
Masalah di lingkungan kerja selalu menjadi bencana. Itu terjadi ketika Anda pulang, dan alasannya selalu tampak bodoh. Baru-baru ini, kami kehabisan memori pada node di cluster Kubernetes, meskipun node segera pulih, tanpa gangguan yang terlihat. Hari ini kita akan membahas tentang kasus ini, tentang kerusakan apa yang kita derita dan bagaimana kita bermaksud menghindari masalah yang sama di masa depan.
Kasus satu
Sabtu, 15 Juni 2019 5:12 malam
Blue Matador (ya, kami memantau diri kami sendiri!) Menghasilkan peringatan: acara di salah satu node di cluster produksi Kubernetes - SystemOOM.
17:16
Blue Matador menghasilkan peringatan: EBS Burst Balance rendah dalam volume root node - yang mana acara SystemOOM berlangsung. Meskipun peringatan tentang Burst Balance muncul setelah pemberitahuan tentang SystemOOM, data CloudWatch aktual menunjukkan bahwa Burst Balance telah mencapai level minimum pada 17:02. Alasan keterlambatannya adalah metrik EBS terus-menerus tertinggal 10-15 menit, dan sistem kami tidak menangkap semua peristiwa secara real time.
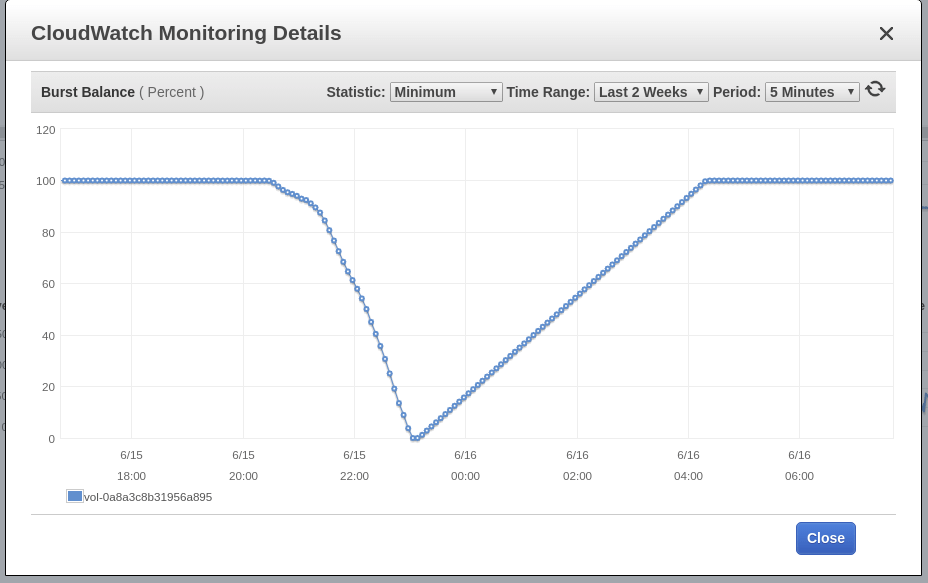
17:18
Saat ini saya melihat peringatan dan peringatan. Saya dengan cepat menjalankan kubectl mendapatkan pod untuk melihat kerusakan apa yang kami alami, dan saya terkejut menemukan bahwa pod dalam aplikasi mati tepat 0. Saya melakukan node top kubectl , tetapi pemeriksaan ini juga menunjukkan bahwa simpul yang dicurigai memiliki masalah memori; Benar, sudah pulih dan menggunakan sekitar 60% dari memorinya. Sekarang jam 5 sore, dan bir kerajinan sudah memanas. Setelah memastikan bahwa node itu operasional dan tidak ada satu pod pun yang rusak, saya memutuskan bahwa telah terjadi kecelakaan. Jika ada, saya akan mencari tahu pada hari Senin.
Ini korespondensi kami dengan stasiun layanan di Slack malam itu:

Kasus dua
Sabtu, 16 Juni 2019 6:02 malam
Blue Matador menghasilkan peringatan: acara sudah ada di node lain, juga SystemOOM. Pasti bahwa stasiun layanan pada saat itu hanya melihat layar smartphone, karena itu menulis kepada saya dan membuat saya segera mengambil acara, saya sendiri tidak dapat menyalakan komputer (apakah sudah waktunya untuk menginstal ulang Windows lagi?). Dan lagi, semuanya tampak normal. Tidak ada satu pod pun yang terbunuh, dan node tersebut hampir tidak mengkonsumsi 70% dari memori.
18:06
Blue Matador menghasilkan peringatan lagi: EBS Burst Balance. Kali kedua dalam sehari, yang artinya saya tidak bisa melepaskan masalah ini saat menginjak rem. Dengan CloudWatch tidak berubah, Burst Balance menyimpang dari norma 2 jam atau lebih sebelum masalah teridentifikasi.
18:11
Saya pergi ke Datalog dan melihat data tentang konsumsi memori. Saya melihat itu tepat sebelum acara SystemOOM, simpul yang dicurigai benar-benar mengambil banyak memori. Jejak mengarah ke polong fluentd-sumologis kami.

Anda dapat dengan jelas melihat penyimpangan tajam dalam konsumsi memori, pada waktu yang hampir bersamaan dengan peristiwa SystemOOM terjadi. Kesimpulan saya: pod-pod inilah yang mengambil semua memori, dan ketika SystemOOM terjadi, Kubernetes menyadari bahwa pod-pod ini dapat dibunuh dan dimulai kembali untuk mengembalikan memori yang diperlukan tanpa mempengaruhi pod saya yang lain. Bagus sekali, Kubernetes!
