Artikel sebelumnya membahas arsitektur jaringan tervirtualisasi, overlay-overlay, jalur paket antara VM dan banyak lagi.
Roman Gorge terinspirasi olehnya dan memutuskan untuk menulis masalah ulasan tentang virtualisasi secara umum.
Pada artikel ini kita akan menyentuh (atau mencoba menyentuh) pertanyaan: bagaimana virtualisasi fungsi jaringan benar-benar terjadi, bagaimana backend produk utama untuk meluncurkan dan mengelola VM diterapkan, dan bagaimana switching virtual bekerja (OVS dan Linux bridge).
Topik virtualisasi sangat luas dan mendalam, tidak mungkin menjelaskan semua detail kerja hypervisor (dan itu tidak perlu). Kami akan membatasi diri pada set minimum pengetahuan yang diperlukan untuk memahami operasi solusi virtual apa pun, belum tentu Telco.

Isi
- Pengantar dan sejarah singkat virtualisasi
- Jenis sumber daya virtual - komputasi, penyimpanan, jaringan
- Peralihan virtual
- Alat virtualisasi - libvirt, virsh dan banyak lagi
- Kesimpulan
Pengantar dan sejarah singkat virtualisasi
Sejarah teknologi virtualisasi modern berasal dari tahun 1999, ketika perusahaan muda VMware merilis produk yang disebut VMware Workstation. Ini adalah produk virtualisasi untuk aplikasi desktop / klien. Virtualisasi sisi server datang sedikit kemudian dalam bentuk produk ESX Server, yang kemudian berkembang menjadi ESXi (i berarti terintegrasi) - ini adalah produk yang sama yang digunakan secara universal di TI dan Telco sebagai hypervisor aplikasi server.
Di sisi opensource, dua proyek besar telah membawa virtualisasi ke Linux:
- KVM (Kernel Virtual Machine) adalah modul kernel Linux yang memungkinkan kernel berfungsi sebagai hypervisor (menciptakan infrastruktur yang diperlukan untuk memulai dan mengelola VM). Itu ditambahkan dalam versi kernel 2.6.20 pada 2007.
- QEMU (Quick Emulator) - secara langsung mengemulasi perangkat keras untuk mesin virtual (CPU, Disk, RAM, apa pun termasuk port USB) dan digunakan bersama dengan KVM untuk mencapai kinerja yang hampir "asli".
Faktanya, saat ini, semua fungsionalitas KVM tersedia di QEMU, tetapi ini tidak penting, karena sebagian besar pengguna virtualisasi Linux tidak secara langsung menggunakan KVM / QEMU, tetapi mengaksesnya melalui setidaknya satu level abstraksi, tetapi lebih pada nanti.
Saat ini, VMware ESXi dan Linux QEMU / KVM adalah dua hypervisor utama yang mendominasi pasar. Mereka juga merupakan perwakilan dari dua jenis hypervisor yang berbeda:
- Tipe 1 - hypervisor berjalan langsung pada perangkat keras (bare-metal). Ini adalah VMware ESXi, Linux KVM, Hyper-V
- Tipe 2 - hypervisor diluncurkan di dalam Host OS (sistem operasi). Ini adalah VMware Workstation atau Oracle VirtualBox.
Diskusi tentang apa yang lebih baik dan apa yang lebih buruk berada di luar cakupan artikel ini.

Produsen besi juga harus melakukan bagian mereka untuk memastikan kinerja yang dapat diterima.
Mungkin yang paling penting dan paling banyak digunakan adalah Intel VT (Teknologi Virtualisasi) - satu set ekstensi yang dikembangkan oleh Intel untuk prosesor x86 yang digunakan untuk operasi hypervisor yang efektif (dan dalam beberapa kasus diperlukan, misalnya, KVM tidak akan bekerja tanpa VT dihidupkan) -x dan tanpa itu, hypervisor dipaksa untuk terlibat dalam persaingan perangkat lunak murni, tanpa akselerasi perangkat keras).
Dua dari ekstensi ini paling dikenal - VT-x dan VT-d. Yang pertama adalah penting untuk meningkatkan kinerja CPU selama virtualisasi, karena menyediakan dukungan perangkat keras untuk beberapa fungsinya (dengan VT-x 99,9% kode OS Guest dieksekusi langsung pada prosesor fisik, membuat output untuk emulasi hanya dalam kasus yang paling diperlukan), yang kedua adalah untuk menghubungkan perangkat fisik secara langsung ke mesin virtual (untuk meneruskan fungsi virtual (VF) SRIOV, misalnya, VT-d
harus diaktifkan ).
