Saya akan mencoba memberi tahu Anda betapa mudahnya mendapatkan hasil yang menarik dengan hanya menerapkan pendekatan yang sepenuhnya standar dari tutorial kursus pembelajaran mesin ke data yang bukan yang paling banyak digunakan dalam Pembelajaran Jauh. Inti dari postingan saya adalah kita masing-masing, Anda hanya perlu melihat berbagai informasi yang Anda ketahui dengan baik. Untuk melakukan ini, pada kenyataannya, jauh lebih penting untuk hanya memahami data Anda dengan baik daripada menjadi ahli dalam struktur terbaru dari jaringan saraf. Artinya, menurut saya, kita berada pada titik emas dalam pengembangan DL, ketika di satu sisi itu sudah menjadi alat yang dapat digunakan tanpa perlu menjadi PhD, dan di sisi lain itu masih penuh dengan area di mana tidak ada yang benar-benar menggunakannya, jika Anda melihat Sedikit lebih jauh dari tema tradisional.

Membaca artikel dan sambil melihat bagaimana pembelajaran mesin berkembang, Anda dan saya dapat dengan mudah mendapatkan perasaan bahwa kereta ini lewat. Memang, jika Anda mengambil kursus paling terkenal (misalnya, Andrew Ng ) atau sebagian besar artikel tentang Habré dari komunitas Open Data Science yang sangat baik , Anda dengan cepat menyadari bahwa tidak ada yang dapat dilakukan di sini dari kedalaman memori pengetahuan lembaga dalam matematika yang lebih tinggi, yah, setidaknya beberapa hasil yang waras (bahkan dalam contoh ' mainan ') dapat dicapai hanya setelah beberapa minggu mempelajari teori terry dan berbagai cara penerapannya. Tetapi seringkali Anda menginginkan yang lain, Anda ingin memiliki alat yang menjalankan fungsinya, yang memecahkan kelas masalah tertentu, sehingga, menerapkannya di bidang Anda, dapatkan hasilnya. Memang, di area lain semuanya benar-benar demikian, jika Anda, misalnya, menulis permainan dan tugas Anda adalah memastikan transfer informasi dari pemain ke server, maka Anda tidak mempelajari teori grafik, tidak mencari tahu bagaimana mengoptimalkan konektivitas sehingga paket Anda mencapai lebih cepat - Anda mengambil alat (pustaka, kerangka kerja) yang melakukan ini untuk Anda dan fokus pada apa yang unik untuk tugas tertentu (misalnya, jenis informasi apa yang Anda perlukan untuk berpindah-pindah). Mengapa ini tidak demikian untuk pembelajaran yang mendalam?
Bahkan, sekarang kita berada di ambang waktu ketika menjadi hampir seperti ini . Dan untuk diri saya sendiri, saya hampir menemukan alat oh - fast.ai. Perpustakaan yang sangat baik dan bahkan lebih curam, seluruh prinsip yang baru saja dibangun "top-down": pertama memecahkan masalah nyata, sering pada tingkat akurasi prediksi model State Of The Art, hingga struktur internal perpustakaan dan teori di baliknya.
Tentu saja, semuanya tidak begitu sederhana.Mengantisipasi tuduhan tidak profesionalisme dan kedangkalan pengetahuan saya (yang, tentu saja, lebih benar daripada tidak), saya ingin segera melakukan pemesanan. Apakah perlu mempelajari teorinya, menonton kuliah yang sangat mendasar itu, mengingat kalkulus matriks, dll.? Tentu saja. Dan semakin Anda menyelami topik ini, semakin Anda membutuhkannya dan harus bergantung pada sumber-sumber utama. Tetapi semakin sadar perendamannya, semakin mudah untuk memahami dengan tepat bagaimana hal-hal mendasar ini mempengaruhi hasilnya. Inti dari prinsip top-down adalah tepatnya bahwa itu harus dilakukan setelahnya. Setelah Anda telah menulis sesuatu yang nyata yang dapat Anda tunjukkan kepada teman-teman Anda. Setelah Anda cukup terjun ke topik dan itu telah membuat Anda terpesona. Dan teori yang diketahui akan menyusul Anda, itu hanya disajikan pada saat ketika akan lebih mudah bagi Anda untuk menghubungkannya dengan apa yang telah Anda lakukan. Sebagai penjelasan mengapa dan bagaimana cara kerjanya.