Jadi mengapa saya tidak melihat ini pada hari Sabtu ketika saya menemukan pod mana yang direstart? Faktanya adalah bahwa saya menjalankan polent fluentd-sumologic di namespace terpisah dan terburu-buru saya hanya tidak berpikir untuk melihatnya.
Kesimpulan 1: Saat mencari pod yang dimulai kembali, periksa semua ruang nama.
Setelah menerima data ini, saya menghitung bahwa pada hari berikutnya memori pada node lain tidak akan berakhir, namun, saya melanjutkan dan me-restart semua pod sumologi sehingga mereka mulai bekerja dengan konsumsi memori yang rendah. Pagi berikutnya, saya berencana untuk menyiapkan cara mengintegrasikan pekerjaan pada masalah ke dalam rencana untuk minggu ini dan tidak memuat terlalu banyak Minggu malam.
23:00
Saya menonton seri "Cermin Hitam" berikutnya (omong-omong, saya suka Miley) dan memutuskan untuk melihat bagaimana kinerja cluster. Konsumsi memori normal, jadi jangan ragu untuk meninggalkan semuanya karena untuk malam.
Perbaiki
Pada hari Senin, saya menyediakan waktu untuk masalah ini. Tidak ada ruginya berburu dengannya setiap malam. Apa yang saya tahu saat ini:
- Wadah-sumologi fluentd melahap satu ton memori;
- Acara SystemOOM diawali oleh aktivitas disk tinggi, tapi saya tidak tahu yang mana.
Awalnya saya berpikir bahwa wadah fluentd-sumologis diterima untuk memakan memori pada saat masuknya kayu gelondongan yang tiba-tiba. Namun, setelah memeriksa Sumologic, saya melihat bahwa log digunakan secara stabil, dan pada saat yang sama ketika ada masalah, tidak ada peningkatan dalam log ini.
Sedikit googling, saya menemukan tugas ini di github , yang menyarankan menyesuaikan beberapa pengaturan Ruby - untuk mengurangi konsumsi memori. Saya memutuskan untuk mencobanya, menambahkan variabel lingkungan ke spesifikasi pod dan menjalankannya:
env: - name: RUBY_GC_HEAP_OLDOBJECT_LIMIT_FACTOR value: "0.9"
Melihat melalui manifes fluentd-sumologic, saya perhatikan bahwa saya tidak mendefinisikan permintaan dan pembatasan sumber daya. Saya mulai curiga bahwa perbaikan RUBY_GCP_HEAP akan melakukan semacam keajaiban, jadi sekarang masuk akal untuk menetapkan batas konsumsi memori. Bahkan jika saya tidak memperbaiki masalah memori, paling tidak akan mungkin membatasi konsumsinya untuk set pod ini. Menggunakan kubectl pod teratas | grep fluentd-sumologic , saya sudah tahu berapa banyak sumber daya untuk diminta:
resources: requests: memory: "128Mi" cpu: "100m" limits: memory: "1024Mi" cpu: "250m"
Kesimpulan 2: Tetapkan batas sumber daya, terutama untuk aplikasi pihak ketiga.
Verifikasi eksekusi
Setelah beberapa hari, saya mengkonfirmasi bahwa metode di atas berfungsi. Konsumsi memori stabil, dan - tidak ada masalah dengan komponen Kubernetes, EC2 dan EBS. Sekarang jelas betapa pentingnya menentukan permintaan dan pembatasan sumber daya untuk semua pod yang saya jalankan, dan inilah yang perlu dilakukan: menerapkan kombinasi batas sumber daya default dan kuota sumber daya .
Misteri yang belum terpecahkan terakhir adalah EBS Burst Balance, yang bertepatan dengan acara SystemOOM. Saya tahu bahwa ketika ada sedikit memori, OS menggunakan ruang swap agar tidak dibiarkan sepenuhnya tanpa memori. Tapi saya belum lahir kemarin dan saya sadar bahwa Kubernetes bahkan tidak akan mulai di server tempat file halaman diaktifkan. Hanya ingin memastikan, saya naik ke node saya melalui SSH - untuk memeriksa apakah file halaman diaktifkan; Saya menggunakan memori bebas dan yang ada di area swap. File tidak diaktifkan.
Dan karena swapping tidak berfungsi, saya memiliki lebih banyak petunjuk tentang apa yang menyebabkan pertumbuhan aliran I / O, itulah mengapa node hampir kehabisan memori, tidak. Sebenarnya, saya punya firasat: pod fluentd-sumologic itu sendiri sedang menulis satu ton pesan log saat ini, bahkan mungkin pesan log yang terkait dengan pengaturan Ruby GC. Ada juga kemungkinan bahwa ada sumber-sumber lain dari Kubernet atau pesan journald yang menjadi sangat produktif ketika ingatannya habis, dan saya menghilangkannya ketika mengatur fluentd. Sayangnya, saya tidak lagi memiliki akses ke file log yang direkam sebelum kerusakan terjadi, dan sekarang tidak ada cara untuk menggali lebih dalam.
Kesimpulan 3: Meskipun ada peluang, gali lebih dalam saat menganalisis akar permasalahan, apa pun masalahnya.
Kesimpulan
Dan meskipun saya tidak sampai ke akar penyebabnya, saya yakin mereka tidak diperlukan untuk mencegah kerusakan yang sama di masa depan. Waktu adalah uang, tetapi saya sudah terlalu lama sibuk, dan setelah itu saya juga menulis posting ini untuk Anda. Dan karena kami menggunakan Blue Matador , kerusakan seperti itu ditangani dengan sangat rinci, jadi saya membiarkan diri saya melepaskan sesuatu pada rem, tanpa terganggu dari proyek utama.