Hai, Habr.
Pada bagian
sebelumnya , kehadiran Habr dianalisis dengan parameter utama - jumlah artikel, pandangan dan peringkat mereka. Namun, pertanyaan tentang popularitas bagian situs tidak dipertimbangkan. Menjadi menarik untuk memeriksa ini secara lebih rinci, dan menemukan hub paling populer dan paling tidak populer. Akhirnya, saya akan memeriksa "efek geektimes" secara lebih rinci, dan pada akhirnya, pembaca akan menerima pilihan baru dari artikel-artikel terbaik pada peringkat baru.
Siapa peduli apa yang terjadi, terus di bawah luka.
Saya mengingatkan Anda sekali lagi bahwa statistik dan peringkat tidak resmi, saya tidak memiliki informasi orang dalam. Juga tidak dijamin bahwa saya tidak salah tempat atau tidak melewatkan sesuatu. Tapi tetap saja, saya pikir itu menarik. Kami akan mulai dengan kode terlebih dahulu, kepada siapa ini tidak relevan, bagian pertama dapat dilewati.
Pengumpulan data
Dalam versi parser pertama, hanya jumlah tampilan, komentar, dan peringkat artikel yang diperhitungkan. Ini sudah bagus, tetapi tidak memungkinkan Anda untuk membuat pertanyaan yang lebih kompleks. Sudah waktunya untuk menganalisis bagian tematik dari situs ini, ini akan memungkinkan kami untuk melakukan studi yang cukup menarik, misalnya, untuk melihat bagaimana popularitas bagian "C ++" telah berubah selama beberapa tahun.
Pengurai artikel telah diperbaiki, sekarang mengembalikan hub tempat artikel tersebut berada, serta nama panggilan penulis dan peringkatnya (di sini Anda juga dapat melakukan banyak hal menarik, tetapi ini nanti). Data disimpan dalam file csv kira-kira tipe berikut:
2018-12-18T12:43Z,https://habr.com/ru/post/433550/," Slack — , , ",votes:7,votesplus:8,votesmin:1,bookmarks:32, views:8300,comments:10,user:ReDisque,karma:5,subscribers:2,hubs:productpm+soft ...
Dapatkan daftar hub tematik utama situs.
def get_as_str(link: str) -> Str: try: r = requests.get(link) return Str(r.text) except Exception as e: return Str("") def get_hubs(): hubs = [] for p in range(1, 12): page_html = get_as_str("https://habr.com/ru/hubs/page%d/" % p)
Fungsi find_between dan kelas Str menyoroti garis antara dua tag, saya menggunakannya
sebelumnya . Hub tematik ditandai dengan "*", sehingga mudah disorot, Anda juga dapat menghapus tanda komentar pada baris yang sesuai untuk mendapatkan bagian dari kategori lain.
Pada output fungsi get_hubs, kami mendapatkan daftar yang cukup mengesankan, yang kami simpan sebagai kamus. Saya secara khusus mengutip seluruh daftar sehingga volumenya dapat diperkirakan.
