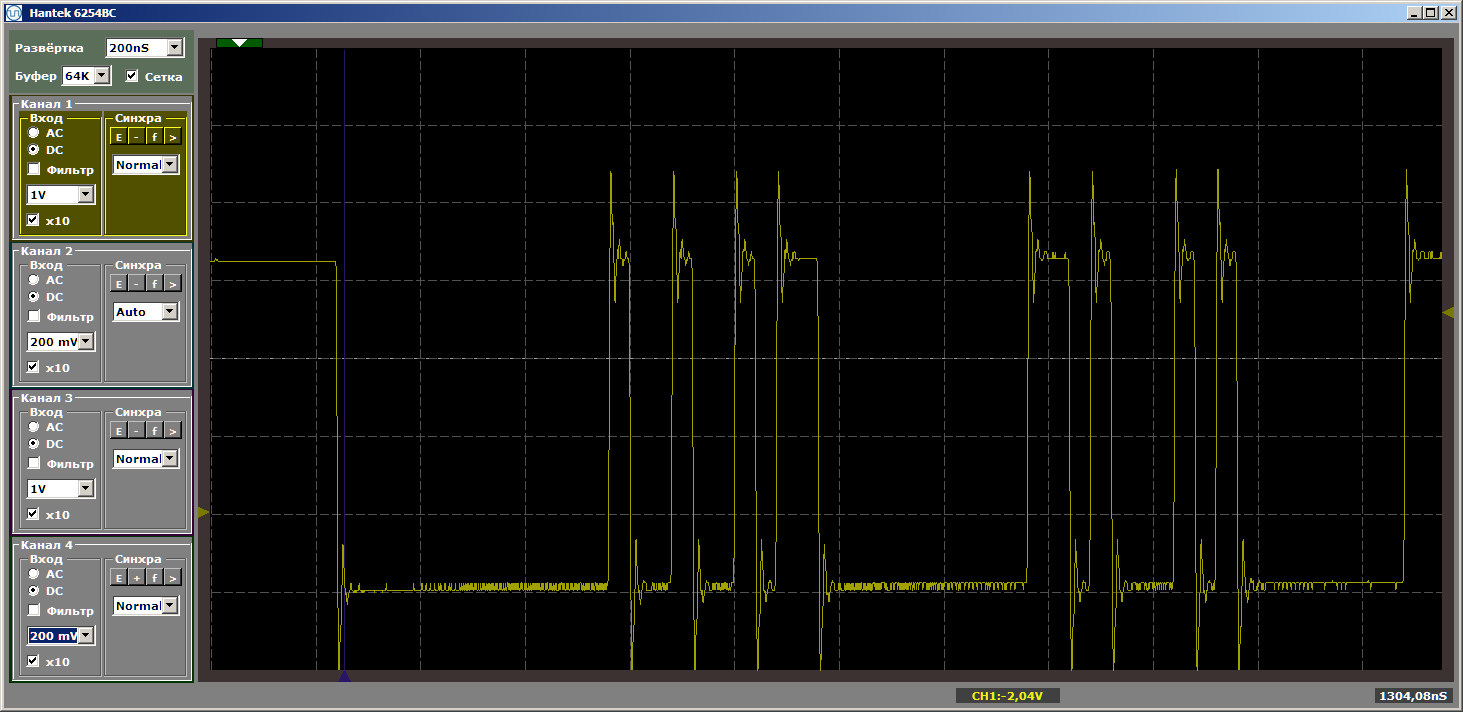
Kengerian Ya benar. Namun, klik "luncurkan" lagi untuk menyelesaikan iterasi lain dari loop. Dan sekarang di pintu keluar kita melihat jalan mulus yang indah:
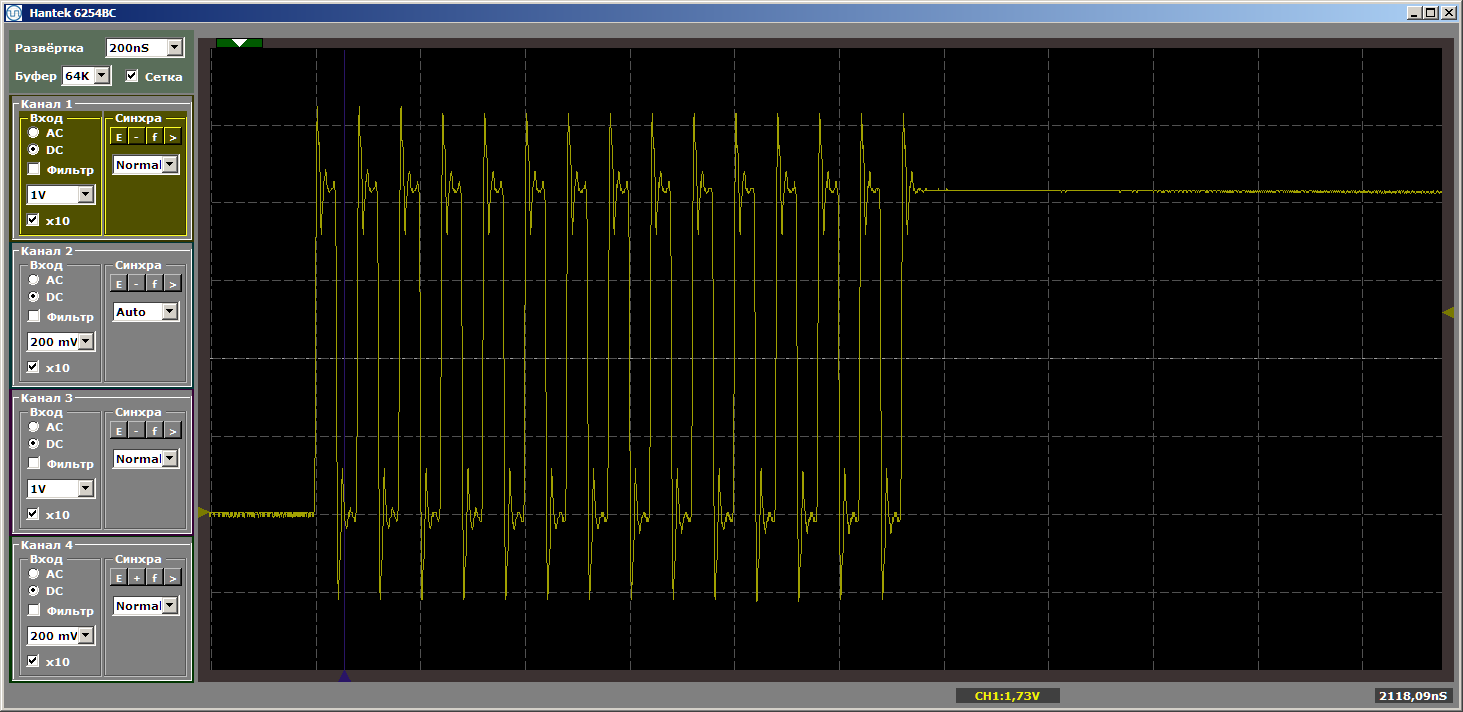
Iterasi lain. Dan satu lagi ... Berliku-liku yang stabil. Kami menghapus breakpoint dan menonton pekerjaan dalam dinamika - tidak ada lagi istirahat seperti itu. Ada semburan pulsa tak berujung.
Mengapa kami telah mematahkan impuls pada pass pertama? Kecelakaan? Tidak. Kami berhenti debug dan mulai lagi. Dan lagi-lagi kita mendapatkan impuls yang sobek. Kesenjangan selalu muncul di pintu masuk program.
Petunjuknya terletak pada cache
Sebenarnya, solusi untuk perilaku ini terletak pada cache. Program kami disimpan di SDRAM. Mengambil kode dari SDRAM tidak cepat. Penting untuk memberikan perintah baca, perlu memberikan alamat, dan alamat terdiri dari dua bagian. Anda harus menunggu sebentar. Hanya dengan demikian microcircuit akan memberikan data. Untuk menghindari keterlambatan seperti itu setiap saat, rangkaian mikro dapat mengeluarkan bukan hanya satu, tetapi beberapa kata berurutan. Kami tidak akan mempertimbangkan grafik waktu hari ini, kami akan menundanya untuk artikel berikut.
