Kursus lengkap dalam bahasa Rusia dapat ditemukan di tautan ini .
Kursus bahasa Inggris asli tersedia di tautan ini .

Isi
- Wawancara dengan Sebastian Trun
- Pendahuluan
- Model Pembelajaran Transfer
- MobileNet
- CoLab: Kucing Vs Anjing dengan Pelatihan Transfer
- Menyelam ke jaringan saraf convolutional
- Bagian praktis: penentuan warna dengan transfer pelatihan
- Ringkasan
Wawancara dengan Sebastian Trun
- Ini adalah pelajaran 6 dan sepenuhnya didedikasikan untuk mentransfer pembelajaran. Transfer pembelajaran adalah proses menggunakan model yang sudah ada dengan sedikit perbaikan untuk tugas-tugas baru. Pemindahan pelatihan membantu mengurangi waktu pelatihan model dengan memberikan peningkatan efisiensi ketika belajar di awal. Sebastian, apa pendapat Anda tentang transfer pelatihan? Apakah Anda pernah dapat menggunakan metodologi transfer pengajaran dalam pekerjaan dan penelitian Anda?
- Disertasi saya dikhususkan hanya untuk topik transfer pelatihan dan disebut " Penjelasan atas dasar transfer pelatihan ." Ketika kami mengerjakan disertasi, idenya adalah memungkinkan untuk mengajar membedakan semua objek lain dari jenis ini pada satu objek (kumpulan data, entitas) dalam berbagai variasi dan format. Dalam karya ini, kami menggunakan algoritma yang dikembangkan, yang membedakan karakteristik utama (atribut) dari objek dan dapat membandingkannya dengan objek lain. Perpustakaan seperti Tensorflow sudah dilengkapi dengan model pra-terlatih.
- Ya, di Tensorflow kami memiliki satu set lengkap model pra-terlatih yang dapat Anda gunakan untuk memecahkan masalah praktis. Kita akan membicarakan set yang sudah jadi sedikit nanti.
- Ya, ya! Jika Anda memikirkannya, orang akan terlibat dalam transfer pelatihan sepanjang waktu sepanjang hidup mereka.
- Bisakah kita mengatakan bahwa berkat metode transfer pelatihan, siswa baru kita di beberapa titik tidak akan perlu tahu sesuatu tentang pembelajaran mesin karena itu akan cukup untuk menghubungkan model yang sudah disiapkan dan menggunakannya?
- Pemrograman adalah menulis baris demi baris, kami memberikan perintah ke komputer. Tujuan kami adalah untuk memastikan bahwa semua orang di planet ini mampu dan dapat memprogram dengan menyediakan komputer dengan hanya contoh data input. Setuju, jika Anda ingin mengajarkan komputer untuk membedakan kucing dari anjing, maka menemukan 100 ribu gambar kucing yang berbeda dan 100 ribu gambar anjing yang berbeda cukup sulit, dan berkat transfer pelatihan Anda dapat menyelesaikan masalah ini dalam beberapa baris.
- Ya itu benar! Terima kasih atas jawabannya dan mari kita lanjut belajar.
Pendahuluan
- Halo dan selamat datang kembali!
- Terakhir kali kami melatih jaringan saraf convolutional untuk mengklasifikasikan kucing dan anjing dalam gambar. Jaringan saraf pertama kami dilatih ulang, sehingga hasilnya tidak terlalu tinggi - sekitar 70% akurasi. Setelah itu, kami menerapkan ekstensi dan putus data (pemutusan neuron yang sewenang-wenang), yang memungkinkan kami meningkatkan akurasi prediksi hingga 80%.
- Terlepas dari kenyataan bahwa 80% mungkin tampak seperti indikator yang sangat baik, kesalahan 20% masih terlalu besar. Benar? Apa yang bisa kita lakukan untuk meningkatkan akurasi klasifikasi? Dalam pelajaran ini, kita akan menggunakan teknik transfer pengetahuan (transfer of the knowledge model), yang akan memungkinkan kita untuk menggunakan model yang dikembangkan oleh para ahli dan dilatih tentang kumpulan data yang sangat besar. Seperti yang akan kita lihat dalam praktik, dengan mentransfer model pengetahuan kita dapat mencapai akurasi klasifikasi 95%. Ayo mulai!
Transfer Model Pembelajaran
Pada 2012, jaringan saraf AlexNet merevolusi dunia pembelajaran mesin dan mempopulerkan penggunaan jaringan saraf konvolusional untuk klasifikasi dengan memenangkan tantangan pengakuan Visual Skala Besar ImageNet.
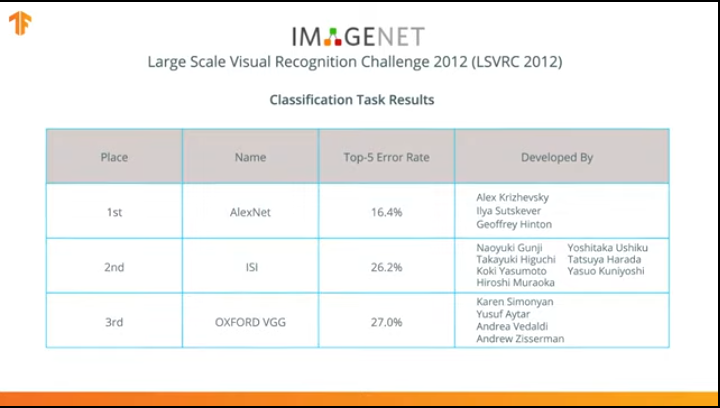
Setelah itu, perjuangan mulai mengembangkan jaringan saraf yang lebih akurat dan efisien yang dapat melampaui AlexNet dalam tugas mengklasifikasikan gambar dari dataset ImageNet.
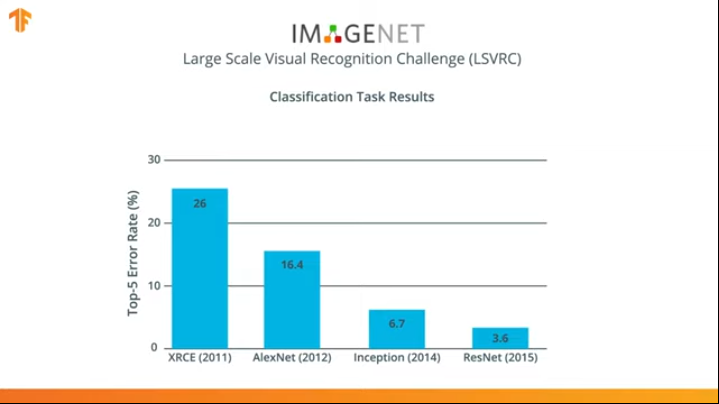
Selama beberapa tahun, jaringan saraf telah dikembangkan yang mengatasi tugas klasifikasi lebih baik daripada AlexNet - Inception dan ResNet.
Setuju bahwa akan lebih baik untuk bisa memanfaatkan jaringan saraf yang sudah dilatih tentang kumpulan data besar dari ImageNet dan menggunakannya dalam klasifikasi kucing dan anjing Anda?
Ternyata kita bisa melakukannya! Teknik ini disebut transfer learning. Gagasan utama metode mentransfer model pelatihan didasarkan pada fakta bahwa setelah melatih jaringan saraf pada set data yang besar, kita dapat menerapkan model yang diperoleh ke set data yang model ini belum temui. Itulah sebabnya teknik ini disebut transfer learning - mentransfer proses belajar dari satu set data ke yang lain.
