Dalam
artikel terakhir, kami menemukan bahwa cache jelas merupakan hal yang bermanfaat, tetapi berkaitan dengan logika pengontrol, terkadang membuat kesulitan. Secara khusus, ini memperkenalkan durasi denyut nadi yang tidak dapat diprediksi atau penundaan lain dalam pembentukan diagram waktu yang terprogram. Nah, dan dalam rencana "program terprogram", lokasi fungsi yang buruk dapat mengurangi keuntungan dari cache menjadi kosong, terus-menerus memprovokasi untuk reboot dari memori lambat. Saya menyebutkan bahwa 15 tahun yang lalu kami harus membuat preprosesor khusus yang memperbaiki masalah yang muncul untuk prosesor SPARC-8, dan berjanji untuk mengatakan betapa mudahnya untuk memperbaiki kesulitan seperti itu ketika mengembangkan prosesor Nios II yang disintesis yang direkomendasikan untuk digunakan dalam paket Redd. Waktunya telah tiba untuk memenuhi janji.

Artikel sebelumnya dalam seri:
- Pengembangan "firmware" paling sederhana untuk FPGA yang dipasang di Redd, dan debugging menggunakan tes memori sebagai contoh.
- Pengembangan "firmware" paling sederhana untuk FPGA yang dipasang di Redd. Bagian 2. Kode program.
- Pengembangan intinya sendiri untuk ditanamkan dalam sistem prosesor berbasis FPGA.
- Pengembangan program untuk prosesor pusat Redd pada contoh akses ke FPGA.
- Eksperimen pertama menggunakan protokol streaming pada contoh koneksi CPU dan prosesor di FPGA kompleks Redd.
- Merry Quartusel, atau bagaimana prosesor telah hidup seperti itu.
- Metode Optimasi Kode untuk Redd. Bagian 1: efek cache.
Hari ini, buku referensi kami akan menjadi
Buku Pegangan Desain Tertanam , atau lebih tepatnya, bagian
7.5. Menggunakan Memori yang Digabungkan dengan Tutorial Prosesor Nios II . Bagian itu sendiri berwarna-warni. Hari ini kami merancang sistem prosesor untuk Intel FPGA dalam program Platform Designer. Pada zaman Altera, itu disebut QSys (maka ekstensi
.qsys dari file proyek). Tetapi sebelum QSsys muncul, semua orang menggunakan leluhurnya, SOPC Builder (yang ingatannya, ekstensi file
.sopcinfo ditinggalkan ). Jadi, walaupun dokumen tersebut ditandai dengan logo Intel, tetapi gambar di dalamnya adalah screenshot dari SOPC Builder ini. Itu jelas ditulis lebih dari sepuluh tahun yang lalu, dan sejak itu hanya istilah yang diperbaiki di dalamnya. Benar, teksnya cukup modern, jadi dokumen ini cukup berguna sebagai panduan pelatihan.
Persiapan Peralatan
Jadi Kami ingin menambahkan memori ke sistem prosesor Spartan kami, yang tidak pernah di-cache dan pada saat yang sama berjalan pada kecepatan setinggi mungkin. Tentu saja, ini akan menjadi memori FPGA internal. Kami akan menambahkan memori untuk kode dan data, tetapi ini akan menjadi blok yang berbeda. Mari kita mulai dengan memori data sebagai yang paling sederhana. Kami
menambahkan Memori OnChip yang sudah dikenal ke sistem.
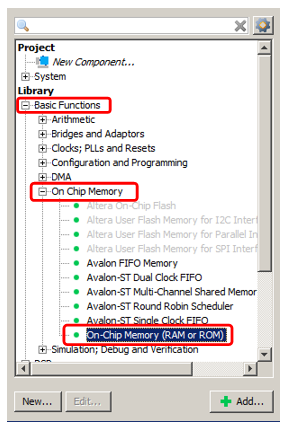
Ya, misalkan volumenya akan 2 kilobyte (masalah utama dengan memori internal FPGA adalah kecil, jadi Anda harus menyimpannya). Sisanya adalah memori biasa, yang telah kita tambahkan.

