Isi
Terkadang bug sendiri menemukan kita. Jadi kami mendorong sederet data besar - dan sistem terhenti. Apakah karena 1 juta karakter yang jatuh? Atau apakah dia suka yang tertentu?
Atau file diunggah ke sistem dan macet. Mengapa Karena nama, ekstensi, data di dalam atau ukuran? Anda dapat mendorong pelokalan ke pengembang, biarkan dia berpikir apa yang buruk dalam file. Namun seringkali Anda dapat menemukan alasannya sendiri, dan kemudian lebih akurat menggambarkan masalahnya.
Jika Anda menemukan data minimum untuk dimainkan, maka:
- Anda akan menghemat waktu untuk pengembang - ia tidak perlu terhubung ke test stand, memuat file sendiri dan debut
- Manajer akan dapat dengan mudah menilai prioritas tugas - apakah perlu segera diperbaiki, atau bisakah bug menunggu? Sementara nama "beberapa file jatuh, mengapa xs" sulit dilakukan ...
- Deskripsi bug dari memahami penyebab musim gugur juga akan bermanfaat.
Bagaimana cara menemukan data minimum untuk memainkan bug? Jika ada petunjuk dalam log, terapkan. Jika tidak ada petunjuk, maka metode terbaik adalah metode pembagian dua bagian (juga dikenal sebagai metode "pembelahan dua" atau "dikotomi").
Deskripsi Metode
Metode ini digunakan untuk menemukan tempat musim gugur yang tepat:
- Ambil paket data yang jatuh.
- Hancurkan menjadi dua.
- Periksa setengah 1
- Jika jatuh, maka masalahnya ada di sana. Kami bekerja lebih jauh dengannya.
- Jika tidak jatuh → periksa setengah 2.
- Ulangi langkah 1-3 hingga satu nilai jatuh tetap ada.

Metode ini memungkinkan Anda untuk melokalisasi masalah dengan cepat, terutama jika dilakukan secara terprogram. Pengembang mengintegrasikan mekanisme tersebut ke dalam pemrosesan data. Dan jika mereka tidak membangunnya, maka mereka sendiri menderita kemudian ketika penguji datang kepada mereka dan berkata, "Itu jatuh pada file ini, tetapi saya tidak dapat menemukan alasan yang tepat."
Aplikasi oleh penguji
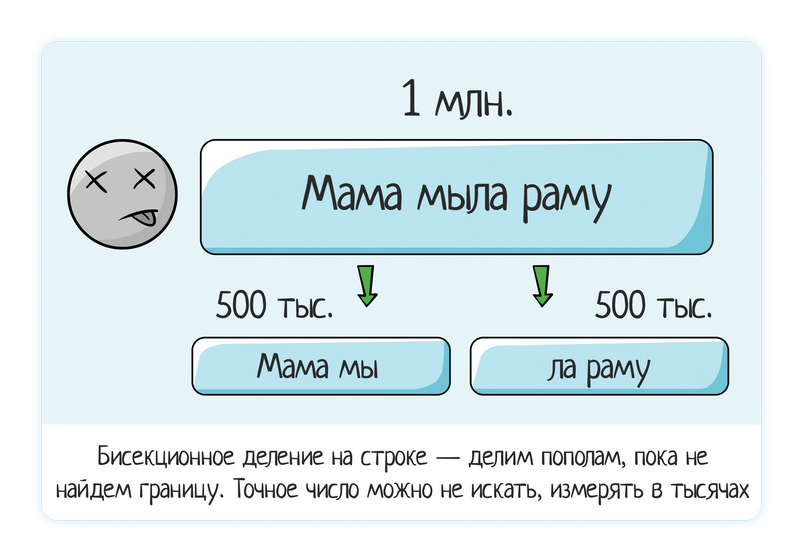
Baris data
Memuat satu baris data 1 juta - sistem membeku.
Kami mencoba 500 ribu (terbagi dua) - masih hang.
Kami mencoba 250 ribu - tidak menggantung, semuanya baik-baik saja.
↓
Oleh karena itu kesimpulan bahwa masalahnya ada di suatu tempat antara 250 dan 500 ribu .. Sekali lagi kami menerapkan pembagian dua bagian.