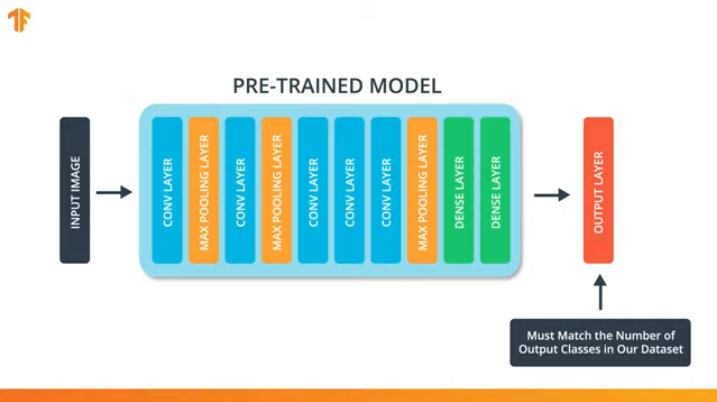
Agar kita dapat menerapkan metodologi mentransfer model pelatihan, kita perlu mengubah lapisan terakhir dari jaringan saraf convolutional kami:
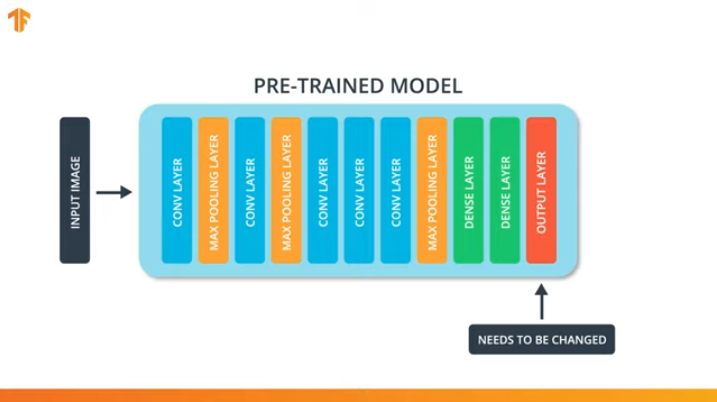
Kami melakukan operasi ini karena setiap set data terdiri dari sejumlah kelas output yang berbeda. Misalnya, kumpulan data di ImageNet berisi 1000 kelas output yang berbeda. FashionMNIST berisi 10 kelas. Kumpulan data klasifikasi kami hanya terdiri dari 2 kelas - kucing dan anjing.
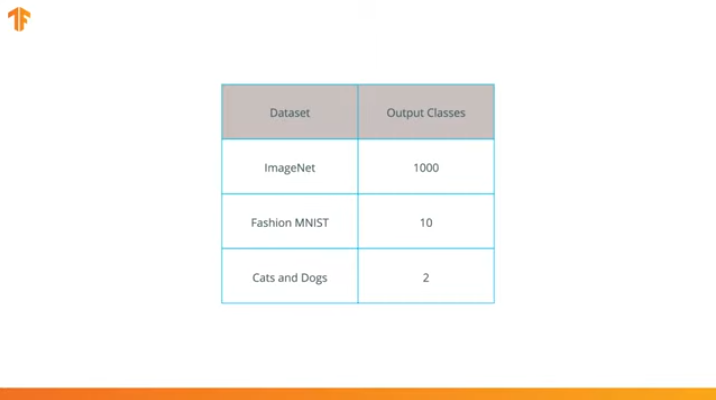
Itu sebabnya perlu untuk mengubah lapisan terakhir dari jaringan saraf convolutional kami sehingga mengandung jumlah output yang akan sesuai dengan jumlah kelas di set baru.
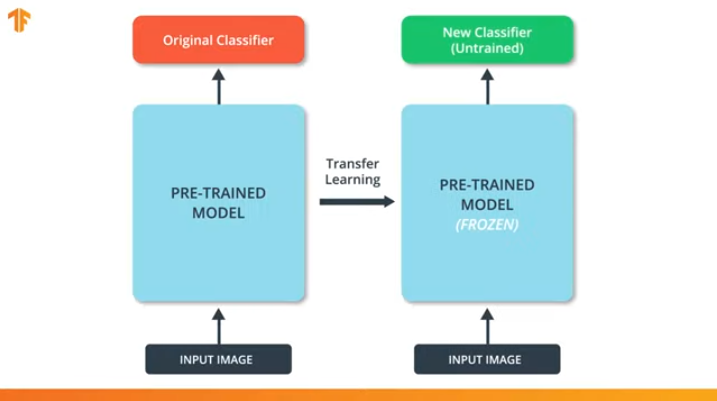
Kita juga perlu memastikan bahwa kita tidak mengubah model pra-terlatih selama proses pelatihan. Solusinya adalah mematikan variabel model pra-terlatih - kami hanya melarang algoritma memperbarui nilai selama propagasi maju dan mundur untuk mengubahnya.
Proses ini disebut "pembekuan model".
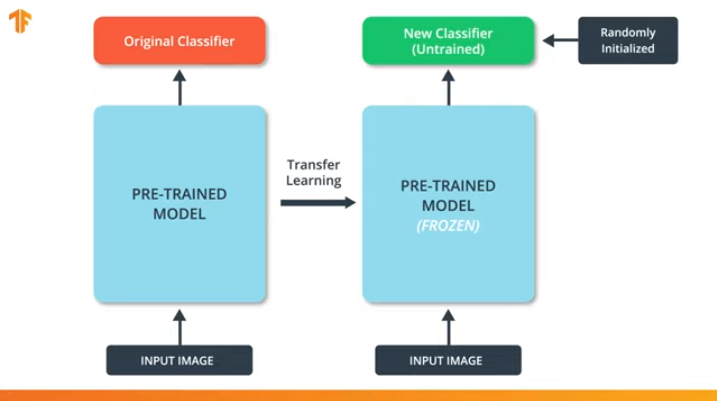
Dengan "membekukan" parameter model pra-terlatih, kami memungkinkan kami untuk hanya mempelajari lapisan terakhir dari jaringan klasifikasi, nilai-nilai variabel dari model pra-terlatih tetap tidak berubah.
Keuntungan lain yang tak terbantahkan dari model pra-terlatih adalah kami mengurangi waktu pelatihan dengan hanya melatih lapisan terakhir dengan jumlah variabel yang jauh lebih kecil, dan bukan keseluruhan model.
Jika kita tidak "membekukan" variabel model pra-terlatih, maka selama proses pelatihan, nilai-nilai variabel akan berubah pada set data baru. Ini karena nilai-nilai variabel pada lapisan terakhir dari klasifikasi akan diisi dengan nilai acak. Karena nilai acak pada lapisan terakhir, model kami akan membuat kesalahan besar dalam klasifikasi, yang, pada gilirannya, akan memerlukan perubahan kuat pada bobot awal dalam model pra-terlatih, yang sangat tidak diinginkan bagi kami.
Karena alasan inilah kita harus selalu ingat bahwa ketika menggunakan model yang ada, nilai-nilai variabel harus "beku" dan kebutuhan untuk melatih model pra-terlatih harus dimatikan.
Sekarang kita tahu bagaimana transfer model pelatihan bekerja, kita hanya harus memilih jaringan saraf pra-terlatih untuk digunakan dalam pengklasifikasi kita sendiri! Ini akan kita lakukan di bagian selanjutnya.
MobileNet
Seperti yang kami sebutkan sebelumnya, jaringan saraf yang sangat efisien dikembangkan yang menunjukkan hasil tinggi pada dataset ImageNet - AlexNet, Inception, Resonant. Jaringan saraf ini adalah jaringan yang sangat dalam dan berisi ribuan bahkan jutaan parameter. Sejumlah besar parameter memungkinkan jaringan untuk mempelajari pola yang lebih kompleks dan dengan demikian mencapai peningkatan akurasi klasifikasi. Sejumlah besar parameter pelatihan jaringan saraf mempengaruhi kecepatan belajar, jumlah memori yang diperlukan untuk menyimpan jaringan dan kompleksitas perhitungan.
Dalam pelajaran ini kita akan menggunakan jaringan neural convolutional modern MobileNet. MobileNet adalah arsitektur jaringan saraf convolutional yang efisien yang mengurangi jumlah memori yang digunakan untuk komputasi sambil mempertahankan akurasi prediksi yang tinggi. Itulah sebabnya MobileNet ideal untuk digunakan pada perangkat seluler dengan jumlah terbatas memori dan sumber daya komputasi.
MobileNet dikembangkan oleh Google dan dilatih tentang dataset ImageNet.
Karena MobileNet dilatih dalam 1.000 kelas dari set data ImageNet, MobileNet memiliki 1.000 kelas output, bukan dua yang kita butuhkan - kucing dan anjing.
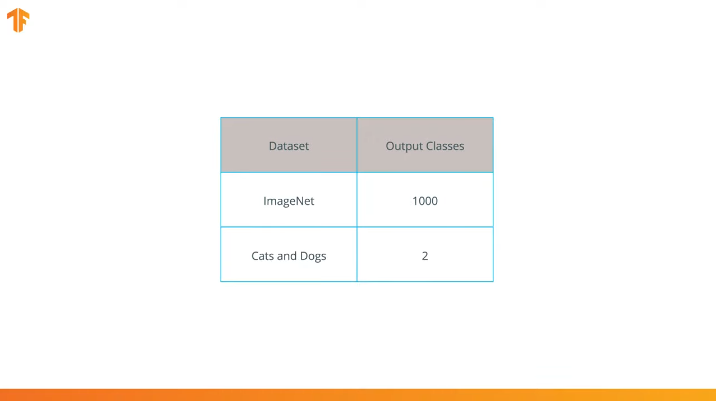
Untuk menyelesaikan transfer pelatihan, kami memuat vektor fitur tanpa lapisan klasifikasi:

Dalam Tensorflow, vektor fitur yang dimuat dapat digunakan sebagai layer Keras biasa dengan data input ukuran tertentu.