Tapi kami tidak akan menghubungkannya ke bus data, tetapi ke bus khusus. Untuk membuatnya muncul, kita masuk ke properti prosesor, pergi ke tab
Cache dan Memory Interfaces dan dalam daftar pilihan
Jumlah port master data coulped erat pilih nilai 1.
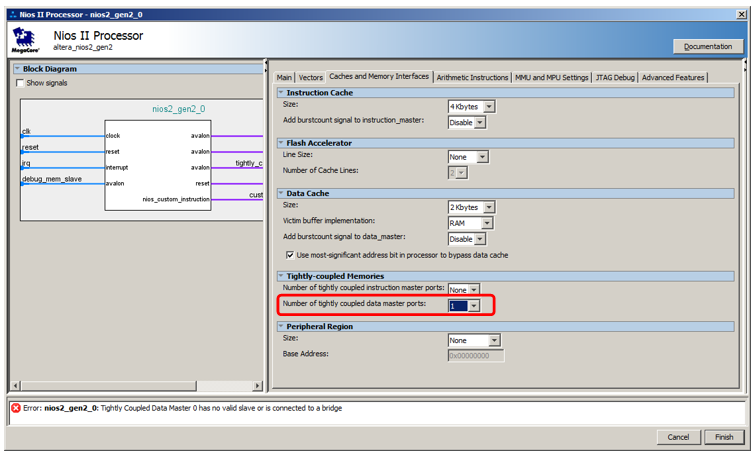
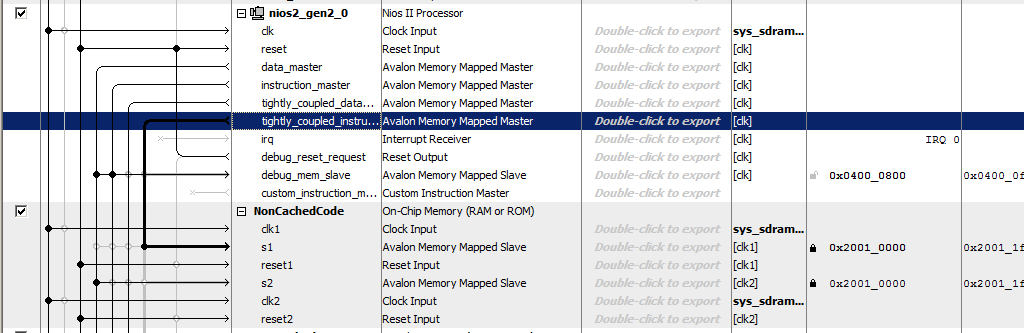
Berikut port baru untuk prosesor:

Kami baru-baru ini menghubungkan blok memori yang baru ditambahkan ke dalamnya!
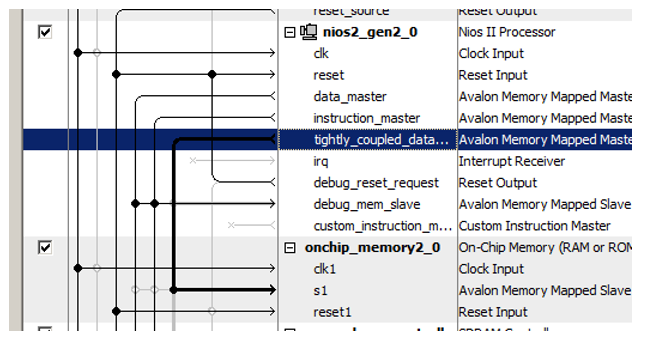
Trik lain adalah dalam menetapkan alamat ke memori baru ini. Dokumen ini memiliki garis panjang alasan tentang optimalisasi decoding alamat. Ini menyatakan bahwa memori yang tidak di-cache harus dibedakan dari semua jenis memori lainnya dengan bit alamat yang diekspresikan dengan jelas. Oleh karena itu, dalam dokumen, semua memori yang tidak dapat disimpan dalam cache termasuk dalam kisaran 0x2XXXXXXX. Jadi, masukkan alamat 0x2000000 secara manual dan kunci agar tidak berubah dengan penetapan otomatis berikut.

