Pendahuluan
Beberapa tahun yang lalu, kami memutuskan bahwa sudah waktunya untuk mendukung kode SIMD di .NET . Kami memperkenalkan System.Numerics namespace dengan tipe Vector2 , Vector3 , Vector4 dan Vector<T> . Jenis-jenis ini mewakili API tujuan umum untuk membuat, mengakses, dan memanipulasi instruksi vektor bila memungkinkan. Mereka juga menyediakan kompatibilitas perangkat lunak untuk kasus-kasus di mana perangkat keras tidak mendukung instruksi yang sesuai. Ini memungkinkan, dengan refactoring minimal, untuk membuat vektor sejumlah algoritma. Namun, secara umum pendekatan ini mempersulit penerapan untuk mendapatkan keuntungan penuh dari semua yang tersedia, pada perangkat keras modern, instruksi vektor. Selain itu, perangkat keras modern menyediakan sejumlah instruksi khusus, non-vektor, yang dapat secara signifikan meningkatkan kinerja. Pada artikel ini, saya akan berbicara tentang bagaimana kami menghindari batasan-batasan ini dalam .NET Core 3.0.

Catatan: Belum ada istilah untuk terjemahan Intrisics . Di akhir artikel ada suara untuk opsi terjemahan. Jika kami memilih opsi yang baik, kami akan mengubah artikel
Apa fungsi bawaan
Di .NET Core 3.0, kami menambahkan fungsionalitas baru yang disebut fungsi bawaan perangkat keras khusus (WF jauh). Fungsionalitas ini menyediakan akses ke banyak instruksi perangkat keras tertentu yang tidak dapat hanya diwakili oleh mekanisme tujuan umum. Mereka berbeda dari instruksi SIMD yang ada dalam hal mereka tidak memiliki tujuan umum ( WF baru bukan lintas platform dan arsitektur mereka tidak memberikan kompatibilitas perangkat lunak). Sebagai gantinya, mereka secara langsung menyediakan fungsionalitas platform dan perangkat keras khusus untuk pengembang .NET. Fungsi SIMD yang ada, misalnya, lintas platform, memberikan kompatibilitas perangkat lunak, dan sedikit disarikan dari perangkat keras yang mendasarinya. Abstraksi ini bisa mahal, selain itu, dapat mencegah pengungkapan beberapa fungsionalitas (ketika, misalnya, fungsionalitas tidak ada, atau sulit untuk ditiru pada semua platform target).
Fungsi bawaan baru , dan tipe yang didukung, terletak di bawah System.Runtime.Intrinsics . Untuk .NET Core 3.0, saat ini, ada satu System.Runtime.Intrinsics.X86 . Kami sedang berupaya mendukung fungsi bawaan untuk platform lain seperti System.Runtime.Intrinsics.Arm .
Di bawah ruang nama khusus platform, WF dikelompokkan ke dalam kelas yang mewakili kelompok instruksi perangkat keras yang terintegrasi secara logis (sering disebut arsitektur set instruksi (ISA)). Setiap kelas menyediakan properti IsSupported menunjukkan apakah perangkat keras yang menjalankan kode mendukung set instruksi ini. Selanjutnya, setiap kelas tersebut berisi serangkaian metode yang dipetakan ke serangkaian instruksi yang sesuai. Kadang-kadang ada subkelas tambahan yang sesuai dengan bagian dari set instruksi yang sama, yang mungkin dibatasi (didukung) oleh perangkat keras tertentu. Sebagai contoh, kelas Lzcnt menyediakan akses ke instruksi untuk menghitung nol terkemuka . Dia memiliki subclass yang disebut X64 , yang berisi bentuk instruksi ini hanya digunakan pada mesin dengan arsitektur 64-bit.
Beberapa kelas ini secara alami bersifat hierarkis. Misalnya, jika Lzcnt.X64.IsSupported mengembalikan true, maka Lzcnt.IsSupported juga harus mengembalikan true, karena ini adalah subkelas eksplisit. Atau, misalnya, jika Sse2.IsSupported mengembalikan true, maka Sse.IsSupported harus mengembalikan true, karena Sse2 secara eksplisit mewarisi dari Sse . Namun, perlu dicatat bahwa kesamaan nama kelas bukan merupakan indikator milik mereka dalam hierarki warisan yang sama. Misalnya, Bmi2 tidak diwarisi dari Bmi1 , sehingga nilai yang dikembalikan oleh IsSupported untuk dua set instruksi ini akan berbeda. Prinsip dasar dalam pengembangan kelas-kelas ini adalah presentasi eksplisit spesifikasi ISA. SSE2 membutuhkan dukungan untuk SSE1, sehingga kelas yang mewakilinya terkait dengan warisan. Pada saat yang sama, BMI2 tidak memerlukan dukungan untuk BMI1, jadi kami tidak menggunakan warisan. Berikut ini adalah contoh dari API di atas.
