Halo semuanya!
Saya sudah memberi tahu di blog ini tentang organisasi sistem pemantauan modular untuk arsitektur layanan mikro dan tentang transisi dari Graphite + Whisper ke Graphite + ClickHouse untuk menyimpan metrik di bawah beban tinggi. Setelah itu, kolega saya Sergey Noskov menulis tentang tautan pertama dalam sistem pemantauan kami - Bioyino yang dikembangkan oleh kami, agregator metrik yang dapat diskalakan yang didistribusikan.
Waktunya telah tiba untuk menyegarkan informasi tentang bagaimana kami mempersiapkan pemantauan di Avito - artikel terakhir kami sudah kembali pada tahun 2018, dan selama waktu ini ada beberapa perubahan menarik dalam arsitektur pemantauan, pemicu dan manajemen pemberitahuan, berbagai optimisasi data di ClickHouse dan inovasi lainnya, tentang yang saya hanya ingin memberi tahu Anda.

Tapi mari kita mulai secara berurutan.
Kembali pada tahun 2017, saya menunjukkan diagram interaksi komponen yang relevan pada waktu itu, dan saya ingin mendemonstrasikannya lagi sehingga Anda tidak perlu berpindah tab lagi.

Sejak saat itu, berikut ini terjadi.
Jumlah server di cluster Graphite telah meningkat dari 3 menjadi 6.
( 56 CPU 2.60GHz, 384GB RAM, 10 SSD SAS 745GB, Raid 6, 10GBit/s Net ).
Kami mengganti brubeck dengan bioyino - implementasi StatsD dengan Rust kami sendiri, dan bahkan menulis seluruh artikel tentang itu . Namun, setelah rilis artikel, kami membawa dukungan untuk tag (Graphite) dan Raft di dalamnya untuk memilih pemimpin.
Kami mencari kemungkinan menggunakan bioyino sebagai agen StatsD dan menempatkan agen tersebut di sebelah instance monolith, serta di mana ia dibutuhkan dalam k8s.