Yah, dan murni untuk estetika, ganti nama blok ... Sebut saja, katakanlah,
NonCachedData .

Dengan perangkat keras untuk memori data yang tidak di-cache, itu saja. Kami beralih ke memori untuk penyimpanan kode. Semuanya hampir sama di sini, tetapi sedikit lebih rumit. Faktanya, semuanya dapat dilakukan dengan sepenuhnya identik, hanya port master bus yang dibuka dalam daftar
Jumlah port master instruksi yang diikat dengan ketat , namun, tidak mungkin untuk melakukan debug sistem seperti itu. Ketika program diisi dengan debugger, itu mengalir ke sana melalui bus data. Ketika berhenti, kode yang dibongkar juga dibaca oleh debugger melalui bus data. Dan bahkan jika program dimuat dari loader eksternal (kami belum mempertimbangkan metode seperti itu, terutama karena dalam versi gratis dari lingkungan pengembangan kami berkewajiban untuk bekerja hanya dengan debugger JTAG terhubung, tetapi secara umum, tidak ada yang melarang melakukan hal ini), isi juga melalui bus data. Oleh karena itu, memori harus melakukan dual-port. Ke satu port, sambungkan wizard instruksi yang tidak di-cache yang berfungsi pada waktu utama, dan ke port lainnya - bus data purnawaktu tambahan. Ini akan digunakan untuk mengunduh program dari luar, serta untuk mendapatkan konten RAM oleh debugger. Sisa waktu ban ini tidak digunakan. Beginilah tampilannya di bagian teoretis dokumen:

Perhatikan bahwa dokumen tidak menjelaskan alasannya, tetapi dicatat bahwa bahkan dengan memori port ganda, hanya satu port yang dapat dihubungkan ke master yang tidak di-cache. Yang kedua harus terhubung dengan yang biasa.
Mari kita tambahkan 8 kilobyte memori, buatlah dual-port, biarkan sisanya secara default:
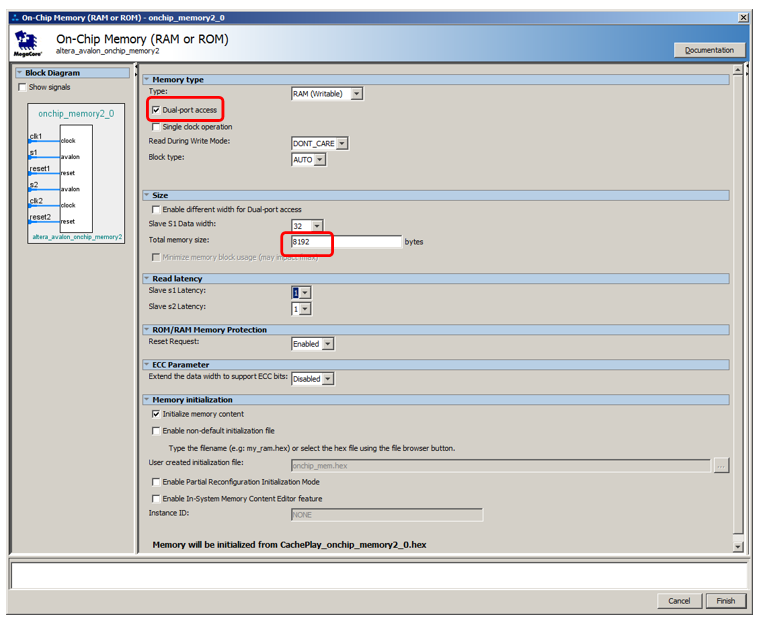
Tambahkan port instruksi yang tidak bisa di-cache ke prosesor:

Kami memanggil memori
NonCachedCode , menghubungkan memori ke bus, menetapkannya 0x20010000 dan menguncinya (untuk kedua port). Total, kami mendapatkan sesuatu seperti ini:
Itu saja. Kami menyimpan dan menghasilkan sistem, mengumpulkan proyek. Perangkat keras sudah siap. Kami lolos ke bagian perangkat lunak.