Saya lebih yakin bahwa seseorang lebih nyaman dengan pendekatan bottom-up tradisional. Dan ada baiknya ada dua cara, yang utama adalah kita bertemu di tengah
Dengan sekumpulan pengetahuan seperti itu, saya memutuskan untuk menerapkan DL pada suatu topik yang saya sendiri sudah lama tertarik dan melihat apa yang dapat menyebabkannya. Dan, tentu saja, hal pertama yang muncul di benak saya adalah sepak bola. Dan ketika saya menemukan statistik transfer yang luar biasa ini pada kaggle, pilihannya menjadi semakin jelas.
Sedikit tentang data ini. Mereka berisi informasi tentang siapa dan di mana telah pindah ke sepakbola Eropa selama 10 tahun terakhir. Ada informasi tentang klub, statistik pemain, liga di mana mereka berpartisipasi, pelatih dan agen, dan banyak lagi (total ada lebih dari seratus bidang yang berbeda). Data ini sangat menarik, tetapi apakah mungkin untuk menentukan berapa harga pemain dari mereka?
Jika Anda memikirkannya, maka harga seorang pemain tergantung pada sejumlah besar faktor. Pada saat yang sama, itu hebat, dan saya (jika tidak sebagian besar) bagian mereka tidak dapat diformalkan. Bagaimana memahami bahwa klub baru saja menjual pemain dengan harga tinggi, membutuhkan penyerang dan cukup siap untuk membayar lebih untuk itu; bagaimana memahami bahwa pelatih baru telah datang dan perlu memperbarui daftar nama; Bagaimana memahami bahwa bek utama klub memperhatikan grand dan dia mulai bermain dengan setengah hati, menuntut transfer? Semua ini pada dasarnya mempengaruhi jumlah transaksi, tetapi tidak disajikan dalam data. Dari situ, harapan awal saya tentang keakuratan ramalan seperti itu kecil.
Saya seorang programmer palsuPada titik ini, sudah waktunya untuk memasukkan penafian standar bahwa # bukan # , saya tidak menghasilkan uang dengan ini, jadi kode saya sangat buruk, dan kemungkinan besar dapat (dan harus?) Ditulis ulang jauh lebih baik, tetapi karena tugasnya adalah untuk menyelidiki ide dan (tidak ?) Konfirmasikan teorinya, lalu kodenya apa adanya :)
Model
Saya mulai dengan mengecualikan transfer yang lebih murah dari $ 1 juta, yang terlalu kacau. Kemudian dia membawa semua data ke satu meja besar dengan satu setengah ratus bidang, di mana untuk setiap transfer ada semua informasi yang tersedia tentang dirinya (baik tentang transfer itu sendiri, pemain dan statistiknya, serta tentang klub yang berpartisipasi di dalamnya, liga, dll. )
Mari kita lihat langkah-langkah bagaimana saya membuat model :
Setelah kami menyelesaikan semua impor Python dan memuat tabel transfer yang didenormalisasi, hal pertama yang perlu kita tentukan adalah bidang mana yang akan kita pertimbangkan sebagai numerik dan mana yang kategorikal. Ini adalah topik yang sangat menarik, Anda dapat membicarakannya di komentar, tetapi untuk menghemat waktu, saya hanya menjelaskan aturan yang saya gunakan: Saya, secara default, mempertimbangkan semua bidang yang dikategorikan, kecuali yang diwakili sebagai angka floating-point atau yang jumlah nilainya berbeda cukup besar.