Kami akhirnya menyingkirkan sistem pemantauan Munin lama (secara resmi kami masih memilikinya, tetapi datanya tidak lagi digunakan).
Pengumpulan data dari kelompok Kubernetes diselenggarakan melalui Prometheus / Federasi, karena Heapster tidak didukung dalam versi baru Kubernetes.
Pemantauan
Selama dua tahun terakhir, jumlah metrik yang diterima dan diproses telah meningkat sekitar 9 kali.
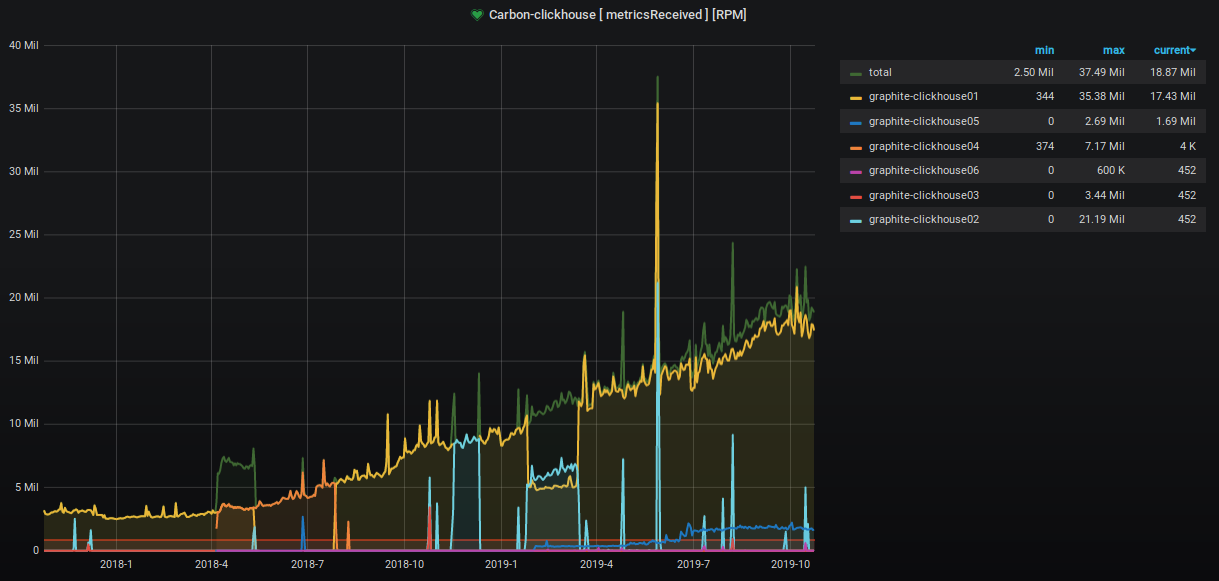
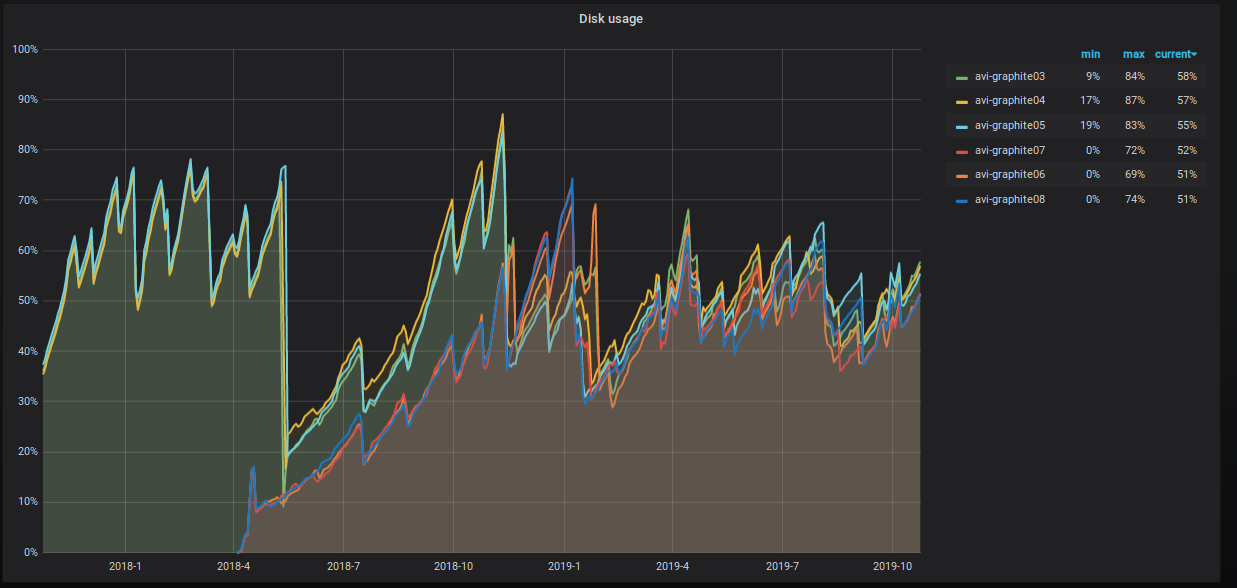
Persentase ruang server yang diduduki juga merayap naik, dan kami mengambil berbagai langkah untuk menurunkannya. Ini terlihat jelas pada grafik.
Apa yang sebenarnya kita lakukan?
10 10 10 * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data' and max_date between today()-55 AND today()-35;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "OPTIMIZE TABLE graphite.data PARTITION ('"$PART"') FINAL";done
- Kami berbagi tabel data. Sekarang kami memiliki tiga pecahan dengan dua replika masing-masing dengan kunci pecahan hash atas nama metrik. Pendekatan ini memberi kita kesempatan untuk melakukan prosedur rollup , karena semua nilai untuk metrik tertentu berada dalam beling yang sama, dan ruang disk pada semua beling digunakan secara seragam.
Skema tabel terdistribusi adalah sebagai berikut.
CREATE TABLE graphite.data_all ( `Path` String, `Value` Float64, `Time` UInt32, `Date` Date, `Timestamp` UInt32 ) ENGINE = Distributed ( 'graphite_cluster', 'graphite', 'data', jumpConsistentHash(cityHash64(Path), 3) )
Kami juga menugaskan pengguna "default" hak baca saja dan melemparkan eksekusi prosedur penulisan ke tabel ke sistem pengguna systemXXX terpisah.