Persiapan BSP di bagian perangkat lunak
Biasanya, setelah mengubah sistem prosesor, cukup pilih item menu
Hasilkan BSP , tetapi hari ini kita harus membuka Editor BSP. Karena kami jarang melakukan ini, izinkan saya mengingatkan Anda di mana item menu yang sesuai berada:
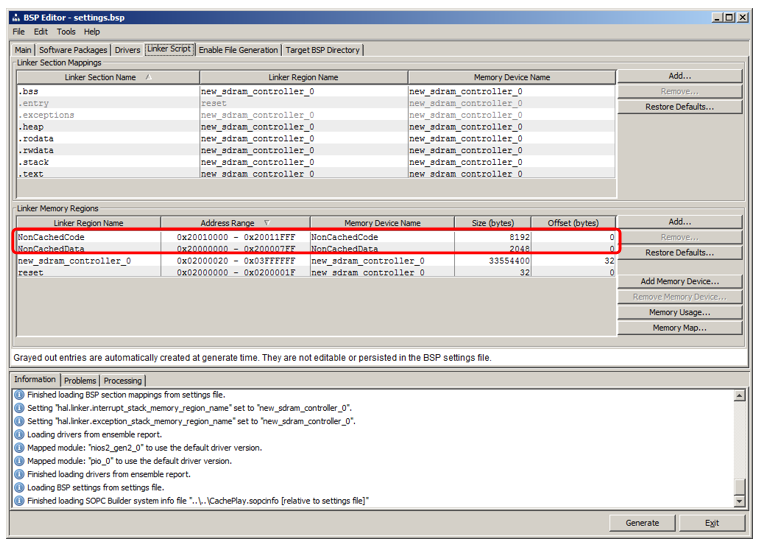
Di sana kita pergi ke tab
Skrip Linker . Kami melihat bahwa kami telah menambahkan wilayah yang mewarisi nama dari blok RAM:
Saya akan menunjukkan cara menambahkan bagian di mana kode akan ditempatkan. Di bagian bagian, klik Tambah:
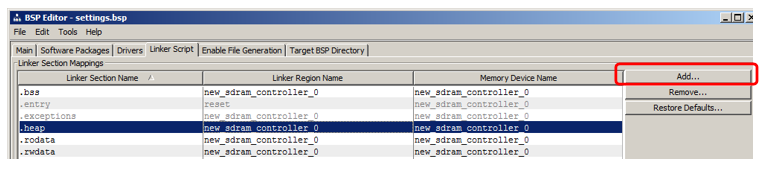
Di jendela yang muncul, beri nama bagian (untuk menghindari kebingungan dalam artikel, saya akan menamainya sangat berbeda dengan nama wilayah, yaitu nccode) dan menghubungkannya dengan wilayah (saya memilih
NonCachedCode dari daftar):

Itu dia, hasilkan BSP dan tutup editor.
Menempatkan kode di bagian memori baru
Biarkan saya mengingatkan Anda bahwa kami memiliki dua fungsi dalam program yang diwarisi dari artikel sebelumnya:
MagicFunction1 () dan
MagicFunction2 () . Pada pass pertama, keduanya memuat tubuh mereka ke dalam cache, yang terlihat pada osiloskop. Lebih lanjut - tergantung pada situasi di lingkungan, mereka bekerja dengan kecepatan maksimum atau secara konstan saling menggosok dengan tubuh mereka, memprovokasi unduhan konstan dari SDRAM.