Dalam konteks ini, misalnya, saya mempertimbangkan tahun kategorisasi transfer, meskipun ini awalnya merupakan angka, karena jumlah nilai yang berbeda kecil di sini (10 - dari 2008 hingga 2018). Tapi, misalnya, kinerja pemain di musim lalu (yang diwakili oleh jumlah rata-rata golnya per pertandingan) adalah pelampung dan dapat mengambil hampir semua nilai, jadi saya menganggapnya numerik.
cat_vars_tpl = ('season','trs_year','trs_month','trs_day','trs_till_deadline', 'contract_left_months', 'contract_left_years','age', 'is_midseason','is_loan','is_end_of_loan', 'nat_national_name','plr_position_main', 'plr_other_positions','plr_nationality_name', 'plr_other_nationality_name','plr_place_of_birth_country_name', 'plr_foot','plr_height','plr_player_agent','from_club_name','from_club_is_first_team', 'from_clb_place','from_clb_qualified_to','from_clb_is_champion','from_clb_is_cup_winner', 'from_clb_is_promoted','from_clb_lg_name','from_clb_lg_country','from_clb_lg_group', 'from_coach_name', 'from_sport_dir_name', 'to_club_name','to_club_is_first_team','to_clb_place', 'to_clb_qualified_to', 'to_clb_is_champion','to_clb_is_cup_winner','to_clb_is_promoted', 'to_clb_lg_name','to_clb_lg_country', 'to_clb_lg_group','to_coach_name', 'to_sport_dir_name', 'plr_position_0','plr_position_1','plr_position_2', 'stats_leag_name_0', 'stats_leag_grp_0', 'stats_leag_name_1', 'stats_leag_grp_1', 'stats_leag_name_2', 'stats_leag_grp_2') cont_vars_tpl = ('nat_months_from_debut','nat_matches_played','nat_goals_scored','from_clb_pts_avg', 'from_clb_goals_diff_avg','to_clb_pts_avg','to_clb_goals_diff_avg','plr_apps_0', 'plr_apps_1','plr_apps_2','stats_made_goals_0','stats_conc_gols_0','stats_cards_0', 'stats_minutes_0','stats_team_points_0','stats_made_goals_1','stats_conc_gols_1', 'stats_cards_1','stats_minutes_1','stats_team_points_1','stats_made_goals_2', 'stats_conc_gols_2','stats_cards_2','stats_minutes_2','stats_team_points_2', 'pop_log1p')
Kemudian, setelah secara eksplisit menunjukkan apa yang akan kami prediksi - jumlah transfer ( fee ), kami membagi data kami secara acak menjadi 2 bagian yaitu 80% dan 20%. Pada yang pertama dari mereka, kami akan mengajarkan jaringan saraf kami, di sisi lain - untuk memeriksa keakuratan prediksi.
ln = len(df) valid_idx = np.random.choice(ln, int(ln*0.2), replace=False)
Pada tahap persiapan terakhir, kita perlu membuat pilihan bagaimana kita akan mengukur masuk akal prediksi kita. Lalu saya memilih bukan metrik paling standar di bagian lokal alam semesta - Median kesalahan persen ( MdAPE ). Atau, sederhananya, berapa persen (harga absolut dari suatu transfer dapat berbeda dengan urutan besarnya) kemungkinan besar kita akan membuat kesalahan dalam harga transfer yang diambil secara acak. Sepertinya saya paling dekat dengan apa arti frasa “akurasi sistem prediksi transfer” bagi saya.
Sekarang saatnya, sebenarnya, untuk mulai mempelajari jaringan.
data = (TabularList.from_df(df, path=path, cat_names=cat_vars, cont_names=cont_vars, procs=procs) .split_by_idx(valid_idx) .label_from_df(cols=dep_var, label_cls=FloatList, log=True) .databunch(bs=BS)) learn = tabular_learner(data, layers=layers, ps=layers_drop, emb_drop=emb_drop, y_range=y_range, metrics=exp_mmape, loss_func=MAELossFlat(), callback_fns=[CSVLogger]) learn.fit_one_cycle(cyc_len=cycles, max_lr=max_lr, wd=w_decay)
Akurasi prediksi

Validation Error = 0.3492 berarti bahwa setelah pelatihan tentang kumpulan data baru ( validation set , validation set ), model rata-rata (median) adalah 34% keliru relatif terhadap harga transfer riil. Dan kami mendapatkannya hanya sebagai hasil dari beberapa baris kode yang diambil dari tutorial.
