Salut, orang Khabrovit! Selamat untuk semua pada hari programmer dan membagikan terjemahan artikel, yang disiapkan khusus untuk siswa dari kursus "Arsitek Beban Tinggi" . "Sharding. Atau jangan beling. Tanpa berusaha. "
"Sharding. Atau jangan beling. Tanpa berusaha. "
- YodaHari ini kita akan membahas pemisahan data antara beberapa server MySQL. Kami selesai sharding pada awal 2012, dan sistem ini masih digunakan untuk menyimpan data dasar kami.
Sebelum kita membahas cara berbagi data, mari kenali mereka dengan lebih baik. Kami akan menyiapkan cahaya yang bagus, mendapatkan stroberi dalam cokelat, mengingat kutipan dari Star Trek ...
Pinterest adalah mesin pencari untuk semua yang menarik minat Anda. Dalam hal data, Pinterest adalah grafik minat manusia terbesar di dunia. Ini berisi lebih dari 50 miliar pin yang telah disimpan oleh pengguna di lebih dari satu miliar papan. Orang-orang menyimpan pin untuk diri mereka sendiri dan seperti pin lainnya, berlangganan pin, papan, dan minat lainnya, melihat feed rumah semua pin, papan, dan minat tempat mereka berlangganan. Hebat! Sekarang mari kita buat skalabel!
Pertumbuhan yang menyakitkan
Pada 2011, kami mulai mendapatkan momentum. Menurut beberapa
perkiraan , kami tumbuh lebih cepat dari startup mana pun yang dikenal saat itu. Sekitar September 2011, setiap komponen infrastruktur kami kelebihan beban. Kami memiliki beberapa teknologi NoSQL yang kami miliki, dan semuanya gagal total. Kami juga memiliki banyak budak MySQL, yang biasa kami baca, yang menyebabkan banyak kesalahan luar biasa, terutama saat caching. Kami membangun kembali seluruh model penyimpanan kami. Untuk bekerja secara efisien, kami dengan hati-hati mendekati pengembangan persyaratan.
Persyaratan
- Seluruh sistem harus sangat stabil, mudah dioperasikan dan skala dari ukuran kotak kecil ke ukuran bulan saat situs tumbuh.
- Semua konten yang dihasilkan oleh pinner harus tersedia di situs kapan saja.
- Sistem harus mendukung permintaan untuk pin N di papan tulis dalam urutan deterministik (misalnya, dalam urutan terbalik waktu pembuatan atau dalam urutan yang ditentukan oleh pengguna). Hal yang sama berlaku untuk pinners seperti, pin mereka, dll.
- Untuk mempermudah, Anda harus mengusahakan pembaruan dengan segala cara yang memungkinkan. Untuk mendapatkan konsistensi yang diperlukan, mainan tambahan, seperti jurnal transaksi yang didistribusikan, akan diperlukan. Sangat menyenangkan dan (tidak terlalu) mudah!
Filsafat Arsitektur dan Catatan
Karena kami ingin data ini menjangkau beberapa basis data, kami tidak bisa menggunakan gabungan, kunci asing, dan indeks untuk mengumpulkan semua data, meskipun mereka dapat digunakan untuk subquery yang tidak menjangkau basis data.
Kami juga perlu menjaga keseimbangan muatan pada data. Kami memutuskan bahwa memindahkan data, elemen demi elemen, akan membuat sistem menjadi tidak perlu dan menyebabkan banyak kesalahan. Jika kami perlu memindahkan data, lebih baik memindahkan seluruh simpul virtual ke simpul fisik lain.
Agar implementasi kami cepat masuk ke sirkulasi, kami membutuhkan solusi paling sederhana dan paling nyaman dan node yang sangat stabil di platform data terdistribusi kami.
Semua data harus direplikasi ke mesin slave untuk membuat cadangan, dengan ketersediaan tinggi dan membuang ke S3 untuk MapReduce. Kami berinteraksi dengan master hanya pada produksi. Pada produksi, Anda tidak akan ingin menulis atau membaca di slave. Slave lag, dan itu menyebabkan bug aneh. Jika pecahan dilakukan, tidak ada gunanya berinteraksi dengan seorang budak pada produksi.
Akhirnya, kita membutuhkan cara yang baik untuk menghasilkan pengidentifikasi unik universal (UUID) untuk semua objek kita.