hubs_profile = {'infosecurity', 'programming', 'webdev', 'python', 'sys_admin', 'it-infrastructure', 'devops', 'javascript', 'open_source', 'network_technologies', 'gamedev', 'cpp', 'machine_learning', 'pm', 'hr_management', 'linux', 'analysis_design', 'ui', 'net', 'hi', 'maths', 'mobile_dev', 'productpm', 'win_dev', 'it_testing', 'dev_management', 'algorithms', 'go', 'php', 'csharp', 'nix', 'data_visualization', 'web_testing', 's_admin', 'crazydev', 'data_mining', 'bigdata', 'c', 'java', 'usability', 'instant_messaging', 'gtd', 'system_programming', 'ios_dev', 'oop', 'nginx', 'kubernetes', 'sql', '3d_graphics', 'css', 'geo', 'image_processing', 'controllers', 'game_design', 'html5', 'community_management', 'electronics', 'android_dev', 'crypto', 'netdev', 'cisconetworks', 'db_admins', 'funcprog', 'wireless', 'dwh', 'linux_dev', 'assembler', 'reactjs', 'sales', 'microservices', 'search_technologies', 'compilers', 'virtualization', 'client_side_optimization', 'distributed_systems', 'api', 'media_management', 'complete_code', 'typescript', 'postgresql', 'rust', 'agile', 'refactoring', 'parallel_programming', 'mssql', 'game_promotion', 'robo_dev', 'reverse-engineering', 'web_analytics', 'unity', 'symfony', 'build_automation', 'swift', 'raspberrypi', 'web_design', 'kotlin', 'debug', 'pay_system', 'apps_design', 'git', 'shells', 'laravel', 'mobile_testing', 'openstreetmap', 'lua', 'vs', 'yii', 'sport_programming', 'service_desk', 'itstandarts', 'nodejs', 'data_warehouse', 'ctf', 'erp', 'video', 'mobileanalytics', 'ipv6', 'virus', 'crm', 'backup', 'mesh_networking', 'cad_cam', 'patents', 'cloud_computing', 'growthhacking', 'iot_dev', 'server_side_optimization', 'latex', 'natural_language_processing', 'scala', 'unreal_engine', 'mongodb', 'delphi', 'industrial_control_system', 'r', 'fpga', 'oracle', 'arduino', 'magento', 'ruby', 'nosql', 'flutter', 'xml', 'apache', 'sveltejs', 'devmail', 'ecommerce_development', 'opendata', 'Hadoop', 'yandex_api', 'game_monetization', 'ror', 'graph_design', 'scada', 'mobile_monetization', 'sqlite', 'accessibility', 'saas', 'helpdesk', 'matlab', 'julia', 'aws', 'data_recovery', 'erlang', 'angular', 'osx_dev', 'dns', 'dart', 'vector_graphics', 'asp', 'domains', 'cvs', 'asterisk', 'iis', 'it_monetization', 'localization', 'objectivec', 'IPFS', 'jquery', 'lisp', 'arvrdev', 'powershell', 'd', 'conversion', 'animation', 'webgl', 'wordpress', 