34% kesalahan, apakah banyak atau sedikit? Semuanya relatif. Satu-satunya sumber yang sebanding, data yang dapat diambil sebagai " prediksi " jumlah transfer, tentu saja adalah transfermarkt . Untungnya, ada bidang dalam data dari kaggle yang menunjukkan bagaimana situs ini memberi peringkat pemain pada saat transfer, dan ini dapat dibandingkan. Perlu dicatat di sini bahwa transfermarkt tidak pernah mengklaim bahwa market value mereka adalah kemungkinan harga transfer. Sebaliknya, mereka menekankan bahwa itu lebih merupakan " nilai jujur " dari satu atau pemain lain. Dan berapa banyak uang yang klub akan bayar untuk itu dalam situasi tertentu adalah hal yang sangat individual dan dapat berfluktuasi dalam satu arah atau lainnya dalam batas yang sangat luas. Tapi ini yang terbaik yang kita miliki, mari kita bandingkan .

Kesalahan transfermarkt - 35% , model kami - 35% . Sangat aneh dan, jujur, sangat mencurigakan.
Pada titik ini, saya mengusulkan untuk berpikir lagi. Sebuah situs dengan sejarah besar, dibuat hanya untuk menunjukkan 'nilai' pemain, yang bergantung pada kekuatan penuh dari efek kerumunan (itu memperoleh nilai dari peringkat pengunjung biasa dan profesional pasar) dan pengetahuan para ahli di satu sisi, dan model, yang tidak tahu apa-apa tentang sepak bola, tidak melihat apa pun kecuali data yang kami berikan (dan di luar data ini di dunia nyata, masih ada banyak hal yang dipertimbangkan oleh orang dengan transfermarkt), di sisi lain, mereka menunjukkan kesalahan yang sama . Selain itu, model kami juga memungkinkan memprediksi harga sewa pemain, yang nilai market value , untuk alasan yang jelas, tidak ditampilkan (dengan memperhitungkan transaksi tersebut, hasil dari transfermarkt bahkan lebih buruk ).
Jujur, saya masih berpikir bahwa saya memiliki semacam kesalahan di sini, semuanya terlalu bagus untuk menjadi kenyataan. Namun, mari kita melangkah lebih jauh.
Cara mudah untuk menguji diri sendiri adalah dengan mencoba menyamakan prediksi dari 2 sumber (model dan transfermarkt). Jika prediksi benar-benar independen satu sama lain dan tidak ada kesalahan yang mengganggu, maka hasilnya akan membaik.

Memang, rata-rata perkiraan mengurangi kesalahan prediksi menjadi 32% (!). Ini mungkin tampak sedikit, tetapi kita harus memahami bahwa kita memfilter lebih banyak informasi dari data, yang sangat diperas.
Tapi apa yang akan kita lakukan selanjutnya, menurut pendapat saya, bahkan lebih mengejutkan dan menarik, meskipun itu di luar cakupan tutorial fast.ai.
Penting fitur
Jaringan saraf, tidak untuk mengatakan bahwa itu benar-benar tidak layak, sering dianggap sebagai "kotak hitam". Kita tahu data apa yang bisa kita letakkan di sana, kita bisa mendapatkan prediksi model, kita bahkan bisa menilai seberapa besar prediksi itu benar. Tetapi kita tidak dapat menjelaskan dengan kriteria apa model “membuat” keputusan ini atau itu. Struktur internal jaringan itu sendiri sangat kompleks, dan yang lebih penting, non-linear, sehingga tidak mungkin untuk secara langsung melacak seluruh rantai pengambilan keputusan dan menarik kesimpulan yang signifikan dari dunia nyata dari sana. Tapi sungguh ingin. Saya ingin memahami apa yang paling mempengaruhi jumlah transfer.