namespace System.Runtime.Intrinsics.X86 { public abstract class Sse { public static bool IsSupported { get; } public static Vector128<float> Add(Vector128<float> left, Vector128<float> right); // Additional APIs public abstract class X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<float> value); // Additional APIs } } public abstract class Sse2 : Sse { public static new bool IsSupported { get; } public static Vector128<byte> Add(Vector128<byte> left, Vector128<byte> right); // Additional APIs public new abstract class X64 : Sse.X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<double> value); // Additional APIs } } }
Anda dapat melihat lebih banyak di kode sumber di tautan berikut source.dot.net atau dotnet / coreclr di GitHub
Pemeriksaan IsSupported diproses oleh kompiler JIT sebagai konstanta runtime (ketika optimasi diaktifkan), sehingga Anda tidak perlu kompilasi silang untuk mendukung beberapa ISA, platform, atau arsitektur. Sebagai gantinya, Anda hanya perlu menulis kode menggunakan ekspresi if , akibatnya cabang kode yang tidak digunakan (mis. Cabang-cabang yang tidak dapat dijangkau karena nilai variabel dalam pernyataan kondisional) akan dibuang ketika kode asli dihasilkan.
Penting bahwa verifikasi IsSupported sesuai mendahului penggunaan perintah perangkat keras IsSupported . Jika tidak ada pemeriksaan seperti itu, maka kode menggunakan perintah khusus platform yang berjalan pada platform / arsitektur di mana perintah ini tidak didukung akan melempar pengecualian runtime PlatformNotSupportedException .
Apa manfaat yang mereka berikan?
Tentu saja, fungsi bawaan perangkat keras khusus tidak untuk semua orang, tetapi mereka dapat digunakan untuk meningkatkan kinerja dalam operasi yang sarat dengan perhitungan. ML.NET dan ML.NET menggunakan metode ini untuk mempercepat operasi seperti menyalin di memori, mencari indeks elemen dalam array atau string, mengubah ukuran gambar, atau bekerja dengan vektor / matriks / tensor. Vektorisasi manual dari beberapa kode yang ternyata menjadi hambatan juga bisa lebih sederhana daripada yang terdengar. Vektorisasi kode, pada kenyataannya, adalah untuk melakukan beberapa operasi pada suatu waktu, secara umum, menggunakan instruksi SIMD (satu aliran instruksi, banyak aliran data).
Sebelum Anda memutuskan untuk membuat vektor beberapa kode, Anda perlu melakukan profil untuk memastikan bahwa kode ini benar-benar bagian dari "hot spot" (dan, oleh karena itu, optimasi Anda akan memberikan peningkatan kinerja yang signifikan). Penting juga untuk melakukan profil pada setiap tahap vektorisasi, karena vektorisasi tidak semua kode mengarah pada peningkatan produktivitas.
Vektorisasi dari algoritma sederhana
Untuk menggambarkan penggunaan fungsi bawaan, kami menggunakan algoritme untuk menjumlahkan semua elemen array atau rentang. Jenis kode ini adalah kandidat yang ideal untuk vektorisasi, karena pada setiap iterasi, operasi sepele yang sama dilakukan.
Contoh implementasi dari algoritma semacam itu mungkin terlihat sebagai berikut:
public int Sum(ReadOnlySpan<int> source) { int result = 0; for (int i = 0; i < source.Length; i++) { result += source[i]; } return result; }
Kode ini cukup sederhana dan mudah, tetapi pada saat yang sama cukup lambat untuk data input besar, seperti tidak hanya satu operasi sepele per iterasi.
BenchmarkDotNet=v0.11.5, OS=Windows 10.0.18362 AMD Ryzen 7 1800X, 1 CPU, 16 logical and 8 physical cores .NET Core SDK=3.0.100-preview9-013775 [Host] : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT [AttachedDebugger] DefaultJob : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT
Tingkatkan Produktivitas Melalui Siklus Penempatan
Prosesor modern memiliki berbagai opsi untuk meningkatkan kinerja kode. Untuk aplikasi single-threaded, salah satu opsi tersebut adalah melakukan beberapa operasi primitif dalam satu siklus prosesor.