Nah, di sisi inti prosesor, cache dibuat secara default. Berikut pengaturannya:
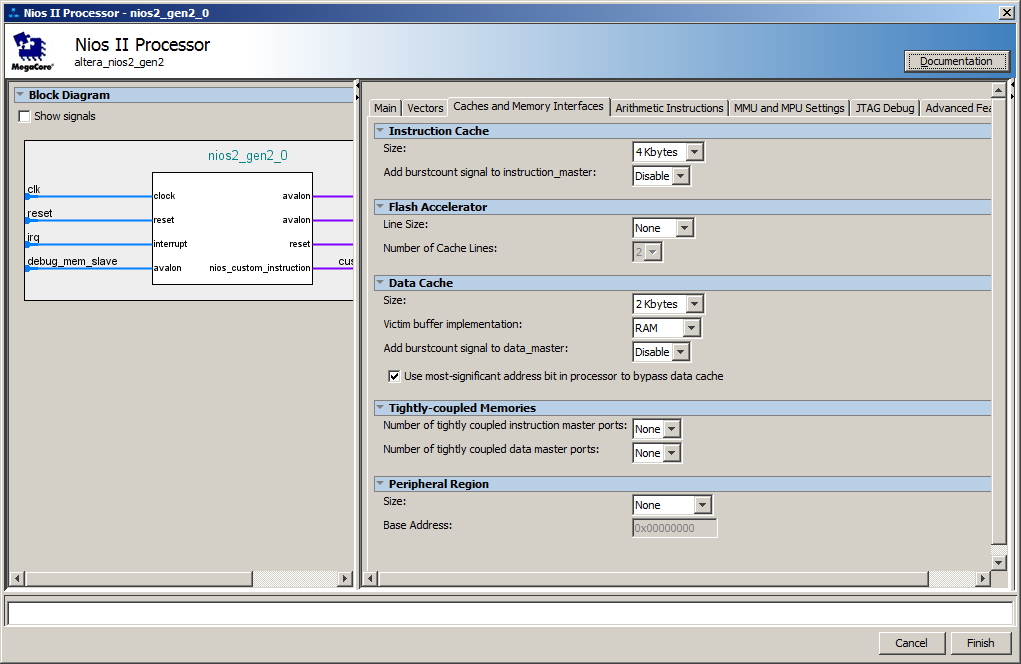
Sebenarnya, penundaan terjadi pada saat pemuatan batch instruksi dari SDRAM ke cache sedang berlangsung. Pada iterasi berikutnya, kode sudah ada dalam cache, jadi pemuatan tidak lagi diperlukan.
Osilogram menunjukkan rata-rata 8 entri per port (satu unit ditulis 4 kali dan nol ditulis 4 kali) per operasi pemuatan. Satu catatan - satu perintah assembler, yang dapat ditemukan dengan memilih item menu Window-> Show View-> Other:
dan kemudian Debug-> Disassembly:
Berikut adalah string kami dan kode perakitan yang sesuai:
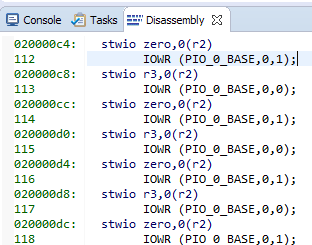
8 tim masing-masing 4 byte. Kami mendapatkan 32 byte per baris cache ... Kami melihat file bantuan favorit kami C: \ Work \ CachePlay \ software \ CachePlay_bsp \ system.h dan lihat:
#define ALT_CPU_ICACHE_LINE_SIZE 32 #define ALT_CPU_ICACHE_LINE_SIZE_LOG2 5
Data praktis dihitung bertepatan dengan teori. Selain itu, dari dokumentasi itu dapat diketahui bahwa ukuran string tidak dapat diubah. Itu selalu sama dengan tiga puluh dua byte.
Percobaan yang sedikit lebih rumit
Mari kita coba memprovokasi cache untuk reboot selama pekerjaan yang sudah mapan. Mari kita ubah sedikit program uji. Kami membuat dua fungsi dan memanggilnya dari fungsi
utama () , menempatkan sebuah loop di dalamnya. Saya tidak akan menetapkan breakpoint. Ngomong-ngomong, jika Anda membuat fungsinya benar-benar identik, pengoptimal akan melihat ini dan menghapus salah satunya, jadi setidaknya satu baris, dan mereka harus berbeda ... Ini adalah apa yang saya tulis di awal: pengoptimal sangat cerdas sekarang.
Kode program pengujian yang dimodifikasi. extern "C" { #include "sys/alt_stdio.h" #include <system.h> #include <io.h> } void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); } int main() { while (1) { MagicFunction1(); MagicFunction2(); } /* Event loop never exits. */ while (1); return 0; }
Kami mendapatkan hasil yang sangat indah, sudah dalam mode yang ditetapkan dari program ini.