Konsep penting berikutnya adalah perbedaan antara virtualisasi penuh dan para-virtualisasi.
Virtualisasi penuh bagus, memungkinkan Anda untuk menjalankan sistem operasi apa pun pada prosesor apa pun, namun, itu sangat tidak efisien dan sama sekali tidak cocok untuk sistem yang sarat muatan.
Singkatnya, para-virtualisasi adalah ketika Guest OS memahami bahwa itu berjalan di lingkungan virtual dan bekerja sama dengan hypervisor untuk mencapai efisiensi yang lebih besar. Yaitu, antarmuka tamu-hypervisor muncul.
Sebagian besar sistem operasi yang digunakan saat ini memiliki dukungan untuk para-virtualisasi - di kernel Linux, ini telah muncul sejak kernel versi 2.6.20.
Agar mesin virtual berfungsi, tidak hanya prosesor virtual (vCPU) dan memori virtual (RAM) yang diperlukan, emulasi perangkat PCI juga diperlukan. Faktanya, seperangkat driver diperlukan untuk mengelola antarmuka jaringan virtual, disk, dan sebagainya.
Dalam hypervisor KVM Linux, tugas ini diselesaikan dengan menerapkan
virtio , kerangka kerja untuk mengembangkan dan menggunakan perangkat I / O tervirtualisasi.
Virtio adalah level tambahan abstraksi, yang memungkinkan Anda untuk meniru berbagai perangkat I / O dalam hypervisor para-virtual, menyediakan antarmuka yang seragam dan standar ke sisi mesin virtual. Ini memungkinkan Anda untuk menggunakan kembali kode driver virtio untuk berbagai perangkat yang inheren. Virtio terdiri dari:
- Driver front-end - apa yang ada di mesin virtual
- Driver back-end - apa yang ada di hypervisor
- Pengemudi transportasi - apa yang menghubungkan backend dan frontend
Modularitas ini memungkinkan Anda untuk mengubah teknologi yang digunakan dalam hypervisor tanpa mempengaruhi driver di mesin virtual (titik ini sangat penting untuk teknologi akselerasi jaringan dan solusi Cloud secara umum, tetapi lebih lanjut tentang itu nanti).
Yaitu, ada koneksi tamu-hypervisor ketika OS Guest "tahu" bahwa itu berjalan di lingkungan virtual.
Jika Anda pernah menulis pertanyaan dalam RFP atau menjawab pertanyaan dalam RFP "Apakah virtio didukung dalam produk Anda?" Itu hanya tentang mendukung driver virtio front-end.
Jenis sumber daya virtual - komputasi, penyimpanan, jaringan
Terdiri dari apa mesin virtual itu?
Ada tiga jenis utama sumber daya virtual:
- compute - prosesor dan RAM
- storage - disk sistem mesin virtual dan penyimpanan blok
- jaringan - kartu jaringan dan perangkat input / output
Hitung
CPU
Secara teoritis, QEMU mampu mengemulasi segala jenis prosesor dan flag serta fungsionalitasnya yang sesuai; dalam praktiknya, mereka menggunakan salah satu model host dan mematikan flag secara langsung sebelum memindahkannya ke OS Guest, atau mereka mengambil model-nama dan mengaktifkan / menonaktifkan flag secara searah.
Secara default, QEMU akan mengemulasi prosesor yang OS Tamu akan kenal sebagai QEMU Virtual CPU. Ini bukan tipe prosesor yang paling optimal, terutama jika aplikasi yang berjalan di mesin virtual menggunakan flag CPU untuk pekerjaannya.
Pelajari lebih lanjut tentang berbagai model CPU di QEMU .
QEMU / KVM juga memungkinkan Anda untuk mengontrol topologi prosesor, jumlah utas, ukuran cache, ikat vCPU ke inti fisik dan banyak lagi.
Apakah ini diperlukan untuk mesin virtual atau tidak tergantung pada jenis aplikasi yang berjalan pada OS Guest. Sebagai contoh, itu adalah fakta yang terkenal bahwa untuk aplikasi yang memproses paket dengan PPS tinggi, penting untuk melakukan
pinning CPU , yaitu, tidak memungkinkan prosesor fisik untuk ditransfer ke mesin virtual lainnya.
