Halo semuanya! Dalam posting ini saya akan memberi tahu Anda pendekatan mana yang kami gunakan dalam Pencarian Mail.ru untuk membandingkan teks. Untuk apa ini? Segera setelah kami mempelajari cara membandingkan teks yang berbeda satu sama lain dengan baik, mesin pencari akan dapat lebih memahami permintaan pengguna.
Apa yang kita butuhkan untuk ini? Untuk memulainya, atur tugas dengan ketat. Anda perlu menentukan sendiri teks mana yang kami anggap serupa dan mana yang tidak kami pertimbangkan, lalu merumuskan strategi untuk secara otomatis menentukan kesamaan. Dalam kasus kami, teks permintaan pengguna akan dibandingkan dengan teks dokumen.
Tugas menentukan relevansi teks terdiri dari tiga tahap. Pertama, yang paling sederhana: mencari kata-kata yang cocok dalam dua teks dan menarik kesimpulan tentang kesamaan berdasarkan hasil. Tugas berikutnya yang lebih sulit adalah mencari hubungan antara kata-kata yang berbeda, memahami sinonim. Dan akhirnya, tahap ketiga: analisis seluruh kalimat / teks, mengisolasi makna dan membandingkan kalimat / teks dengan makna.

Salah satu cara untuk mengatasi masalah ini adalah menemukan beberapa pemetaan dari ruang teks ke beberapa yang lebih sederhana. Misalnya, Anda dapat menerjemahkan teks ke dalam ruang vektor dan membandingkan vektor.
Mari kita kembali ke awal dan mempertimbangkan pendekatan yang paling sederhana: menemukan kata yang cocok dalam pertanyaan dan dokumen. Tugas semacam itu sendiri sudah cukup rumit: untuk melakukan ini dengan baik, kita perlu belajar bagaimana mendapatkan bentuk kata-kata normal, yang dengan sendirinya tidak trivial.
Model pemetaan langsung dapat sangat ditingkatkan. Salah satu solusinya adalah mencocokkan sinonim bersyarat. Misalnya, Anda dapat memasukkan asumsi probabilistik pada distribusi kata dalam teks. Anda dapat bekerja dengan representasi vektor dan secara implisit mengisolasi koneksi antara kata-kata yang tidak cocok, dan melakukannya secara otomatis.
Karena kami terlibat dalam pencarian, kami memiliki banyak data tentang perilaku pengguna ketika menerima dokumen tertentu sebagai tanggapan terhadap beberapa pertanyaan. Berdasarkan data ini, kita dapat menarik kesimpulan tentang hubungan antara kata-kata yang berbeda.
Mari kita ambil dua kalimat:

Tetapkan setiap pasangan kata dari kueri dan dari judul beberapa bobot, yang akan berarti seberapa banyak kata pertama dikaitkan dengan yang kedua. Kami akan memprediksi klik sebagai transformasi sigmoidal dari jumlah bobot ini. Artinya, kami menetapkan tugas regresi logistik, di mana atribut diwakili oleh seperangkat pasangan bentuk (kata dari kueri, kata dari judul / teks dokumen). Jika kita dapat melatih model seperti itu, maka kita akan memahami kata-kata mana yang sinonim, lebih akurat, dapat dihubungkan, dan mana yang paling mungkin tidak bisa.
textbfprobabilitasklik= sigma kiri( jumlah varphii kanan) textbf,dimana varphii textbf−bobotbeberapakata(katapermintaan,katadokumen))
Sekarang Anda perlu membuat dataset yang baik. Ternyata cukup untuk mengambil riwayat klik pengguna, tambahkan contoh negatif. Bagaimana mencampur contoh negatif? Cara terbaik untuk menambahkannya ke dataset dalam rasio 1: 1. Selain itu, contoh-contoh itu sendiri pada tahap pertama pelatihan dapat dilakukan secara acak: untuk pasangan dokumen permintaan, kami menemukan dokumen acak lain, dan kami menganggap pasangan semacam itu negatif. Pada tahap akhir pelatihan, akan menguntungkan untuk memberikan contoh yang lebih kompleks: contoh yang memiliki persimpangan, serta contoh acak yang model anggap serupa (penambangan negatif keras).
Contoh: Sinonim untuk kata "triangle."
Pada tahap ini, kita sudah dapat membedakan fungsi yang baik yang cocok dengan kata-kata, tetapi ini bukanlah apa yang kita perjuangkan.Fungsi semacam itu memungkinkan kita melakukan pencocokan kata tidak langsung, dan kami ingin membandingkan seluruh kalimat.
