
Selamat datang di artikel berikutnya dalam
serangkaian teka-teki yang saya tanyakan di wawancara Google sebelum mereka dilarang setelah kebocoran. Sejak itu, saya berhenti bekerja sebagai insinyur perangkat lunak di Google dan pindah ke posisi manajer pengembangan di Reddit, tetapi saya masih memiliki beberapa topik hebat. Sampai saat ini, kami telah memeriksa
pemrograman dinamis ,
meningkatkan matriks ke kekuatan dan
sinonim dari pertanyaan . Kali ini pertanyaan yang sama sekali baru.
Tapi pertama, dua poin. Pertama, pekerjaan di Reddit luar biasa. Selama delapan bulan terakhir, saya telah membangun dan memimpin tim Relevansi Iklan baru dan mendirikan kantor pengembangan baru di New York. Tidak peduli betapa menyenangkannya itu, sayangnya, saya menemukan bahwa sampai saat ini saya tidak punya waktu atau tenaga untuk blog. Saya takut bahwa saya meninggalkan seri ini sedikit. Maaf atas keterlambatannya.
Kedua, jika Anda mengikuti artikel, maka setelah masalah terakhir Anda mungkin berpikir bahwa saya akan mulai menggali opsi sinonim dari pertanyaan. Meskipun saya ingin kembali ke suatu saat, saya harus mengakui bahwa saya kehilangan minat karena masalah ini karena perubahan pekerjaan dan sejauh ini saya memutuskan untuk menundanya. Namun, tetap terhubung! Saya berutang pada saya, dan saya bermaksud mengembalikannya. Hanya, Anda tahu, sedikit kemudian ...
Penafian cepat: Meskipun mewawancarai kandidat adalah salah satu tugas profesional saya, blog ini menyajikan pengamatan pribadi saya, kisah pribadi, dan pendapat pribadi. Tolong jangan mengambil ini untuk pernyataan resmi dari Google, Alfabet, Reddit atau orang atau organisasi lain.Cari pertanyaan baru
Dalam
artikel sebelumnya, saya menggambarkan salah satu pertanyaan favorit saya yang saya gunakan sejak lama, sebelum kebocoran yang tak terhindarkan. Pertanyaan-pertanyaan sebelumnya menarik dari sudut pandang teoretis, tetapi saya ingin memilih masalah yang sedikit lebih relevan bagi Google sebagai sebuah perusahaan. Ketika pertanyaan ini dilarang, saya ingin mencari penggantinya, dengan mempertimbangkan batasan baru: untuk membuat pertanyaan
lebih sederhana .
Sekarang ini mungkin tampak sedikit mengejutkan mengingat proses wawancara yang terkenal di Google. Tetapi pada saat itu masalah yang lebih sederhana masuk akal. Alasan saya terdiri dari dua bagian. Yang pertama adalah pragmatis: para kandidat biasanya tidak dapat mengatasi dengan baik pertanyaan-pertanyaan sebelumnya, meskipun ada banyak petunjuk dan penyederhanaan, dan saya tidak selalu sepenuhnya yakin mengapa. Yang teoretis kedua: proses wawancara harus membagi kandidat ke dalam kategori "layak merekrut" dan "tidak layak merekrut", dan saya ingin tahu apakah ini bisa dilakukan sedikit lebih mudah dengan pertanyaan.
Sebelum mengklarifikasi dua poin ini, saya ingin menunjukkan apa yang
tidak mereka maksudkan. "Saya tidak selalu yakin mengapa seseorang memiliki masalah" tidak berarti ketidakbergunaan pertanyaan dan saya ingin menyederhanakan wawancara karena alasan ini. Bahkan pertanyaan yang paling sulit, banyak diatasi dengan baik. Maksud saya, ketika kandidat memiliki masalah, sulit bagi saya untuk memahami apa yang mereka lewatkan.
Wawancara yang baik memberikan gambaran luas tentang kekuatan dan kelemahan kandidat. Tidak cukup bagi komite perekrutan untuk sekadar mengatakan bahwa itu “gagal”: komite menentukan apakah kandidat memiliki kualitas khusus perusahaan yang mereka cari. Demikian pula, kata-kata "dia keren" tidak membantu panitia memutuskan seorang kandidat yang kuat di beberapa bidang, tetapi ragu-ragu di bidang lain. Saya telah menemukan bahwa masalah yang lebih kompleks terlalu sering memisahkan kandidat ke dalam dua kategori ini. Dalam hal ini, "Saya tidak selalu yakin mengapa seseorang memiliki masalah" berarti "ketidakmampuan untuk maju tentang masalah ini tidak dengan sendirinya melukiskan gambaran kemampuan kandidat ini."
