CQM adalah pandangan berbeda dalam pembelajaran mendalam untuk mengoptimalkan pencarian bahasa alami
Deskripsi Singkat: Kalibrasi Quantum Mesh (CQM) adalah langkah berikutnya dari RNN / LSTM (Jaringan Syaraf Berulang) / Memori jangka pendek (LSTM). Ada algoritma baru yang disebut Calibrated Quantum Mesh (CQM), yang berjanji untuk meningkatkan akurasi pencarian bahasa alami tanpa menggunakan data pelatihan berlabel.
Algoritma pencarian bahasa alami (NLS) dan pemahaman bahasa alami (NLU) yang sepenuhnya baru telah dibuat, yang tidak hanya melampaui algoritma RNN / LSTM tradisional atau bahkan CNN, tetapi juga belajar mandiri dan tidak memerlukan data yang ditandai untuk pelatihan.
Kedengarannya terlalu bagus untuk menjadi kenyataan, tetapi hasil awalnya mengesankan. CQM - dikembangkan oleh Praful Krishna dan timnya di Coseer (San Francisco).
Meskipun perusahaan ini masih kecil, mereka bekerja dengan beberapa perusahaan Fortune 500 dan telah mulai mengadakan konferensi teknis.
Di sinilah mereka berharap untuk membuktikan diri:
Akurasi: Menurut Krishna, fungsi NLS rata-rata di chatbot yang kurang serius, pada umumnya, memiliki akurasi hanya sekitar 70%.
Aplikasi awal Coseer mencapai akurasi lebih dari 95% dalam mengembalikan informasi relevan yang benar. Kata kunci tidak diperlukan.
Data pelatihan berlabel tidak diperlukan: Kita semua tahu bahwa data pelatihan berlabel adalah biaya keuangan dan waktu yang membatasi keakuratan bot obrolan kami.
Beberapa tahun yang lalu M.D. Anderson meninggalkan eksperimen mahal dan bertahun-tahun dengan IBM Watson untuk onkologi karena keakuratan.
Yang menghambat keakuratan adalah perlunya peneliti kanker yang sangat berpengalaman untuk membubuhi keterangan dokumen di kandang. Mereka seharusnya melakukan ini daripada melakukan penelitian mereka.
Kecepatan implementasi: Coseer mengatakan bahwa tanpa data pelatihan, sebagian besar penyebaran dapat diluncurkan dalam waktu 4-12 minggu. Ini jauh lebih sedikit dibandingkan ketika pengguna mulai menggunakan sistem pra-terlatih, yang operasinya dimulai dengan pemuatan awal dokumen yang ditandai.
Selain itu, tidak seperti vendor besar saat ini yang menggunakan algoritma pembelajaran mendalam tradisional, Coseer lebih memilih untuk menggunakan mereka di cloud yang aman dan pribadi untuk memastikan keamanan data.
Semua "bukti" yang digunakan untuk mencapai kesimpulan apa pun disimpan dalam jurnal yang dapat digunakan untuk menunjukkan transparansi dan kepatuhan terhadap aturan keamanan data seperti GDPR.
Bagaimana cara kerjanya
Coseer berbicara tentang tiga prinsip yang mendefinisikan CQM:
1. Kata-kata (variabel) memiliki arti yang berbeda.
Pertimbangkan kata "oven", yang bisa berupa kata benda atau kata kerja. Misalnya, "ayat", yang dapat berarti "puisi" atau kata kerja "ayat angin" - ini adalah kata-kata homonim.
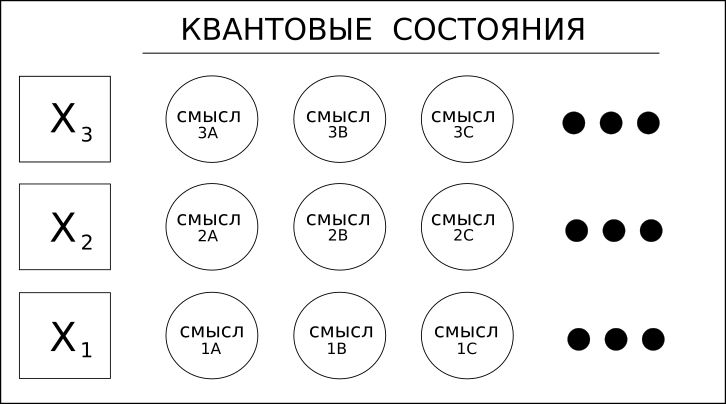
Solusi pembelajaran yang mendalam, termasuk RNN / LSTM atau bahkan CNN untuk teks, hanya dapat melihat ke depan atau ke belakang untuk menentukan "konteks" kata dan dengan demikian menentukan maknanya.
Coseer memperhitungkan semua arti yang mungkin dari kata tersebut dan menerapkan probabilitas statistik untuk masing-masing berdasarkan seluruh dokumen atau korpus.
Penggunaan istilah "kuantum" dalam kasus ini hanya merujuk pada kemungkinan beberapa nilai, dan bukan pada superposisi yang lebih eksotis dari komputasi kuantum.