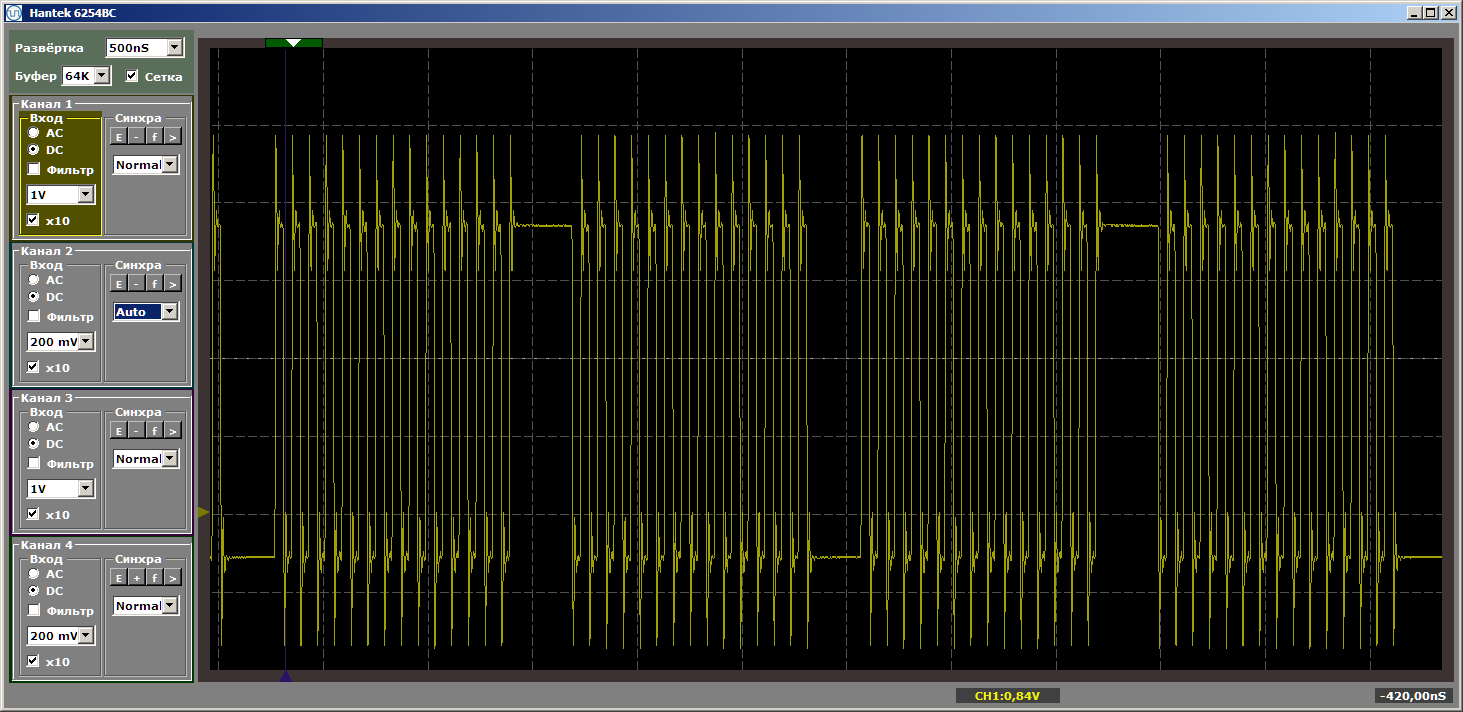
Dan sekarang kami akan menempatkan beberapa fungsi baru di antara sepasang fungsi ini, dan kami tidak akan menyebutnya, itu hanya akan ditempatkan di antara keduanya di dalam memori. Sekarang saya akan mencoba membuatnya mengambil lebih banyak ruang ... Ukuran cache adalah 4 kilobyte, jadi kami akan membuatnya sama dengan empat kilobyte ... Cukup masukkan 1024 NOP, yang masing-masing berukuran 4 byte. Saya akan menunjukkan akhir dari fungsi pertama, fungsi baru dan awal yang kedua, sehingga jelas bagaimana perubahan program:
... IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } #define Nops4 __asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop"); #define Nops16 Nops4 Nops4 Nops4 Nops4 #define Nops64 Nops16 Nops16 Nops16 Nops16 #define Nops256 Nops64 Nops64 Nops64 Nops64 #define Nops1024 Nops256 Nops256 Nops256 Nops256 volatile void FuncBetween() { Nops1024 } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ...