Mari kita pindahkan fungsi pertama ke segmen yang tidak di-cache yang baru, dan biarkan yang kedua di tempatnya, lalu jalankan beberapa langkah.
Untuk menempatkan fungsi di bagian baru, tambahkan atribut bagian ke dalamnya.
Sebelum mendefinisikan fungsi
MagicFunction1 () ,
kami juga menempatkan deklarasi dengan atribut ini:
void MagicFunction1()__attribute__ ((section("nccode"))); void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ...
Kami melakukan run pertama dari satu iterasi dari loop (saya meletakkan breakpoint pada baris while):
while (1) { MagicFunction1(); MagicFunction2(); }
Kami melihat hasil berikut:
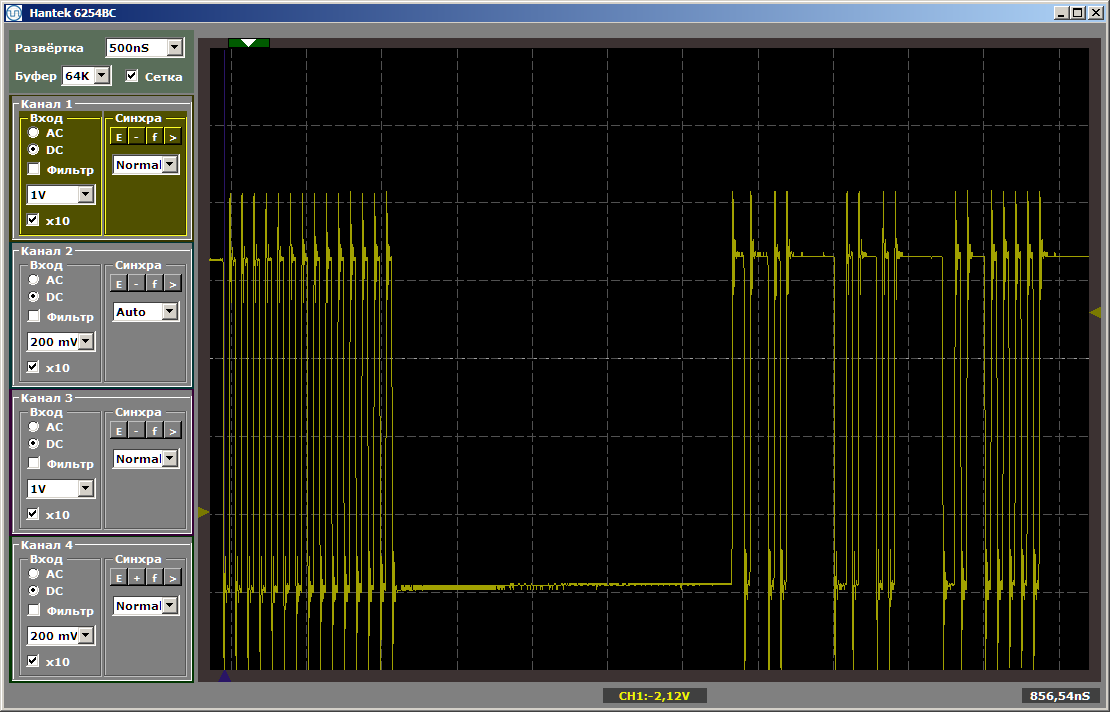
Seperti yang Anda lihat, fungsi pertama benar-benar dijalankan pada kecepatan maksimum, yang kedua diambil dari SDRAM. Jalankan jalankan kedua:
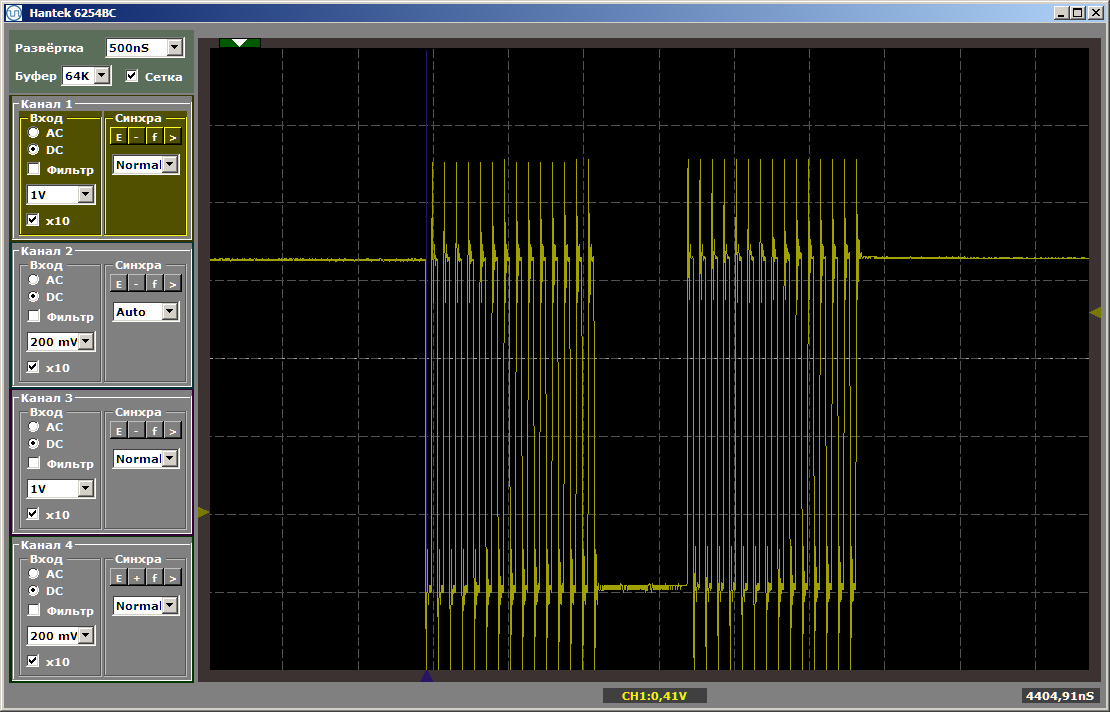
Kedua fungsi beroperasi pada kecepatan maksimum. Dan fungsi pertama tidak membongkar yang kedua dari cache, meskipun fakta bahwa di antara mereka adalah sisipan yang saya tinggalkan setelah menulis artikel terakhir:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 }