Konfigurasi cluster Graphite di ClickHouse adalah sebagai berikut.
<remote_servers> <graphite_cluster> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse01</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse04</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse02</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse05</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse03</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse06</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> </graphite_cluster> </remote_servers>
Selain beban tulis, jumlah permintaan untuk membaca data dari Graphite telah meningkat. Data ini digunakan untuk:
- memicu pemrosesan dan pembuatan lansiran;
- menampilkan grafik pada monitor di kantor dan layar laptop dan PC dari semakin banyak karyawan perusahaan.
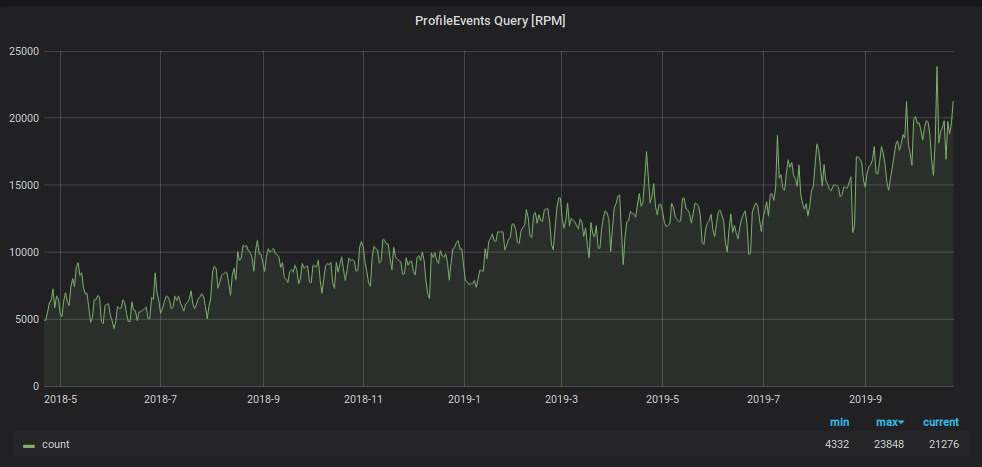
Untuk mencegah pemantauan tenggelam di bawah beban ini, kami menggunakan retasan lain: kami menyimpan data selama dua hari terakhir di piring "kecil" yang terpisah, dan kami mengirim semua permintaan membaca selama dua hari terakhir di sana, mengurangi beban di tabel beling utama. Juga untuk tablet "kecil" ini, kami menggunakan skema penyimpanan metrik terbalik, yang sangat mempercepat pencarian data yang terkandung di dalamnya dan mengatur partisi harian untuknya. Skema pelat ini adalah sebagai berikut.
CREATE TABLE graphite.data_reverse ( `Path` String, `Value` Float64, `Time` UInt32 CODEC(Delta(4), ZSTD(1)), `Date` Date, `Timestamp` UInt32 ) ENGINE = ReplicatedGraphiteMergeTree ( '/clickhouse/tables/{cluster}/data_reverse', '{replica}', 'graphite_rollup' ) PARTITION BY Date ORDER BY (Path, Time) SETTINGS index_granularity = 4096
Untuk mengarahkan data ke dalamnya, kami menambahkan bagian baru ke file konfigurasi aplikasi carbon-clickhouse .
[upload.graphite_reverse] type = "points-reverse" table = "graphite.data_reverse" threads = 2 url = "http://systemXXX:XXXXXXX@localhost:8123/" timeout = "60s" cache-ttl = "6h0m0s" zero-timestamp = true
Untuk menghapus partisi yang lebih dari dua hari, kami menulis tugas cron. Itu terlihat seperti ini.
1 12 * * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data_reverse' and max_date<today()-2;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "ALTER TABLE graphite.data_reverse DROP PARTITION ('"$PART"')";done
Untuk membaca data dari tabel, dalam file konfigurasi graphite-clickhouse , bagian telah ditambahkan:
[[data-table]] table = "graphite.data_reverse" max-age = "48h" reverse = true
Akibatnya, kami memiliki tabel dengan 100% dari data yang direplikasi ke enam server yang memproses seluruh beban bacaan dari permintaan dengan jendela kurang dari dua hari (dan kami memiliki 95% dari ini). Dan juga kami memiliki tabel berjuntai dengan 1/3 data pada setiap beling, yang menyediakan pembacaan semua data historis. Dan bahkan jika permintaan seperti itu jauh lebih kecil, beban darinya jauh lebih tinggi.