Karena MobileNet dilatih pada dataset ImageNet, kita perlu membawa ukuran data input ke yang digunakan dalam proses pelatihan. Dalam kasus kami, MobileNet dilatih tentang gambar RGB ukuran tetap 224x224px.
TensorFlow berisi repositori pra-terlatih yang disebut TensorFlow Hub.
TensorFlow Hub berisi beberapa model pra-terlatih di mana lapisan klasifikasi terakhir dikeluarkan dari arsitektur jaringan saraf untuk digunakan kembali berikutnya.
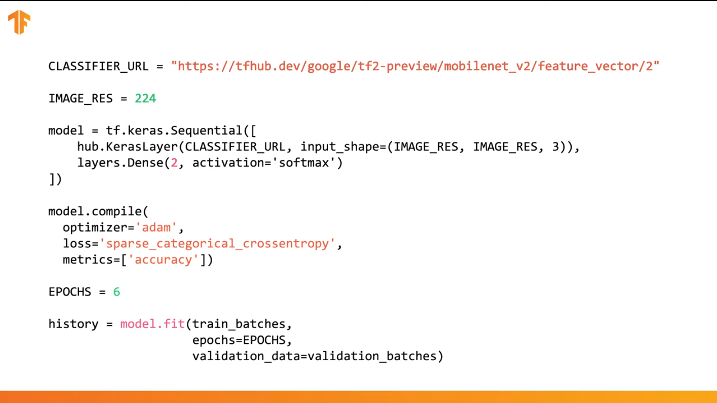
Anda dapat menggunakan TensorFlow Hub dalam kode dalam beberapa baris:

Cukup untuk menentukan URL vektor fitur dari model pelatihan yang diinginkan dan kemudian menanamkan model di classifier kami dengan lapisan terakhir dengan jumlah kelas output yang diinginkan. Ini adalah lapisan terakhir yang akan dikenakan pelatihan dan mengubah nilai parameter. Kompilasi dan pelatihan model baru kami dilakukan dengan cara yang sama seperti yang kami lakukan sebelumnya:
Mari kita lihat bagaimana ini akan bekerja dan menulis kode yang sesuai.
CoLab: Kucing Vs Anjing dengan Pelatihan Transfer
Tautan ke CoLab dalam bahasa Rusia dan CoLab dalam bahasa Inggris .
TensorFlow Hub adalah repositori dengan model pra-terlatih yang dapat kita gunakan.
Transfer pembelajaran adalah proses di mana kami mengambil model pra-terlatih dan mengembangkannya untuk melakukan tugas tertentu. Pada saat yang sama, kami membiarkan bagian dari model pra-pelatihan yang kami integrasikan ke dalam jaringan saraf tidak tersentuh, tetapi hanya melatih lapisan keluaran terakhir untuk mendapatkan hasil yang diinginkan.
Pada bagian praktis ini, kami akan menguji kedua opsi.
Tautan ini memungkinkan Anda menjelajahi seluruh daftar model yang tersedia.
Di bagian Colab ini
- Kami akan menggunakan model TensorFlow Hub untuk prediksi;
- Kami akan menggunakan model-TensorFlow Hub untuk kumpulan data kucing dan anjing;
- Mari mentransfer pelatihan menggunakan model dari TensorFlow Hub.
Sebelum melanjutkan dengan implementasi bagian praktis saat ini, kami menyarankan pengaturan ulang Runtime -> Reset all runtimes...
Impor Perpustakaan
Pada bagian praktis ini, kami akan menggunakan sejumlah fitur perpustakaan TensorFlow yang belum dalam rilis resmi. Itulah sebabnya kami akan menginstal versi TensorFlow dan TensorFlow Hub untuk pengembang.
Menginstal versi dev TensorFlow secara otomatis mengaktifkan versi terinstal terbaru. Setelah kami selesai berurusan dengan bagian praktis ini, kami sarankan mengembalikan pengaturan TensorFlow dan kembali ke versi stabil melalui item menu Runtime -> Reset all runtimes... Menjalankan perintah ini akan mengatur ulang semua pengaturan lingkungan ke yang asli.
!pip install tf-nightly-gpu !pip install "tensorflow_hub==0.4.0" !pip install -U tensorflow_datasets
Kesimpulan:
Requirement already satisfied: absl-py>=0.7.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0) Requirement already satisfied: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.7.1) Requirement already satisfied: google-pasta>=0.1.6 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.1.7) Collecting tf-estimator-nightly (from tf-nightly-gpu) Downloading https://files.pythonhosted.org/packages/ea/72/f092fc631ef2602fd0c296dcc4ef6ef638a6a773cb9fdc6757fecbfffd33/tf_estimator_nightly-1.14.0.dev2019092201-py2.py3-none-any.whl (450kB) |████████████████████████████████| 450kB 45.9MB/s Requirement already satisfied: numpy<2.0,>=1.16.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.16.5) Requirement already satisfied: wrapt>=1.11.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.11.2) Requirement already satisfied: astor>=0.6.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0) Requirement already satisfied: opt-einsum>=2.3.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.0.1) Requirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.33.6) Requirement already satisfied: h5py in /usr/local/lib/python3.6/dist-packages (from keras-applications>=1.0.8->tf-nightly-gpu) (2.8.0) Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (3.1.1) Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (41.2.0) Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (0.15.6) Installing collected packages: tb-nightly, tf-estimator-nightly, tf-nightly-gpu Successfully installed tb-nightly-1.15.0a20190911 tf-estimator-nightly-1.14.0.dev2019092201 tf-nightly-gpu-1.15.0.dev20190821 Collecting tensorflow_hub==0.4.0 Downloading https://files.pythonhosted.org/packages/10/5c/6f3698513cf1cd730a5ea66aec665d213adf9de59b34f362f270e0bd126f/tensorflow_hub-0.4.0-py2.py3-none-any.whl (75kB) |████████████████████████████████| 81kB 5.0MB/s Requirement already satisfied: protobuf>=3.4.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (3.7.1) Requirement already satisfied: numpy>=1.12.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.16.5) Requirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.12.0) Requirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.4.0->tensorflow_hub==0.4.0) (41.2.0) Installing collected packages: tensorflow-hub Found existing installation: tensorflow-hub 0.6.0 Uninstalling tensorflow-hub-0.6.0: Successfully uninstalled tensorflow-hub-0.6.0 Successfully installed tensorflow-hub-0.4.0 Collecting tensorflow_datasets Downloading https://files.pythonhosted.org/packages/6c/34/ff424223ed4331006aaa929efc8360b6459d427063dc59fc7b75d7e4bab3/tensorflow_datasets-1.2.0-py3-none-any.whl (2.3MB) |████████████████████████████████| 2.3MB 4.9MB/s Requirement already satisfied, skipping upgrade: future in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.16.0) Requirement already satisfied, skipping upgrade: wrapt in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.11.2) Requirement already satisfied, skipping upgrade: dill in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.3.0) Requirement already satisfied, skipping upgrade: numpy in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.16.5) Requirement already satisfied, skipping upgrade: requests>=2.19.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.21.0) Requirement already satisfied, skipping upgrade: tqdm in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (4.28.1) Requirement already satisfied, skipping upgrade: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (3.7.1) Requirement already satisfied, skipping upgrade: psutil in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (5.4.8) Requirement already satisfied, skipping upgrade: promise in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.2.1) Requirement already satisfied, skipping upgrade: absl-py in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.8.0) Requirement already satisfied, skipping upgrade: tensorflow-metadata in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.14.0) Requirement already satisfied, skipping upgrade: six in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.12.0) Requirement already satisfied, skipping upgrade: termcolor in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.1.0) Requirement already satisfied, skipping upgrade: attrs in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (19.1.0) Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2.8) Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2019.6.16) Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (3.0.4) Requirement already satisfied, skipping upgrade: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (1.24.3) Requirement already satisfied, skipping upgrade: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.6.1->tensorflow_datasets) (41.2.0) Requirement already satisfied, skipping upgrade: googleapis-common-protos in /usr/local/lib/python3.6/dist-packages (from tensorflow-metadata->tensorflow_datasets) (1.6.0) Installing collected packages: tensorflow-datasets Successfully installed tensorflow-datasets-1.2.0
Kami telah melihat dan menggunakan beberapa impor sebelumnya. Dari yang baru - impor tensorflow_hub , yang kami pasang dan yang akan kami gunakan di bagian praktis ini.
from __future__ import absolute_import, division, print_function, unicode_literals import matplotlib.pylab as plt import tensorflow as tf tf.enable_eager_execution() import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.keras import layers
Kesimpulan:
WARNING:tensorflow: TensorFlow's `tf-nightly` package will soon be updated to TensorFlow 2.0. Please upgrade your code to TensorFlow 2.0: * https://www.tensorflow.org/beta/guide/migration_guide Or install the latest stable TensorFlow 1.X release: * `pip install -U "tensorflow==1.*"` Otherwise your code may be broken by the change.
