Habr, halo.
Posting ini adalah gambaran singkat dari algoritma pembelajaran mesin umum. Masing-masing disertai dengan deskripsi singkat, panduan, dan tautan yang bermanfaat.
Metode Komponen Utama (PCA) / SVD
Ini adalah salah satu algoritma pembelajaran mesin dasar. Memungkinkan Anda mengurangi dimensi data, kehilangan jumlah informasi paling sedikit. Ini digunakan dalam banyak bidang, seperti pengenalan objek, visi komputer, kompresi data, dll. Penghitungan komponen utama mengurangi untuk menghitung vektor eigen dan nilai eigen dari matriks kovarians dari data sumber atau ke dekomposisi singular dari matriks data.
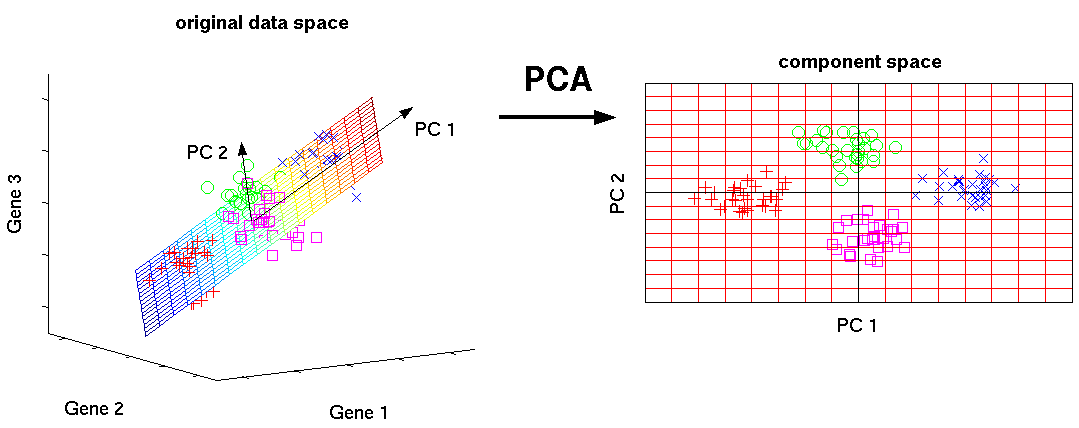
SVD adalah cara menghitung komponen yang dipesan.
Tautan yang bermanfaat:
Panduan Pendahuluan:
Metode kuadrat terkecil
Metode kuadrat terkecil adalah metode matematika yang digunakan untuk memecahkan berbagai masalah, berdasarkan pada meminimalkan jumlah kuadrat dari penyimpangan beberapa fungsi dari variabel yang diinginkan. Ini dapat digunakan untuk "memecahkan" sistem persamaan yang ditentukan secara berlebihan (ketika jumlah persamaan melebihi jumlah yang tidak diketahui), untuk menemukan solusi dalam kasus sistem persamaan nonlinier biasa (tidak didefinisikan ulang), dan juga untuk memperkirakan nilai titik fungsi.
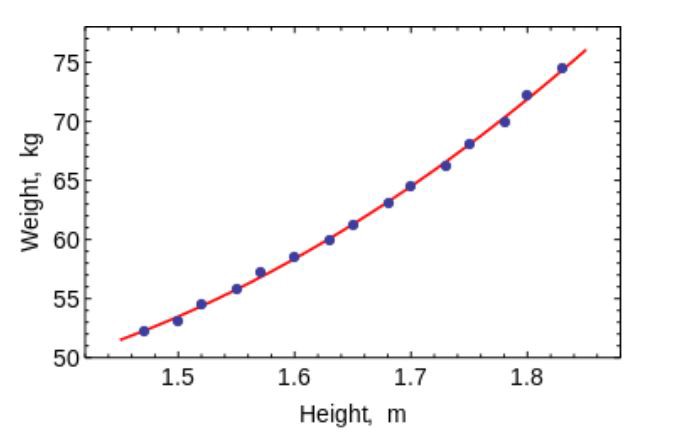
Gunakan algoritma ini untuk menyesuaikan kurva / regresi sederhana.