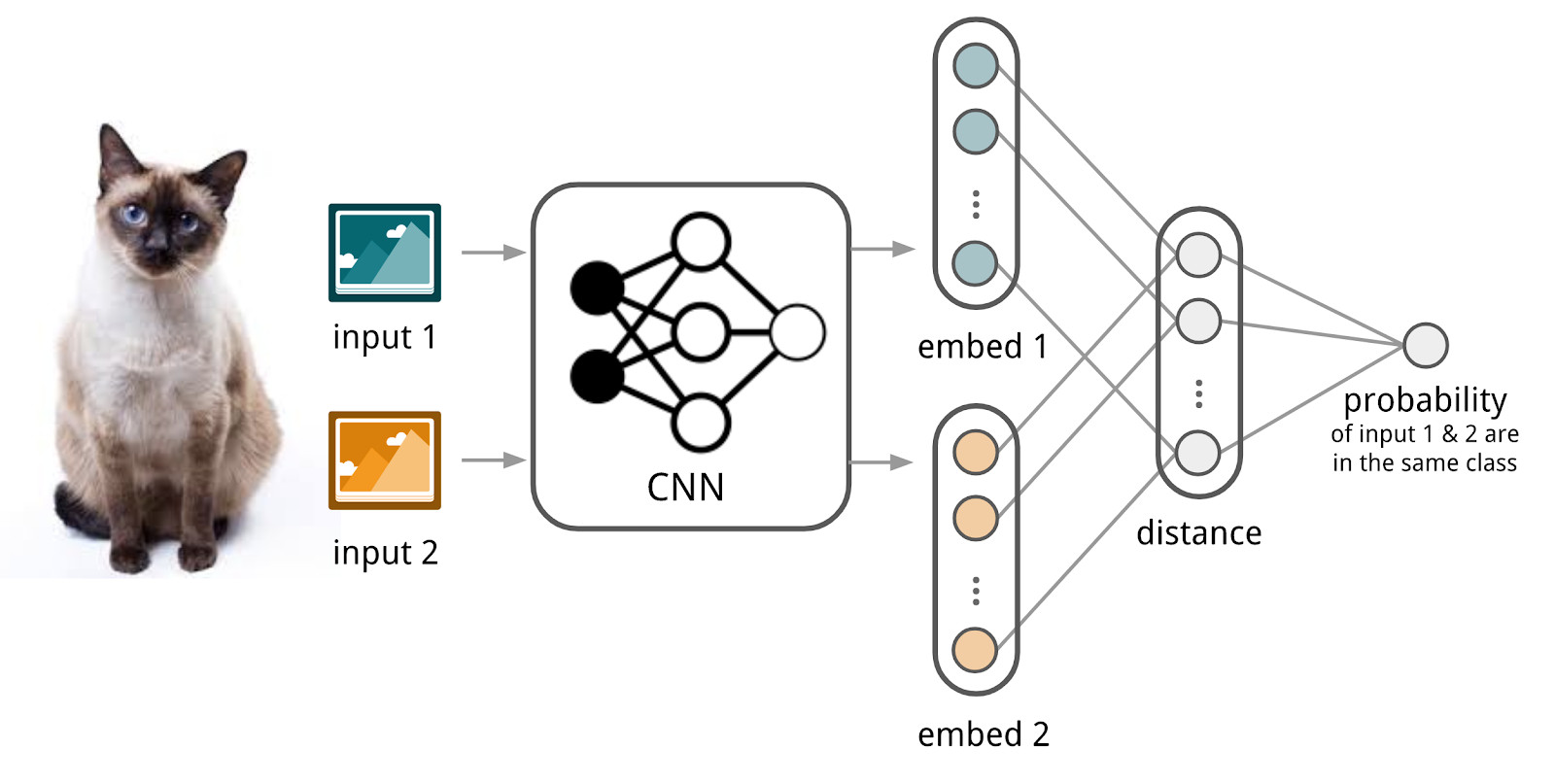
Di sini jaringan saraf akan membantu kita. Mari kita membuat encoder yang menerima teks (permintaan atau dokumen) dan menghasilkan representasi vektor sehingga teks yang mirip memiliki vektor yang dekat dan yang jauh. Misalnya, Anda dapat menggunakan jarak cosinus sebagai ukuran kesamaan.