Memori
Baris berikutnya adalah RAM. Dari sudut pandang Host OS, mesin virtual yang diluncurkan menggunakan QEMU / KVM tidak berbeda dari proses lain yang berjalan di ruang pengguna sistem operasi. Karenanya, proses mengalokasikan memori ke mesin virtual dilakukan oleh panggilan yang sama di kernel Host OS, seolah-olah Anda meluncurkan, misalnya, browser Chrome.
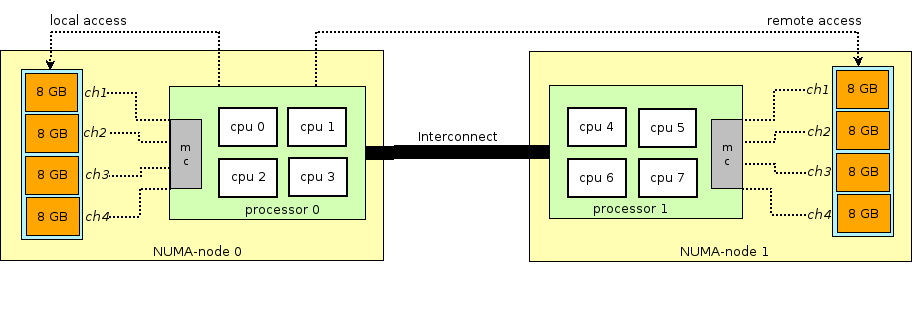
Sebelum melanjutkan kisah RAM di mesin virtual, Anda perlu menyimpang dan menjelaskan istilah NUMA - Non-Uniform Memory Access.
Arsitektur server fisik modern melibatkan kehadiran dua prosesor atau lebih (CPU) dan terkait dengannya memori akses acak (RAM). Seperti sekelompok prosesor + memori disebut node atau node. Komunikasi antara berbagai NUMA node dilakukan melalui bus khusus - QPI (QuickPath Interconnect)
NUMA node lokal dialokasikan - ketika proses yang berjalan di sistem operasi menggunakan prosesor dan RAM yang terletak di NUMA node yang sama, dan NUMA node jarak jauh - ketika proses yang berjalan di sistem operasi menggunakan prosesor dan RAM yang terletak di NUMA node yang berbeda, yaitu, untuk interaksi prosesor dan memori, diperlukan transfer data melalui bus QPI.
Dari sudut pandang mesin virtual, memori sudah dialokasikan untuk itu pada saat peluncurannya, tetapi pada kenyataannya tidak demikian, dan kernel Host OS mengalokasikan bagian memori baru untuk proses QEMU / KVM karena aplikasi di OS Guest meminta memori tambahan (walaupun mungkin juga ada pengecualian jika Anda secara langsung menentukan QEMU / KVM untuk mengalokasikan semua memori ke mesin virtual langsung saat startup).
Memori dialokasikan bukan byte demi byte, tetapi oleh
halaman ukuran tertentu. Ukuran halaman dapat dikonfigurasi dan secara teoritis dapat berupa apa saja, tetapi dalam praktiknya ukurannya adalah 4kB (default), 2MB dan 1GB. Dua ukuran terakhir disebut
HugePages dan sering digunakan untuk mengalokasikan memori untuk mesin virtual intensif memori. Alasan untuk menggunakan HugePages dalam proses menemukan kecocokan antara alamat virtual halaman dan memori fisik dalam
Translation Lookaside Buffer (
TLB ), yang pada gilirannya terbatas dan menyimpan informasi hanya tentang halaman yang terakhir digunakan. Jika tidak ada informasi tentang halaman yang diinginkan di TLB, proses yang disebut
miss TLB terjadi, dan Anda perlu menggunakan prosesor Host OS untuk menemukan sel memori fisik yang sesuai dengan halaman yang diinginkan.
Proses ini tidak efisien dan lambat, sehingga lebih sedikit halaman dengan ukuran yang lebih besar digunakan.
QEMU / KVM juga memungkinkan Anda untuk meniru berbagai topologi NUMA untuk OS Guest, mengambil memori untuk mesin virtual hanya dari NUMA node Host OS tertentu, dan sebagainya. Praktik yang paling umum adalah mengambil memori untuk mesin virtual dari NUMA node lokal ke prosesor yang dialokasikan ke mesin virtual. Alasannya adalah keinginan untuk menghindari beban yang tidak perlu pada bus
QPI yang menghubungkan soket CPU dari server fisik (tentu saja, ini logis jika server Anda memiliki 2 soket atau lebih).