Sebagian besar prosesor modern dapat melakukan empat operasi tambahan dalam satu siklus clock (dalam kondisi optimal), sebagai akibatnya, dengan "tata letak" kode yang benar, Anda kadang-kadang dapat meningkatkan kinerja, bahkan dalam implementasi single-threaded.
Meskipun JIT dapat melakukan loop unrolling sendiri, JIT konservatif dalam membuat keputusan semacam ini, karena ukuran kode yang dihasilkan. Oleh karena itu, mungkin menguntungkan untuk menggunakan loop, dalam kode, secara manual.
Anda dapat memperluas loop dalam kode di atas sebagai berikut:
public unsafe int SumUnrolled(ReadOnlySpan<int> source) { int result = 0; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); // Pin source so we can elide the bounds checks fixed (int* pSource = source) { while (i < lastBlockIndex) { result += pSource[i + 0]; result += pSource[i + 1]; result += pSource[i + 2]; result += pSource[i + 3]; i += 4; } while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
Kode ini sedikit lebih rumit, tetapi lebih baik menggunakan fitur perangkat keras.
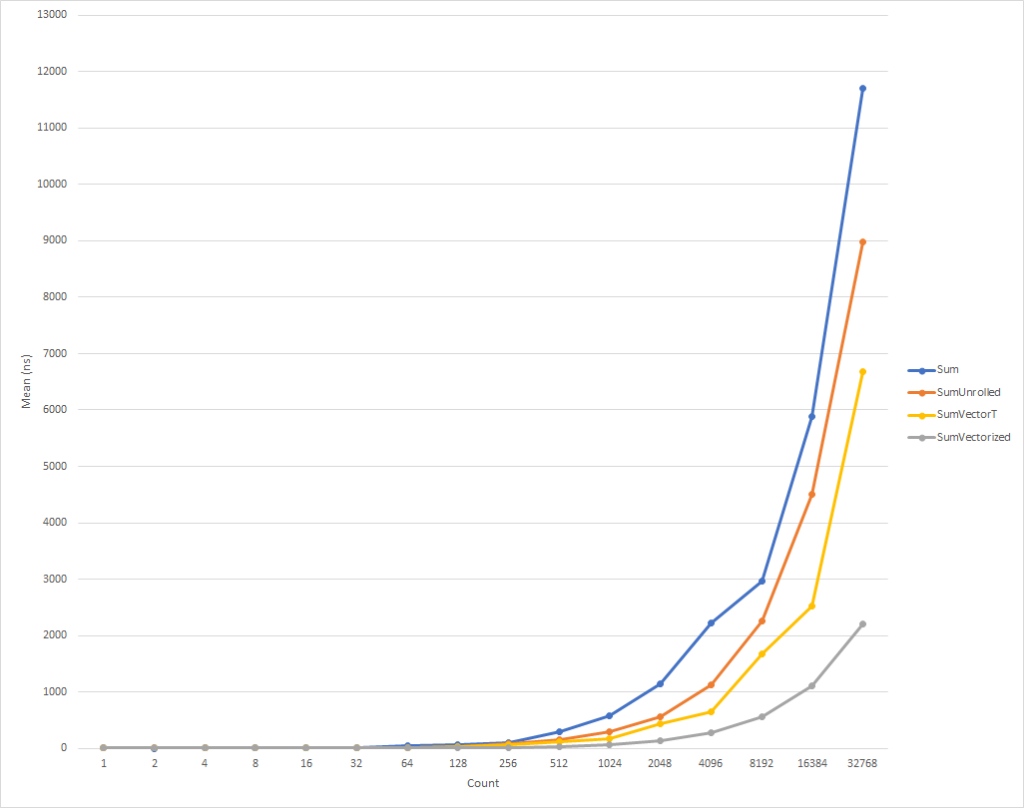
Untuk loop yang sangat kecil, kode ini berjalan sedikit lebih lambat. Tetapi tren ini sudah berubah untuk input data dari delapan elemen, setelah itu kecepatan eksekusi mulai meningkat (waktu eksekusi kode yang dioptimalkan, untuk 32 ribu elemen, lebih sedikit 26% dari waktu versi aslinya). Perlu dicatat bahwa optimasi seperti itu tidak selalu meningkatkan produktivitas. Misalnya, ketika bekerja dengan koleksi dengan elemen tipe float "yang digunakan" dari algoritma memiliki kecepatan yang hampir sama dengan yang asli. Karena itu, sangat penting untuk melakukan profiling.