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
Bagian 1: gunakan TensorFlow Hub MobileNet untuk prediksi
Di bagian CoLab ini, kami akan mengambil model yang sudah dilatih sebelumnya, mengunggahnya ke Keras dan mengujinya.
Model yang kami gunakan adalah MobileNet v2 (bukan MobileNet, model classifier gambar tf2 lain yang kompatibel dengan tfhub.dev dapat digunakan).
Unduh classifier
Unduh model MobileNet dan buat model Keras darinya. MobileNet pada input mengharapkan untuk menerima gambar dengan ukuran 224x224 piksel dengan 3 saluran warna (RGB).
CLASSIFIER_URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/2" IMAGE_RES = 224 model = tf.keras.Sequential([ hub.KerasLayer(CLASSIFIER_URL, input_shape=(IMAGE_RES, IMAGE_RES, 3)) ])
Jalankan classifier pada satu gambar
MobileNet telah dilatih tentang dataset ImageNet. ImageNet berisi 1000 kelas keluaran dan salah satu dari kelas ini adalah seragam militer. Mari kita cari gambar di mana seragam militer akan ditempatkan dan yang tidak akan menjadi bagian dari paket pelatihan ImageNet untuk memverifikasi akurasi klasifikasi.
import numpy as np import PIL.Image as Image grace_hopper = tf.keras.utils.get_file('image.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg') grace_hopper = Image.open(grace_hopper).resize((IMAGE_RES, IMAGE_RES)) grace_hopper
Kesimpulan:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg 65536/61306 [================================] - 0s 0us/step

grace_hopper = np.array(grace_hopper)/255.0 grace_hopper.shape
Kesimpulan:
(224, 224, 3)
Perlu diingat bahwa model selalu menerima set (blok) gambar untuk diproses pada input. Dalam kode di bawah ini, kami menambahkan dimensi baru - ukuran blok.
result = model.predict(grace_hopper[np.newaxis, ...]) result.shape
Kesimpulan:
(1, 1001)
Hasil prediksi adalah vektor dengan ukuran 1,001 elemen, di mana setiap nilai mewakili probabilitas bahwa objek dalam gambar milik kelas tertentu.
Posisi nilai probabilitas maksimum dapat ditemukan menggunakan fungsi argmax . Namun, ada pertanyaan yang masih belum kami jawab - bagaimana kami bisa menentukan kelas mana yang termasuk dalam elemen dengan probabilitas maksimum?
predicted_class = np.argmax(result[0], axis=-1) predicted_class
Kesimpulan:
653
Mengartikan Prediksi
Agar kami dapat menentukan kelas yang terkait dengan prediksi, kami mengunggah daftar tag ImageNet dan dengan indeks dengan kesetiaan maksimum, kami menentukan kelas yang terkait dengan prediksi.
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt') imagenet_labels = np.array(open(labels_path).read().splitlines()) plt.imshow(grace_hopper) plt.axis('off') predicted_class_name = imagenet_labels[predicted_class] _ = plt.title("Prediction: " + predicted_class_name.title())
Kesimpulan:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt 16384/10484 [==============================================] - 0s 0us/step

Bingo! Model kami mengidentifikasi dengan benar seragam militer.
Bagian 2: gunakan model TensorFlow Hub untuk dataset kucing dan anjing
Sekarang kita akan menggunakan versi lengkap model MobileNet dan melihat bagaimana itu akan mengatasi kumpulan data kucing dan anjing.
Dataset
Kita dapat menggunakan Kumpulan Data TensorFlow untuk mengunduh dataset kucing dan anjing.
splits = tfds.Split.ALL.subsplit(weighted=(80, 20)) splits, info = tfds.load('cats_vs_dogs', with_info=True, as_supervised=True, split = splits) (train_examples, validation_examples) = splits num_examples = info.splits['train'].num_examples num_classes = info.features['label'].num_classes
Kesimpulan:
Downloading and preparing dataset cats_vs_dogs (786.68 MiB) to /root/tensorflow_datasets/cats_vs_dogs/2.0.1... /usr/local/lib/python3.6/dist-packages/urllib3/connectionpool.py:847: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) WARNING:absl:1738 images were corrupted and were skipped Dataset cats_vs_dogs downloaded and prepared to /root/tensorflow_datasets/cats_vs_dogs/2.0.1. Subsequent calls will reuse this data.
Tidak semua gambar dalam dataset kucing dan anjing memiliki ukuran yang sama.
for i, example_image in enumerate(train_examples.take(3)): print("Image {} shape: {}".format(i+1, example_image[0].shape))
Kesimpulan:
Image 1 shape: (500, 343, 3) Image 2 shape: (375, 500, 3) Image 3 shape: (375, 500, 3)
Oleh karena itu, gambar dari kumpulan data yang diperoleh memerlukan reduksi ke ukuran tunggal, yang diharapkan oleh model MobileNet pada input - 224 x 224.
Fungsi .repeat() dan steps_per_epoch tidak diperlukan di sini, tetapi mereka memungkinkan Anda untuk menghemat sekitar 15 detik per iterasi pelatihan, karena buffer sementara harus diinisialisasi hanya sekali pada awal proses pembelajaran.
def format_image(image, label): image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES)) / 255.0 return image, label BATCH_SIZE = 32 train_batches = train_examples.shuffle(num_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_examples.map(format_image).batch(BATCH_SIZE).prefetch(1)
Jalankan classifier pada set gambar
Biarkan saya mengingatkan Anda bahwa pada tahap ini, masih ada versi lengkap dari jaringan MobileNet yang sudah dilatih sebelumnya, yang berisi 1.000 kemungkinan kelas keluaran. ImageNet berisi sejumlah besar gambar anjing dan kucing, jadi mari kita coba memasukkan salah satu gambar uji dari kumpulan data kami dan melihat prediksi apa yang akan diberikan oleh model.
image_batch, label_batch = next(iter(train_batches.take(1))) image_batch = image_batch.numpy() label_batch = label_batch.numpy() result_batch = model.predict(image_batch) predicted_class_names = imagenet_labels[np.argmax(result_batch, axis=-1)] predicted_class_names
Kesimpulan:
array(['Persian cat', 'mink', 'Siamese cat', 'tabby', 'Bouvier des Flandres', 'dishwasher', 'Yorkshire terrier', 'tiger cat', 'tabby', 'Egyptian cat', 'Egyptian cat', 'tabby', 'dalmatian', 'Persian cat', 'Border collie', 'Newfoundland', 'tiger cat', 'Siamese cat', 'Persian cat', 'Egyptian cat', 'tabby', 'tiger cat', 'Labrador retriever', 'German shepherd', 'Eskimo dog', 'kelpie', 'mink', 'Norwegian elkhound', 'Labrador retriever', 'Egyptian cat', 'computer keyboard', 'boxer'], dtype='<U30')
Labelnya mirip dengan nama ras kucing dan anjing. Sekarang mari kita menampilkan beberapa gambar dari dataset kucing dan anjing kita dan menempatkan label yang diprediksi pada masing-masing gambar.
plt.figure(figsize=(10, 9)) for n in range(30): plt.subplot(6, 5, n+1) plt.subplots_adjust(hspace=0.3) plt.imshow(image_batch[n]) plt.title(predicted_class_names[n]) plt.axis('off') _ = plt.suptitle("ImageNet predictions")

Bagian 3: Menerapkan Transfer Pembelajaran dengan TensorFlow Hub
Sekarang mari kita gunakan TensorFlow Hub untuk mentransfer pembelajaran dari satu model ke model lainnya.
Dalam proses mentransfer pelatihan, kami menggunakan kembali satu model pra-terlatih dengan mengubah lapisan terakhirnya, atau beberapa lapisan, dan kemudian memulai proses pelatihan lagi pada kumpulan data baru.