Bagaimana kami melakukan sharding
Apa yang akan kami ciptakan, harus memenuhi persyaratan, bekerja secara stabil, secara umum, bisa dikerjakan dan dipelihara. Itulah mengapa kami memilih
teknologi MySQL yang sudah cukup matang sebagai
teknologi yang mendasarinya. Kami sengaja waspada terhadap teknologi baru untuk penskalaan otomatis MongoDB, Cassandra dan Membase, karena mereka cukup jauh dari kedewasaan (dan dalam kasus kami mereka pecah dengan cara yang mengesankan!).
Selain itu: Saya masih merekomendasikan startup untuk menghindari hal-hal aneh baru - coba gunakan MySQL. Percayalah padaku. Saya bisa membuktikannya dengan bekas luka.
MySQL - teknologinya terbukti, stabil, dan sederhana - ia berfungsi. Kami tidak hanya menggunakannya, tetapi juga populer di perusahaan lain dengan skala yang lebih mengesankan. MySQL sepenuhnya memenuhi kebutuhan kami untuk merampingkan kueri data, memilih rentang data tertentu dan transaksi tingkat-baris. Bahkan, di gudang senjatanya ada lebih banyak peluang, tetapi kita semua tidak membutuhkannya. Tetapi MySQL adalah solusi "kemas", jadi data harus dibelokkan. Inilah solusi kami:
Kami mulai dengan delapan server EC2, satu contoh MySQL pada masing-masing:
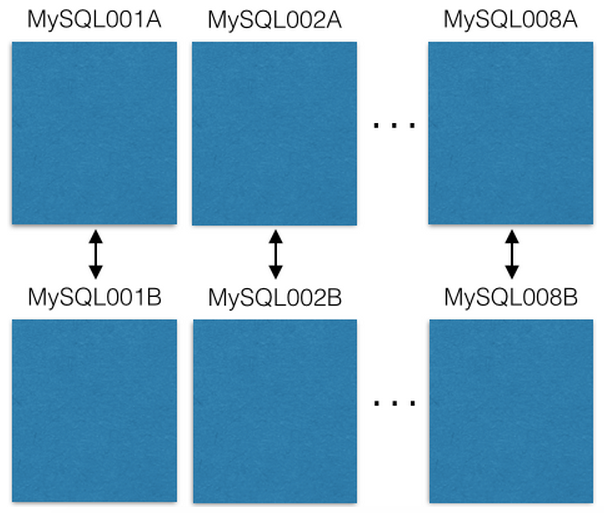
Setiap server master-master MySQL direplikasi ke host cadangan jika terjadi kegagalan primer. Server produksi kami hanya membaca atau menulis untuk dikuasai. Saya sarankan Anda melakukannya juga. Ini sangat menyederhanakan dan menghindari kesalahan dengan penundaan replikasi.
Setiap entitas MySQL memiliki banyak basis data:

Perhatikan bahwa setiap database secara unik dinamai: db00000, db00001 hingga dbNNNNN. Setiap basis data adalah pecahan data kami. Kami membuat keputusan arsitektural, dengan dasar hanya sebagian data yang jatuh ke dalam beling, dan itu tidak pernah melampaui beling ini. Namun, Anda bisa mendapatkan lebih banyak kapasitas dengan memindahkan serpihan ke mesin lain (kami akan membicarakannya nanti).
Kami bekerja dengan tabel konfigurasi yang menunjukkan mesin mana yang memiliki pecahan:
[{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”}, {“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”}, ... {“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}]
Konfigurasi ini hanya berubah ketika kita perlu memindahkan pecahan atau mengganti host. Jika
master mati, kita bisa menggunakan
slave ada, dan kemudian mengambil yang baru. Konfigurasi ini terletak di
ZooKeeper dan, ketika diperbarui, dikirim ke layanan yang melayani MySQL shard.
Setiap pecahan memiliki set tabel yang sama:
pins ,
boards ,
users_has_pins ,
users_likes_pins ,
pin_liked_by_user , dll. Saya akan membicarakannya nanti.
Bagaimana kita mendistribusikan data untuk pecahan ini?
Kami membuat ID 64-bit yang berisi ID beling, tipe data yang terkandung di dalamnya, dan tempat data ini ada di tabel (ID lokal). ID beling terdiri dari 16 bit, tipe ID adalah 10 bit, dan ID lokal adalah 36 bit. Ahli matematika tingkat lanjut akan memperhatikan bahwa hanya ada 62 bit. Pengalaman masa lalu saya sebagai pembuat kompiler dan papan sirkuit telah mengajarkan saya bahwa bit cadangan bernilai emas. Jadi, kami memiliki dua bit seperti itu (set ke nol).