Ya, kami tidak akan naik ke dalam jaringan. Tapi apa arti penting setiap bidang, sebut saja Fitur Pentingnya (FI)? Salah satu opsi untuk memahami 'pentingnya' adalah menghitung berapa banyak hal akan menjadi lebih buruk jika kita tidak memiliki bidang ini. Dan inilah tepatnya yang bisa kita ukur. Kami sekarang memiliki alat yang memberikan prediksi pada set data apa pun. Jadi, jika kita hanya menghitung seberapa besar kesalahan prediksi akan meningkat ketika kita mengganti data acak di lapangan, maka kita bisa memperkirakan seberapa besar (bidang) itu mempengaruhi hasil akhir, yang berarti betapa pentingnya itu. Untuk tetap berada dalam distribusi data yang nyata, bidang tersebut akan diisi tidak hanya dengan angka acak, tetapi dengan nilai campuran acak (yaitu, kami hanya akan mencampur kolom, misalnya, 'tahun transfer', dalam tabel asli). Untuk kesetiaan, proses ini dapat dilakukan beberapa kali untuk setiap bidang dengan rata-rata hasilnya. Semuanya cukup sederhana. Sekarang mari kita lihat bagaimana hal ini memberikan hasilnya:
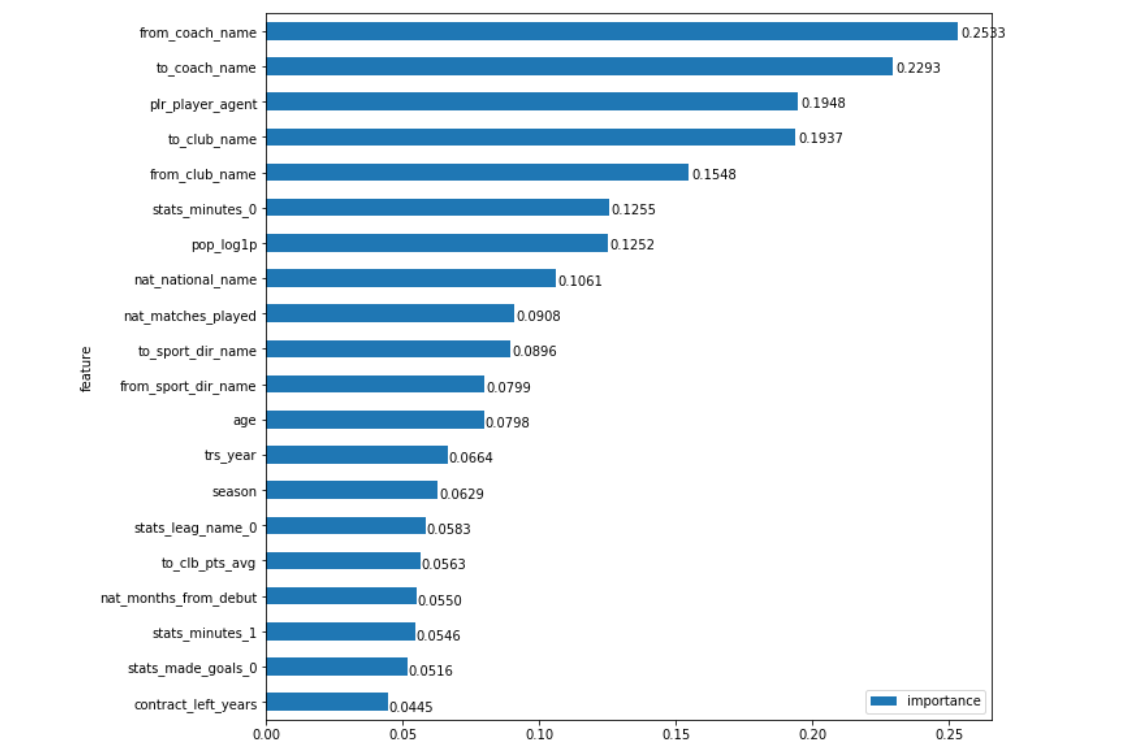
Naluriku berkata, "Ya dan tidak!"