Apa yang terjadi dengan CPU ?! Sebagai hasil dari peningkatan volume data yang direkam dan dibaca dalam cluster Graphite, total beban CPU pada server juga meningkat. Itu terlihat seperti ini.
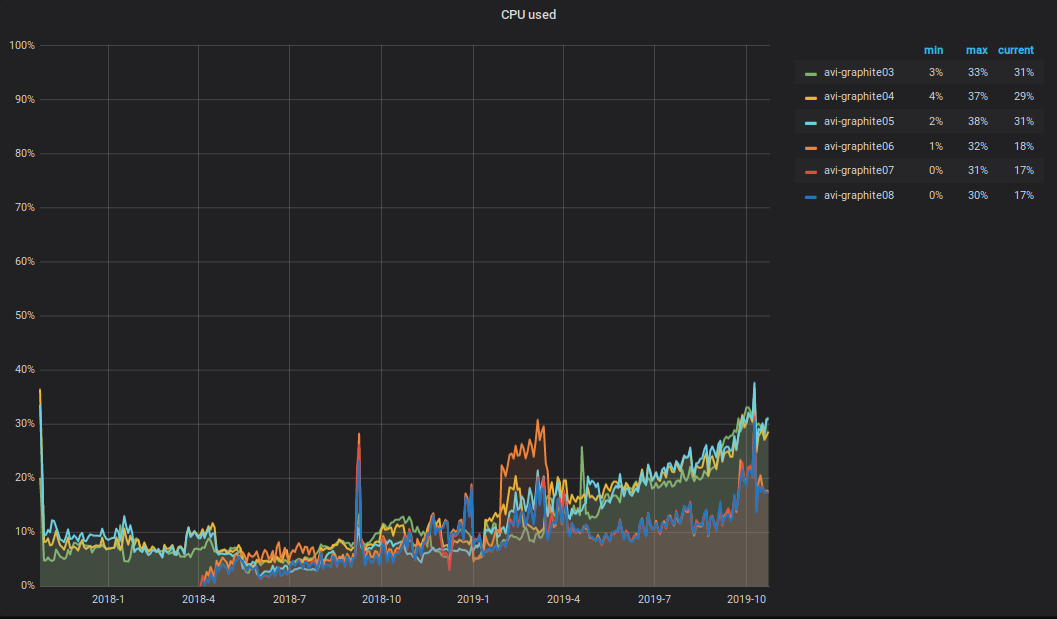
Saya ingin menarik perhatian pada nuansa berikut: setengah dari CPU digunakan untuk parsing dan pemrosesan metrik utama dalam karbon-c-relay (v3.2 dari 2018-09-05, yang bertanggung jawab untuk mengangkut metrik), yang terletak pada tiga dari enam server. Seperti yang Anda lihat dari grafik, ketiga server inilah yang ada di TOP.
Peringatan
Sebagai sistem peringatan, kami masih memiliki Moira dan klien-moira yang ditulis untuk itu. Untuk manajemen pemicu, pemberitahuan, dan eskalasi yang fleksibel, kami menggunakan deskripsi deklaratif yang disebut alert.yaml. Ini dihasilkan secara otomatis ketika layanan dibuat melalui PaaS (lebih lanjut tentang ini dapat ditemukan dalam artikel oleh Vadim Madison "Apa yang kita ketahui tentang layanan microser" ) dan ditempatkan dalam repositori. Untuk bekerja dengan alert.yaml, kami membuat ikatan pada moira-client dan menyebutnya alert-autoconf (kami berencana untuk membuka). Ada langkah dalam perakitan layanan di TeamCity dengan mengekspor pemicu dan pemberitahuan ke Moira melalui alert-autoconf. Saat melakukan perubahan pada alert.yaml, tes otomatis dijalankan yang memeriksa validitas file yaml, dan juga meminta Graphite untuk setiap templat metrik untuk memverifikasi kebenarannya.