Tingkatkan produktivitas melalui vektorisasi loop
Meski begitu, tapi kami masih bisa sedikit mengoptimalkan kode ini. Instruksi SIMD adalah opsi lain yang disediakan oleh prosesor modern untuk meningkatkan kinerja. Menggunakan instruksi tunggal, mereka memungkinkan Anda untuk melakukan beberapa operasi dalam satu siklus clock tunggal. Ini mungkin lebih baik daripada loop terbuka berlangsung, karena, pada kenyataannya, hal yang sama dilakukan, tetapi dengan jumlah yang lebih kecil dari kode yang dihasilkan.
Untuk memperjelas, setiap operasi penambahan, dalam siklus yang digunakan, membutuhkan 4 byte. Jadi, kita membutuhkan 16 byte untuk 4 operasi penambahan dalam bentuk diperluas. Pada saat yang sama, instruksi penambahan SIMD juga melakukan 4 operasi tambahan, tetapi hanya membutuhkan 4 byte. Ini berarti kami memiliki lebih sedikit instruksi untuk CPU. Selain itu, dalam kasus instruksi SIMD, CPU dapat membuat asumsi dan melakukan optimasi, tetapi ini di luar ruang lingkup artikel ini. Apa yang lebih baik adalah bahwa prosesor modern dapat menjalankan lebih dari satu instruksi SIMD pada suatu waktu, yaitu, dalam beberapa kasus, Anda dapat menerapkan strategi campuran, pada saat yang sama melakukan pemindaian siklus parsial dan vektorisasi.
Secara umum, Anda harus mulai dengan melihat kelas tujuan umum Vector<T> untuk tugas Anda. Dia, seperti WF baru, akan menanamkan instruksi SIMD, tetapi pada saat yang sama, mengingat keserbagunaan kelas ini, ia dapat mengurangi jumlah pengkodean "manual".
Kode mungkin terlihat seperti ini:
public int SumVectorT(ReadOnlySpan<int> source) { int result = 0; Vector<int> vresult = Vector<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % Vector<int>.Count); while (i < lastBlockIndex) { vresult += new Vector<int>(source.Slice(i)); i += Vector<int>.Count; } for (int n = 0; n < Vector<int>.Count; n++) { result += vresult[n]; } while (i < source.Length) { result += source[i]; i += 1; } return result; }
Kode ini bekerja lebih cepat, tetapi kami dipaksa untuk merujuk ke setiap elemen secara terpisah saat menghitung jumlah akhir. Juga, Vector<T> tidak memiliki ukuran yang ditentukan secara tepat, dan dapat bervariasi, tergantung pada peralatan di mana kode berjalan. fungsi bawaan khusus perangkat keras menyediakan fungsionalitas tambahan yang sedikit dapat meningkatkan kode ini dan membuatnya sedikit lebih cepat (dengan biaya kompleksitas kode tambahan dan persyaratan pemeliharaan).

CATATAN Untuk artikel ini, saya secara paksa membuat ukuran Vector<T> sama dengan 16 byte menggunakan parameter konfigurasi internal ( COMPlus_SIMD16ByteOnly=1 ). Tweak ini menormalkan hasil ketika membandingkan SumVectorT dengan SumVectorizedSse , dan memungkinkan kami untuk menjaga kode tetap sederhana. Secara khusus, ia menghindari penulisan lompatan bersyarat if (Avx2.IsSupported) { } . Kode ini hampir identik dengan kode untuk Sse2 , tetapi berkaitan dengan Vector256<T> (32-byte) dan memproses lebih banyak elemen dalam satu iterasi dari loop.
Dengan demikian, menggunakan fungsi bawaan yang baru, kode dapat ditulis ulang sebagai berikut:
public int SumVectorized(ReadOnlySpan<int> source) { if (Sse2.IsSupported) { return SumVectorizedSse2(source); } else { return SumVectorT(source); } } public unsafe int SumVectorizedSse2(ReadOnlySpan<int> source) { int result; fixed (int* pSource = source) { Vector128<int> vresult = Vector128<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); while (i < lastBlockIndex) { vresult = Sse2.Add(vresult, Sse2.LoadVector128(pSource + i)); i += 4; } if (Ssse3.IsSupported) { vresult = Ssse3.HorizontalAdd(vresult, vresult); vresult = Ssse3.HorizontalAdd(vresult, vresult); } else { vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0x4E)); vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0xB1)); } result = vresult.ToScalar(); while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
Kode ini, sekali lagi, sedikit lebih rumit, tetapi secara signifikan lebih cepat untuk semua orang kecuali set input terkecil. Untuk 32 ribu elemen, kode ini mengeksekusi 75% lebih cepat dari siklus yang diperluas, dan 81% lebih cepat dari kode sumber contoh.