Kami mencoba 350 ribu (membaginya "dengan mata" - cukup diizinkan, Anda tidak harus berlari ke angka yang tepat ketika bermain secara manual) - semuanya baik
Kami mencoba 450 ribu - ini buruk.
Kami mencoba 400 ribu - ini buruk.
↓
Secara umum, Anda sudah bisa mendapatkan bug. Sangat jarang diperlukan dari penguji untuk melaporkan bahwa perbatasan atau bug jelas dalam angka 286 586. Cukup cukup untuk melokalisasi kira-kira - 290 ribu.
Hanya satu hal untuk memeriksa "10" dan segera "300 ribu", dan sama sekali berbeda untuk memberikan informasi yang lebih lengkap: "hingga 10 ribu semuanya baik-baik saja, mulai 10 hingga 280 ribu rem dimulai, sudah turun menjadi 290 ribu".
Jelas bahwa ketika kuantitas diukur dalam ribuan, akan terlalu lama untuk mencari wajah tertentu secara manual. Ya, pengembang tidak membutuhkan ini. Nah, tidak ada yang mau membuang waktu dengan sia-sia.
Tentu saja, jika masalah aslinya ada pada garis dengan panjang 10-30 karakter, Anda dapat menemukan batas yang tepat. Itu semua masalah hubungan yang wajar dengan waktu - jika menggunakan menebak atau membagi dua, Anda dapat dengan cepat menemukan nilai yang tepat dan itu kecil (hingga 100 biasanya) - kami mencari pasti. Jika masalahnya ada pada jalur yang besar, lebih dari 1000 → cari kira-kira.
File
Mengunggah file - macet! Bagaimana, mengapa? Pertama, kami mencoba menganalisis untuk diri kami sendiri apa yang dapat memengaruhi tes yang kami uji? Ini adalah chip aturan utama "pertama positif, kemudian negatif." Jika Anda tidak mencoba memasukkan semuanya ke dalam satu tes sekaligus:
- Memeriksa file sampel kecil
- Kami memeriksa file 2GB besar, dengan banyak kolom, banyak kolom, ditambah variasi data internal yang berbeda
Akan sulit untuk dilokalisasi di sini. Dan jika Anda memisahkan cek:
- Banyak baris (tetapi datanya positif dan diverifikasi sebelumnya)
- Banyak kolom
- Beban berat
- ...
Itu kira-kira sudah bisa dimengerti, apa alasannya. Misalnya, jatuh pada sejumlah besar garis - dari 100 ribu. Oke, kami sedang mencari perbatasan yang lebih akurat menggunakan pembagian dua bagian:
- Kami membagi file menjadi dua oleh 50 ribu, memeriksa yang pertama.
- Jika Anda jatuh, bagilah
- Maka, sampai kita menemukan tempat khusus untuk jatuh
Jika penurunan tergantung pada jumlah garis, kami mencari batas perkiraan: "Setelah 5.000 jatuh, tidak ada 4000 ribu." Mencari tempat tertentu (4589) tidak perlu. Terlalu lama dan tidak sepadan dengan waktu.
Bug ini ditemukan oleh siswa di Dadat . File data dapat dimuat di sana, sistem akan memproses dan menstandarisasi data ini: kesalahan ketik yang benar, menentukan informasi yang hilang dari direktori (kode KLADR, FIAS, koordinat geografis, distrik kota, kode pos ...).
Gadis itu mencoba mengunduh file besar dan mendapatkan hasilnya: sistem menunjukkan bilah progres pada 100% beban dan hang lebih dari 30 menit.
Lokalisasi melangkah lebih jauh - kapan pembekuan dimulai? Ini penting karena memengaruhi prioritas tugas. Berapa ukuran unduhan yang umum? Seberapa sering pengguna mengirimkan LOTS langsung?
Mungkin sistem ini dirancang untuk memproses ribuan baris, kemudian bug semacam itu dijejalkan ke "Perbaiki suatu hari". Atau unduhan biasa - 10-50 ribu baris yang memproses secara normal, yah, itu berarti bug tidak menyala, kami akan memperbaikinya nanti.