'elm', 'qt_software', 'google_api', 'groovy_grails', 'Sailfish_dev', 'Atlassian', 'desktop_environment', 'game_testing', 'mysql', 'ecm', 'cms', 'Xamarin', 'haskell', 'prototyping', 'sw', 'django', 'gradle', 'billing', 'tdd', 'openshift', 'canvas', 'map_api', 'vuejs', 'data_compression', 'tizen_dev', 'iptv', 'mono', 'labview', 'perl', 'AJAX', 'ms_access', 'gpgpu', 'infolust', 'microformats', 'facebook_api', 'vba', 'twitter_api', 'twisted', 'phalcon', 'joomla', 'action_script', 'flex', 'gtk', 'meteorjs', 'iconoskaz', 'cobol', 'cocoa', 'fortran', 'uml', 'codeigniter', 'prolog', 'mercurial', 'drupal', 'wp_dev', 'smallbasic', 'webassembly', 'cubrid', 'fido', 'bada_dev', 'cgi', 'extjs', 'zend_framework', 'typography', 'UEFI', 'geo_systems', 'vim', 'creative_commons', 'modx', 'derbyjs', 'xcode', 'greasemonkey', 'i2p', 'flash_platform', 'coffeescript', 'fsharp', 'clojure', 'puppet', 'forth', 'processing_lang', 'firebird', 'javame_dev', 'cakephp', 'google_cloud_vision_api', 'kohanaphp', 'elixirphoenix', 'eclipse', 'xslt', 'smalltalk', 'googlecloud', 'gae', 'mootools', 'emacs', 'flask', 'gwt', 'web_monetization', 'circuit-design', 'office365dev', 'haxe', 'doctrine', 'typo3', 'regex', 'solidity', 'brainfuck', 'sphinx', 'san', 'vk_api', 'ecommerce'}
Sebagai perbandingan, bagian geektimes terlihat lebih sederhana:
hubs_gt = {'popular_science', 'history', 'soft', 'lifehacks', 'health', 'finance', 'artificial_intelligence', 'itcompanies', 'DIY', 'energy', 'transport', 'gadgets', 'social_networks', 'space', 'futurenow', 'it_bigraphy', 'antikvariat', 'games', 'hardware', 'learning_languages', 'urban', 'brain', 'internet_of_things', 'easyelectronics', 'cellular', 'physics', 'cryptocurrency', 'interviews', 'biotech', 'network_hardware', 'autogadgets', 'lasers', 'sound', 'home_automation', 'smartphones', 'statistics', 'robot', 'cpu', 'video_tech', 'Ecology', 'presentation', 'desktops', 'wearable_electronics', 'quantum', 'notebooks', 'cyberpunk', 'Peripheral', 'demoscene', 'copyright', 'astronomy', 'arvr', 'medgadgets', '3d-printers', 'Chemistry', 'storages', 'sci-fi', 'logic_games', 'office', 'tablets', 'displays', 'video_conferencing', 'videocards', 'photo', 'multicopters', 'supercomputers', 'telemedicine', 'cybersport', 'nano', 'crowdsourcing', 'infographics'}
Demikian pula, hub yang tersisa diselamatkan. Sekarang mudah untuk menulis fungsi yang mengembalikan hasilnya, artikel merujuk ke geektimes atau ke hub profil.