Penyisipan ini tidak lagi memengaruhi posisi relatif dari kedua fungsi tersebut, karena yang pertama tertinggal di area memori yang sama sekali berbeda.
Beberapa kata tentang data
Demikian pula, Anda dapat membuat bagian data yang tidak di-cache dan menempatkan variabel global di sana, menugaskan mereka atribut yang sama, tetapi untuk menghemat ruang, saya tidak akan memberikan contoh seperti itu.
Kami telah membuat wilayah untuk memori seperti itu, pemetaan ke bagian dapat dilakukan dengan cara yang sama seperti untuk bagian kode. Tetap hanya untuk memahami cara menetapkan atribut yang sesuai ke variabel. Berikut ini adalah contoh pertama dari mendeklarasikan data tersebut yang ditemukan dalam isi kode yang dibuat secara otomatis:
volatile alt_u32 alt_log_boot_on_flag \ __attribute__ ((section (".sdata"))) = ALT_LOG_BOOT_ON_FLAG_SETTING;
Apa manfaatnya bagi kita
Sebenarnya, dari hal-hal yang jelas: sekarang kita dapat menempatkan bagian utama dari kode di SDRAM, dan di bagian yang tidak dapat di-cache kita dapat mengeluarkan fungsi-fungsi yang membentuk diagram waktu secara terprogram, atau yang kinerjanya harus maksimal, yang berarti mereka tidak boleh melambat karena bahwa beberapa fungsi lain terus-menerus membuang kode yang sesuai dari cache.