Pelokalan tugas:
- untuk file dengan 50 ribu baris, 15 detik hang,
- untuk file dengan 100 ribu baris, 30 detik hang,
- untuk file dengan 150 ribu baris, 1 menit hang,
- untuk file dengan 165 ribu baris hang 4 menit,
- untuk file 172 ribu baris dengan 100% progress bar penuh membeku selama lebih dari setengah jam
Di sinilah pekerjaan penguji sudah dilakukan secara kualitatif. Informasi lengkap diberikan tentang pengoperasian sistem, atas dasar yang mana manajer dapat menyimpulkan betapa mendesaknya diperlukan untuk memperbaiki bug.
Verifikasi juga tidak memakan banyak waktu. Anda dapat pergi atau dari akhir - di sini kami telah mengunduh 200 ribu baris, dan kapan masalahnya dimulai? Kami menggunakan metode pembagian dua bagian!
Atau mulai dengan jumlah yang relatif kecil - 50 ribu, secara bertahap meningkat (setengahnya, metode pembagian dua bagian, justru sebaliknya). Mengetahui bahwa semuanya akan menjadi buruk pada 200 ribu, kami memahami bahwa tidak akan ada banyak tes. Kami memeriksa 50, 100, 150 - untuk tiga tes kami menemukan batas perkiraan. Dan kemudian menggali tidak lagi diperlukan.
Tetapi ingat bahwa Anda juga perlu menguji teori Anda. Benarkah masalahnya ada pada jumlah baris, dan bukan data di dalam file? Memeriksa ini sangat mudah - buat file 5000 baris dengan satu nilai "positif". Nilai itu yang tepatnya berfungsi yang sudah Anda periksa sebelumnya. Jika tidak ada jatuh, maka masalahnya adalah najis =)) Tampaknya teori jumlah baris salah dan masalahnya ada di data itu sendiri.
Meskipun Anda dapat mencoba 10 ribu baris dengan nilai positif. Mungkin saja kejatuhan akan terjadi lagi. Hanya file sumber Anda ada di beberapa kolom. Atau ada karakter di dalamnya yang mengambil byte lebih dari nilai positif ... Secara umum, jangan langsung menolak teori ukuran file atau jumlah baris. Coba pembagian dua bagian sebaliknya - gandakan file.
Tetapi bagaimanapun juga, ingatlah bahwa semakin banyak cek tercampur dalam satu, semakin sulit untuk melokalisasi bug. Oleh karena itu, lebih baik untuk segera menguji jumlah baris atau kolom pada nilai positif tunggal. Sehingga Anda yakin bahwa Anda menguji jumlah data, bukan data itu sendiri. Analisis uji dan semua itu =)
Tetapi bagaimana jika masalahnya bukan pada jumlah baris, tetapi pada data itu sendiri? Dan Anda tidak tahu persis di mana. Mungkin Anda menjejalkan data dari "War and Peace" ke dalam file uji, atau mengunduh spreadsheet besar dari suatu tempat di Internet ... Atau pengguna menemukan masalah sama sekali - ia mengunggah file-nya dan semuanya jatuh. Dia datang untuk mendukung, dukungan datang kepada Anda: file ada pada Anda, mainkan.
Tindakan selanjutnya tergantung pada situasinya. Jika tenggat waktu pengguna berjalan atau uang didebit darinya, dan kemudian pemrosesan file telah jatuh, maka ini adalah bug pemblokir. Dan tidak ada waktu untuk melatih penguji pelokalan. Lebih mudah untuk memberikan file yang jatuh ke pengembang, biarkan dia bebas dan temukan alasannya sendiri.
Tetapi jika Anda sendiri menemukan kesalahan, yaitu waktu untuk menggali sendiri. Sekali lagi, jangan lupa akal sehat, seperti biasa dengan lokalisasi. Awalnya kami mencoba menarik kesimpulan sendiri, lalu meminta bantuan. Untuk membuat kesimpulan sendiri, Anda perlu:
- periksa log, mungkin ada jawaban yang tepat;
- melihat isi file: sesuatu mungkin menarik perhatian Anda, itulah teori pertama;
- gunakan metode pembagian dua bagian.