Di sini kita akan menggunakan peralatan jaringan siam, karena mereka jauh lebih mudah untuk dilatih. Jaringan Siam terdiri dari pembuat enkode, yang diterapkan pada sampel data dari dua keluarga atau lebih dan operasi perbandingan (misalnya, jarak kosinus). Saat menerapkan encoder ke elemen dari keluarga yang berbeda, bobot yang sama digunakan; ini dengan sendirinya memberikan regularisasi yang baik dan sangat mengurangi jumlah faktor yang diperlukan untuk pelatihan.
Encoder menghasilkan representasi vektor dari teks dan belajar sehingga kosinus antara representasi teks yang sama adalah maksimum, dan antara representasi yang berbeda adalah minimal.
Jaringan dengan kompleksitas semantik yang dalam, DSSM cocok untuk tugas kami. Kami menggunakannya dengan perubahan kecil, yang akan saya bahas di bawah ini.
Cara kerja DSSM klasik: kueri dan dokumen disajikan dalam bentuk sekantong trigram, yang darinya diperoleh representasi vektor standar. Ia dilewatkan melalui beberapa lapisan yang terhubung sepenuhnya, dan jaringan dilatih sedemikian rupa untuk memaksimalkan probabilitas bersyarat dari dokumen berdasarkan permintaan, yang setara dengan memaksimalkan jarak kosinus antara representasi vektor yang diperoleh melalui lintasan penuh melalui jaringan.
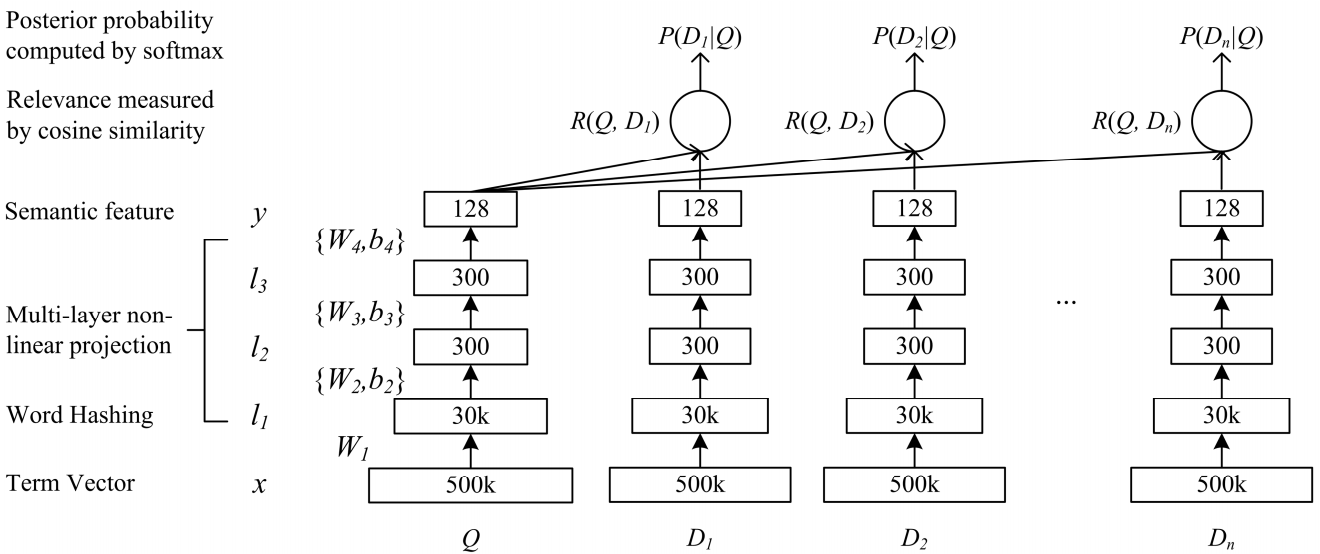 Po-Sen Huang Xiaodong He Jianfeng Gao Li Deng Alex Acero Larry Heck. 2013 Mempelajari Model Semantik Terstruktur Dalam untuk Pencarian Web menggunakan Data Clickthrough
Po-Sen Huang Xiaodong He Jianfeng Gao Li Deng Alex Acero Larry Heck. 2013 Mempelajari Model Semantik Terstruktur Dalam untuk Pencarian Web menggunakan Data ClickthroughKami pergi dengan cara yang hampir sama. Yaitu, setiap kata dalam kueri direpresentasikan sebagai vektor trigram, dan teks sebagai vektor kata, sehingga meninggalkan informasi tentang kata mana yang berdiri. Selanjutnya, kami menggunakan konvolusi satu dimensi di dalam kata-kata, memperhalus representasi ini, dan operasi penarikan maksimum global untuk mengumpulkan informasi tentang kalimat dalam representasi vektor sederhana.