Di satu sisi, bidang yang Anda harapkan ada di atas: pelatih tim dari mana dan ke mana pemain pergi ( from_coach_name , to_coach_name ), klub-klub itu sendiri yang berpartisipasi dalam transfer ( from_club_name , to_club_name ), ketenaran agen ( plr_player_agent ), ketenarannya di jejaring sosial ( pop_log1p ) dll. Tetapi di sisi lain ... Secara intuitif, sepertinya nama-nama pelatih seharusnya tidak memiliki bobot lebih dalam harga transfer daripada, misalnya, klub itu sendiri (kami tahu betul bahwa Benfica yang kondisional mampu menjual pemainnya dengan mahal). Apakah merek pelatih lebih kuat mempengaruhi harga daripada merek klub. Apakah kedatangan Mancini bersyarat begitu banyak memaksa klub untuk membayar lebih? Apa itu, kasus ketika data memberi kita informasi baru, sedikit berlawanan dengan intuisi, atau hanya kesalahan dalam model?
Mari kita perbaiki. Dengan melihat dari dekat grafik, mata dengan cepat menempel pada hal yang aneh. Tepat di bawah pusat ada 2 trs_year dan bidang season di trs_year , mereka mewakili tahun transfer dan musim di mana transisi akan dilakukan (secara umum, mereka mungkin tidak bertepatan, meskipun ini tidak sering terjadi). Pertama, tampaknya mereka harus lebih tinggi, kita tahu berapa banyak harga untuk pemain sepak bola telah meningkat dalam beberapa tahun terakhir, dan kedua, mereka jelas memaksudkan hal yang sama. Apa yang harus dilakukan? Ringkas saja pentingnya mereka? Bukan fakta bahwa ini bisa dilakukan! Tapi yang bisa kita lakukan adalah menerapkan pendekatan yang sama (menggabungkan nilai) tidak secara terpisah untuk dua bidang ini, tetapi sebagai sebuah kelompok. Artinya, ukur bagaimana kesalahan akan berubah jika ada nilai acak di 2 kolom ini sekaligus. Yah, karena kita telah melakukan ini selama bertahun-tahun, kita perlu melihat apakah kita memiliki bidang lain yang sama-sama 'terhubung'.
Misalnya, untuk klub, kami memiliki beberapa parameter: klub itu sendiri ( club_name ), serta serangkaian informasi tentangnya - dari liga, negara, dll. ( club_is_first_team , clb_lg_name , clb_lg_country , clb_lg_group ). Hanya dalam beberapa kasus kami tertarik untuk mengetahui seberapa besar pengaruhnya terhadap harga, misalnya, negara tempat pemain pergi secara terpisah ( clb_lg_country ), paling sering penting bagi kami untuk memahami berapa berat total bidang 'klub', yang sudah ada di negara tertentu, liga, dll. .
Dengan demikian, kita dapat menggabungkan semua bidang menjadi grup sesuai dengan konten semantik. Ini akan membantu kami hanya sebagai pengetahuan tentang area subjek dan akal sehat, serta 'kedekatan' fitur yang dihitung . Yang terakhir hanya menunjukkan bagaimana bidang berkorelasi satu sama lain, yaitu, seberapa mungkin untuk menganggapnya sebagai satu kelompok.