Penyimpanan
Seperti yang Anda ketahui, RAM disebut memori operasional karena isinya menghilang ketika daya dimatikan atau sistem operasi dinyalakan kembali. Untuk menyimpan informasi, Anda memerlukan perangkat penyimpanan persisten (ROM) atau
penyimpanan persisten .
Ada dua jenis penyimpanan persisten:
- Block storage - blok ruang disk yang dapat digunakan untuk menginstal sistem file dan membuat partisi. Jika tidak sopan, maka Anda dapat menganggapnya sebagai disk biasa.
- Penyimpanan objek - informasi hanya dapat disimpan sebagai objek (file), dapat diakses melalui HTTP / HTTPS. Contoh umum penyimpanan objek adalah AWS S3 atau Dropbox.
Mesin virtual membutuhkan
penyimpanan persisten , bagaimana cara melakukan ini jika mesin virtual "hidup" dalam RAM OS host? Singkatnya, setiap panggilan OS tamu ke pengontrol disk virtual dicegat oleh QEMU / KVM dan diubah menjadi catatan pada disk fisik OS host. Metode ini tidak efisien, dan karenanya, di sini, serta untuk perangkat jaringan, driver virtio digunakan alih-alih sepenuhnya meniru perangkat IDE atau iSCSI. Baca lebih lanjut tentang ini di
sini . Dengan demikian, mesin virtual mengakses disk virtualnya melalui driver virtio, dan kemudian QEMU / KVM membuat informasi yang ditransfer ditulis ke disk fisik. Penting untuk dipahami bahwa di OS Host, backend disk dapat diimplementasikan sebagai rak CEPH, NFS, atau iSCSI.
Cara termudah untuk meniru penyimpanan persisten adalah dengan menggunakan file di beberapa direktori Host OS sebagai ruang disk mesin virtual. QEMU / KVM mendukung berbagai format file jenis ini - raw, vdi, vmdk dan lainnya. Namun, format yang paling banyak digunakan adalah
qcow2 (QEMU copy-on-write versi 2). Secara umum, qcow2 adalah file terstruktur dengan cara tertentu tanpa sistem operasi apa pun. Sejumlah besar mesin virtual didistribusikan dalam bentuk qcow2-images (images) dan merupakan salinan dari disk sistem mesin virtual, dikemas dalam format qcow2. Ini memiliki beberapa keuntungan - pengkodean qcow2 memakan banyak ruang lebih sedikit daripada salinan mentah dari byte ke byte disk, QEMU / KVM dapat mengubah ukuran file qcow2, yang berarti dimungkinkan untuk mengubah ukuran disk mesin virtual, enkripsi AES qcow2 juga didukung (Ini masuk akal, karena gambar mesin virtual mungkin mengandung kekayaan intelektual).
Lebih lanjut, ketika mesin virtual dimulai, QEMU / KVM menggunakan file qcow2 sebagai disk sistem (saya menghilangkan proses memuat mesin virtual di sini, meskipun ini juga merupakan tugas yang menarik), dan mesin virtual memiliki kemampuan untuk membaca / menulis data ke file qcow2 melalui virtio pengemudi. Dengan demikian, proses pengambilan gambar dari mesin virtual bekerja, karena kapan saja file qcow2 berisi salinan lengkap dari disk sistem mesin virtual, dan gambar dapat digunakan untuk cadangan, transfer ke host lain, dll.
Secara umum, file qcow2 ini akan didefinisikan dalam OS Guest sebagai perangkat
/ dev / vda , dan OS Guest akan mempartisi ruang disk menjadi partisi dan menginstal sistem file. Demikian pula, file qcow2 berikut yang dihubungkan oleh QEMU / KVM sebagai perangkat
/ dev / vdX dapat digunakan sebagai
penyimpanan blok dalam mesin virtual untuk menyimpan informasi (ini persis seperti komponen Openstack Cinder bekerja).
Jaringan
Terakhir di daftar sumber daya virtual kami adalah kartu jaringan dan perangkat I / O. Mesin virtual, seperti host fisik, membutuhkan
bus PCI / PCIe untuk menghubungkan perangkat I / O. QEMU / KVM mampu mengemulasi berbagai jenis chipset - q35 atau i440fx (yang pertama mendukung PCIe, yang kedua mendukung legacy PCI), serta berbagai topologi PCI, misalnya, membuat bus PCI yang terpisah (bus PCI expander) untuk NUMA node Guest OS.