Klasifikasi kandidat sebagai "layak merekrut" dan "tidak layak merekrut"
tidak berarti bahwa proses wawancara harus memisahkan kandidat bodoh dari yang pintar. Saya tidak dapat mengingat satu calon pun yang tidak cerdas, berbakat, dan tidak termotivasi. Banyak yang datang dari universitas-universitas terbaik, dan sisanya jelas sangat termotivasi. Melewati wawancara telepon sudah menjadi saringan yang bagus, dan bahkan menolak pada tahap ini bukanlah pertanda kurangnya kemampuan.
Namun, saya
dapat mengingat banyak orang yang tidak cukup siap untuk wawancara atau bekerja terlalu lambat, atau membutuhkan terlalu banyak pengawasan untuk menyelesaikan masalah, atau dikomunikasikan dengan cara yang tidak jelas, atau tidak dapat menerjemahkan ide-ide mereka ke dalam kode, atau memegang posisi yang tidak akan memimpin Keberhasilannya dalam jangka panjang, dll. Definisi “layak merekrut” tidak jelas dan bervariasi tergantung pada perusahaan, dan proses wawancara adalah untuk menentukan apakah setiap kandidat memenuhi persyaratan perusahaan tertentu.
Saya membaca banyak komentar reddit mengeluh tentang pertanyaan wawancara yang terlalu kompleks. Saya ingin tahu apakah masih mungkin untuk membuat rekomendasi yang layak / tidak layak untuk tugas yang lebih sederhana. Saya curiga ini akan memberikan sinyal yang berguna tanpa perlu berteriak dengan gugup. Saya akan memberi tahu Anda tentang kesimpulan saya di akhir artikel ...
Dengan pemikiran ini, saya mencari pertanyaan baru. Di dunia yang ideal, ini adalah pertanyaan yang cukup sederhana untuk diselesaikan dalam 45 menit, tetapi dengan pertanyaan tambahan sehingga kandidat yang lebih kuat menunjukkan keterampilan mereka. Ini juga harus ringkas dalam implementasi, karena banyak kandidat masih menulis di papan tulis. Nilai tambah besar jika topik tersebut terkait dengan produk Google.
Akhirnya, saya memutuskan sebuah pertanyaan yang dijelaskan dan dimasukkan oleh beberapa orang yang luar biasa ke dalam basis data pertanyaan kami. Sekarang saya telah berkonsultasi dengan mantan rekan kerja dan memastikan bahwa pertanyaannya masih dilarang, jadi Anda pasti tidak akan ditanyai saat wawancara. Saya menyajikannya dalam bentuk yang menurut saya paling efektif, dengan permintaan maaf kepada penulis asli.
Pertanyaan
Bicara tentang mengukur jarak.
Hand adalah satuan ukuran empat inci yang biasa digunakan di negara-negara berbahasa Inggris untuk mengukur ketinggian kuda.
Tahun cahaya adalah satuan pengukuran lain yang sama dengan jarak yang ditempuh partikel (atau gelombang?) Cahaya dalam jumlah detik tertentu, kira-kira sama dengan satu tahun bumi. Pada pandangan pertama, mereka memiliki sedikit kesamaan satu sama lain, kecuali bahwa mereka digunakan untuk mengukur jarak. Tetapi ternyata Google dapat mengonversinya dengan mudah:

Ini mungkin tampak jelas: pada akhirnya, keduanya mengukur jarak, jadi jelas bahwa ada transformasi. Tetapi jika Anda memikirkannya, ini agak aneh: bagaimana mereka menghitung tingkat konversi ini? Jelas, tidak ada yang benar-benar menghitung jumlah tangan dalam satu tahun yang cerah. Sebenarnya, Anda tidak perlu mengambil ini secara langsung. Anda cukup menggunakan konversi terkenal:
- 1 tangan = 4 inci
- 4 inci = 0,33333 kaki
- 0,33333 kaki = 6,3125e - 5 mil
- 6.3125e - 5 miles = 1.0737e - 17 tahun cahaya
Tujuan dari tugas ini adalah untuk mengembangkan sistem yang akan melakukan transformasi ini. Khususnya:
Pada input Anda memiliki daftar faktor konversi (diformat dalam bahasa pilihan Anda) dalam bentuk seperangkat unit pengukuran awal, unit akhir dan faktor, misalnya:
ft 12
yard kaki 0,3333333
dll.
Sehingga ORIGIN * MULTIPLIER = DESTINATION. Kembangkan algoritme yang mengambil dua nilai unit acak dan mengembalikan faktor konversi di antaranya.
Diskusi
Saya suka masalah ini karena memiliki jawaban yang intuitif dan jelas: cukup konversi dari satu unit ke unit lain, lalu ke unit berikutnya, hingga Anda menemukan target! Saya tidak dapat mengingat satu calon pun yang mengalami masalah ini dan benar-benar bingung bagaimana menyelesaikannya. Ini cocok dengan persyaratan masalah yang “lebih sederhana”, karena yang sebelumnya biasanya membutuhkan studi dan refleksi yang panjang sebelum setidaknya ditemukan pendekatan dasar untuk solusi.