Di TensorFlow Hub, Anda dapat menemukan tidak hanya model pra-latih lengkap (dengan lapisan terakhir), tetapi juga model tanpa lapisan klasifikasi terakhir. Yang terakhir dapat dengan mudah digunakan untuk mentransfer pelatihan. Kami akan terus menggunakan MobileNet v2 untuk alasan sederhana bahwa pada bagian selanjutnya dari kursus kami, kami akan mentransfer model ini dan meluncurkannya pada perangkat seluler menggunakan TensorFlow Lite.
Kami juga akan terus menggunakan kumpulan data kucing dan anjing, jadi kami akan memiliki kesempatan untuk membandingkan kinerja model ini dengan yang kami terapkan dari awal.
Perhatikan bahwa kami menyebut model parsial dengan TensorFlow Hub (tanpa lapisan klasifikasi terakhir) feature_extractor . Nama ini dijelaskan oleh fakta bahwa model menerima data sebagai input dan mengubahnya menjadi sekumpulan properti (karakteristik) terbatas. Dengan demikian, model kami melakukan pekerjaan mengidentifikasi isi gambar, tetapi tidak menghasilkan distribusi probabilitas akhir atas kelas output. Model mengekstraksi sekumpulan properti dari gambar.
URL = 'https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/2' feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
Mari kita jalankan serangkaian gambar melalui feature_extractor dan lihat bentuk yang dihasilkan (format output). 32 - jumlah gambar, 1280 - jumlah neuron pada lapisan terakhir model pra-terlatih dengan TensorFlow Hub.
feature_batch = feature_extractor(image_batch) print(feature_batch.shape)
Kesimpulan:
(32, 1280)
Kami "membekukan" variabel dalam lapisan ekstraksi properti sehingga hanya nilai-nilai variabel dari lapisan klasifikasi yang berubah selama proses pelatihan.
feature_extractor.trainable = False
Tambahkan lapisan klasifikasi
Sekarang bungkus layer dari TensorFlow Hub di model tf.keras.Sequential dan tambahkan layer klasifikasi.
model = tf.keras.Sequential([ feature_extractor, layers.Dense(2, activation='softmax') ]) model.summary()
Kesimpulan:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 1280) 2257984 _________________________________________________________________ dense (Dense) (None, 2) 2562 ================================================================= Total params: 2,260,546 Trainable params: 2,562 Non-trainable params: 2,257,984 _________________________________________________________________
Model kereta
Sekarang kita melatih model yang dihasilkan seperti yang kita lakukan sebelum memanggil compile diikuti oleh fit untuk pelatihan.
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'] ) EPOCHS = 6 history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
Kesimpulan:
Epoch 1/6 582/582 [==============================] - 77s 133ms/step - loss: 0.2381 - acc: 0.9346 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 582/582 [==============================] - 70s 120ms/step - loss: 0.1827 - acc: 0.9618 - val_loss: 0.1629 - val_acc: 0.9670 Epoch 3/6 582/582 [==============================] - 69s 119ms/step - loss: 0.1733 - acc: 0.9660 - val_loss: 0.1623 - val_acc: 0.9666 Epoch 4/6 582/582 [==============================] - 69s 118ms/step - loss: 0.1677 - acc: 0.9676 - val_loss: 0.1627 - val_acc: 0.9677 Epoch 5/6 582/582 [==============================] - 68s 118ms/step - loss: 0.1636 - acc: 0.9689 - val_loss: 0.1634 - val_acc: 0.9675 Epoch 6/6 582/582 [==============================] - 69s 118ms/step - loss: 0.1604 - acc: 0.9701 - val_loss: 0.1643 - val_acc: 0.9668
Seperti yang mungkin Anda perhatikan, kami dapat mencapai ~ 97% akurasi prediksi pada set data validasi. Luar biasa! Pendekatan saat ini telah secara signifikan meningkatkan akurasi klasifikasi dibandingkan dengan model pertama yang kami latih sendiri dan memperoleh akurasi klasifikasi ~ 87%. Alasannya adalah bahwa MobileNet dirancang oleh para ahli dan dikembangkan dengan hati-hati dalam jangka waktu yang lama, dan kemudian dilatih pada dataset ImageNet yang sangat besar.
Anda dapat melihat cara membuat MobileNet Anda sendiri di Keras di tautan ini .
Mari kita buat grafik perubahan dalam nilai akurasi dan kehilangan pada set data pelatihan dan validasi.
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.show()
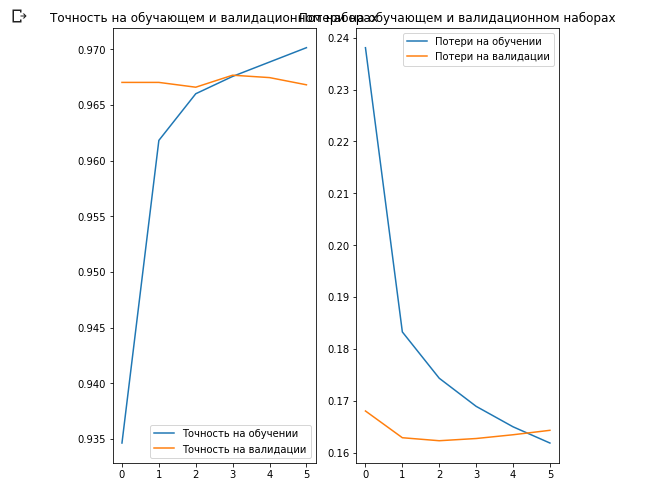
Yang menarik di sini adalah bahwa hasil pada set data validasi lebih baik daripada hasil pada set data pelatihan dari awal hingga akhir proses pembelajaran.
Salah satu alasan perilaku ini adalah bahwa akurasi pada dataset validasi diukur pada akhir iterasi pelatihan, dan akurasi pada dataset pelatihan dianggap sebagai rata-rata semua iterasi pelatihan.
Alasan terbesar untuk perilaku ini adalah penggunaan sub-jaringan MobileNet yang telah dilatih sebelumnya, yang sebelumnya dilatih pada kumpulan data besar kucing dan anjing. Dalam proses pembelajaran, jaringan kami terus memperluas set data pelatihan input (augmentasi yang sama), tetapi bukan set validasi. Ini berarti bahwa gambar yang dihasilkan pada set data pelatihan lebih sulit untuk diklasifikasikan daripada gambar normal dari set data yang divalidasi.
Periksa Hasil Prediksi
Untuk mengulang grafik dari bagian sebelumnya, pertama Anda harus mendapatkan daftar nama kelas yang diurutkan:
class_names = np.array(info.features['label'].names) class_names
Kesimpulan:
array(['cat', 'dog'], dtype='<U3')
Lewati blok dengan gambar melalui model dan konversi indeks yang dihasilkan menjadi nama kelas:
predicted_batch = model.predict(image_batch) predicted_batch = tf.squeeze(predicted_batch).numpy() predicted_ids = np.argmax(predicted_batch, axis=-1) predicted_class_names = class_names[predicted_ids] predicted_class_names
Kesimpulan:
array(['cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'dog', 'dog', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog'], dtype='<U3')
Mari kita lihat label yang sebenarnya dan prediksi:
print(": ", label_batch) print(": ", predicted_ids)
Kesimpulan:
: [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 1 1 0 0 1] : [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 0 1 0 0 1]
plt.figure(figsize=(10, 9)) for n in range(30): plt.subplot(6, 5, n+1) plt.subplots_adjust(hspace=0.3) plt.imshow(image_batch[n]) color = "blue" if predicted_ids[n] == label_batch[n] else "red" plt.title(predicted_class_names[n].title(), color=color) plt.axis('off') _ = plt.suptitle(" (: , : )")

Menyelam ke jaringan saraf convolutional
Menggunakan jaringan saraf convolutional, kami berhasil memastikan bahwa mereka mengatasi dengan baik tugas mengklasifikasikan gambar. Namun, saat ini, kita tidak dapat membayangkan bagaimana mereka benar-benar bekerja. Jika kita dapat memahami bagaimana proses pembelajaran terjadi, maka, pada prinsipnya, kita dapat meningkatkan pekerjaan klasifikasi lebih jauh. Salah satu cara untuk memahami cara kerja jaringan saraf convolutional adalah memvisualisasikan lapisan dan hasil pekerjaan mereka. Kami sangat menyarankan Anda mempelajari bahan-bahan di sini untuk lebih memahami cara memvisualisasikan hasil dari lapisan konvolusional.