Untuk tim infrastruktur yang tidak menggunakan PaaS, kami telah mengatur repositori terpisah bernama Alerting. Itu membuat struktur formulir: Tim / Proyek / alert.yaml. Untuk setiap alert.yaml, kami membuat perakitan terpisah di TeamCity, yang menjalankan tes dan mendorong konten alert.yaml di Moira.
Dengan demikian, semua karyawan kami dapat mengelola pemicu, pemberitahuan, dan eskalasi mereka menggunakan pendekatan tunggal.
Karena sebelum kita telah memicu trigger melalui GUI, kami mengimplementasikan kemampuan untuk mengunggahnya dalam format yaml. Isi dari dokumen yaml yang diterima dapat dimasukkan ke dalam alert.yaml dengan praktis tidak ada transformasi tambahan, dan kemudian mendorong perubahan ke wizard. Selama proses pembuatan, alert-autoconf akan memahami bahwa pemicu seperti itu sudah ada dan akan mendaftarkannya di registri kami di Redis.
Dan belum lama ini, kami mendapat giliran tugas insinyur 24x7. Untuk mentransfer pemicu kepada mereka untuk diservis, cukup dalam lansiran Anda. Anda dapat mengisi deskripsi "apa yang harus dilakukan jika Anda melihatnya", letakkan tag [24x7] dan dorong perubahan ke wizard. Setelah rolling alert.yaml, semua pemicu yang dijelaskan di dalamnya akan secara otomatis berada di bawah pemantauan shift 24 jam 24x7. U - Sederhanakan! Cantik!
Pengumpulan metrik bisnis
Sejak artikel terakhir tentang mengumpulkan dan memproses metrik bisnis, bioyino kami menjadi lebih baik.
- Alih-alih memilih pemimpin melalui Konsul , Rakit bawaan digunakan .
- Tag diproses dengan benar dalam format Graphite .
- Sekarang Anda dapat menggunakan bioyino (StatsD-server) sebagai agen.
- Untuk menghitung nilai unik, format "set" didukung.
- Agregasi akhir metrik dapat dilakukan dalam beberapa utas.
- Data dapat dikirim ke potongan Graphite dalam beberapa koneksi paralel.
- Memperbaiki semua bug yang ditemukan.
Sekarang berfungsi seperti ini.
Kami mulai secara aktif memperkenalkan agen StatsD di sebelah semua generator metrik besar yang besar: dalam wadah dengan instance monolith, di pod k8s di samping layanan, pada host dengan komponen infrastruktur, dll.
Agen Statsd terletak di sebelah aplikasi. Dibutuhkan metrik dari aplikasi ini semua sama di atas UDP, tetapi tidak lagi menggunakan subsistem jaringan (karena optimasi di kernel Linux). Semua acara sudah dipra-agregat, dan data yang dikumpulkan setiap detik (interval dapat dikonfigurasi) dikirim ke kelompok utama server StatsD (bioyino0 [1-3]) dalam format Cap'n Proto.
Pemrosesan lebih lanjut dan agregasi metrik, pilihan pemimpin di cluster StatsD, dan pengiriman metrik oleh pemimpin ke Graphite tidak berubah. Anda dapat membaca tentang ini secara rinci di artikel terakhir kami .
Adapun angkanya, adalah sebagai berikut.