Namun demikian, banyak kandidat gagal menyadari intuisi mereka sebagai solusi yang berhasil tanpa petunjuk yang jelas. Salah satu keuntungan dari pertanyaan ini adalah ia menguji kemampuan kandidat untuk merumuskan masalah (untuk membuat pembingkaian) sehingga cocok untuk dianalisis dan dikodekan. Seperti yang akan kita lihat, ada satu ekstensi yang sangat menarik di sini yang membutuhkan lompatan konseptual baru.
Untuk konteks, pembingkaian adalah tindakan menerjemahkan masalah dengan solusi yang tidak jelas ke dalam masalah yang setara, di mana solusi disimpulkan dengan cara yang alami. Jika ini kedengarannya benar-benar abstrak dan tidak bisa ditembus, saya minta maaf, tapi itu benar. Saya akan menjelaskan apa yang saya maksud ketika saya menyajikan solusi awal untuk masalah ini. Bagian pertama dari solusi akan menjadi latihan dalam mengembangkan dan menerapkan pengetahuan algoritmik. Bagian kedua akan menjadi latihan dalam memanipulasi pengetahuan ini untuk sampai pada optimasi baru dan tidak jelas.
Bagian 0. Intuisi
Sebelum menggali lebih dalam, mari kita sepenuhnya mengeksplorasi solusi "jelas". Sebagian besar konversi yang diperlukan sederhana dan mudah. Setiap orang Amerika yang telah bepergian ke luar Amerika Serikat tahu bahwa sebagian besar dunia menggunakan unit "kilometer" misterius untuk mengukur jarak. Untuk mengkonversi, Anda hanya perlu mengalikan jumlah mil dengan sekitar 1,6.
Kami telah menemukan hal-hal seperti itu hampir sepanjang hidup kami. Untuk sebagian besar unit, sudah ada konversi yang dihitung sebelumnya, jadi Anda hanya perlu melihatnya di tabel yang sesuai. Tetapi jika tidak ada konversi langsung (misalnya, dari tahun tangan ke tahun), masuk akal untuk membangun jalur konversi, seperti ditunjukkan di atas:
- 1 tangan = 4 inci
- 4 inci = 0,33333 kaki
- 0,33333 kaki = 6,3125e - 5 mil
- 6.3125e - 5 miles = 1.0737e - 17 tahun cahaya
Itu sangat sederhana, saya baru saja datang dengan transformasi seperti itu menggunakan imajinasi saya dan tabel transformasi standar! Namun, masih ada beberapa pertanyaan. Apakah ada cara yang lebih pendek? Seberapa akurat koefisien tersebut? Apakah konversi selalu mungkin? Apakah mungkin mengotomatiskannya? Sayangnya, di sini pendekatan naif rusak.
Bagian 1. Keputusan naif
Sangat menyenangkan bahwa masalah memiliki solusi intuitif, tetapi pada kenyataannya, kesederhanaan ini merupakan hambatan untuk menyelesaikan masalah. Tidak ada yang lebih sulit daripada mencoba memahami dengan cara baru apa yang sudah Anda pahami - paling tidak karena Anda sering tahu lebih sedikit dari yang Anda pikirkan. Sebagai ilustrasi, bayangkan Anda datang untuk wawancara - dan Anda memiliki metode intuitif ini di kepala Anda. Namun dia tidak mengizinkan untuk memecahkan sejumlah masalah penting.
Misalnya, bagaimana jika
tidak ada konversi ? Pendekatan yang jelas tidak mengatakan apa-apa, apakah benar-benar mungkin untuk mengkonversi dari satu unit ke unit lainnya. Jika mereka memberi saya seribu tingkat konversi, akan sangat sulit bagi saya untuk menentukan apakah mungkin secara prinsip. Jika saya diminta melakukan konversi antara unit
pointer dan
jab yang tidak dikenal, maka saya tidak tahu harus mulai dari mana. Bagaimana pendekatan intuitif membantu di sini?
Saya harus mengakui bahwa ini adalah semacam skenario yang dibuat-buat, tetapi ada juga yang lebih realistis. Anda melihat bahwa pernyataan saya tentang masalah hanya mencakup satuan jarak. Ini dilakukan dengan sengaja. Bagaimana jika saya meminta sistem untuk mengubah dari inci ke kilogram? Anda dan saya tahu bahwa ini tidak mungkin karena mereka mengukur tipe yang berbeda, tetapi input tidak mengatakan apa pun tentang “tipe” yang diukur masing-masing unit.