Perhatikan baik-baik bannya.
Sekarang perhatikan baik-baik ban di sistem prosesor yang dihasilkan. Kami punya hampir empat dari mereka. Saya mengitari bus utama merah (yang merupakan gabungan dari keduanya, itulah sebabnya saya menulis "hampir": secara fisik - ada dua ban, tetapi secara logis - satu). Saya menyoroti dalam warna hijau bus menuju ke memori instruksi yang tidak di-cache, dengan warna biru - ke memori data yang tidak di-cache.
Ketiga ban ini bekerja secara paralel dan independen satu sama lain!
Ingat, dalam
artikel tentang DMA, saya berpendapat bahwa salah satu faktor pembatas kinerja adalah bahwa data ditransmisikan pada bus yang sama? Blok DMA membaca data dari bus, menulis data ke dalamnya, dan bahkan pada saat yang sama inti prosesor menggunakan bus yang sama. Seperti yang Anda lihat, kelemahan sistem tertutup ini sepenuhnya dihilangkan dalam FPGA. Pada pengontrol siap pakai, pabrikan, ketika meletakkan koneksi, dipaksa untuk merobek antara kebutuhan dan kemampuan. Programmer mungkin perlu opsi ini. Dan semacamnya. Dan semacamnya. Maka ... Banyak hal mungkin diperlukan. Tetapi sumber daya membutuhkan biaya, dan tidak selalu ada ruang yang cukup untuk mereka pada kristal yang dipilih. Anda tidak dapat memposting semuanya. Kita harus memilih apa yang benar-benar dibutuhkan semua orang dan apa yang dibutuhkan dalam kasus-kasus yang terisolasi. Dan kasus terisolasi mana yang harus diperkenalkan, dan mana yang harus dilupakan. Dan kemudian muncul solusi kompromi, semua kehalusannya, jika ada keinginan untuk menggunakannya, programmer harus mengingatnya. Dalam kasus kami, kami dapat bertindak tanpa basa-basi lagi. Apa yang kita butuhkan hari ini diletakkan hari ini. Sumber daya kami fleksibel. Kami membelanjakannya agar peralatannya optimal untuk tugas kita hari ini. Untuk tugas besok dan kemarin, sumber daya tidak perlu dipesan. Tetapi di bawah hari ini kita akan meletakkan segala sesuatu sedemikian rupa sehingga program bekerja seefisien mungkin, tanpa memerlukan kesenangan pemrograman khusus.
Sekali waktu, di sebuah universitas dalam kursus pengolah sinyal kami diajarkan seni menggunakan dua bus secara paralel dengan satu tim. Sejauh yang saya tahu, dalam pengontrol ARM modern, pengetahuan rinci tentang matriks bus juga memungkinkan pengoptimalan. Tapi semua ini bagus ketika pengembang telah bekerja dengan sistem yang sama selama bertahun-tahun. Jika Anda harus menggunakan perangkat keras yang berbeda dari satu proyek ke proyek lainnya, Anda tidak dapat mengingat semuanya. Dalam kasus FPGA, kami tidak mempelajari fitur-fitur lingkungan, kami bebas untuk menyesuaikan lingkungan untuk diri kami sendiri.
Sehubungan dengan pendekatan "kami tidak menghabiskan banyak waktu untuk pengembangan", kedengarannya seperti ini:
Kita tidak perlu melakukan upaya untuk mengoptimalkan penggunaan ban standar yang sudah jadi, kita dapat dengan cepat meletakkannya di cara yang paling optimal untuk menyelesaikan tugas, dengan cepat menyelesaikan pengembangan bantu ini dan dengan cepat memastikan proses debugging atau pengujian proyek utama.
Mari kita lihat contoh termasuk blok DMA dari
Panduan Pengguna IP Perangkat Tertanam untuk mengkonsolidasikan materi.