Setelah membuat bus PCI / PCIe, Anda harus menghubungkan perangkat I / O ke sana. Secara umum, dapat berupa apa saja dari kartu jaringan hingga GPU fisik. Dan, tentu saja, kartu jaringan, baik sepenuhnya tervirtualisasi (sepenuhnya antarmuka virtual e1000, misalnya), dan para-tervirtualisasi (virtio, misalnya) atau NIC fisik. Opsi terakhir digunakan untuk mesin virtual data-plane di mana Anda perlu mendapatkan tarif paket tingkat garis - router, firewall, dll.
Ada dua pendekatan utama di sini -
PCI passthrough dan
SR-IOV . Perbedaan utama di antara mereka adalah bahwa untuk PCI-PT, driver hanya digunakan di dalam OS Guest, dan untuk SRIOV, driver OS Host (untuk membuat
VF - Fungsi Virtual ) dan driver OS Guest digunakan untuk mengontrol SR-IOV VF.
Juniper menulis detail yang sangat baik tentang PCI-PT dan SRIOV.

Untuk klarifikasi, perlu dicatat bahwa PCI passthrough dan SR-IOV adalah teknologi yang saling melengkapi. SR-IOV mengiris fungsi fisik menjadi fungsi virtual. Ini dilakukan pada level OS host. Pada saat yang sama, Host OS melihat fungsi virtual sebagai perangkat PCI / PCIe lainnya. Apa yang dia lakukan selanjutnya dengan mereka tidak penting.
Dan PCI-PT adalah mekanisme untuk meneruskan perangkat PCI OS Host di OS Guest, termasuk fungsi virtual yang dibuat oleh perangkat SR-IOV
Jadi, kami memeriksa jenis utama sumber daya virtual dan langkah selanjutnya adalah memahami bagaimana mesin virtual berkomunikasi dengan dunia luar melalui jaringan.
Peralihan virtual
Jika ada mesin virtual, dan ada antarmuka virtual di dalamnya, maka, jelas, muncul masalah mentransfer paket dari satu VM ke yang lain. Dalam hypervisor berbasis Linux (KVM, misalnya), masalah ini dapat diselesaikan menggunakan jembatan Linux, namun, proyek
Open vSwitch (OVS) telah mendapatkan penerimaan luas.
Ada beberapa fungsi inti yang memungkinkan OVS untuk menyebar luas dan menjadi metode packet switching primer yang digunakan dalam banyak platform komputasi awan (seperti Openstack) dan solusi tervirtualisasi.
- Transfer status jaringan - saat memigrasi VM di antara hypervisor, tugas muncul saat mentransfer ACL, QoS, tabel penerusan L2 / L3, dan banyak lagi. Dan OVS dapat melakukannya.
- Implementasi mekanisme transfer paket (datapath) di kedua kernel dan ruang pengguna
- Arsitektur CUPS (Control / User-plane separation) - memungkinkan Anda untuk mentransfer fungsionalitas pemrosesan paket ke chipset khusus (chipset Broadcom dan Marvell, misalnya, dapat melakukan ini), mengendalikannya melalui OVS pesawat kontrol.
- Dukungan untuk metode kontrol lalu lintas jarak jauh - Protokol OpenFlow (hai, SDN).
Arsitektur OVS pada pandangan pertama terlihat cukup menakutkan, tetapi hanya pada pandangan pertama.
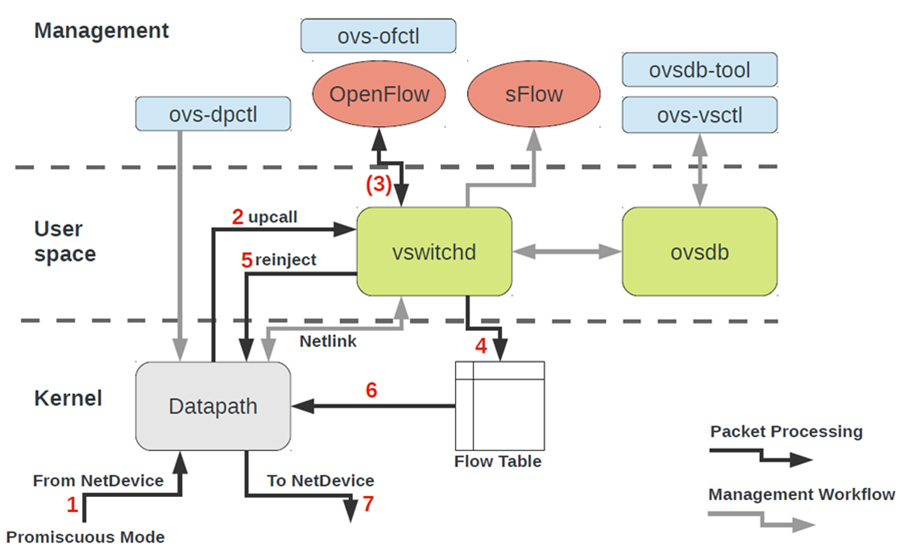
Untuk bekerja dengan OVS, Anda perlu memahami yang berikut:
- Datapath - paket diproses di sini. Analogi ini adalah switch-fabric dari saklar besi. Datapath termasuk menerima paket, header pemrosesan, pencocokan yang cocok di tabel aliran, yang sudah diprogram dalam Datapath. Jika OVS berjalan dalam kernel, itu diimplementasikan sebagai modul kernel. Jika OVS berjalan di ruang pengguna, maka ini adalah proses di ruang pengguna Linux.