Bidang visi komputer melihat cahaya di ujung terowongan dan telah membuat kemajuan yang signifikan sejak munculnya jaringan saraf convolutional. Kecepatan luar biasa yang digunakan dalam penelitian di bidang ini dan sejumlah besar gambar yang dipublikasikan di Internet telah memberikan hasil yang luar biasa selama beberapa tahun terakhir. Munculnya jaringan saraf convolutional dimulai dengan AlexNet pada 2012, yang diciptakan oleh Alex Krizhevsky, Ilya Sutskever dan Jeffrey Hinton dan memenangkan Tantangan Pengenalan Visual Skala Besar ImageNet yang terkenal. Sejak itu, tidak ada keraguan di masa depan yang cerah menggunakan jaringan saraf convolutional, dan bidang visi komputer dan hasil kerja di dalamnya hanya mengkonfirmasi fakta ini. Mulai dari mengenali wajah Anda di ponsel dan berakhir dengan pengenalan objek di mobil otonom, jaringan saraf convolutional telah berhasil menunjukkan dan membuktikan kekuatan mereka dan menyelesaikan banyak masalah dari dunia nyata.
Terlepas dari sejumlah besar kumpulan data besar dan model pra-pelatihan jaringan saraf convolutional, kadang-kadang sangat sulit untuk memahami bagaimana jaringan bekerja dan untuk apa sebenarnya jaringan ini dilatih, terutama bagi orang-orang yang tidak memiliki pengetahuan yang cukup di bidang pembelajaran mesin. , , , Inception, . . , , , , .
" Python"
François Chollet. , . Keras, , " " TensorFlow, MXNET Theano. , , . , .
, , .
(training accuracy) . , , , , Inception, .
, , . Inception v3 ( ImageNet) , Kaggle. Inception, , Inception v3 .
10 () 32 , 2292293. 0.3195, — 0.6377. ImageDataGenerator , . GitHub .
, "" , . .
, Inception v3 , .

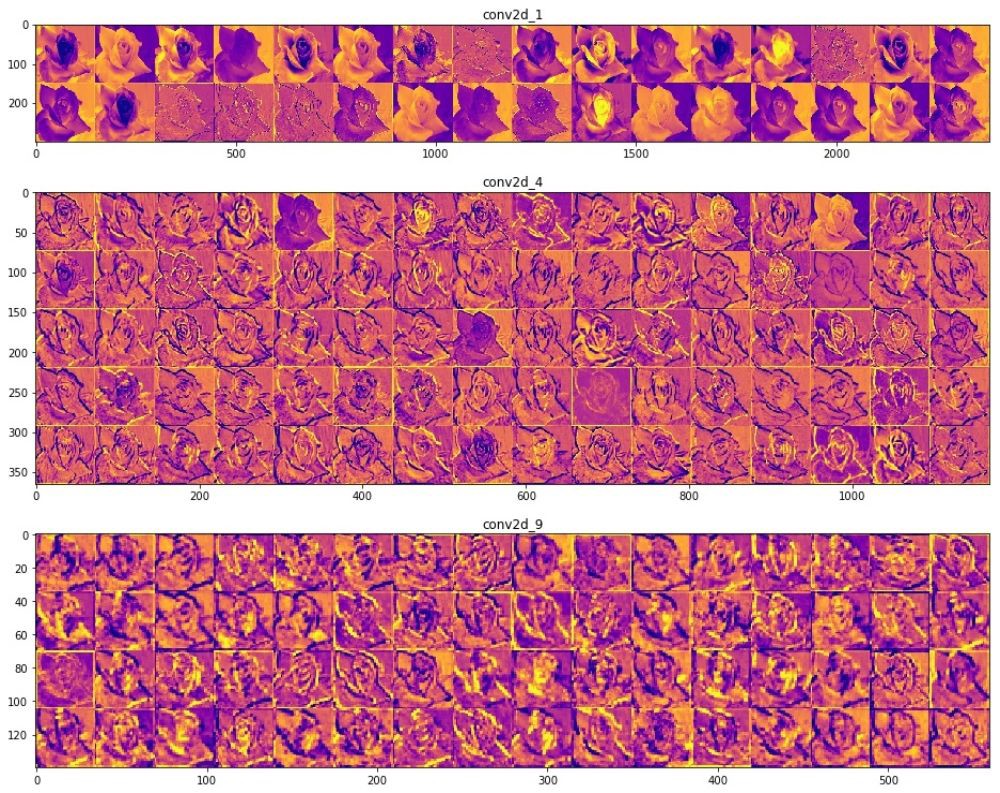
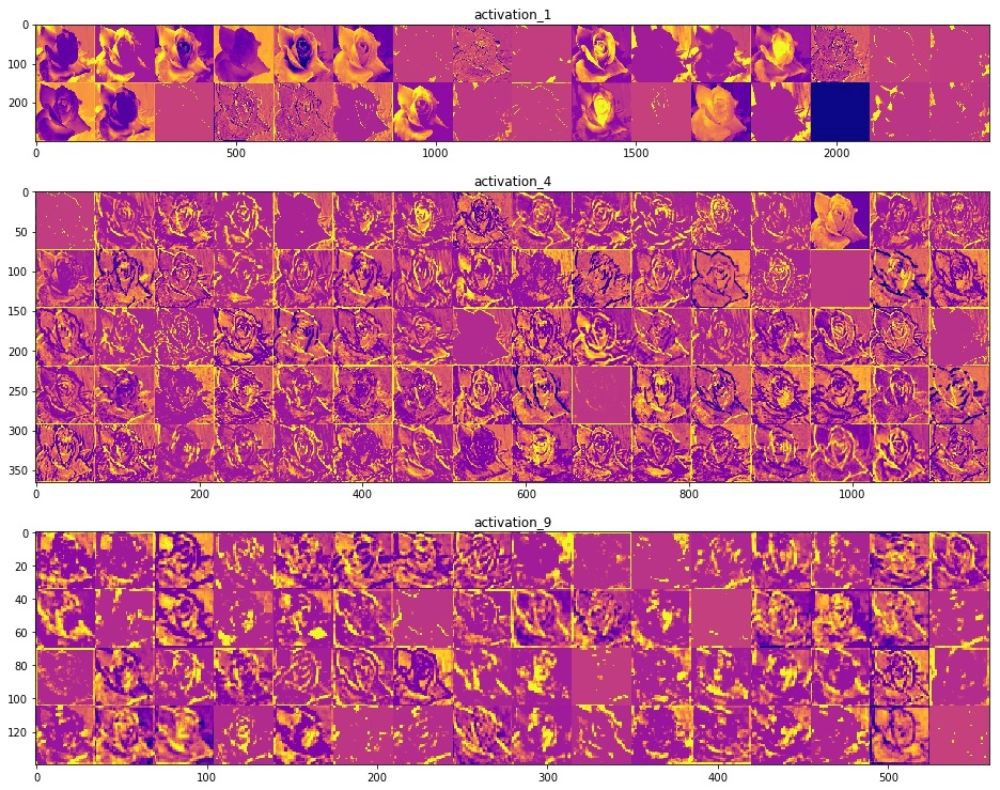
— . .
, () . (), , , , . , , , , .
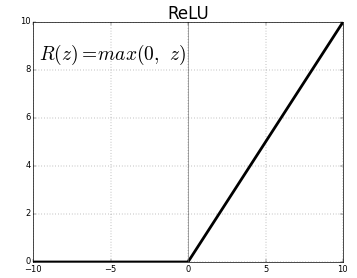
ReLU- . , ReLU(z) = max(0, z) .