Di sinilah perumusan pertanyaan yang cermat memungkinkan kandidat kuat untuk membuktikan diri.
Sebelum mengembangkan algoritma, mereka memikirkan kasus-kasus ekstrim dari sistem. Dan pernyataan masalah seperti itu dengan sengaja memberi mereka kesempatan untuk bertanya kepada saya apakah kami akan menerjemahkan unit yang berbeda. Ini bukan masalah besar jika terjadi pada tahap awal, tetapi selalu merupakan pertanda baik ketika seseorang bertanya kepada saya di muka: "Apa yang harus dikembalikan oleh program jika konversi tidak memungkinkan?" Mengajukan pertanyaan seperti ini memberi saya gambaran tentang kemampuan kandidat sebelum ia menulis setidaknya satu baris kode.
Tampilan grafikJelas, pendekatan naif tidak cocok, jadi kita perlu berpikir tentang bagaimana melakukan konversi seperti itu? Jawabannya adalah untuk mempertimbangkan satuan sebagai grafik. Ini adalah lompatan pemahaman pertama yang dibutuhkan untuk menyelesaikan masalah ini.
Secara khusus, bayangkan bahwa setiap unit adalah simpul dalam grafik, dan ada tepi dari simpul
A ke simpul
B jika
A dapat dikonversi ke
B :
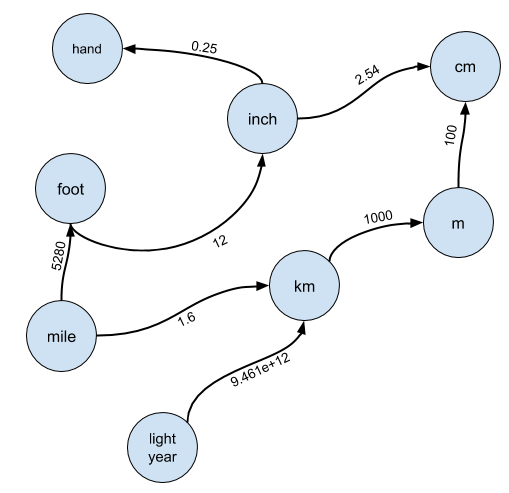
Tepi-tepian ditandai dengan tingkat konversi yang dengannya Anda harus mengalikan
A untuk mendapatkan
BSaya hampir selalu mengharapkan kandidat untuk membuat framing seperti itu, dan jarang memberi petunjuk serius kepadanya. Saya bisa memaafkan kandidat yang tidak melihat solusi untuk masalah menggunakan set disjoint atau tidak terlalu akrab dengan aljabar linier untuk mewujudkan solusi yang mengurangi untuk kembali ke kekuatan matriks kedekatan, tetapi grafik diajarkan pada kurikulum atau kursus pemrograman. Jika kandidat tidak memiliki pengetahuan yang sesuai, ini adalah sinyal “tidak ada perekrutan”.
BagaimanapunRepresentasi grafik mengurangi solusi untuk masalah pencarian grafik klasik. Secara khusus, dua algoritma berguna di sini: pencarian lebar (BFS) dan pencarian dalam (DFS). Saat mencari lebar, kami memeriksa node sesuai dengan jaraknya dari titik asal:
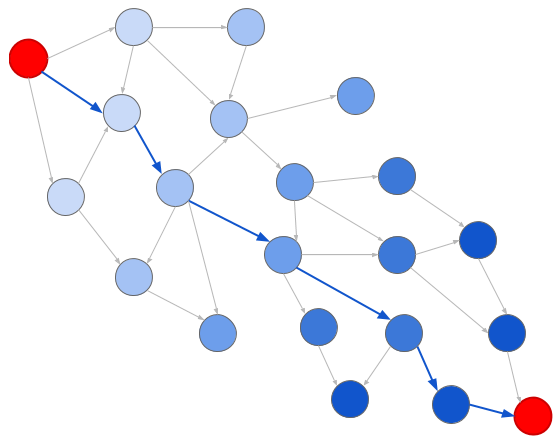 Blues yang lebih gelap berarti generasi selanjutnya
Blues yang lebih gelap berarti generasi selanjutnyaDan ketika mencari secara mendalam, kami memeriksa node sesuai urutan terjadinya:
 Blues yang lebih gelap juga berarti generasi selanjutnya. Harap perhatikan bahwa kami tidak benar-benar mengunjungi semua situs
Blues yang lebih gelap juga berarti generasi selanjutnya. Harap perhatikan bahwa kami tidak benar-benar mengunjungi semua situsSalah satu algoritma dengan mudah menentukan apakah ada konversi dari satu unit ke unit lain, cukup dengan hanya mencari grafik. Kami mulai dari unit sumber dan mencari sampai kami menemukan unit tujuan. Jika Anda tidak dapat menemukan tujuan Anda (seolah-olah mencoba mengonversi inci menjadi kilogram), kami tahu bahwa tidak ada cara.