- vswitchd dan ovsdb adalah daemon di ruang pengguna, yang secara langsung mengimplementasikan fungsi switch, menyimpan konfigurasi, mengatur aliran ke datapath dan memprogramnya.
- Penyiapan OVS dan memecahkan masalah toolkit - ovs-vsctl, ovs-dpctl, ovs-ofctl, ovs-appctl . Semua yang diperlukan untuk mendaftarkan konfigurasi port di ovsdb, mendaftar aliran mana yang harus dialihkan, mengumpulkan statistik dan sebagainya. Orang baik menulis artikel tentang ini.
Bagaimana perangkat jaringan mesin virtual berakhir di OVS?Untuk mengatasi masalah ini, kita perlu entah bagaimana menghubungkan antarmuka virtual yang terletak di ruang pengguna sistem operasi dengan OVS datapath yang terletak di kernel.
Dalam sistem operasi Linux, paket ditransfer antara kernel dan proses ruang pengguna melalui dua antarmuka khusus.
Kedua antarmuka menggunakan menulis / membaca paket ke / dari file khusus untuk mentransfer paket dari proses ruang pengguna ke kernel dan sebaliknya - file descriptor (FD) (ini adalah salah satu alasan untuk kinerja switching virtual yang buruk jika datapath OVS di kernel - setiap paket perlu menulis / membaca FD)- TUN (tunnel) - perangkat yang bekerja dalam mode L3 dan memungkinkan Anda untuk menulis / membaca hanya paket IP ke / dari FD.
- TAP (ketuk jaringan) - sama dengan antarmuka tun + dapat melakukan operasi dengan frame Ethernet, mis. bekerja dalam mode L2.
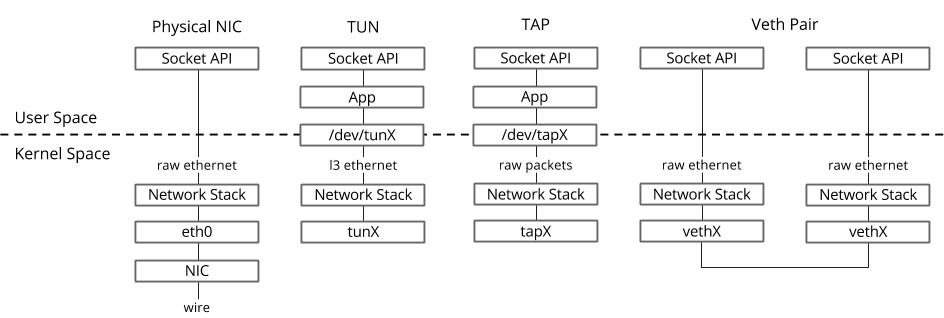 Itulah sebabnya ketika mesin virtual berjalan di Host OS, Anda dapat melihat antarmuka TAP yang dibuat dengan tautan ip atau perintah ifconfig - ini adalah bagian "respons" dari virtio, yang "terlihat" di kernel Host OS. Perlu juga dicatat bahwa antarmuka TAP memiliki alamat MAC yang sama dengan antarmuka virtio di mesin virtual.Antarmuka TAP dapat ditambahkan ke OVS menggunakan perintah ovs-vsctl - maka setiap paket yang diubah oleh OVS ke antarmuka TAP akan ditransfer ke mesin virtual melalui deskriptor file.