Menerapkan pendekatan ini, kami memperoleh grafik yang lebih intuitif tentang pentingnya bidang:
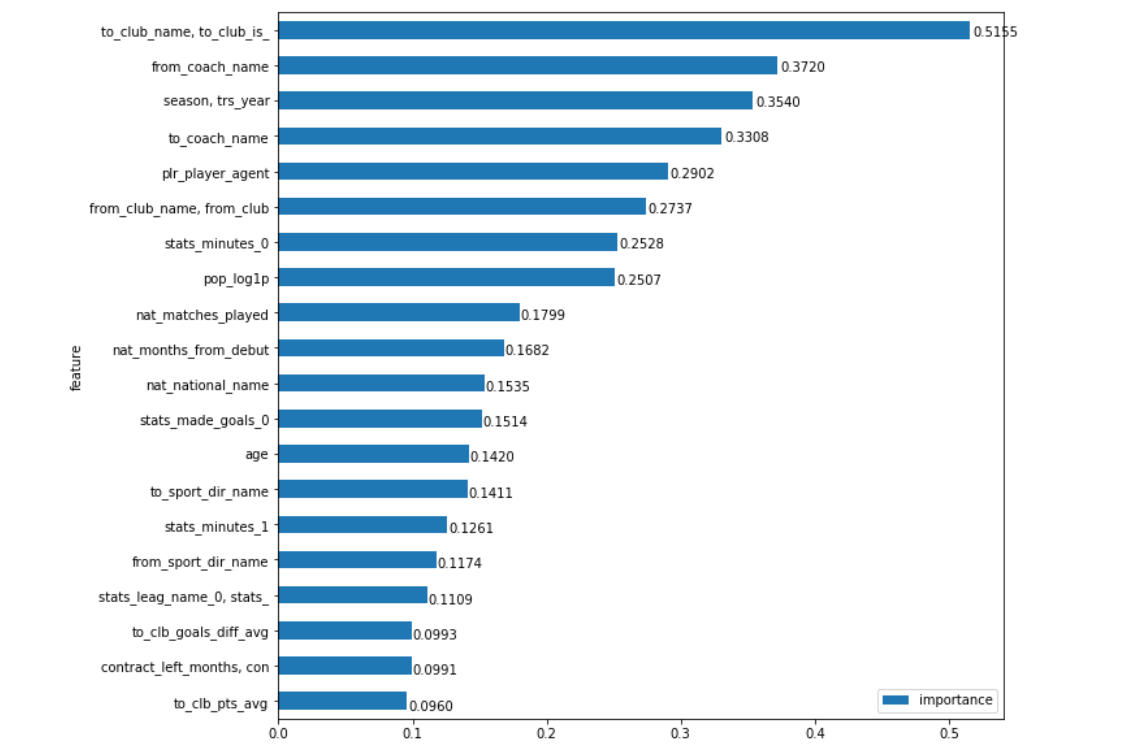
Itu dia. Tepatnya klub apa yang dibeli pemain yang paling memengaruhi jumlah transfer, dengan margin yang sangat bagus. Hi Man City, Barcelona, Zenit dan, misalnya, Benfica yang sama (setelah semua, " sangat mempengaruhi " hal yang sama tentang fakta bahwa beberapa klub, sebaliknya, dapat membeli pemain berkualitas lebih murah daripada "pasar"). Sepertinya bagi saya bahwa hal yang paling menarik dalam bekerja dengan data adalah bahwa ketika diperoleh, kesimpulannya jelas di satu sisi (well, saya ragu bahwa pembeli klub memiliki pengaruh paling kuat pada jumlah transfer), dan di sisi lain, itu agak mengejutkan (dan kandidat untuk kandidat pertama) tempat, secara intuitif, bisa agak, dan pemisahan dari yang kedua sepertinya tidak begitu signifikan)
Masih banyak hal menarik untuk dijelajahi. Misalnya, nama pelatih dari mana pemain dibeli, dari sudut pandang model, masih lebih penting daripada klub ... Biarkan perbedaannya sangat berkurang. Penjelasan logis untuk ini dapat ditemukan pada prinsipnya (meskipun kadang-kadang dapat ditemukan untuk apa pun). Ada pelatih (Guardiola, Klopp, Benitez, Berdyev) yang mematuhi ideologi tertentu dari permainan di klub yang berbeda, yang lebih baik mengungkapkan atau sebaliknya membuat posisi tertentu di lapangan kurang cerah, dan visibilitas pemain sangat mempengaruhi harganya. Tentang klub, bisa dikatakan, hampir mustahil. Dan fakta bahwa kita melihat pelatih yang tidak secara radikal menyimpang dari prinsip permainan mereka jauh lebih sering daripada klub yang mengganti pelatih, tetapi tetap berada dalam filosofi yang sama (misalnya, begitu saja, kecuali bahwa Ajax muncul di pikiran, dan Barcelona sangat dipertanyakan), berbicara tentang bahwa, mungkin, manajer tertentu mengungkapkan pemain lebih stabil daripada klub. Meskipun di sini saya tidak akan berpegang teguh pada pernyataan saya.