def is_geektimes(hubs: List) -> bool: return len(set(hubs) & hubs_gt) > 0 def is_geektimes_only(hubs: List) -> bool: return is_geektimes(hubs) is True and is_profile(hubs) is False def is_profile(hubs: List) -> bool: return len(set(hubs) & hubs_profile) > 0
Fungsi serupa dibuat untuk bagian lain ("pengembangan", "administrasi", dll.).
Pengolahan
Saatnya memulai analisis. Kami memuat dataset dan memproses data hub.
def to_list(s: str) -> List[str]:
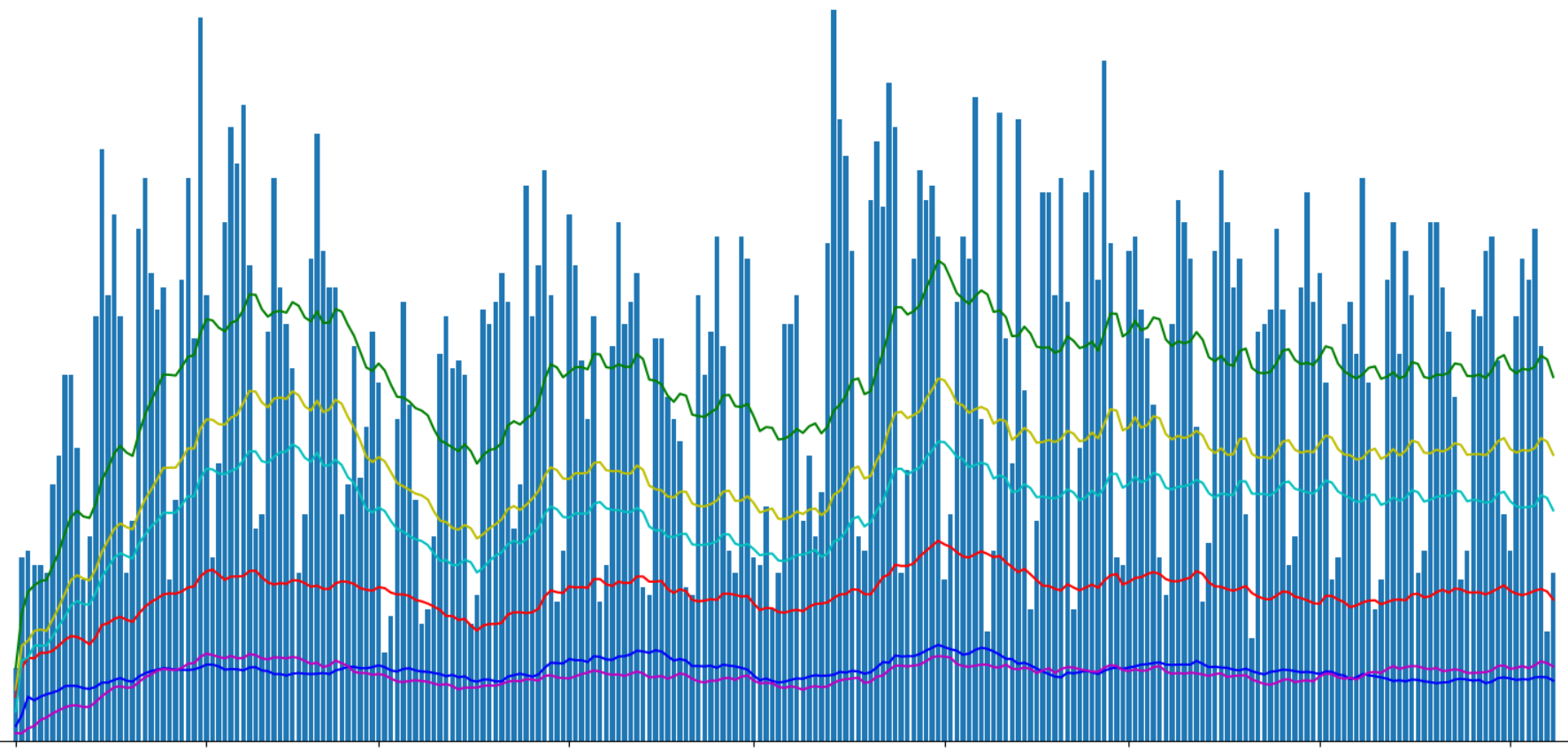
Sekarang kita dapat mengelompokkan data berdasarkan hari dan menampilkan jumlah publikasi berdasarkan hub yang berbeda.
g = df.groupby(['date']) days_count = g.size().reset_index(name='counts') year_days = days_count['date'].values grouped = g.sum().reset_index() profile_per_day_avg = grouped['is_profile'].rolling(window=20, min_periods=1).mean() geektimes_per_day_avg = grouped['is_geektimes'].rolling(window=20, min_periods=1).mean() geektimesonly_per_day_avg = grouped['is_geektimes_only'].rolling(window=20, min_periods=1).mean() admin_per_day_avg = grouped['is_admin'].rolling(window=20, min_periods=1).mean() develop_per_day_avg = grouped['is_develop'].rolling(window=20, min_periods=1).mean()
Tampilkan jumlah artikel yang diterbitkan menggunakan Matplotlib:

Saya membagi artikel "geektimes" dan "hanya geektimes" dalam grafik, karena sebuah artikel dapat menjadi milik kedua bagian secara bersamaan (misalnya, "DIY" + "mikrokontroler" + "C ++"). Dengan “profil” penunjukan, saya menyoroti artikel-artikel profil dari situs tersebut, walaupun ada kemungkinan bahwa profil istilah bahasa Inggris tidak cukup tepat untuk ini.
Pada bagian sebelumnya kami bertanya tentang "efek geektimes" yang terkait dengan perubahan aturan untuk membayar artikel untuk geektimes dari musim panas ini. Kami memperoleh artikel geektimes terpisah:
df_gt = df[(df['is_geektimes_only'] == True)] group_gt = df_gt.groupby(['date']) days_count_gt = group_gt.size().reset_index(name='counts') grouped = group_gt.sum().reset_index() year_days_gt = days_count_gt['date'].values view_gt_per_day_avg = grouped['views'].rolling(window=20, min_periods=1).mean()
Hasilnya menarik. Rasio perkiraan tampilan artikel geektimes dengan total sekitar 1: 5. Tetapi jika jumlah total penayangan berfluktuasi secara nyata, maka tampilan artikel "menghibur" dipertahankan pada tingkat yang hampir sama.