Tapi tunggu, ada yang hilang. Kami tidak ingin mencari cara, kami ingin menemukan tingkat konversi! Di sinilah kandidat harus melakukan lompatan: ternyata Anda dapat memodifikasi algoritma pencarian apa pun untuk menghitung tingkat konversi hanya dengan menyimpan status tambahan saat Anda maju. Di situlah ilustrasi tidak lagi masuk akal, jadi mari selami kode itu.
Pertama, Anda perlu menentukan struktur data grafik, jadi kami menggunakan ini:
class RateGraph(object): def __init__(self, rates): 'Initialize the graph from an iterable of (start, end, rate) tuples.' self.graph = {} for orig, dest, rate in rates: self.add_conversion(orig, dest, rate) def add_conversion(self, orig, dest, rate): 'Insert a conversion into the graph.' if orig not in self.graph: self.graph[orig] = {} self.graph[orig][dest] = rate def get_neighbors(self, node): 'Returns an iterable of the nodes neighboring the given node.' if node not in self.graph: return None return self.graph[node].items() def get_nodes(self): 'Returns an iterable of all the nodes in the graph.' return self.graph.keys()
Lalu mari kita mulai dari DFS. Ada banyak cara untuk mengimplementasikannya, tetapi sejauh ini yang paling umum adalah solusi rekursif. Mari kita mulai dengan ini:
from collections import deque def __dfs_helper(rate_graph, node, end, rate_from_origin, visited): if node == end: return rate_from_origin visited.add(node) for unit, rate in rate_graph.get_neighbors(node): if unit not in visited: rate = __dfs_helper(rate_graph, unit, end, rate_from_origin * rate, visited) if rate is not None: return rate return None def dfs(rate_graph, node, end): return __dfs_helper(rate_graph, node, end, 1.0, set())
Singkatnya, algoritma ini dimulai dengan satu node, iterate atas tetangganya dan segera mengunjungi masing-masing, membuat panggilan rekursif ke fungsi. Setiap panggilan fungsi pada tumpukan menyimpan status iterasi sendiri, jadi ketika satu kunjungan rekursif dikembalikan, induknya segera melanjutkan iterasi. Kami menghindari mengunjungi situs yang sama lagi dengan mempertahankan satu set situs yang dikunjungi di semua panggilan. Kami juga menghitung koefisien dengan menetapkan faktor konversi antara setiap node dan sumber. Jadi, ketika kita menjumpai node / blok target, kita telah membuat koefisien konversi dari node sumber, dan kita bisa mengembalikannya.
Ini adalah implementasi yang bagus, tetapi memiliki dua kelemahan utama. Pertama, bersifat rekursif. Jika ternyata jalur yang diinginkan terdiri dari lebih dari seribu lompatan, kita akan terbang dengan kesalahan. Tentu saja, ini tidak mungkin, tetapi jika ada sesuatu yang tidak dapat diterima untuk layanan jangka panjang, itu adalah kegagalan. Kedua, bahkan jika kita berhasil menyelesaikannya, jawabannya memiliki beberapa sifat yang tidak diinginkan.
Saya sebenarnya sudah memberi petunjuk di awal posting. Pernahkah Anda memperhatikan bagaimana Google menunjukkan tingkat konversi
1.0739e-17 , tetapi perhitungan manual saya memberi
1.0737e-17 ? Ternyata semua perkalian floating point ini membuat orang sudah berpikir untuk menyebarkan kesalahan. Ada terlalu banyak nuansa untuk artikel ini, tetapi intinya adalah bahwa Anda perlu meminimalkan perkalian floating point untuk menghindari kesalahan yang menumpuk dan menyebabkan masalah.
DFS adalah algoritma pencarian yang bagus. Jika ada solusi, itu akan menemukannya. Tetapi dia tidak memiliki properti utama: dia tidak harus menemukan jalan terpendek. Ini penting bagi kami karena jalur yang lebih pendek berarti lebih sedikit lompatan dan lebih sedikit kesalahan karena perkalian floating point. Untuk mengatasi masalah, kita beralih ke BFS.
Bagian 2. Solusi BFS
Pada tahap ini, jika seorang kandidat berhasil mengimplementasikan solusi DFS rekursif dan berhenti pada itu, saya biasanya memberikan setidaknya rekomendasi yang lemah tentang mempekerjakan kandidat ini. Dia memahami masalahnya, memilih pembingkaian yang tepat dan menerapkan solusi yang berfungsi. Ini adalah keputusan yang naif, jadi saya tidak bersikeras mempekerjakannya, tetapi jika dia berhasil dengan baik dengan wawancara lain, saya tidak akan merekomendasikan menolak.