Itulah sebabnya ketika mesin virtual berjalan di Host OS, Anda dapat melihat antarmuka TAP yang dibuat dengan tautan ip atau perintah ifconfig - ini adalah bagian "respons" dari virtio, yang "terlihat" di kernel Host OS. Perlu juga dicatat bahwa antarmuka TAP memiliki alamat MAC yang sama dengan antarmuka virtio di mesin virtual.Antarmuka TAP dapat ditambahkan ke OVS menggunakan perintah ovs-vsctl - maka setiap paket yang diubah oleh OVS ke antarmuka TAP akan ditransfer ke mesin virtual melalui deskriptor file.Prosedur sebenarnya untuk membuat mesin virtual mungkin berbeda, mis. Pertama, Anda dapat membuat jembatan OVS, kemudian memberi tahu mesin virtual untuk membuat antarmuka yang terhubung ke OVS ini, atau sebaliknya.
Sekarang, jika kita harus dapat mentransfer paket antara dua atau lebih mesin virtual yang berjalan pada hypervisor yang sama, kita hanya perlu membuat jembatan OVS dan menambahkan antarmuka TAP ke dalamnya menggunakan perintah ovs-vsctl. Tim mana yang dibutuhkan untuk ini mudah dicari di Google.Mungkin ada beberapa jembatan OVS pada hypervisor, misalnya, ini adalah cara kerja Openstack Neutron, atau mesin virtual dapat berada dalam ruang nama yang berbeda untuk mengimplementasikan multi-tenancy.Dan jika mesin virtual berada di jembatan OVS yang berbeda?Untuk mengatasi masalah ini, ada alat lain - pasangan veth. Pasangan Veth dapat direpresentasikan sebagai sepasang antarmuka jaringan yang dihubungkan oleh kabel - semua yang “terbang” menjadi satu antarmuka, “terbang” dari yang lain. Pasangan Veth digunakan untuk menghubungkan beberapa jembatan OVS atau jembatan Linux satu sama lain. Poin penting lainnya adalah bahwa bagian-bagian dari pasangan veth dapat berada dalam namespace Linux OS yang berbeda, yaitu pasangan veth juga dapat digunakan untuk berkomunikasi namespace satu sama lain di tingkat jaringan.Alat virtualisasi - libvirt, virsh dan banyak lagi
Dalam bab-bab sebelumnya kami memeriksa landasan teoritis virtualisasi, dalam bab ini kita akan berbicara tentang alat yang tersedia untuk pengguna secara langsung untuk memulai dan mengubah mesin virtual pada hypervisor KVM.Mari kita bahas tiga komponen utama yang mencakup 90 persen dari semua jenis operasi dengan mesin virtual:- libvirt
- virsh CLI
- virt-install
, CLI-, , , qemu_system_x86_64 virt manager, . Cloud-, Openstack, , libvirt.
libvirt
libvirt adalah proyek open-source skala besar yang mengembangkan seperangkat alat dan driver untuk mengelola hypervisor. Ini mendukung tidak hanya QEMU / KVM, tetapi juga ESXi, LXC dan banyak lagi.Alasan utama popularitasnya adalah antarmuka yang terstruktur dan dapat dipahami untuk berinteraksi melalui satu set file XML, ditambah kemampuan untuk mengotomatisasi melalui API. Perlu dicatat bahwa libvirt tidak menggambarkan semua fungsi yang mungkin dari hypervisor, itu hanya menyediakan antarmuka yang nyaman untuk menggunakan fungsi hypervisor yang berguna , dari sudut pandang peserta proyek.Dan ya, libvirt adalah standar de facto di dunia virtualisasi saat ini. Hanya melihat daftar aplikasi yang menggunakan libvirt. Kabar baiknya tentang libvirt adalah bahwa semua paket yang diperlukan sudah diinstal sebelumnya di semua OS Host yang paling sering digunakan - Ubuntu, CentOS dan RHEL, jadi kemungkinan besar Anda tidak perlu mengkompilasi paket yang diperlukan dan mengkompilasi libvirt. Dalam kasus terburuk, Anda harus menggunakan pemasang batch yang sesuai (apt, yum dan sejenisnya).Setelah instalasi awal dan startup, libvirt membuat Linux bridge virbr0 dan konfigurasi minimalnya secara default.