Logikanya program tidak berubah, tetapi ketika dijalankan sekarang kita mendapatkan pulsa robek
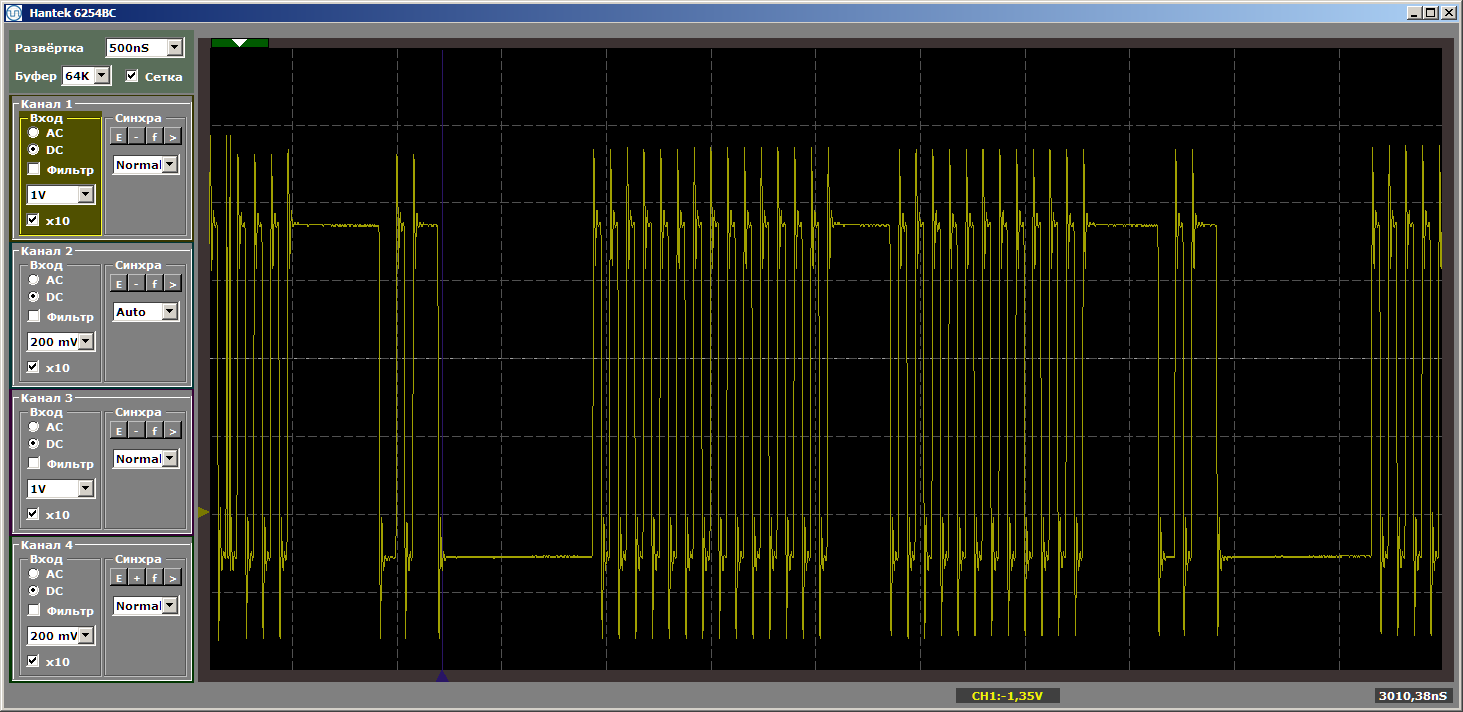
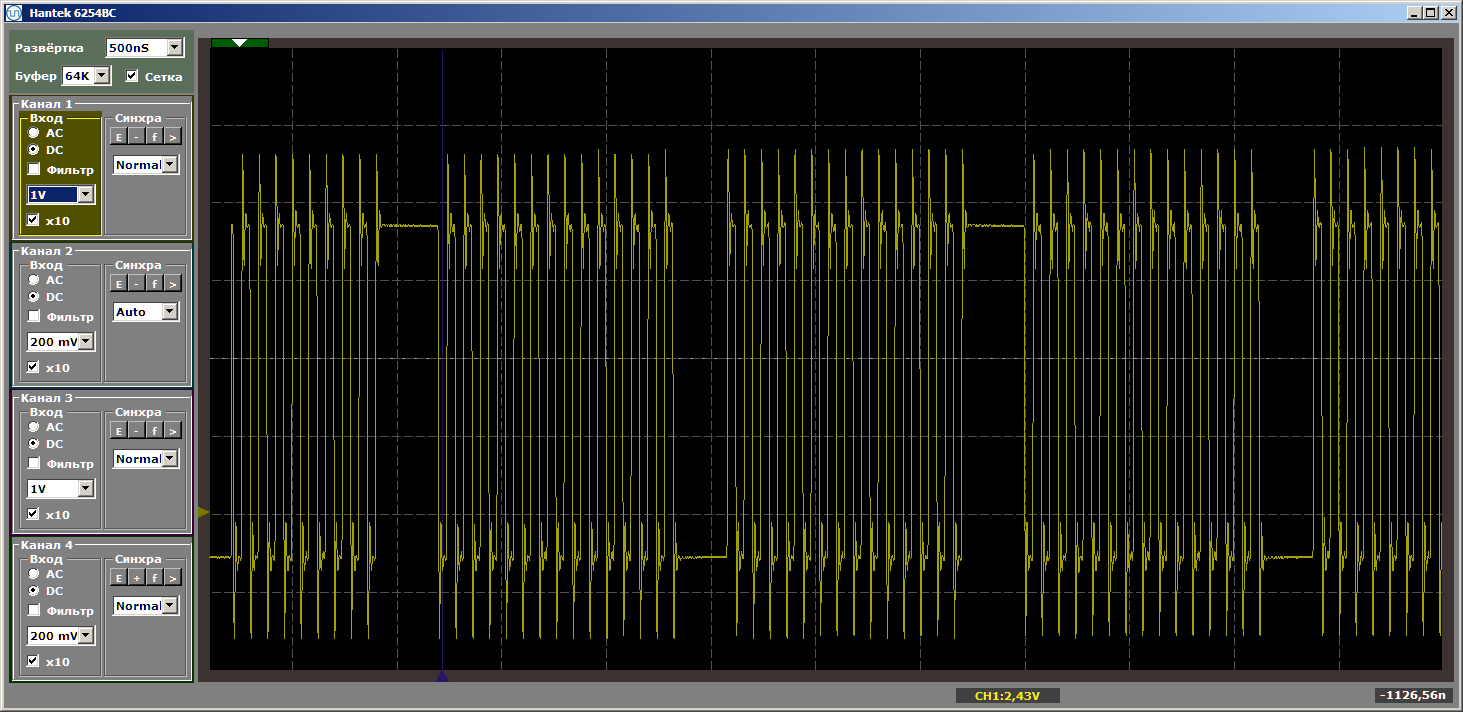
Saya akan mengajukan pertanyaan naif: kami terbang keluar dari cache, dan sekarang, saat celah semakin lebar, apakah selalu ada pemuatan? Tidak semuanya! Ubah ukuran fungsi "buruk", menjadikannya sama dengan, katakanlah, lima kilobyte. Lima lebih dari empat, apakah kita masih terbang? Atau tidak? Ganti sisipan dengan ini:
volatile void FuncBetween() { Nops1024 Nops256 }
Dan lagi kita mendapatkan keindahan:
Jadi apa yang menentukan perlunya memuat kode ke dalam cache? Bisakah kita memprediksi sesuatu, atau setiap kali kita perlu melihat fakta? Mari kita selami teori, yang
Panduan Referensi Prosesor Nios II membantu kita.
Sedikit teori
Ini adalah bagaimana bidang alamat terbelah dalam prosesor:
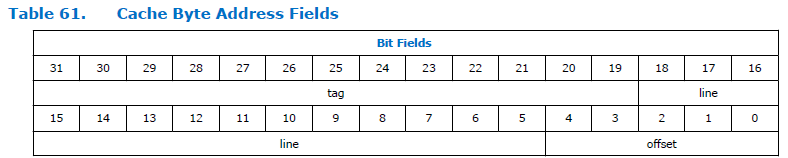
Seperti yang Anda lihat, alamat itu dibagi menjadi tiga bagian. Tag, garis, dan offset. Dimensi bidang offset konstan untuk prosesor Nios II dan selalu lima bit, yaitu dapat mengatasi 32 byte. Dimensi bidang "garis" tergantung pada ukuran cache yang ditentukan saat mengkonfigurasi prosesor. Pada gambar di atas, itu cukup besar. Saya tidak tahu mengapa dokumen