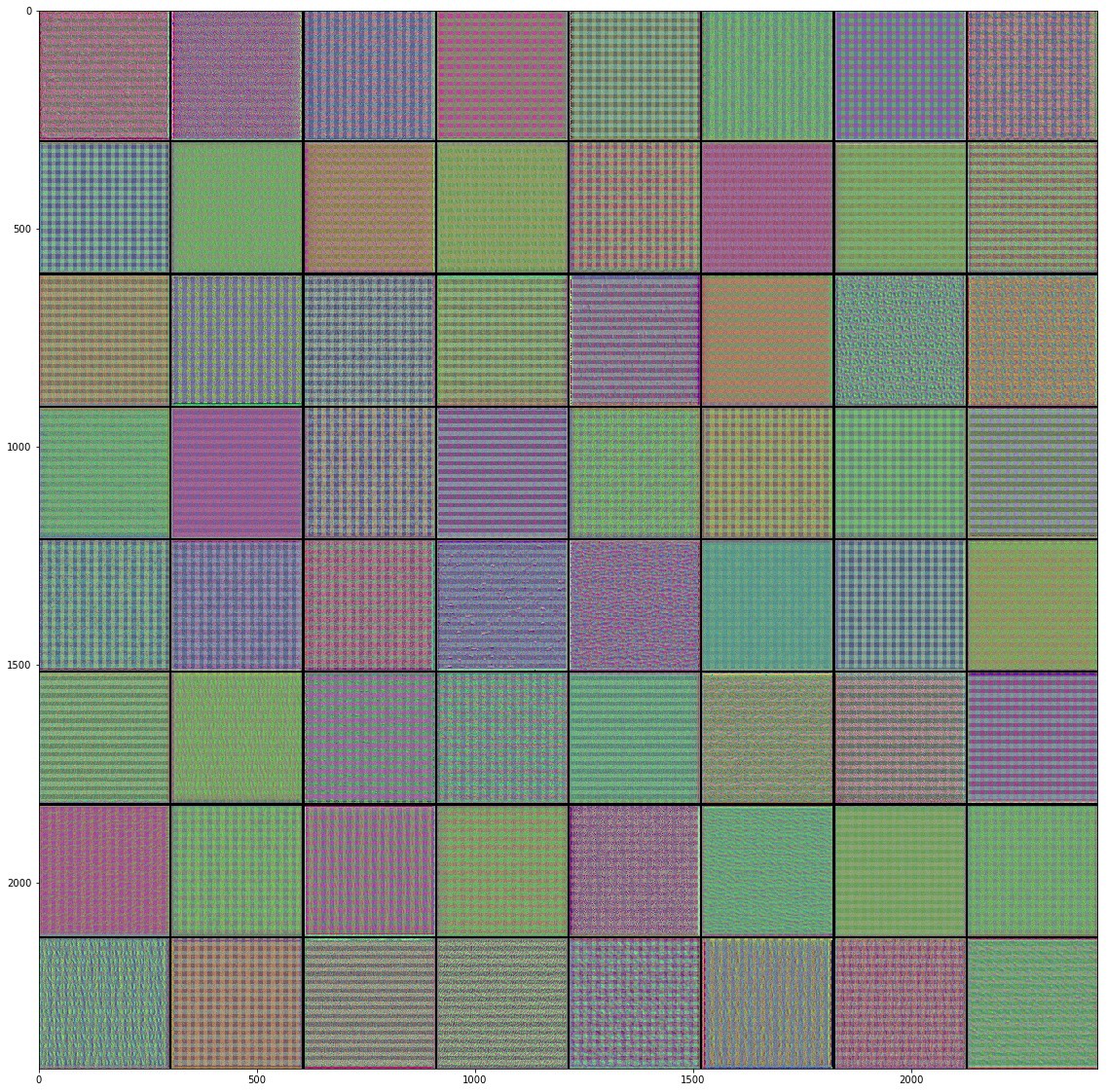
, , , , , , , , .. , . "" () , , , .
"" . .
, Inveption V3 :
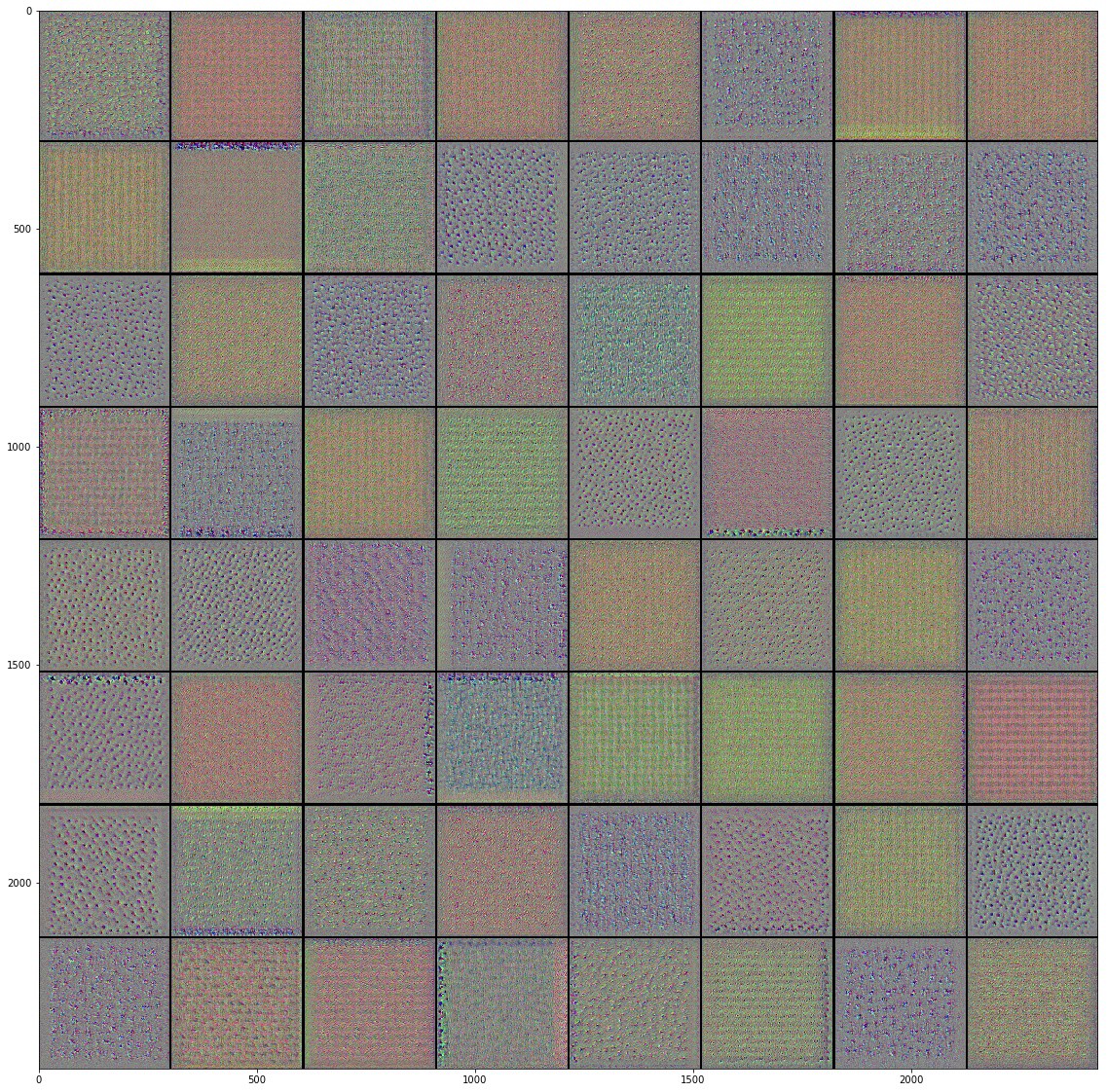

, . , , , , .. , , . , , , "" ( , ).
, , , . , .
Class Activation Map ( ). CAM . 2D , .
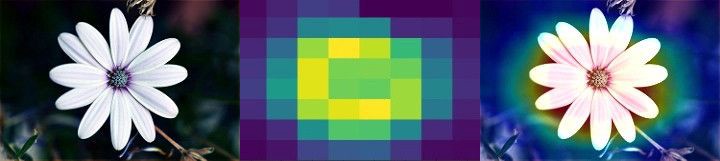

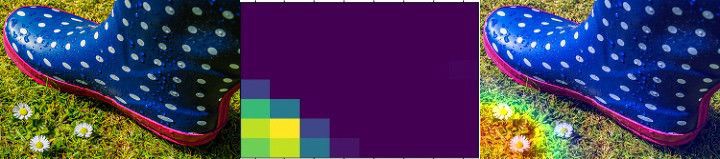
, . , , Mixed- Inception V3-, . () , .
, , . , , . , . , , , , .
, "" - . . .
, , .
:
Colab Colab .
TensorFlow Hub
TensorFlow Hub , .
. , , , .
.
Runtime -> Reset all runtimes...
, :
from __future__ import absolute_import, division, print_function, unicode_literals import numpy as np import matplotlib.pyplot as plt import tensorflow as tf tf.enable_eager_execution() import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.keras import layers
:
WARNING:tensorflow: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons * https://github.com/tensorflow/io (for I/O related ops) If you depend on functionality not listed there, please file an issue.