ID = (shard ID << 46) | (type ID << 36) | (local ID<<0)
Mari kita ambil pin ini:
https://www.pinterest.com/pin/241294492511762325/ , mari kita analisis ID-nya 241294492511762325:
Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429 Type ID = (241294492511762325 >> 36) & 0x3FF = 1 Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733
Dengan demikian, objek pin hidup di 3429 beling. Jenisnya adalah "1" (yaitu, "Pin"), dan ada pada baris 7075733 dalam tabel pin. Sebagai contoh, mari kita bayangkan pecahan ini ada di MySQL012A. Kita bisa mendapatkannya sebagai berikut:
conn = MySQLdb.connect(host=”MySQL012A”) conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)
Ada dua jenis data: objek dan pemetaan. Objek berisi bagian, seperti data pin.
Tabel Obyek
Tabel objek seperti Pin, pengguna, papan, dan komentar memiliki ID (ID lokal, dengan kunci primer yang meningkat secara otomatis) dan gumpalan yang berisi JSON dengan semua data objek.
CREATE TABLE pins ( local_id INT PRIMARY KEY AUTO_INCREMENT, data TEXT, ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) ENGINE=InnoDB;
Misalnya, objek pin terlihat seperti ini:
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}
Untuk membuat pin baru, kami mengumpulkan semua data dan membuat gumpalan JSON. Kemudian kami memilih ID beling (kami lebih memilih untuk memilih ID beling yang sama seperti papan tempat ia ditempatkan, tetapi ini tidak perlu). Untuk jenis pin 1. Kami terhubung ke database ini dan memasukkan JSON ke tabel pin. MySQL akan mengembalikan ID lokal yang meningkat secara otomatis. Sekarang kami memiliki pecahan, tipe dan ID lokal baru, sehingga kami dapat mengkompilasi pengidentifikasi 64-bit penuh!
Untuk mengedit pin, kami membaca-memodifikasi-menulis JSON menggunakan
transaksi MySQL :
> BEGIN > SELECT blob FROM db03429.pins WHERE local_id=7075733 FOR UPDATE [Modify the json blob] > UPDATE db03429.pins SET blob='<modified blob>' WHERE local_id=7075733 > COMMIT
Untuk menghapus pin, Anda dapat menghapus barisnya di MySQL. Namun, lebih baik menambahkan bidang
"aktif" di JSON dan mengaturnya ke
"salah" , serta menyaring hasil di sisi klien.
Tabel Pemetaan
Tabel pemetaan menautkan satu objek ke objek lain, misalnya papan dengan pin di atasnya. Tabel MySQL untuk pemetaan berisi tiga kolom: 64-bit untuk ID "from", 64-bit untuk ID "where" dan urutan ID. Dalam triple ini (dari mana, di mana, urutan) ada kunci indeks, dan mereka berada di beling pengidentifikasi "dari".
CREATE TABLE board_has_pins ( board_id INT, pin_id INT, sequence INT, INDEX(board_id, pin_id, sequence) ) ENGINE=InnoDB;
Tabel pemetaan adalah searah, misalnya, seperti tabel
board_has_pins . Jika Anda membutuhkan arah yang berlawanan, Anda perlu tabel
pin_owned_by_board terpisah. ID urutan menentukan urutan (ID kami tidak dapat dibandingkan antara pecahan, karena ID lokal baru berbeda). Biasanya kami memasukkan pin baru di papan baru dengan urutan ID sama dengan waktu di unix (cap waktu unix). Jumlah apa pun dapat berurutan, tetapi waktu unix adalah cara yang baik untuk menyimpan bahan baru secara berurutan, karena indikator ini meningkat secara monoton. Anda dapat melihat data di tabel pemetaan:
SELECT pin_id FROM board_has_pins WHERE board_id=241294561224164665 ORDER BY sequence LIMIT 50 OFFSET 150
Ini akan memberi Anda lebih dari 50 pin_id, yang kemudian dapat Anda gunakan untuk mencari objek pin.
Apa yang baru saja kita lakukan adalah penggabungan lapisan aplikasi (board_id -> pin_id -> objek pin). Salah satu properti koneksi yang menakjubkan pada level aplikasi adalah Anda dapat men-cache gambar secara terpisah dari objek. Kami menyimpan pin_id di cache dari objek pin di cluster memcache, namun kami menyimpan board_id di pin_id di cluster redis. Ini memungkinkan kita untuk memilih teknologi yang tepat yang paling sesuai dengan objek yang di-cache.