tersebut memiliki dimensi yang sangat besar. Kami memiliki ukuran cache 4 kilobyte, yang berarti total kedalaman bit dan offset adalah 12 bit. 5 bit mengambil offset, untuk garis tetap ada 12-5 = 7 bit.
Kami mendapatkan tabel tertentu dengan 128 baris, masing-masing panjangnya 32 byte. Saya akan memberikan, katakanlah, 6 baris pertama:
Maka kami pun beralih ke alamat 0x123
004 . Jika Anda membuang bagian "tidak penting", pasangan "garis + offset" adalah 0x004. Ini adalah rentang baris nol. Data akan dimuat ke dalam baris ini. Dan selanjutnya bekerja dengan data dari kisaran 0x123
000 hingga 0x123
01F akan bekerja melalui cache. Dalam kondisi apa string akan kelebihan beban? Saat mengakses alamat lain yang berakhir dalam rentang dari 0x000 hingga 0x01F. Nah, itu adalah, jika kita beralih ke alamat 0xABC
204 , semuanya akan tetap di tempatnya, karena rentang alamat yang lebih rendah tidak tumpang tindih dengan alamat kita. Dan 0xABC
804 tidak akan merusak apa pun. Tetapi ketika mengeksekusi kode dari alamat 0xABC
004, itu akan menghasilkan konten baru yang dimuat ke dalam baris cache. Dan sudah transisi ke alamat 0x123
004 lagi akan menyebabkan kelebihan. Jika Anda terus-menerus melompat antara 0xABC
004 dan 0x123
004 , kelebihan akan terjadi terus menerus.