Dari indikator statistik murni, jumlah tertinggi hanyalah jumlah waktu yang dihabiskan pemain di lapangan tahun lalu dalam kompetisi utamanya ( stats_minutes_0 ). Ini hanya, cukup logis, karena seberapa banyak pemain ini menjadi "utama" di klubnya musim lalu sepertinya indikator statistik yang lebih universal dari keberhasilannya daripada yang lain - misalnya, jumlah gol yang dicetak atau kartu yang diterima.
Popularitas pemain ( pop_log1p ) menutup grup ini dari 8 parameter paling penting. Perlu diingat bahwa data yang kami sajikan selama 10 tahun terakhir. Saya pikir pentingnya bidang ini akan lebih tinggi jika kita mempertimbangkan 5 tahun terakhir, dan untuk nilai rata-rata selama dekade terakhir ini adalah hasil yang sepenuhnya dapat dimengerti, terutama jika kita memperhitungkan jarak dari tempat berikutnya.
Nah, hal terakhir yang ingin saya perhatikan adalah pentingnya bidang agen ( plr_player_agent ). Saya akan meninggalkan ini tanpa komentar, karena jika Anda dapat mematahkan margin salinan dalam perselisihan tentang (un) kebutuhan agen, maka tidak ada keraguan tentang tingkat pengaruhnya terhadap pasar transfer modern (walaupun model menyarankan untuk tidak melebih-lebihkan itu).

Ngomong-ngomong, mungkin hal yang paling menarik dalam metode analisis ini adalah aksesibilitasnya: tidak perlu membuat model " ideal " untuk mendapatkan informasi tentang pentingnya parameter. Dalam banyak kasus, itu cukup bahwa itu hanya memprediksi setidaknya, secara statistik berbeda secara signifikan dari melempar koin, dan Anda akan mendapatkan hasil yang sering berisi wawasan yang menarik atau memberi tahu Anda dari sisi baru mana Anda dapat melihat data.
Maka sudah saatnya untuk membulatkan, agar tidak menambah begitu banyak teks. Dalam perpisahan, saya ingin sekali lagi mendesak semua yang tertarik pada topik untuk mencoba (yang terbaik, menurut pendapat saya, untuk pemula) kursus Pembelajaran Mendalam - fast.ai dan terapkan pengetahuan yang diperoleh dalam 'bidang keahlian Anda', kemungkinan Anda akan menjadi yang pertama di sana :)
Dan jika Anda menyukainya, saya akan mencoba untuk menguasai bagian kedua dari teks tentang percobaan saya di mana model menggunakan alat yang sama kuatnya - Ketergantungan Partial akan memberi tahu Anda: klien agensi mana yang terbaik untuk menjadi pemain sepak bola, klub mana yang memiliki kebijakan transfer paling efektif, yang mana pelatih terbaik meningkatkan biaya pemain (selain calon yang jelas, ada banyak 'merek' yang tidak begitu dipromosikan yang jelas layak untuk dilihat lebih dekat) dan banyak lagi.
Bagian 2 - Model transfer sepakbola: menggali lebih dalam