Kabar baiknya tentang libvirt adalah bahwa semua paket yang diperlukan sudah diinstal sebelumnya di semua OS Host yang paling sering digunakan - Ubuntu, CentOS dan RHEL, jadi kemungkinan besar Anda tidak perlu mengkompilasi paket yang diperlukan dan mengkompilasi libvirt. Dalam kasus terburuk, Anda harus menggunakan pemasang batch yang sesuai (apt, yum dan sejenisnya).Setelah instalasi awal dan startup, libvirt membuat Linux bridge virbr0 dan konfigurasi minimalnya secara default.Itu sebabnya ketika menginstal Ubuntu Server, misalnya, Anda akan melihat di output dari perintah ifconfig Linux bridge virbr0 - ini adalah hasil dari menjalankan daemon libvirtd
Jembatan Linux ini tidak akan terhubung ke antarmuka fisik apa pun, namun, dapat digunakan untuk berkomunikasi mesin virtual dalam satu hypervisor tunggal. Libvirt tentu dapat digunakan bersama dengan OVS, namun, untuk ini, pengguna harus secara independen membuat jembatan OVS menggunakan perintah OVS yang sesuai.Sumber daya virtual apa pun yang diperlukan untuk membuat mesin virtual (komputasi, jaringan, penyimpanan) direpresentasikan sebagai objek di libvirt. Satu set file XML yang berbeda bertanggung jawab untuk proses menggambarkan dan membuat objek-objek ini.Tidak masuk akal untuk menggambarkan proses pembuatan jaringan virtual dan penyimpanan virtual secara terperinci, karena aplikasi ini dijelaskan dengan baik dalam dokumentasi libvirt:Mesin virtual itu sendiri dengan semua perangkat PCI yang terhubung disebut domain dalam terminologi libvirt. Ini juga merupakan objek di dalam libvirt , yang dijelaskan oleh file XML terpisah.File XML ini, sebenarnya, adalah mesin virtual dengan semua sumber daya virtual - RAM, prosesor, perangkat jaringan, disk, dan banyak lagi. Seringkali file XML ini disebut libvirt XML atau dump XML.Tidak mungkin bahwa akan ada orang yang memahami semua parameter libvirt XML, namun, ini tidak diperlukan ketika ada dokumentasi.Secara umum, libvirt XML untuk Ubuntu Desktop Guest OS akan sangat sederhana - 40-50 baris. Karena semua optimasi kinerja juga dijelaskan dalam libvirt XML (topologi NUMA, topologi CPU, pinning CPU, dll.), Untuk fungsi jaringan, libvirt XML bisa sangat kompleks dan berisi beberapa ratus baris. Setiap produsen perangkat jaringan yang mengirimkan perangkat lunak mereka sebagai mesin virtual telah merekomendasikan contoh-contoh XML libvirt.virsh CLI
Utilitas virsh adalah baris perintah "asli" untuk mengelola libvirt. Tujuan utamanya adalah untuk mengelola objek libvirt yang digambarkan sebagai file XML. Contoh khasnya adalah mulai, berhenti, mendefinisikan, menghancurkan, dan sebagainya. Yaitu, siklus hidup objek - manajemen siklus hidup.Deskripsi semua perintah dan flag virsh juga tersedia dalam dokumentasi libvirt .virt-instal
Utilitas lain yang digunakan untuk berinteraksi dengan libvirt. Salah satu keuntungan utama adalah Anda tidak harus berurusan dengan format XML, tetapi bertahan dengan bendera yang tersedia di Inggris. Poin penting kedua adalah lautan contoh dan informasi di Web.Jadi, tidak masalah utilitas apa yang Anda gunakan, pada akhirnya akan menjadi libvirt yang akan mengendalikan hypervisor, sehingga penting untuk memahami arsitektur dan prinsip-prinsip operasinya.
Kesimpulan
Pada artikel ini, kami menguji set minimum pengetahuan teoritis yang diperlukan untuk bekerja dengan mesin virtual. Saya sengaja tidak memberikan contoh dan kesimpulan praktis dari tim, karena contoh seperti itu dapat ditemukan sebanyak yang Anda suka di Web, dan saya tidak menetapkan diri saya tugas untuk menulis "panduan langkah demi langkah". Jika Anda tertarik pada topik atau teknologi tertentu, tinggalkan komentar Anda dan tulis pertanyaan.
Tautan yang bermanfaat
Terima kasih
- Alexander Shalimov , kolega dan pakar saya dalam pengembangan jaringan virtual. Untuk komentar dan pengeditan.
- Yevgeny Yakovlev, kolega dan pakar saya di bidang virtualisasi, untuk komentar dan koreksi.