Ini layak untuk diulangi: jika ragu, tuliskan solusi naif! Bahkan jika itu tidak sepenuhnya optimal, keberadaan kode di papan tulis sudah merupakan suatu prestasi, dan seringkali solusi yang tepat dapat ditemukan atas dasar itu. Saya akan mengatakan berbeda: tidak pernah bekerja untuk apa-apa. Kemungkinan besar, Anda memikirkan solusi naif, tetapi tidak ingin menawarkannya, karena Anda tahu itu tidak optimal. Jika Anda siap memberikan solusi terbaik saat ini, itu bagus, tetapi jika tidak, catat kemajuan yang dibuat sebelum beralih ke hal-hal yang lebih kompleks.
Mulai sekarang, mari kita bicara tentang peningkatan algoritma. Kerugian utama dari solusi DFS rekursif adalah bahwa itu adalah rekursif dan tidak meminimalkan jumlah perkalian. Seperti yang akan segera kita lihat, BFS meminimalkan jumlah perkalian, dan juga sangat sulit untuk mengimplementasikannya secara rekursif. Sayangnya, kita harus meninggalkan solusi DFA rekursif, karena untuk memperbaikinya kita perlu menulis ulang kode sepenuhnya.
Tanpa basa-basi lagi, saya menyajikan pendekatan berulang berdasarkan BFS:
from collections import deque def bfs(rate_graph, start, end): to_visit = deque() to_visit.appendleft( (start, 1.0) ) visited = set() while to_visit: node, rate_from_origin = to_visit.pop() if node == end: return rate_from_origin visited.add(node) for unit, rate in rate_graph.get_neighbors(node): if unit not in visited: to_visit.appendleft((unit, rate_from_origin * rate)) return None
Implementasi ini secara fungsional sangat berbeda dari yang sebelumnya, tetapi jika Anda melihat dari dekat, itu melakukan hal yang sama, dengan satu perubahan signifikan: sementara DFS rekursif menyimpan keadaan rute lebih lanjut dalam panggilan stack, secara efektif mengimplementasikan LIFO stack, solusi berulang menyimpannya dalam antrian FIFO
Ini menyiratkan properti "jalur terpendek / jumlah perkalian terkecil". Kami mengunjungi node dalam urutan di mana mereka terjadi, dan dengan cara ini kami mendapatkan generasi node. Node pertama menyisipkan tetangganya, dan kemudian kami mengunjungi tetangga ini secara berurutan, menempel tetangga mereka sepanjang waktu dan seterusnya. Properti jalur terpendek mengikuti dari fakta bahwa node dikunjungi dalam urutan jaraknya dari sumber. Karena itu, ketika kita menemukan tujuan, kita tahu bahwa tidak ada generasi sebelumnya yang bisa mengarah ke sana.
Pada saat ini, kita
hampir selesai. Pertama, Anda perlu menjawab beberapa pertanyaan, dan mereka dipaksa untuk kembali ke perumusan asli masalah.
Pertama, hal paling sepele yang harus dilakukan jika unit aslinya tidak ada? Artinya, kita tidak dapat menemukan simpul dengan nama yang diberikan. Dalam praktiknya, Anda perlu melakukan beberapa normalisasi string sehingga Pound, Pound dan lb menunjuk ke simpul “pound” yang sama (atau beberapa representasi kanonik lainnya), tetapi ini di luar ruang lingkup pertanyaan kami.
Kedua, bagaimana jika tidak ada konversi antara kedua unit? Ingatlah bahwa dalam data awal hanya ada konversi antar unit, dan itu tidak memberikan indikasi apakah mungkin untuk mendapatkan yang lain dari satu unit tertentu. Ini bermuara pada fakta bahwa transformasi dan jalur secara langsung setara, jadi jika tidak ada jalur antara dua node, maka tidak ada transformasi. Dalam praktiknya, Anda berakhir dengan pulau unit yang tidak terkait: satu untuk jarak, satu untuk bobot, satu untuk mata uang, dll.
Akhirnya, jika Anda perhatikan dengan seksama pada grafik di atas, ternyata Anda tidak dapat mengkonversi antara tangan dan tahun cahaya dengan solusi ini. Arah koneksi antara node berarti bahwa tidak ada jalan dari tahun cahaya ke tangan. Namun, ini cukup mudah untuk diperbaiki, karena transformasi dapat dibalik. Kami dapat mengubah kode inisialisasi grafik kami sebagai berikut:
def add_conversion(self, orig, dest, rate): 'Insert a conversion into the graph. Note we insert its inverse also.' if orig not in self.graph: self.graph[orig] = {} self.graph[orig][dest] = rate if dest not in self.graph: self.graph[dest] = {} self.graph[dest][orig] = 1.0 / rate
Bagian 3. Evaluasi
Selesai! Jika kandidat telah mencapai titik ini, maka saya kemungkinan besar akan merekomendasikan dia untuk disewa. Jika Anda mempelajari ilmu komputer atau mengambil kursus dalam algoritma, Anda dapat bertanya: "Apakah ini benar-benar cukup untuk mendapatkan wawancara dengan orang ini?", Untuk itu saya akan menjawab: "Pada dasarnya, ya."