Anda juga dapat melihat bahwa jumlah total penayangan artikel di bagian "geektimes" setelah mengubah aturan masih turun, tetapi "dengan mata", tidak lebih dari 5% dari total nilai.
Sangat menarik untuk melihat jumlah rata-rata tampilan per artikel:

Untuk artikel "menghibur", sekitar 40% di atas rata-rata. Ini mungkin tidak mengejutkan. Kegagalan pada awal April tidak jelas bagi saya, mungkin itu, atau itu semacam kesalahan parsing, atau mungkin salah satu penulis geektimes pergi berlibur;).
By the way, pada grafik adalah dua puncak yang lebih terlihat dalam jumlah tampilan artikel - liburan Tahun Baru dan Mei.
Hub
Mari kita beralih ke analisis hub yang dijanjikan. Kami akan menampilkan 20 hub teratas berdasarkan jumlah tampilan:
hubs_info = [] for hub_name in hubs_all: mask = df['hubs'].apply(lambda x: hub_name in x) df_hub = df[mask] count, views = df_hub.shape[0], df_hub['views'].sum() hubs_info.append((hub_name, count, views))
Hasil:

Yang mengejutkan, hub "Keamanan Informasi" ternyata menjadi yang paling populer dalam hal tampilan, juga "Pemrograman" dan "Ilmu pengetahuan populer" berada di 5 pemimpin teratas.
Antitope mengambil Gtk dan Cocoa.

Saya akan memberi tahu Anda sebuah rahasia, hub teratas juga dapat dilihat di
sini , meskipun jumlah tampilan tidak ditampilkan di sana.
Peringkat
Dan akhirnya, peringkat yang dijanjikan. Menggunakan data dari analisis hub, kami dapat menampilkan artikel paling populer di hub paling populer untuk tahun 2019 ini.
Keamanan informasi- Bagaimana saya tidak bekerja selama setahun di Sberbank 304000 dilihat, 599 komentar, peringkat + 457,0 / -14,0
- Bola lampu pintar yang dibuang ke tempat sampah adalah sumber informasi pribadi yang berharga 232.000 pandangan, 147 komentar, peringkat + 75.0 / -11.0
- Penipu dan EDS - semuanya sangat buruk 176.000 dilihat, 778 komentar, peringkat + 356.0 / -0.0
- Bagaimana Megafon tidur di langganan seluler, 166.000 tampilan, 676 komentar, peringkat + 624.0 / -2.0
- Meretas VK, otentikasi dua faktor tidak akan menyimpan 148.000 tampilan, 332 komentar, peringkat + 124.0 / -17.0
- Bagaimana peramban membantu Kamerad Utama 132.000 tampilan, 321 komentar, peringkat + 246.0 / -19.0
- Dump terbesar dalam sejarah: 2,7 miliar akun, di antaranya 773 juta unik 123.000 tampilan, 154 komentar, peringkat + 86.0 / -5.0
- Sayang, kami membunuh Internet 121.000 dilihat, 933 komentar, peringkat + 392.0 / -83.0
- 'Konten seluler' gratis, tanpa SMS dan pendaftaran. Penipuan Megafon merinci 114.000 tampilan, 478 komentar, rating + 488.0 / -8.0
- Port scanner di akun pribadi dari Rostelecom 111.000 dilihat, 194 komentar, peringkat + 300.0 / -8.0
Pemrograman- Tentang satu orang 167.000 pandangan, 249 komentar, nilai + 239.0 / -33.0
- Semakin cepat Anda melupakan OOP, semakin baik bagi Anda dan program Anda 129.000 tampilan, 1271 komentar, peringkat + 131.0 / -63.0
- Mengapa Pengembang Senior tidak bisa mendapatkan pekerjaan 119.000 tampilan, 901 komentar, peringkat + 151.0 / -14.0