Dataset yang kami gunakan untuk pelatihan hampir sepenuhnya bertepatan pada intinya dengan yang digunakan untuk model linier.
Kami tidak berhenti di situ. Pertama, mereka datang dengan mode pra-pelatihan. Kami mengambil daftar pertanyaan untuk dokumen, memasukkan pengguna yang berinteraksi dengan dokumen ini, dan melatih jaringan saraf untuk menyematkan pasangan semacam itu. Karena pasangan ini berasal dari keluarga yang sama, jaringan seperti itu lebih mudah dipelajari. Plus, maka lebih mudah untuk melatihnya pada contoh pertempuran ketika kita membandingkan permintaan dan dokumen.
Contoh: pengguna pergi ke e.mail.ru/login dengan permintaan: email, input email, alamat email, ...Akhirnya, bagian sulit terakhir, yang masih kami perjuangkan dan di mana kami hampir mencapai kesuksesan, adalah tugas membandingkan permintaan dengan beberapa dokumen panjang. Mengapa tugas ini lebih sulit? Di sini, mesin-mesin jaringan Siam sudah lebih buruk, karena permintaan dan dokumen panjang itu milik berbagai kelompok benda. Namun demikian, kami tidak mampu mengubah arsitekturnya. Anda hanya perlu menambahkan konvolusi dengan kata-kata, yang akan menyimpan lebih banyak informasi tentang konteks setiap kata untuk representasi vektor akhir teks.
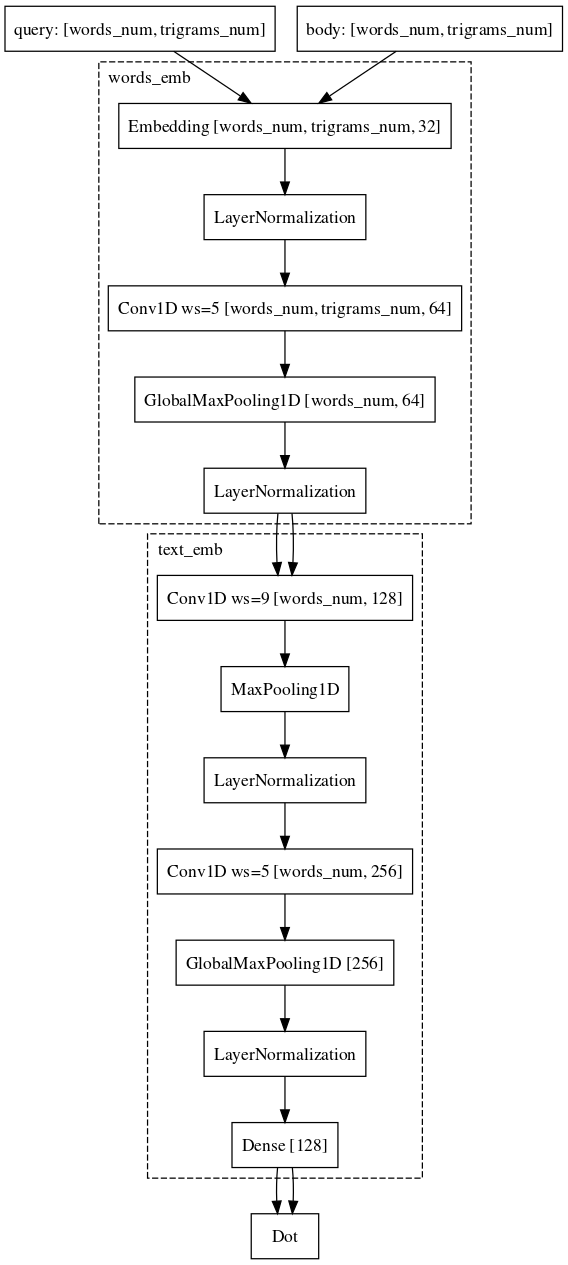
Saat ini, kami terus meningkatkan kualitas model kami dengan memodifikasi arsitektur dan bereksperimen dengan sumber data dan mekanisme pengambilan sampel.