Sebelum Anda memutuskan bahwa pertanyaannya terlalu sederhana, mari kita lihat apa yang harus dilakukan seorang kandidat untuk mencapai titik ini:
- Pahami pertanyaannya
- Membangun jaringan transformasi dalam bentuk grafik
- Pahami bahwa koefisien dapat dibandingkan dengan tepi grafik
- Lihat kemungkinan menggunakan algoritma pencarian untuk mencapai ini.
- Pilih algoritma favorit Anda dan ubah untuk melacak peluang
- Jika dia menerapkan DFS sebagai solusi naif, kenali kelemahannya.
- Terapkan BFS
- Untuk mundur dan mempelajari kasus-kasus ekstrem:
- Bagaimana jika kita ditanya tentang simpul yang tidak ada?
- Bagaimana jika faktor konversi tidak ada?
- Ketahuilah bahwa transformasi terbalik adalah mungkin dan mungkin perlu
Pertanyaan ini lebih mudah dari yang sebelumnya, tetapi juga sulit. Seperti dalam semua pertanyaan sebelumnya, kandidat harus membuat lompatan mental dari pertanyaan yang dirumuskan secara abstrak ke algoritma atau struktur data yang membuka jalan ke solusi. Satu-satunya hal adalah bahwa algoritma terakhir kurang canggih daripada masalah lainnya. Di luar materi algoritmik ini, persyaratan yang sama berlaku, terutama yang berkaitan dengan kasus ekstrim dan kebenaran.
"Tapi tunggu!" Anda mungkin bertanya. - Bukankah Google terobsesi dengan kompleksitas runtime? Anda bahkan tidak bertanya tentang kompleksitas temporal atau spasial dari masalah ini. Oh well! " Anda juga dapat bertanya: "Tunggu sebentar, Anda memberi peringkat" sangat merekomendasikan untuk disewa "? Bagaimana cara mendapatkannya? " Pertanyaan yang sangat bagus. Ini membawa kita ke babak bonus tambahan final kami ...
Bagian 4. Apakah mungkin untuk melakukan yang lebih baik?
Pada titik ini, saya ingin memberi selamat kepada kandidat dengan jawaban yang baik dan memperjelas bahwa semuanya adalah bonus. Ketika tekanan menghilang, kita bisa mulai menciptakan.
Jadi apa kesulitan menjalankan BFS? Dalam kasus terburuk, kita harus mempertimbangkan setiap node dan edge, yang memberikan kompleksitas linier
O(N+E) . Ini di atas kompleksitas yang sama dari konstruksi grafik
O(N+E) . Untuk mesin pencari, ini mungkin bagus: seribu unit ukuran sudah cukup untuk sebagian besar aplikasi yang masuk akal, dan melakukan pencarian memori untuk setiap permintaan bukanlah kelebihan.
Namun, seseorang dapat melakukan yang lebih baik. Untuk memotivasi, pertimbangkan bagaimana kode ini dimasukkan ke dalam string pencarian. Konversi beberapa unit non-standar sedikit lebih umum, jadi kami akan menghitungnya lagi dan lagi. Setiap kali pencarian dilakukan, nilai menengah dihitung, dan seterusnya.
Sering disarankan untuk hanya men-cache hasil perhitungan. Setiap kali konversi satuan dihitung, kami selalu dapat menambahkan keunggulan di antara dua konversi tersebut. Sebagai bonus, kami mendapatkan transformasi terbalik, dan gratis! Apakah kamu sudah selesai?
Memang, ini akan memberi kita waktu pencarian konstan asimptotik, tetapi akan biaya penyimpanan tepi tambahan. Ini sebenarnya menjadi sangat mahal: seiring waktu, kami akan berusaha untuk grafik yang lengkap, karena semua pasang transformasi secara bertahap dihitung dan disimpan. Jumlah tepi yang mungkin pada grafik adalah setengah kuadrat dari jumlah node, jadi untuk seribu node kita membutuhkan setengah juta tepi. Untuk sepuluh ribu node, sekitar lima puluh juta, dll.
Melampaui ruang lingkup mesin pencari, untuk grafik sejuta node, kami berjuang untuk setengah triliun tepi. Jumlah ini tidak masuk akal untuk disimpan, ditambah kami menghabiskan waktu memasukkan tepi ke dalam grafik. Kita harus berbuat lebih baik.