Anda perhatikan bahwa kami menulis beberapa cek yang IsSupported . Yang pertama memeriksa apakah perangkat keras saat ini mendukung sekumpulan fungsi bawaan yang diperlukan, jika tidak, maka optimasi dilakukan melalui kombinasi sapuan dan Vector<T> . Opsi terakhir akan dipilih untuk platform seperti ARM / ARM64 yang tidak mendukung set instruksi yang diperlukan, atau jika set telah dinonaktifkan untuk platform. Tes IsSupported kedua, dalam metode SumVectorizedSse2 , digunakan untuk optimasi tambahan jika perangkat keras mendukung Ssse3 instruksi Ssse3 .
Jika tidak, sebagian besar logikanya pada dasarnya sama dengan loop yang diperluas. Vector128<T> adalah tipe 128-bit yang mengandung Vector128<T>.Count . Dalam hal ini, uint , yang itu sendiri adalah 32-bit, dapat memiliki 4 (128/32) elemen, ini adalah bagaimana kami meluncurkan loop.
Kesimpulan
Fungsi bawaan yang baru memberi Anda kesempatan untuk memanfaatkan fungsionalitas khusus perangkat keras dari mesin tempat Anda menjalankan kode. Ada sekitar 1.500 API untuk X86 dan X64 yang didistribusikan lebih dari 15 set, ada terlalu banyak untuk dijelaskan dalam satu artikel. Dengan membuat profil kode untuk mengidentifikasi kemacetan, Anda dapat menentukan bagian dari kode yang mendapat manfaat dari vektorisasi dan mengamati peningkatan kinerja yang cukup baik. Ada banyak skenario di mana vektorisasi dapat diterapkan dan loop unfolding hanyalah awal.
Siapa pun yang ingin melihat lebih banyak contoh dapat mencari penggunaan fungsi bawaan dalam kerangka kerja (lihat dotnet dan aspnet ), atau di artikel komunitas lainnya. Dan meskipun WF saat ini sangat luas, masih ada banyak fungsi yang perlu diperkenalkan. Jika Anda memiliki fungsi yang ingin Anda perkenalkan, jangan ragu untuk mendaftarkan permintaan API Anda melalui dotnet / corefx di GitHub . Proses peninjauan API dijelaskan di sini dan ada contoh yang bagus dari templat permintaan API yang ditentukan pada langkah 1.
Terima kasih khusus
Saya ingin menyampaikan terima kasih khusus kepada anggota komunitas kami Fei Peng (@fiigii) dan Jacek Blaszczynski (@ 4creators) atas bantuan mereka dalam mengimplementasikan WF , serta kepada semua anggota komunitas atas umpan balik yang berharga mengenai pengembangan, implementasi dan kemudahan penggunaan fungsi ini.
Kata penutup untuk terjemahan
Saya suka mengamati perkembangan platform .NET, dan, khususnya, bahasa C #. Berasal dari dunia C ++, dan memiliki sedikit pengalaman berkembang di Delphi dan Java, saya sangat nyaman memulai program menulis dalam C #. Pada tahun 2006, bahasa pemrograman ini (yaitu bahasa itu) bagi saya lebih ringkas dan praktis daripada Jawa dalam dunia pengumpulan sampah yang dikelola dan lintas-platform. Karena itu, pilihan saya jatuh pada C #, dan saya tidak menyesalinya. Tahap pertama dalam evolusi suatu bahasa hanyalah penampilannya. Pada tahun 2006, C # menyerap semua yang terbaik pada waktu itu dalam bahasa dan platform terbaik: C ++ / Java / Delphi. Pada 2010, F # go public. Itu adalah platform eksperimental untuk mempelajari paradigma fungsional dengan tujuan memperkenalkannya ke dunia .NET. Hasil percobaan adalah tahap berikutnya dalam evolusi C # - perluasan kemampuannya terhadap FP, melalui pengenalan fungsi anonim, ekspresi lambda, dan, pada akhirnya, LINQ. Perpanjangan bahasa ini menjadikan C # yang paling canggih, dari sudut pandang saya, bahasa tujuan umum. Langkah evolusi selanjutnya terkait dengan mendukung konkurensi dan asinkron. Tugas / Tugas <T>, seluruh konsep TPL, pengembangan LINQ - PLINQ, dan, akhirnya, async / menunggu. , - , .NET C# — . Span<T> Memory<T>, ValueTask/ValueTask<T>, IAsyncDispose, ref readonly struct in, foreach, IO.Streams. GC . , — . , .NET C#, , . ( ) .