Selama hampir satu tahun sekarang saya telah menggunakan layanan Musik Yandex dan semuanya cocok untuk saya. Tetapi ada satu halaman yang menarik dalam layanan ini - sejarah. Ini menyimpan semua trek yang telah didengarkan dalam urutan kronologis. Dan tentu saja, saya ingin mengunduhnya dan menganalisis apa yang saya dengar di sana sepanjang waktu.

Upaya pertama
Mulai berurusan dengan halaman ini, saya langsung mengalami masalah. Layanan ini tidak mengunduh semua trek sekaligus, tetapi hanya saat Anda menggulir. Saya tidak ingin mengunduh sniffer dan memahami lalu lintas, dan saya tidak memiliki keahlian dalam hal ini pada saat itu. Karena itu, saya memutuskan untuk bertindak lebih sederhana dengan meniru browser menggunakan selenium.
Naskah ditulis. Tetapi dia bekerja sangat tidak stabil dan untuk waktu yang lama. Tapi dia berhasil memuat cerita. Setelah analisis sederhana, saya meninggalkan script tanpa modifikasi, sampai setelah beberapa waktu saya tidak mau lagi mengunduh cerita. Berharap yang terbaik, saya meluncurkannya. Dan, tentu saja, dia memberikan kesalahan. Kemudian saya menyadari bahwa sudah waktunya untuk melakukan semuanya secara manusiawi.
Opsi kerja
Untuk analisis lalu lintas, saya memilih Fiddler untuk diri saya sendiri karena antarmuka yang lebih kuat untuk lalu lintas http, tidak seperti wireshark. Menjalankan sniffer, saya berharap melihat permintaan api dengan token. Tapi tidak. Tujuan kami adalah di music.yandex.ru/handlers/library.jsx . Dan permintaan untuk itu memerlukan otorisasi penuh di situs. Kami akan mulai dengannya.
Login
Tidak ada yang rumit di sini. Kami pergi ke passport.yandex.ru/auth , menemukan parameter untuk permintaan dan membuat dua permintaan untuk otorisasi.
auth_page = self.get('/auth').text csrf_token, process_uuid = self.find_auth_data(auth_page) auth_login = self.post( '/registration-validations/auth/multi_step/start', data={'csrf_token': csrf_token, 'process_uuid': process_uuid, 'login': self.login} ).json() auth_password = self.post( '/registration-validations/auth/multi_step/commit_password', data={'csrf_token': csrf_token, 'track_id': auth_login['track_id'], 'password': self.password} ).json()
Jadi kami masuk.
Unduh Riwayat
Selanjutnya kita pergi ke music.yandex.ru/user/<user>/history , di mana kami juga mengambil beberapa parameter yang berguna bagi kami ketika menerima informasi tentang trek. Sekarang kamu bisa mengunduh ceritanya. Kami mendapatkan music.yandex.ru/handlers/library.jsx di music.yandex.ru/handlers/library.jsx dengan parameter {'owner': <user>, 'filter': 'history', 'likeFilter': 'favorite', 'lang': 'ru', 'external-domain': 'music.yandex.ru', 'overembed': 'false', 'ncrnd': '0.9546193023464256'} . Saya tertarik pada parameter ncrnd di sini. Saat membuat permintaan, Yandex selalu memberikan nilai yang berbeda untuk parameter ini, tetapi semuanya berfungsi dengan sama. Kembali kita mendapatkan sejarah dalam bentuk trek id dan informasi rinci tentang sepuluh lagu teratas. Dari informasi trek terperinci, Anda dapat menyimpan banyak data menarik untuk dianalisis nanti. Misalnya, tahun rilis, durasi trek, dan genre. Informasi tentang sisa trek diperoleh dari music.yandex.ru/handlers/track-entries.jsx . Kami menyimpan semua bisnis ini di csv dan lolos analisis.
Analisis
Untuk analisis, kami menggunakan alat standar dalam bentuk panda dan matplotlib.
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv('statistics.csv') df.head(3)
Ubah None python ke NaN dan buang mereka.
df = df.replace('None', pd.np.nan).dropna()
Mari kita mulai dengan yang sederhana. Mari kita lihat waktu yang kita habiskan untuk mendengarkan semua lagu
duration_sec = df['duration_sec'].astype('int64').sum() ss = duration_sec % 60 m = duration_sec // 60 mm = m % 60 h = m // 60 hh = h % 60 f'{h // 24} {hh}:{mm}:{ss}'
'15 15:30:14'
Tetapi di sini Anda dapat berdebat tentang keakuratan angka ini, karena tidak jelas bagian mana dari lagu yang perlu Anda dengarkan, Yandex menambahkannya ke dalam cerita.
Sekarang mari kita lihat distribusi lagu berdasarkan tahun rilis.
plt.rcParams['figure.figsize'] = [15, 5] plt.hist(df['year'].sort_values(), bins=len(df['year'].unique())) plt.xticks(rotation='vertical') plt.show()
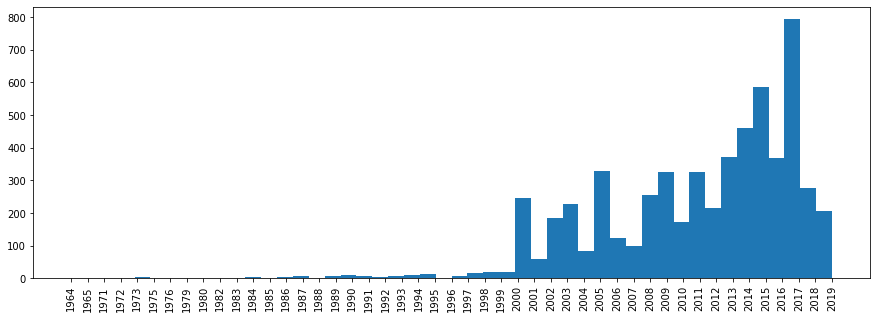
Di sini, hal yang sama tidak begitu sederhana, karena beragam koleksi "Best Hits" akan memiliki tahun kemudian.
Statistik lain akan dibangun berdasarkan prinsip yang sangat mirip. Saya akan memberikan contoh lagu yang paling banyak didengarkan
df.groupby(['track_id', 'artist','track'])['track_id'].count().sort_values(ascending=False).head()
dan trek artis yang paling sering diputar
artist_name = 'Coldplay' df.groupby([ 'artist_id', 'track_id', 'artist', 'track' ])['artist_id'].count().sort_values(ascending=False)[:,:,artist_name].head(5)
Kode lengkap dapat ditemukan di sini.