Mari kita coba menggambarkan ini dalam bentuk gambar. Misalkan kita hanya memiliki 8 baris dalam cache, lebih mudah untuk memberi warna pada warna yang berbeda. Saya akan membuat ukuran garis 0x10, lebih mudah untuk mengecat alamat dalam gambar (ingat bahwa Nios II sebenarnya ukuran garis selalu 0x20 byte). Memori berdetak pada halaman bersyarat yang ukurannya sama dengan garis cache. Halaman merah memori akan selalu menuju ke garis merah cache, oranye ke oranye, dan seterusnya. Karenanya, konten lama akan dibongkar.

Sebenarnya, perilaku program selama percobaan sekarang jelas. Ketika fungsi dipisahkan secara ketat oleh 4 kilobyte, mereka menekan halaman dengan warna yang sama. Karena itu kodenya
while (1) { MagicFunction1(); MagicFunction2(); }
menyebabkan pemuatan cache demi satu, lalu demi fungsi lainnya. Dan ketika jaraknya bukan 4, tetapi 5 kilobyte, fungsinya diberi spasi menjadi blok-blok warna yang berbeda. Tidak ada konflik, semuanya bekerja tanpa penundaan.
Kesimpulan
Ketika saya membaca beberapa tahun yang lalu bahwa ada garis Cortex A, Cortex R dan Cortex M yang dirancang untuk hal-hal yang produktif, untuk bekerja secara real time dan untuk bekerja dalam sistem yang murah, masing-masing, pada awalnya saya tidak mengerti, tetapi apa, sebenarnya bedanya . Tidak, sistem murah bisa dimengerti, tetapi dua yang pertama adalah apa bedanya? Namun, setelah memainkan inti Cortex A9 yang tersedia di Cyclone V SoC FPGA, saya merasakan semua kekurangan cache ketika bekerja dengan besi. Ada banyak cache di inti Cortex A ... Dan prediktabilitas perilaku sistem hampir nol. Tetapi cache tidak meningkatkan kinerja. Terkadang lebih baik jika semuanya berfungsi tidak dapat diprediksi akurat untuk mengalahkan, tetapi lebih cepat dari yang diperkirakan lambat. Ini terutama berlaku untuk komputasi atau, katakanlah, menampilkan grafik.
Tetapi masalah utama bukanlah bahwa hal-hal yang dijelaskan dalam artikel muncul, tetapi bahwa perilaku sistem akan berubah dari perakitan ke perakitan, karena tidak ada yang tahu alamat fungsi yang akan jatuh setelah menambah atau menghapus kode. 15 tahun yang lalu, dalam proyek emulator konsol game Sega untuk dekoder televisi kabel, kami harus membuat seluruh preprosesor yang, setelah setiap pengeditan, memindahkan fungsi yang meniru perintah assembler Motorola pada inti SPARC-8 sehingga waktu eksekusi mereka selalu sama (di sana). karena cache, kalau tidak semuanya banyak berenang).
Tetapi kapan kita membutuhkan prediktabilitas? Tentu saja, ketika membuat diagram waktu secara terprogram (ingat bahwa secara umum dalam FPGA dimungkinkan untuk mempercayakan ini pada perangkat keras juga, tetapi ada beberapa hal dengan perkembangan cepat). Tetapi ketika bekerja dengan algoritma komputasi, itu tidak begitu penting. Kecuali jika algoritmanya kompleks, maka Anda perlu memastikan bahwa bagian-bagian penting tidak menyebabkan kelebihan cache yang konstan. Dalam kebanyakan kasus, cache tidak menimbulkan masalah, dan produktivitas meningkat.
Pada artikel berikutnya, kita akan melihat bagaimana mungkin untuk mentransfer fungsi-fungsi yang penting untuk dapat diprediksi ke dalam memori yang tidak dapat di-cache, yang selalu bekerja dengan kecepatan maksimum, dan juga membahas keuntungan implisit dari FPGA atas sistem standar yang timbul dari teknologi yang digunakan dalam proses ini.