2. Semuanya saling berhubungan dalam kisi nilai:
Mengekstraksi dari semua kata yang tersedia (variabel) semua kemungkinan hubungan mereka adalah prinsip kedua.
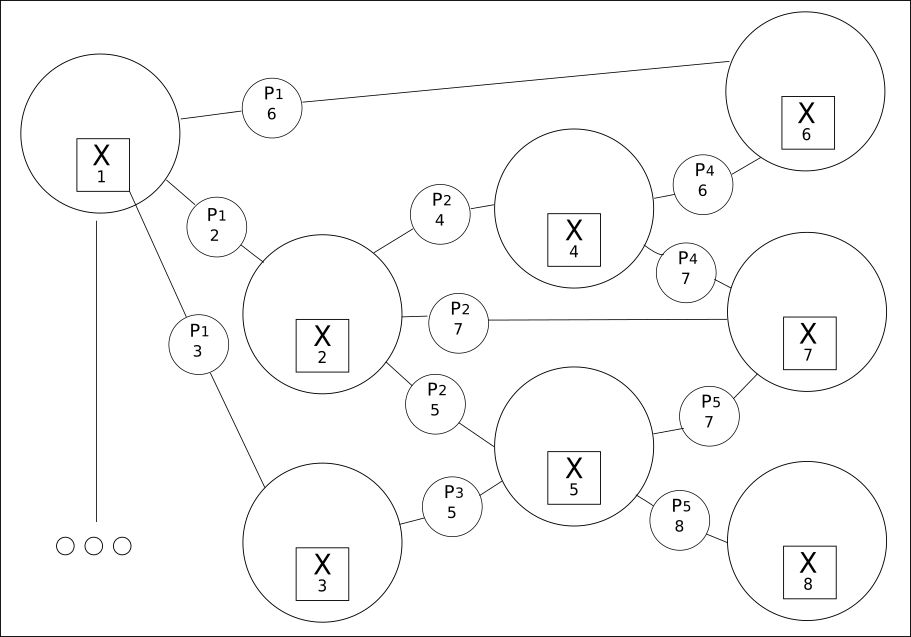
CQM menciptakan kisi-kisi nilai yang mungkin, di antaranya nilai nyata akan ditemukan. Menggunakan pendekatan ini mengungkapkan hubungan yang jauh lebih luas antara frasa-frasa sebelumnya atau berikutnya daripada yang dapat diberikan oleh Deep Learning tradisional.
Meskipun jumlah kata dapat dibatasi, hubungan mereka dapat mencapai ratusan ribu.
3. Semua informasi yang tersedia digunakan secara berurutan untuk menggabungkan kisi-kisi menjadi satu nilai. Proses kalibrasi ini dengan cepat mengidentifikasi kata atau konsep yang hilang dan memberikan pelatihan yang sangat cepat dan akurat.
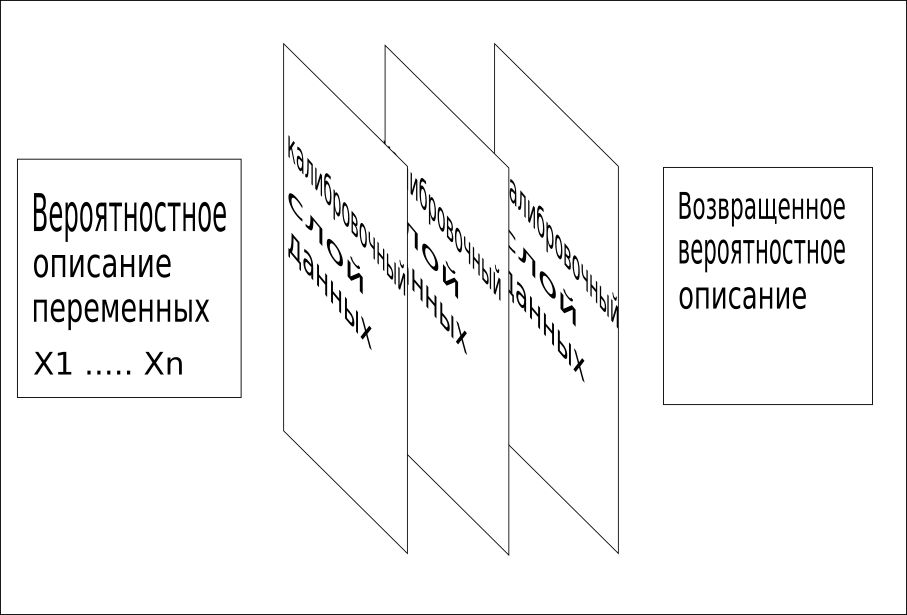
Model CQM menggunakan data pelatihan, data konteks, data referensi, dan fakta lain yang diketahui tentang masalah untuk mengidentifikasi lapisan data kalibrasi ini.
Sayangnya, Coseer telah menerbitkan sangat sedikit dalam domain publik untuk menjelaskan aspek teknis dari algoritma.
Setiap terobosan dalam menghilangkan data yang ditandai selama pelatihan harus disambut, dan, tentu saja, meningkatkan akurasi akan mengarah pada kenyataan bahwa pelanggan yang jauh lebih puas akan menggunakan bot obrolan Anda.