Tingkatkan kapasitas
Ada tiga cara utama untuk meningkatkan kapasitas dalam sistem kami. Cara termudah untuk memperbarui mesin (untuk menambah ruang, meletakkan hard drive lebih cepat, lebih banyak RAM).
Cara selanjutnya untuk meningkatkan kapasitas adalah membuka rentang baru. Awalnya, kami membuat total 4096 pecahan, meskipun fakta bahwa ID beling terdiri dari 16 bit (total 64rb pecahan). Objek baru hanya dapat dibuat di pecahan 4k pertama ini. Pada titik tertentu, kami memutuskan untuk membuat server MySQL baru dengan pecahan dari 4096 hingga 8191 dan mulai mengisinya.
Cara terakhir kami meningkatkan kapasitas adalah memindahkan beberapa pecahan ke alat berat baru. Jika kami ingin meningkatkan kapasitas MySQL001A (dengan pecahan dari 0 hingga 511), kami membuat pasangan master-master baru dengan nama maksimum yang mungkin berikut (katakanlah MySQL009A dan B) dan mulai replikasi dari MySQL001A.
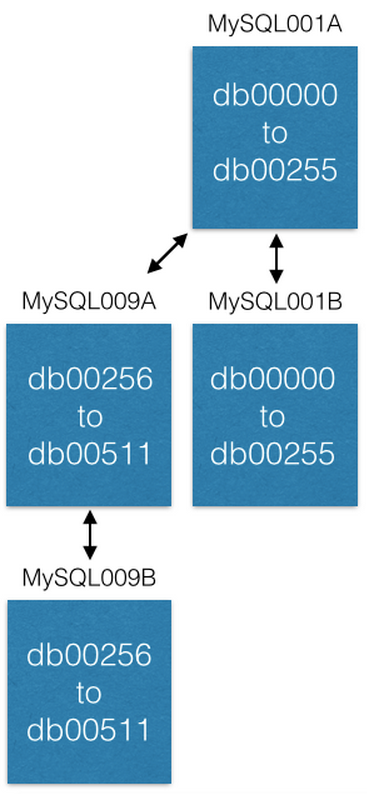
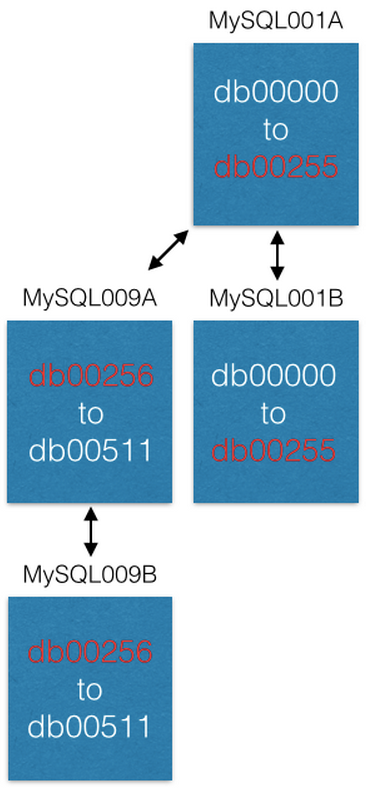
Segera setelah replikasi selesai, kami mengubah konfigurasi kami sehingga di MySQL001A hanya ada pecahan dari 0 hingga 255, dan di MySQL009A dari 256 menjadi 511. Sekarang setiap server harus memproses hanya setengah dari pecahan yang diproses sebelumnya.
Beberapa fitur keren
Mereka yang sudah memiliki sistem untuk menghasilkan
UUID baru akan memahami bahwa dalam sistem ini kita mendapatkannya tanpa biaya! Saat Anda membuat objek baru dan menyisipkannya ke dalam tabel objek, ia mengembalikan pengidentifikasi lokal baru. ID lokal ini, dikombinasikan dengan ID shard dan tipe ID, memberi Anda UUID.