Untuk yang paling perhatian
Pembaca korosif mungkin bertanya: "Mengapa osilogram tidak cukup robek saat memasukkan empat kilobyte kode?" Semuanya sederhana. Jika Anda memasukkan tepat 4 kilobyte, maka kami mendapatkan alamat berikut untuk menempatkan fungsi dalam memori:
MagicFunction1(): 0200006c: movhi r2,1024 02000070: movi r4,1 02000074: addi r2,r2,4096 02000078: stwio r4,0(r2) 92 IOWR (PIO_0_BASE,0,0); 0200007c: mov r3,zero 02000080: stwio r3,0(r2) 93 IOWR (PIO_0_BASE,0,1); ... 120 IOWR (PIO_0_BASE,0,0); 020000f0: stwio r3,0(r2) 020000f4: ret 131 Nops1024 FuncBetween(): 020000f8: nop 020000fc: nop 02000100: nop 02000104: nop ... 020010ec: nop 020010f0: nop 020010f4: nop 020010f8: ret 135 IOWR (PIO_0_BASE,0,0); MagicFunction2(): 020010fc: movhi r2,1024 02001100: mov r4,zero 02001104: addi r2,r2,4096
Untuk bentuk gelombang yang sangat buruk, Anda harus memasukkan NOP sehingga 4 kilobyte volumenya beserta panjang fungsi
MagicFunction1 () . Apa pun yang Anda lakukan untuk mendapatkan gambar yang indah! Ubah sisipan untuk ini:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 }
Berkali-kali saya perhatikan bahwa sisipan tidak menerima kontrol. Ini hanya mengubah posisi fungsi dalam memori relatif satu sama lain. Dengan sisipan ini, kita mendapatkan horor mengerikan yang diinginkan:
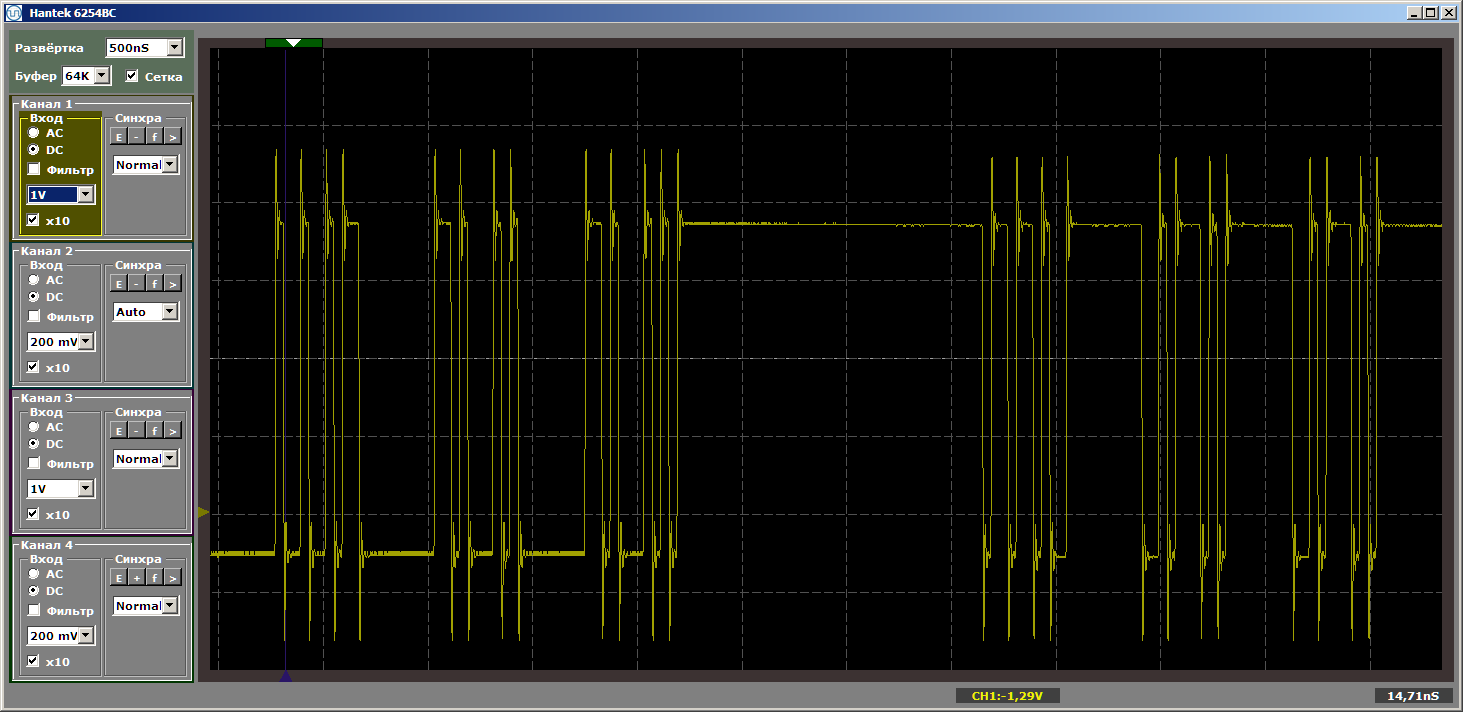
Tampak bagi saya bahwa perincian seperti itu yang dimasukkan ke dalam teks utama akan mengalihkan perhatian semua orang dari yang utama, jadi saya memasukkannya ke dalam postscript.