Akibatnya, alih-alih bug “Falls file, mengapa xs, ini adalah lampiran file 2GB”, Anda meletakkan bug yang dipikirkan dengan baik dan dilokalkan: “File jatuh jika tanggal format DD / MM / YYYYY ada di dalam”. Dan kemudian Anda tidak perlu file 2GB, Anda hanya perlu satu file untuk satu baris dan satu kolom!

Aplikasi oleh pengembang
Pada sejumlah besar data, tester tidak mencari batas yang jelas, karena tidak masuk akal untuk melakukan ini secara manual. Tetapi pengembang menggunakan metode pembagian dua bagian dalam kode dan selalu dapat menemukan tempat tertentu untuk jatuh. Bagaimanapun, sistem akan membagi kemenangan, dan bukan seseorang!
Sebagai contoh, kami memiliki mekanisme untuk memuat data ke dalam sistem. Itu bisa memuat 10 ribu satu juta. Tapi ini tidak masalah, karena unduhannya ada dalam 200 entri. Jika ada yang salah, sistem itu sendiri melakukan pembagian dua bagian. Itu sendiri. Sampai menemukan tempat masalah. Kemudian baca di log:
- Mendapat 1.000 entri
- 200 catatan yang diproses
- Diproses 400 catatan
- Ups, jatuh di atas tumpukan 200 rekaman!
- Saya mencoba memproses satu pak ukuran 100
- Saya mencoba memproses satu pak ukuran 50
- Saya mencoba memproses satu pak ukuran 25
...
- Kesalahan pada pengidentifikasi seperti itu: bidang Email yang diperlukan tidak diisi
- 600 catatan yang diproses
...
Di sini, tentu saja, logika selanjutnya juga tergantung pada pengembangnya. Entah pemrosesan berhenti setelah menemukan kesalahan, atau melangkah lebih jauh. Tersandung pada paket 200 entri? Kami sampai pada titik menemukan kemacetan, menandai entri sebagai salah, memproses 199 yang tersisa, dan melanjutkan.
Tetapi bagaimana jika seluruh paket berantakan? Kami menandai catatan sebagai salah, tetapi 199 sisanya juga tidak dapat diproses. Mengapa Kami menerapkan metode yang sama, mencari masalah baru. Caranya adalah Anda selalu harus bisa berhenti tepat waktu.
Jika jumlah kesalahan lebih dari 10-50-100, maka lebih baik menghentikan pengunduhan. Mungkin saja terjadi kesalahan unggahan di sistem asli dan kami menerima sejuta "kurva" data. Jika sistem akan membagi setiap paket dari 200 catatan menjadi dua, dan kemudian membagi 199 sisanya, dan seterusnya, maka itu akan buruk bagi semua orang:
- Log tumbuh dari 15 mb menjadi 3 gb dan menjadi tidak dapat dibaca;
- Sistem mungkin macet saat mencoba membuat pesan kesalahan akhir (saya berbicara tentang situasi ini di bagian BMW Mnemonics );
- Banyak waktu dihabiskan untuk mencari semua kesalahan. Ya, sistem melakukan ini lebih cepat daripada seseorang, tetapi jika Anda membagi satu juta paket dari 200 catatan, itu akan memakan waktu.
Jadi otak harus dimasukkan di mana-mana - baik dalam pengujian manual dan saat menulis kode program. Anda harus selalu mengerti kapan harus berhenti. Hanya dalam kasus pengujian manual akan "menemukan perbatasan", dan dalam pengembangan "berhenti jika ada banyak jatuh".
Ringkasan
Metode pembagian dua bagian digunakan untuk mencari lokasi yang tepat dari musim gugur dan lokalisasi bug.
Cari nomornya dan mulailah membaginya menjadi dua:
- panjang garis;
- ukuran file
- berat file;
- jumlah baris / kolom;
- jumlah memori bebas di ponsel;
- ...
Tapi ingat - suatu hari Anda harus berhenti! Tidak perlu berhenti dan mencari angka pastinya jika membutuhkan ribuan tes tambahan. Tetapi 5-10 menit dapat diberikan untuk pelokalan.
PS - cari artikel yang lebih bermanfaat di blog saya dengan tag “berguna”