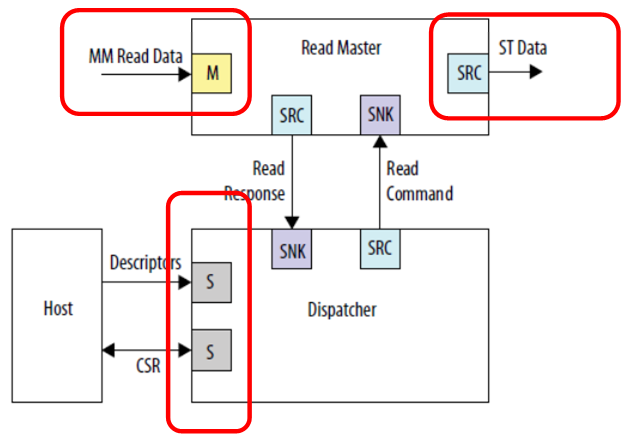
Kami melihat tiga koneksi independen. Input data (pada gambar ini adalah bus yang diproyeksikan ke memori), data keluaran (dalam gambar ini adalah bus yang sama sekali berbeda - antarmuka aliran) dan komunikasi dengan prosesor kontrol. Tidak ada yang mengganggu untuk menghubungkan semuanya ke bus yang berbeda, maka pekerjaan akan berjalan paralel. Input data (misalnya, dari SDRAM) akan masuk dalam satu aliran, yang tidak ada yang mengganggu; output akan masuk dalam aliran yang berbeda, katakanlah, ke saluran FT245-FIFO, yang telah kita pertimbangkan; dan prosesor pusat tidak akan makan jauh dari bus jam ini, karena bus utama terisolasi. Meskipun dalam kasus ini, tentu saja, memori dalam SDRAM, berada di bus terpisah, tidak akan tersedia secara terprogram. Tapi tidak ada yang akan mencegahnya dibaca oleh DMA. Jika tujuannya adalah untuk mencapai kinerja tinggi dengan buffer, maka itu harus dicapai di semua biaya. Kecuali jika keseluruhan program harus sesuai dengan memori yang terpasang dalam FPGA, karena tidak ada unit penyimpanan lain di perangkat keras Redd.
Untuk memparalelkan ban, Anda juga dapat menggunakan ban yang tidak di-cache, karena kami melihat ada beberapa ban. Sejumlah pembatasan diberlakukan pada budak yang terhubung dengan bus ini:
- budak itu selalu ada di bus;
- budak tidak menggunakan mekanisme penundaan bus;
- tulis latensi selalu nol, baca latensi selalu satu.
Jika kondisi ini terpenuhi, perangkat budak seperti itu dapat dihubungkan ke bus yang tidak di-cache. Tentu saja, kemungkinan besar, itu akan menjadi data bus.
Secara umum, mengetahui prinsip-prinsip dasar ini, Anda tentu dapat menggunakannya dalam tugas nyata. Tetapi, secara umum, Anda bisa. Anda dapat melakukannya tanpa ini, jika hasilnya dicapai dengan cara konvensional. Namun perlu diingat. Terkadang, mengoptimalkan sistem melalui mekanisme ini lebih sederhana daripada memperbaiki program.
Kesimpulan
Kami memeriksa teknik untuk mentransfer bagian-bagian kode yang penting untuk kinerja atau ke prediktabilitas pemrosesan eksekusi dalam memori yang tidak dapat di-cache. Sepanjang jalan, kami memeriksa kemungkinan mengoptimalkan kinerja melalui penggunaan beberapa ban yang beroperasi secara paralel dan independen satu sama lain.
Untuk menyelesaikan topik, kita masih harus belajar cara menaikkan frekuensi jam sistem (sekarang ini terbatas pada pulsa clock yang menghasilkan komponen untuk chip SDRAM). Tetapi karena artikel mengikuti prinsip "satu hal - satu artikel", kami akan melakukannya lain kali.