Untungnya, ada cara untuk mencapai waktu yang konstan untuk mencari koefisien, tanpa pertumbuhan ruang kuadratik. Faktanya, hampir semua yang kita butuhkan ada di bawah hidung kita.
Bagian 4. Waktu konstan
Jadi, caching total sebenarnya dekat dengan solusi optimal. Dalam pendekatan ini, kita (pada akhirnya) mendapatkan tepi di antara semua node, yaitu transformasi kita direduksi menjadi menemukan satu sisi. Tetapi apakah benar-benar perlu untuk menyimpan konversi dari setiap node ke setiap node? Bagaimana jika kita hanya menyimpan faktor konversi dari
satu node ke yang lainnya?
Lihatlah lagi solusi BFS:
from collections import deque def bfs(rate_graph, start, end): to_visit = deque() to_visit.appendleft( (start, 1.0) ) visited = set() while to_visit: node, rate_from_origin = to_visit.pop() if node == end: return rate_from_origin visited.add(node) for unit, rate in rate_graph.get_neighbors(node): if unit not in visited: to_visit.appendleft((unit, rate_from_origin * rate)) return None
Mari kita lihat apa yang terjadi di sini: kita mulai dari simpul sumber, dan untuk setiap simpul yang kita temui, kita menghitung koefisien konversi dari sumber ke simpul ini. Kemudian, segera setelah kami tiba di tujuan, kami mengembalikan koefisien antara titik awal dan akhir dan membuang koefisien antara.
Rasio antara ini adalah kuncinya. Tetapi bagaimana jika kita tidak membuangnya? Bagaimana jika kita menuliskannya? Semua pencarian yang paling kompleks dan tidak dapat dipahami menjadi sederhana: untuk menemukan rasio A ke B, pertama temukan rasio X ke B, kemudian membaginya dengan rasio X ke A, dan Anda selesai! Secara visual, tampilannya seperti ini:
 Perhatikan bahwa antara dua node tidak lebih dari dua sisi
Perhatikan bahwa antara dua node tidak lebih dari dua sisiTernyata untuk menghitung tabel ini, kita hampir tidak perlu mengubah solusi BFS:
from collections import deque def make_conversions(graph): def conversions_bfs(rate_graph, start, conversions): to_visit = deque() to_visit.appendleft( (start, 1.0) ) while to_visit: node, rate_from_origin = to_visit.pop() conversions[node] = (start, rate_from_origin) for unit, rate in rate_graph.get_neighbors(node): if unit not in conversions: to_visit.append((unit, rate_from_origin * rate)) return conversions conversions = {} for node in graph.get_nodes(): if node not in conversions: conversions_bfs(graph, node, conversions) return conversions
Struktur transformasi diwakili oleh kamus unit A dalam dua nilai: root untuk komponen terkait unit A dan koefisien konversi antara unit root dan unit A. Karena kita memasukkan unit ke dalam kamus ini pada setiap kunjungan, kita dapat menggunakan ruang kunci dari kamus ini sebagai serangkaian kunjungan alih-alih menggunakan serangkaian kunjungan khusus. Perhatikan bahwa kami tidak memiliki simpul final, dan alih-alih kami mengulangi simpul tersebut sampai selesai.
Di luar BFS ini, ada fungsi pembantu yang beralih di atas node dalam grafik. Setiap kali bertemu dengan simpul di luar kamus terjemahan, BFS dimulai dari simpul itu. , .
, , :
def convert(conversions, start, end): 'Given a conversion structure, performs a constant-time conversion' try: start_root, start_rate = conversions[start] end_root, end_rate = conversions[end] except KeyError: return None if start_root != end_root: return None return end_rate / start_rate
« » . « » : , , BFS, , . , .
!
O(V+E) ( , ), . , , ó , . , :
O(V+E) , ,
O(V) , .
Hasil
, , , , - . - , . , .
( , , , ), « ». , : , , .
. , , , . — . , , Google ( , , ).
, . , , . , , , , - , .
. DFS, , , . , BFS DFS, , , .
, , «», . , , . . , . : , « » .
, !
, , , , . :
-, : , , . , , . , - , - . , , .
-, , , . — : — , A B — / . : , , , , , . .
Akhirnya, permata nyata: beberapa unit dinyatakan sebagai kombinasi dari unit dasar yang berbeda. Misalnya, satu watt didefinisikan dalam sistem SI sebagai kg • m² / s³. Tugas terakhir adalah memperluas sistem ini untuk mendukung konversi antara unit-unit ini, dengan hanya mempertimbangkan definisi unit SI dasar.Jika Anda memiliki pertanyaan, jangan ragu untuk menghubungi saya di reddit .Kesimpulan
, , . : , , , . , , , , : , . , , , .
, . , , . . , , . —
.