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
TensorFlow Datasets
TensorFlow Datasets. , — tf_flowers . , . tfds.splits (70%) (30%). tfds.load . tfds.load , , .
splits = tfds.Split.TRAIN.subsplit([70, 30]) (training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits)
:
Downloading and preparing dataset tf_flowers (218.21 MiB) to /root/tensorflow_datasets/tf_flowers/1.0.0... Dl Completed... 1/|/100% 1/1 [00:07<00:00, 3.67s/ url] Dl Size... 218/|/100% 218/218 [00:07<00:00, 30.69 MiB/s] Extraction completed... 1/|/100% 1/1 [00:07<00:00, 7.05s/ file] Dataset tf_flowers downloaded and prepared to /root/tensorflow_datasets/tf_flowers/1.0.0. Subsequent calls will reuse this data.
, , () , , — .
num_classes = dataset_info.features['label'].num_classes num_training_examples = 0 num_validation_examples = 0 for example in training_set: num_training_examples += 1 for example in validation_set: num_validation_examples += 1 print('Total Number of Classes: {}'.format(num_classes)) print('Total Number of Training Images: {}'.format(num_training_examples)) print('Total Number of Validation Images: {} \n'.format(num_validation_examples))
:
Total Number of Classes: 5 Total Number of Training Images: 2590 Total Number of Validation Images: 1080
— .
for i, example in enumerate(training_set.take(5)): print('Image {} shape: {} label: {}'.format(i+1, example[0].shape, example[1]))
:
Image 1 shape: (226, 240, 3) label: 0 Image 2 shape: (240, 145, 3) label: 2 Image 3 shape: (331, 500, 3) label: 2 Image 4 shape: (240, 320, 3) label: 0 Image 5 shape: (333, 500, 3) label: 1
— , MobilNet v2 — 224224 (grayscale). image () label () .
IMAGE_RES = 224 def format_image(image, label): image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES))/255.0 return image, label BATCH_SIZE = 32 train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1)
TensorFlow Hub
TensorFlow Hub . , , .
feature_extractor MobileNet v2. , TensorFlow Hub ( ) . . tf2-preview/mobilenet_v2/feature_vector , URL MobileNet v2 . feature_extractor hub.KerasLayer input_shape .
URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4" feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
, :
feature_extractor.trainable = False
, . . .
model = tf.keras.Sequential([ feature_extractor, layers.Dense(num_classes, activation='softmax') ]) model.summary()
:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer (KerasLayer) (None, 1280) 2257984 _________________________________________________________________ dense (Dense) (None, 5) 6405 ================================================================= Total params: 2,264,389 Trainable params: 6,405 Non-trainable params: 2,257,984
, .
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) EPOCHS = 6 history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
:
Epoch 1/6 81/81 [==============================] - 17s 216ms/step - loss: 0.7765 - acc: 0.7170 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 81/81 [==============================] - 12s 147ms/step - loss: 0.3806 - acc: 0.8757 - val_loss: 0.3485 - val_acc: 0.8833 Epoch 3/6 81/81 [==============================] - 12s 146ms/step - loss: 0.3011 - acc: 0.9031 - val_loss: 0.3190 - val_acc: 0.8907 Epoch 4/6 81/81 [==============================] - 12s 147ms/step - loss: 0.2527 - acc: 0.9205 - val_loss: 0.3031 - val_acc: 0.8917 Epoch 5/6 81/81 [==============================] - 12s 148ms/step - loss: 0.2177 - acc: 0.9371 - val_loss: 0.2933 - val_acc: 0.8972 Epoch 6/6 81/81 [==============================] - 12s 146ms/step - loss: 0.1905 - acc: 0.9456 - val_loss: 0.2870 - val_acc: 0.9000
~90% 6 , ! , , ~76% 80 . , MobilNet v2 .
.
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.show()
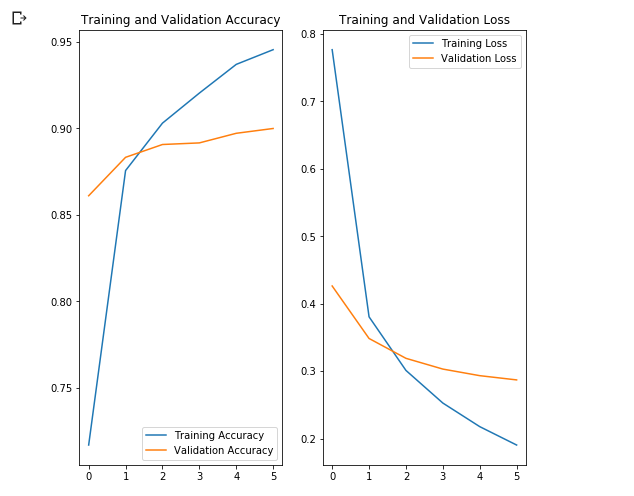
, , .
, , .
- MobileNet, . ( augmentation), . .
NumPy. , .
class_names = np.array(dataset_info.features['label'].names) print(class_names)
:
['dandelion' 'daisy' 'tulips' 'sunflowers' 'roses']
next() image_batch ( ) label_batch ( ). image_batch label_batch NumPy .numpy() . .predict() . np.argmax() . .
image_batch, label_batch = next(iter(train_batches)) image_batch = image_batch.numpy() label_batch = label_batch.numpy() predicted_batch = model.predict(image_batch) predicted_batch = tf.squeeze(predicted_batch).numpy() predicted_ids = np.argmax(predicted_batch, axis=-1) predicted_class_names = class_names[predicted_ids] print(predicted_class_names)
:
['sunflowers' 'roses' 'tulips' 'tulips' 'daisy' 'dandelion' 'tulips' 'sunflowers' 'daisy' 'daisy' 'tulips' 'daisy' 'daisy' 'tulips' 'tulips' 'tulips' 'dandelion' 'dandelion' 'tulips' 'tulips' 'dandelion' 'roses' 'daisy' 'daisy' 'dandelion' 'roses' 'daisy' 'tulips' 'dandelion' 'dandelion' 'roses' 'dandelion']
print("Labels: ", label_batch) print("Predicted labels: ", predicted_ids)
:
Labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0] Predicted labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0]
plt.figure(figsize=(10,9)) for n in range(30): plt.subplot(6,5,n+1) plt.subplots_adjust(hspace = 0.3) plt.imshow(image_batch[n]) color = "blue" if predicted_ids[n] == label_batch[n] else "red" plt.title(predicted_class_names[n].title(), color=color) plt.axis('off') _ = plt.suptitle("Model predictions (blue: correct, red: incorrect)")

Inception-
TensorFlow Hub tf2-preview/inception_v3/feature_vector . Inception V3 . , Inception V3 . , Inception V3 299299 . Inception V3 MobileNet V2.
IMAGE_RES = 299 (training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits) train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1) URL = "https://tfhub.dev/google/tf2-preview/inception_v3/feature_vector/4" feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3), trainable=False) model_inception = tf.keras.Sequential([ feature_extractor, tf.keras.layers.Dense(num_classes, activation='softmax') ]) model_inception.summary()
:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 2048) 21802784 _________________________________________________________________ dense_1 (Dense) (None, 5) 10245 ================================================================= Total params: 21,813,029 Trainable params: 10,245 Non-trainable params: 21,802,784
model_inception.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) EPOCHS = 6 history = model_inception.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
:
Epoch 1/6 81/81 [==============================] - 44s 541ms/step - loss: 0.7594 - acc: 0.7309 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 81/81 [==============================] - 35s 434ms/step - loss: 0.3927 - acc: 0.8772 - val_loss: 0.3945 - val_acc: 0.8657 Epoch 3/6 81/81 [==============================] - 35s 434ms/step - loss: 0.3074 - acc: 0.9120 - val_loss: 0.3586 - val_acc: 0.8769 Epoch 4/6 81/81 [==============================] - 35s 434ms/step - loss: 0.2588 - acc: 0.9282 - val_loss: 0.3385 - val_acc: 0.8796 Epoch 5/6 81/81 [==============================] - 35s 436ms/step - loss: 0.2252 - acc: 0.9375 - val_loss: 0.3256 - val_acc: 0.8824 Epoch 6/6 81/81 [==============================] - 35s 435ms/step - loss: 0.1996 - acc: 0.9440 - val_loss: 0.3164 - val_acc: 0.8861
Ringkasan
. :
- : , . .
- : . "" , , .
- MobileNet: Google, . MobileNet .
MobileNet . . MobileNet .
… call-to-action — , share :)
YouTube
Telegram
VKontakte
Ojok .