Anda yang telah melakukan ALTER untuk menambahkan lebih banyak kolom ke tabel MySQL tahu bahwa mereka dapat bekerja sangat lambat dan menjadi masalah besar. Pendekatan kami tidak memerlukan perubahan level MySQL. Di Pinterest, kami mungkin hanya membuat satu ALTER dalam tiga tahun terakhir. Untuk menambahkan bidang baru ke objek, cukup beri tahu layanan Anda bahwa ada beberapa bidang baru di skema JSON. Anda dapat mengubah nilai default sehingga saat deserializing JSON dari objek tanpa bidang baru, Anda mendapatkan nilai default. Jika Anda membutuhkan tabel pemetaan, buat tabel pemetaan baru dan mulailah mengisinya kapan pun Anda mau. Dan setelah selesai, Anda dapat mengirim!
Mod beling
Ini hampir seperti
regu mod , hanya sangat berbeda.
Beberapa objek perlu ditemukan tanpa ID. Misalnya, jika pengguna masuk dengan akun Facebook, kami perlu pemetaan dari ID Facebook ke Pinterest ID. Bagi kami, ID Facebook hanyalah bit, jadi kami menyimpannya dalam sistem beling terpisah yang disebut mod shard.
Contoh lain termasuk alamat IP, nama pengguna dan alamat email.
Mod Shard sangat mirip dengan sistem sharding yang dijelaskan di bagian sebelumnya, dengan satu-satunya perbedaan adalah Anda dapat mencari data menggunakan data input yang berubah-ubah. Input ini di-hash dan dimodifikasi sesuai dengan jumlah total pecahan dalam sistem. Akibatnya, sebuah pecahan akan diperoleh di mana data akan atau sudah ditemukan. Sebagai contoh:
shard = md5(“1.2.3.4") % 4096
Dalam hal ini, shard akan sama dengan 1524. Kami memproses file konfigurasi yang sesuai dengan ID shard:
[{“range”: (0, 511), “master”: “msdb001a”, “slave”: “msdb001b”}, {“range”: (512, 1023), “master”: “msdb002a”, “slave”: “msdb002b”}, {“range”: (1024, 1535), “master”: “msdb003a”, “slave”: “msdb003b”}, …]
Jadi, untuk menemukan data pada alamat IP 1.2.3.4, kita perlu melakukan hal berikut:
conn = MySQLdb.connect(host=”msdb003a”) conn.execute(“SELECT data FROM msdb001a.ip_data WHERE ip='1.2.3.4'”)
Anda kehilangan beberapa properti ID shard yang baik, seperti lokalitas spasial. Anda harus mulai dengan semua pecahan yang dibuat di awal dan membuat sendiri kunci (itu tidak akan dihasilkan secara otomatis). Itu selalu lebih baik untuk mewakili objek pada sistem Anda dengan ID abadi. Dengan demikian, Anda tidak perlu memperbarui banyak tautan ketika, misalnya, pengguna mengubah "nama pengguna" -nya.
Pikiran terakhir
Sistem ini telah menjalankan produksi di Pinterest selama 3,5 tahun, dan kemungkinan akan bertahan selamanya. Menerapkannya relatif sederhana, tetapi menjalankannya dan memindahkan semua data dari mesin lama itu sulit. Jika Anda mengalami masalah ketika Anda baru saja membuat pecahan baru, pertimbangkan untuk membuat sekelompok mesin pengolah data latar belakang (petunjuk: gunakan
tumpukan ) untuk memindahkan data Anda dengan skrip dari basis data lama ke pecahan baru Anda. Saya menjamin bahwa beberapa data akan hilang, tidak peduli seberapa keras Anda mencoba (semuanya gremlin, saya bersumpah), jadi ulangi transfer data berulang-ulang sampai jumlah informasi baru di beling menjadi sangat kecil atau tidak sama sekali.
Segala upaya telah dilakukan untuk sistem ini. Tetapi itu tidak memberikan atomitas, isolasi atau koherensi dengan cara apa pun. Wow! Kedengarannya buruk! Tapi jangan khawatir. Tentunya, Anda akan merasa luar biasa tanpa mereka. Anda selalu dapat membangun lapisan ini dengan proses / sistem lain, jika perlu, tetapi secara default dan tanpa biaya Anda sudah mendapatkan cukup banyak: kapasitas kerja. Keandalan dicapai melalui kesederhanaan, dan bahkan bekerja dengan cepat!
Tetapi bagaimana dengan toleransi kesalahan? Kami menciptakan layanan untuk melayani pecahan MySQL, menyimpan tabel konfigurasi pecahan di ZooKeeper. Ketika server master crash, kami menaikkan mesin slave dan kemudian menaikkan mesin yang akan menggantinya (selalu up to date). Kami tidak menggunakan pemrosesan kegagalan otomatis hingga hari ini.