Tautan yang bermanfaat:
Panduan Pendahuluan:
Regresi linier terbatas
Metode kuadrat terkecil dapat membingungkan outliers, bidang salah, dll. Kendala diperlukan untuk mengurangi varians dari garis yang kita masukkan ke dalam kumpulan data. Solusi yang tepat adalah menyesuaikan model regresi linier yang memastikan bahwa bobot tidak berperilaku "buruk". Model dapat memiliki norma L1 (LASSO) atau L2 (Ridge Regression) atau keduanya (regresi elastis).
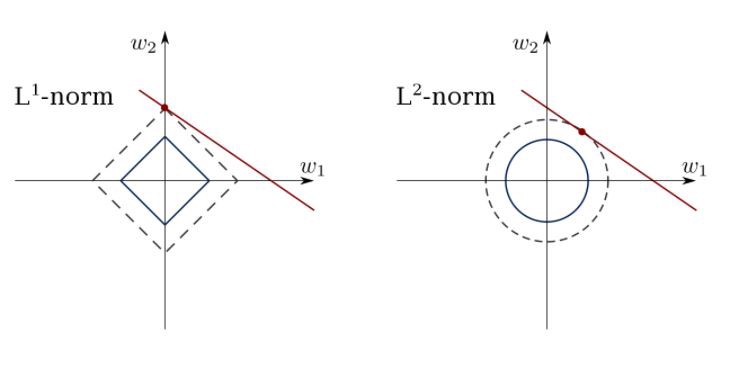
Gunakan algoritma ini untuk mencocokkan garis regresi terbatas, menghindari pengesampingan.
Tautan yang berguna:
Panduan Pendahuluan:
Metode K-means
Algoritma pengelompokan tidak terkontrol favorit semua orang. Diberi dataset dalam bentuk vektor, kita bisa membuat kelompok titik berdasarkan jarak di antara mereka. Ini adalah salah satu algoritma pembelajaran mesin yang secara berurutan menggerakkan pusat-pusat cluster dan kemudian mengelompokkan poin dengan masing-masing pusat cluster. Input adalah jumlah cluster yang akan dibuat dan jumlah iterasi.
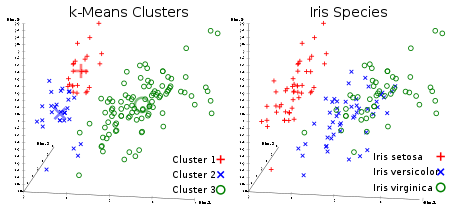
Tautan yang berguna:
Panduan Pendahuluan:
Regresi Logistik
Regresi logistik dibatasi oleh regresi linier dengan non-linearitas (terutama menggunakan fungsi sigmoid atau tanh) setelah menerapkan bobot, oleh karena itu, batasan output dekat dengan kelas +/- (yaitu 1 dan 0 dalam kasus sigmoid). Fungsi kehilangan lintas-entropi dioptimalkan menggunakan metode gradient descent.
Catatan untuk pemula: regresi logistik digunakan untuk klasifikasi, bukan regresi. Secara umum, ini mirip dengan jaringan saraf single-layer. Terlatih menggunakan teknik optimasi seperti gradient descent atau L-BFGS. Pengembang NLP sering menggunakannya, menyebutnya "klasifikasi entropi maksimum".

Gunakan LR untuk melatih pengklasifikasi sederhana namun sangat "kuat".
Tautan yang berguna:
Panduan Pendahuluan:
SVM (Metode Vektor Dukungan)
SVM adalah model linier seperti regresi linier / logistik. Perbedaannya adalah bahwa ia memiliki fungsi kerugian berbasis margin. Anda dapat mengoptimalkan fungsi kerugian menggunakan metode optimisasi seperti L-BFGS atau SGD.

Satu hal unik yang dapat dilakukan SVM adalah mempelajari pengklasifikasi kelas.
SVM dapat digunakan untuk melatih pengklasifikasi (bahkan regressor).
Tautan yang berguna:
Panduan Pendahuluan:
Jaringan saraf distribusi langsung
Pada dasarnya, ini adalah klasifikasi multilevel dari regresi logistik. Banyak lapisan bobot dipisahkan oleh non-linearitas (sigmoid, tanh, relu + softmax dan cool new selu). Mereka juga disebut multilayer perceptrons. FFNN dapat digunakan untuk klasifikasi dan “pelatihan tanpa guru” sebagai auto-encoders.