- Orang tua tidak seharusnya berada di sini? Kami memprogram setelah tigapuluh lima 116.000 tampilan, 649 komentar, peringkat + 222.0 / -16.0
- Bahasa pemrograman baru secara tidak kasat mata membunuh koneksi kita dengan kenyataan 106.000 tampilan, 764 komentar, rating + 164.0 / -52.0
- Apa yang saya pelajari dari pengalaman pahit saya (lebih dari 30 tahun dalam pengembangan perangkat lunak) 101.000 tampilan, 128 komentar, peringkat + 178.0 / -9.0
- Bahasa pemrograman paling langka dan paling mahal 82900 dilihat, 119 komentar, rating + 38.0 / -10.0
- Kursus kuliah dalam JavaScript dan Node.js di KPI 80300 tampilan, 14 komentar, peringkat + 34.0 / -2.0
- Istilah IT pada contoh proses penanaman kentang 78.000 tampilan, 86 komentar, rating + 84.0 / -14.0
- 256 baris telanjang C ++: menulis pelacak sinar dari awal dalam beberapa jam, 77600 tampilan, 124 komentar, rating + 241.0 / -0.0
Ilmu pengetahuan populer- Apa yang dihisap perancang: senjata api yang tidak biasa, 236.000 tampilan, 123 komentar, nilai + 119.0 / -9.0
- Para ilmuwan telah menemukan vertebrata hidup tertua di Bumi 234.000 kali dilihat, 212 komentar, peringkat + 82.0 / -14.0
- Seri 'Chernobyl': tonton dan pikirkan 173.000 tampilan, 803 komentar, rating + 164.0 / -25.0
- Seorang remaja 12 tahun melakukan reaksi fusi nuklir di laboratorium rumahnya 145.000 pandangan, 280 komentar, penilaian + 126.0 / -29.0
- The Tale of the Rose Alloy dan the Fallen Krenka 134.000 dilihat, 244 komentar, nilai + 217.0 / -1.0
- Tingkatkan itu! Peningkatan modern dalam resolusi 134000 tampilan, 235 komentar, rating + 377.0 / -1.0
- Perangkat lunak untuk Boeing-737 Max ditulis oleh agen outsourcing menghasilkan $ 9 per jam ; 126.000 tampilan; 560 komentar; peringkat + 153.0 / -6.0
- Jangan gugup, jangan terburu-buru, jangan menyela: kisah satu tragedi 121.000 dilihat, 384 komentar, rating + 242.0 / -4.0
- Matematikawan telah menemukan cara sempurna untuk melipatgandakan angka 108.000 tampilan, 222 komentar, peringkat + 173.0 / -10.0
- Bahasa pemrograman baru secara tidak kasat mata membunuh koneksi kita dengan kenyataan 106.000 tampilan, 764 komentar, rating + 164.0 / -52.0
Karier- Bagaimana saya tidak bekerja selama setahun di Sberbank 304000 dilihat, 599 komentar, peringkat + 457,0 / -14,0
- Saya merusak kehidupan pengembang dengan ulasan kode saya dan saya minta maaf 187.000 tampilan, 21 komentar, rating + 37.0 / -3.0
- Development King 179.000 tampilan, 668 komentar, rating + 315.0 / -60.0
- Tentang satu orang 167.000 pandangan, 249 komentar, nilai + 239.0 / -33.0
- Pensiun pada 22.158.000 tampilan, 927 komentar, nilai + 259.0 / -100.0
- Bagaimana cara mengganti bola lampu di tempat kerja sehingga Anda tidak dipecat? 139000 dilihat, 762 komentar, rating + 200.0 / -20.0
- Inovasi dalam 128.000 tampilan Rusia , 612 komentar, rating + 480.0 / -33.0
- Mengapa Pengembang Senior tidak bisa mendapatkan pekerjaan 119.000 tampilan, 901 komentar, peringkat + 151.0 / -14.0