Grafik acara StatsD yang diterima
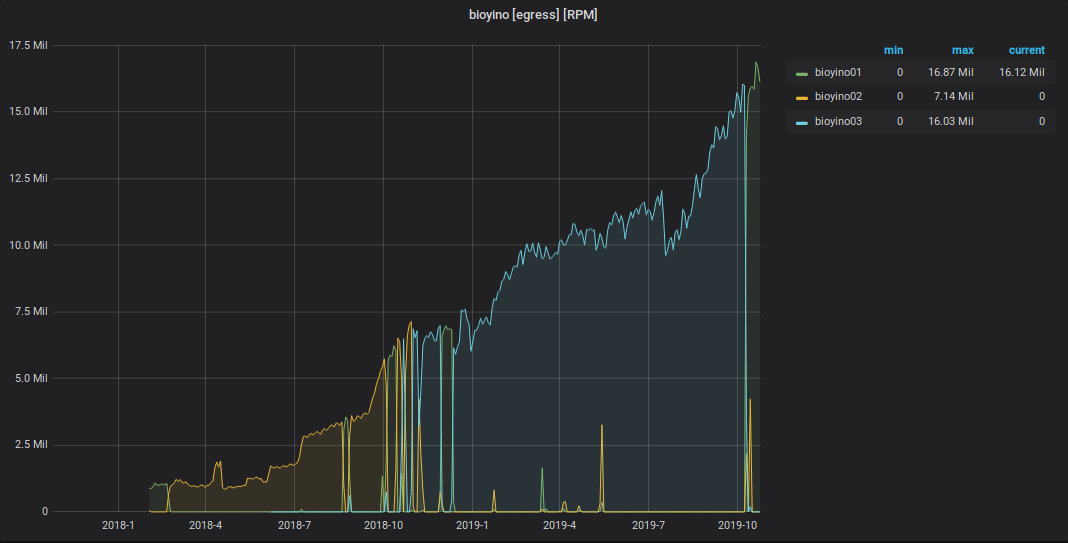

Grafik metrik yang dikirim dari StatsD ke Graphite
Total
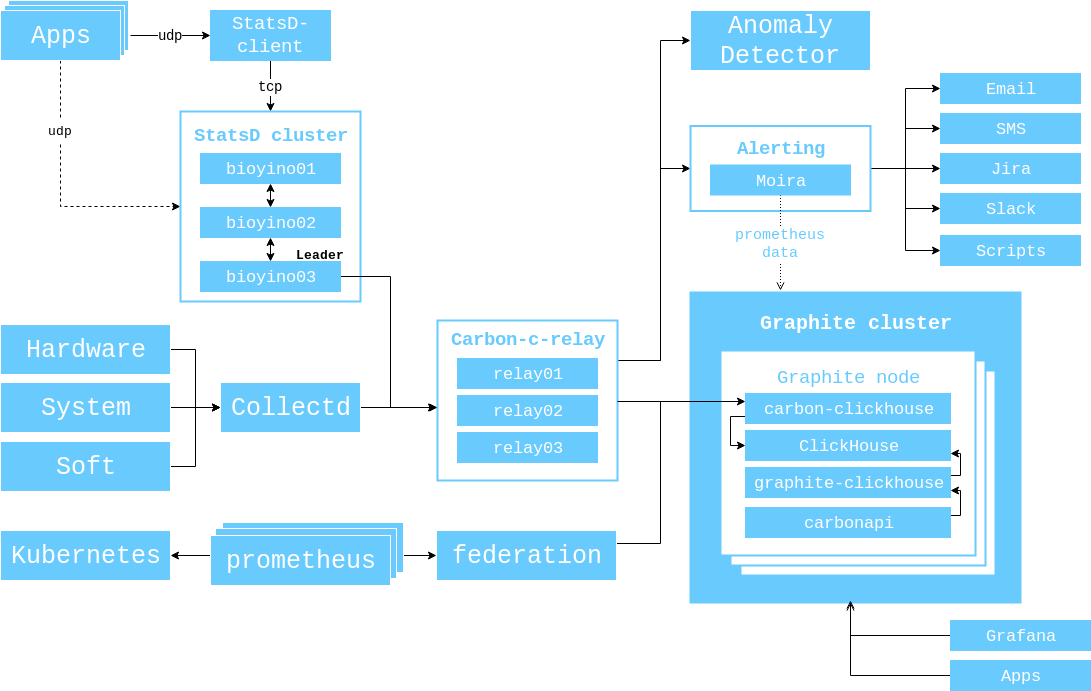
Skema umum interaksi antara komponen pemantauan saat ini terlihat seperti ini.
Total jumlah metrik: 2 189 484 898 474.
Total kedalaman penyimpanan metrik: 3 tahun.
Jumlah nama metrik unik: 6 585 413 171.
Jumlah pemicu: 1053, mereka melayani dari 1 hingga 15k metrik.
Paket untuk waktu dekat:
- mulai memindahkan layanan produk ke skema penyimpanan metrik yang ditandai;
- tambahkan tiga server lagi ke cluster Graphite;
- berteman dengan Moira dengan jaringan persisten ;
- Temukan pengembang lain di tim pemantauan.
Saya akan senang memberikan komentar dan pertanyaan di sini - tulis. Dan saya juga akan tampil di Highload ++ pada 7 November , jika Anda ada di sana, kita bisa bicara.