FFNN dapat digunakan untuk melatih classifier atau mengekstrak fungsi sebagai auto-encoders.
Tautan yang bermanfaat:
Panduan Pendahuluan:
Jaringan saraf convolutional
Hampir semua prestasi modern di bidang pembelajaran mesin dicapai menggunakan jaringan saraf convolutional. Mereka digunakan untuk mengklasifikasikan gambar, mendeteksi objek, atau bahkan mengelompokkan gambar. Diciptakan oleh Jan Lekun di awal tahun 90-an, jaringan memiliki lapisan konvolusional yang bertindak sebagai pengekstraksi objek secara hierarkis. Anda dapat menggunakannya untuk bekerja dengan teks (dan bahkan untuk bekerja dengan gambar).
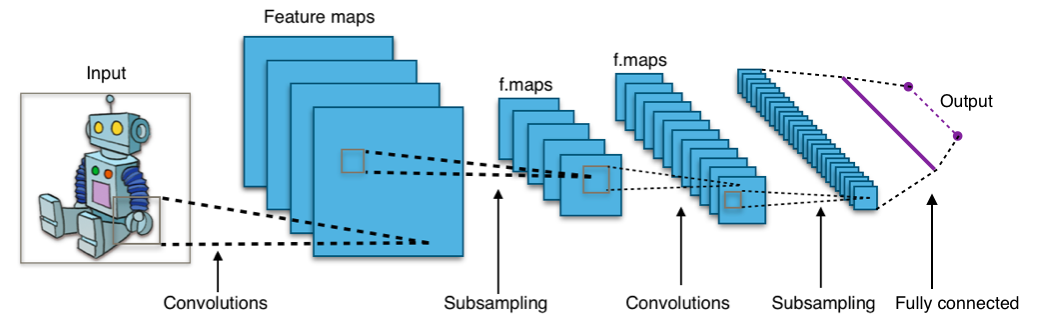
Tautan yang bermanfaat:
Panduan Pendahuluan:
Jaringan Syaraf Berulang (RNNs)
Urutan model RNNs dengan menerapkan set bobot yang sama secara rekursif ke keadaan agregator pada waktu t dan input pada waktu t. RNN murni jarang digunakan sekarang, tetapi rekan-rekannya, seperti LSTM dan GRU, adalah yang paling canggih dalam kebanyakan tugas pemodelan urutan. LSTM, yang digunakan sebagai pengganti lapisan padat sederhana di RNN murni.

Gunakan RNN untuk tugas klasifikasi teks, terjemahan mesin, pemodelan bahasa.
Tautan yang bermanfaat:
Panduan Pendahuluan:
Conditional Random Fields (CRFs)
Mereka digunakan untuk pemodelan urutan, seperti RNNs, dan dapat digunakan dalam kombinasi dengan RNNs. Mereka juga dapat digunakan dalam tugas peramalan terstruktur lainnya, misalnya, dalam segmentasi gambar. CRF memodelkan setiap elemen dari urutan (katakanlah, kalimat), sehingga tetangga mempengaruhi label komponen dalam urutan, dan tidak semua label yang independen satu sama lain.
Gunakan CRF untuk menghubungkan urutan (dalam teks, gambar, seri waktu, DNA, dll.).
Tautan yang berguna:
Panduan Pendahuluan:
Pohon Keputusan dan Hutan Acak
Salah satu algoritma pembelajaran mesin yang paling umum. Digunakan dalam statistik dan analisis data untuk model perkiraan. Strukturnya adalah "daun" dan "cabang". Atribut yang menjadi tujuan fungsi obyektif dicatat pada "cabang" dari pohon keputusan, nilai-nilai fungsi obyektif ditulis dalam "daun", dan atribut yang membedakan kasus dicatat dalam node yang tersisa.
Untuk mengklasifikasikan kasus baru, Anda harus turun pohon ke daun dan mengeluarkan nilai yang sesuai. Tujuannya adalah untuk membuat model yang memprediksi nilai variabel target berdasarkan beberapa variabel input.
Tautan yang bermanfaat:
Panduan Pendahuluan:
Anda akan mempelajari lebih banyak informasi tentang pembelajaran mesin dan Ilmu Data dengan berlangganan ke akun saya di
Habré dan saluran Telegram
Neuron . Jangan lewatkan artikel mendatang.
Semua pengetahuan!