- Karyawan 'Terbakar': apakah ada jalan keluar? 117000 tampilan, 398 komentar, rating + 210.0 / -14.0
- Orang tua tidak seharusnya berada di sini? Kami memprogram setelah tigapuluh lima 116.000 tampilan, 649 komentar, peringkat + 222.0 / -16.0
Perundang-undangan di bidang TI- Penipu dan EDS - semuanya sangat buruk 176.000 dilihat, 778 komentar, peringkat + 356.0 / -0.0
- Bagaimana Megafon tidur di langganan seluler, 166.000 tampilan, 676 komentar, peringkat + 624.0 / -2.0
- Inovasi dalam 128.000 tampilan Rusia , 612 komentar, rating + 480.0 / -33.0
- 'Konten seluler' gratis, tanpa SMS dan pendaftaran. Penipuan Megafon merinci 114.000 tampilan, 478 komentar, rating + 488.0 / -8.0
- Ketika pihak berwenang dari Kazakhstan mencoba untuk menutupi kegagalan mereka dengan memperkenalkan sertifikat 111.000 pandangan, 77 komentar, peringkat + 122.0 / -14.0
- Bagaimana Protonmail diblokir di Rusia 102000 dilihat, 398 komentar, peringkat + 418.0 / -7.0
- Undang-undang tentang isolasi Runet diadopsi oleh Duma Negara dalam tiga bacaan, 88.200 pandangan, 878 komentar, peringkat + 73.0 / -18.0
- Sebagai seorang programmer, bank memilih dan membaca kontrak 87.200 tampilan, 611 komentar, peringkat + 166.0 / -9.0
- Kementerian Komunikasi dan Media Massa telah menyetujui rancangan undang-undang tentang isolasi pandangan Runet 83600, 364 komentar, rating + 79.0 / -9.0
- Jawaban terperinci untuk komentar, serta sedikit tentang kehidupan penyedia di Federasi Rusia, 74700 dilihat, 389 komentar, peringkat + 290.0 / -1.0
Pengembangan web- Orang tua tidak seharusnya berada di sini? Kami memprogram setelah tigapuluh lima 116.000 tampilan, 649 komentar, peringkat + 222.0 / -16.0
- Cara membuat situs di 2019 110.000 dilihat, 278 komentar, peringkat + 233.0 / -11.0
- Learning Docker, Bagian 1: Dasar-dasar 91300 dilihat, 24 komentar, peringkat + 52.0 / -10.0
- Kursus kuliah dalam JavaScript dan Node.js di KPI 80300 tampilan, 14 komentar, peringkat + 34.0 / -2.0
- Trainee Vasya dan kisah-kisahnya tentang idempotensi API 68900 tampilan, 160 komentar, peringkat + 216.0 / -3.0
- Pemahaman tentang gabungan rusak. Ini jelas bukan persimpangan lingkaran, jujur 65.900 dilihat, 223 komentar, nilai + 138.0 / -41.0
- Mengapa Anda tidak perlu menghabiskan waktu untuk membuat situs tematik niche 62700 tampilan, 243 komentar, peringkat + 179.0 / -13.0
- Kami membuat aplikasi web modern dari awal 62200 tampilan, 122 komentar, rating + 56.0 / -8.0
- Hari yang gelap untuk Vue.js 60.800 tayangan, 133 komentar, nilai + 77.0 / -6.0
- Mengapa pengembangan web modern begitu rumit? Bagian 1.577.700 tayangan, 319 komentar, peringkat + 101.0 / -6.0
GTKDan akhirnya, agar tidak menyinggung siapa pun, saya akan memberi Anda peringkat "gtk" hub yang paling jarang dikunjungi. Di dalamnya,
satu artikel diterbitkan sepanjang tahun, itu juga "secara otomatis" menempati peringkat pertama peringkat.
Kesimpulan
Tidak akan ada kesimpulan. Nikmati membaca untuk semua orang.